La codifica di tensori sparsi è un attributo per codificare le informazioni sulle proprietà di sparsità dei tensori, ispirata tramite la formalizzazione TACO dei tensori sparsi. Questa codifica viene infine utilizzata da un passaggio di sparsifier per generare codice sparso completamente automaticamente da una rappresentazione del calcolo indipendente dalla sparsità, ovvero una rappresentazione sparsità rappresentazione viene convertita in una rappresentazione sparsa esplicita in cui i loop di co-iterazione operano su archivi sparsi formati anziché tensori con una sparsità codifica. Devi conoscere i passaggi del compilatore che vengono eseguiti prima di questo passaggio della semantica dei tipi di tensori con una tale codifica di sparsità.

In questa codifica, utilizziamo dimensione per fare riferimento agli assi del tensore semantico, e level per fare riferimento agli assi del formato effettivo di archiviazione, ovvero operativa del tensore sparso in memoria. Il numero di di solito è uguale a il numero dei livelli (ad esempio il formato di archiviazione CSR). Tuttavia, la codifica può anche mappare dimensioni a livelli di ordine superiore (ad esempio, per codificare un formato di archiviazione BSR sparso a blocchi) o a livelli di ordine inferiore (ad esempio, per linearizzare le dimensioni come un singolo livello dello spazio di archiviazione).
La codifica contiene una mappa che fornisce quanto segue:
- Una sequenza ordinata di specifiche delle dimensioni, ciascuna delle quali definisce:
- la dimensione-dimensione (implicita dalla forma della dimensione del tensore)
- un'espressione-dimensione
- Una sequenza ordinata di specifiche dei livelli, ciascuna delle quali include un
level-type, che definisce la modalità di archiviazione del livello. Ogni tipo di livello
è costituito da:
- un'espressione level-expression, che definisce cosa viene archiviato
- un formato a livello
- una raccolta di proprietà-livello che si applicano al formato dei livelli
Ogni espressione di livello è un'espressione affine rispetto alle variabili di dimensione. Di conseguenza, livello-espressioni definiscono collettivamente mappa affine dalle coordinate delle dimensioni e coordinate di livello. Espressioni di dimensioni definiscono collettivamente la mappa inversa, che deve essere fornito solo per i casi elaborati in cui non può essere dedotto automaticamente.
Ogni dimensione può anche avere un elemento SparseTensorDimSliceAttr facoltativo.
Per il formato di archiviazione sparso ci riferiamo agli indici memorizzati
come coordinate e offset nel formato di archiviazione come positions.
I formati dei livelli supportati sono i seguenti:
- dense : tutte le voci in questo livello vengono memorizzate
- compresso : vengono memorizzati solo i valori diversi da zero in questo livello
- loose_compressed : come compresso, ma consente spazio libero tra regioni
- singleton : una variante del formato compresso, in cui le coordinate non hanno fratelli o sorelle
- block2_4 : la compressione utilizza una codifica 2:4 per ogni blocco 1x4
Per un livello compresso, ogni intervallo di posizione è rappresentato in un modello
con il limite inferiore pos(i) e il limite superiore pos(i+1) - 1, il che implica
che gli intervalli successivi devono apparire in ordine senza "buchi" come separatori
che li rappresentano. Il formato compresso sciolto allenta questi vincoli rappresentando ciascuno
di posizione con un limite inferiore lo(i) e un limite superiore hi(i), che
consente che gli intervalli vengano visualizzati in ordine arbitrario e che siano separati per il gomito.
Per impostazione predefinita, ogni tipo di livello ha la proprietà di essere univoco (non duplicati coordinate a quel livello) e in ordine (le coordinate vengono visualizzate ordinate in questo ). Le seguenti proprietà possono essere aggiunte a un livello-formato da modificare questo comportamento predefinito:
- non univoche : a questo livello potrebbero essere visualizzate coordinate duplicate
- nonordered : le coordinate possono essere visualizzate in ordine arbitrario
Oltre alla mappa, sono facoltativi i due campi seguenti:
La larghezza in bit richiesta per l'archiviazione della posizione (offset integrali) nello schema di archiviazione sparse). Una larghezza ridotta riduce la memoria in più di spazio di archiviazione, purché la larghezza sia sufficiente definiscono l'intervallo totale richiesto (cioè il numero massimo a tutti i livelli indiretti). Le opzioni sono
8,16,32,64o0per indicare la larghezza in bit nativa.La larghezza in bit richiesta per l'archiviazione delle coordinate (le coordinate di voci memorizzate). Una larghezza ridotta riduce l'ingombro di memoria di archiviazione overhead, purché la larghezza sia sufficiente per definire l'intervallo totale richiesto (ovvero il valore massimo di ogni tensore coordinate su tutti i livelli). Le scelte sono
8,16,32,64o0per indicare una larghezza in bit nativa.
Esempi
Nel formato CSR(Compressed Sparse Row)
come mostrato di seguito, la codifica dei tensori sparsi
sarebbe:
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
Indica che first dimension (riga) è mappata a first level,
che è un livello dense, indicato dalla dimensione 4. second dimension
(colonna) è mappato al second level, indicato dalla matrice delle posizioni e
dell'array di coordinate. Il valore 3 ([1, 1] nella matrice originale) è
rappresentato dall'offset dalla matrice delle posizioni (il numero di riga del valore 3
è 1 nella matrice originale poiché è la seconda coppia di offset e
il numero di colonna risiede nell'indice [2 : 4) nella matrice delle coordinate). E nel
dell'array di coordinate, possiamo vedere che il numero di colonna del valore 3 è 1
principale.

Per il formato BSR(Block Sparse Row), il tipo di tensore sparso è:
#BSR = #sparse_tensor.encoding<{
map = (i, j) ->
( i floordiv 2 : dense
, j floordiv 2 : compressed
, i mod 2 : dense
, j mod 2 : dense
)
Considera la seguente matrice sparsa, con blocchi 2x2:
Example 2x2 block storage:
+-----+-----+-----+ +-----+-----+-----+
| 1 2 | . . | 4 . | | 1 2 | | 4 0 |
| . 3 | . . | . 5 | | 0 3 | | 0 5 |
+-----+-----+-----+ => +-----+-----+-----+
| . . | 6 7 | . . | | | 6 7 | |
| . . | 8 . | . . | | | 8 0 | |
+-----+-----+-----+ +-----+-----+-----+
che viene infine memorizzato in formato TACO
Stored as:
positions[1] : 0 2 3
coordinates[1] : 0 2 1
values : 1.000000 2.000000 0.000000 3.000000
4.000000 0.000000 0.000000 5.000000
6.000000 7.000000 8.000000 0.000000
Che, tra l'altro, è letteralmente Formato a blocchi NVidia presentato nella documentazione cuSparse.
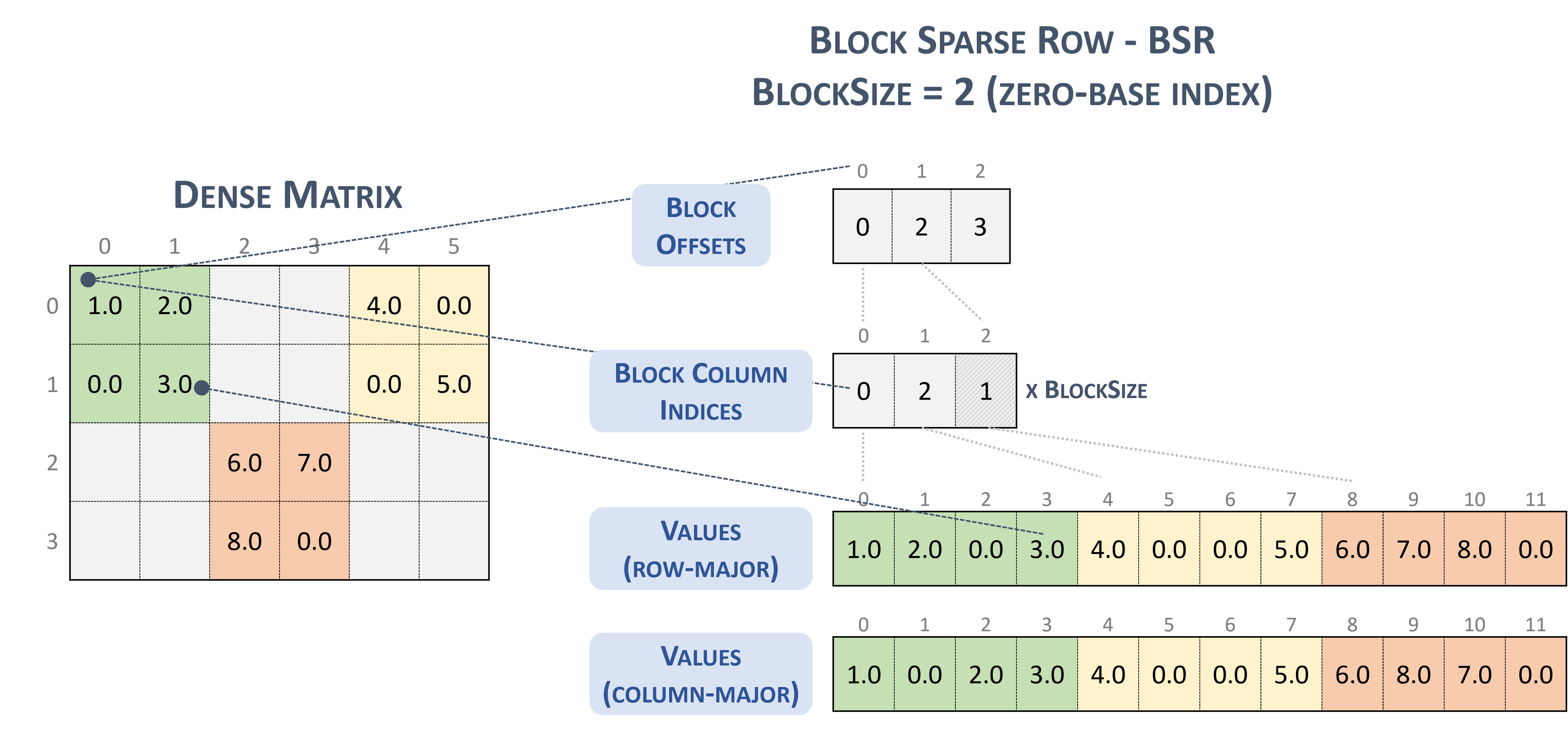
Blocca riga sparsa. (nessuna data). Nvidia. https://docs.nvidia.com/cuda/cusparse/_images/bsr.png
Supportiamo anche Nvidia's 2:4 structured sparsity.
Il tipo di tensore sparso è il seguente:
#NV_24 = #sparse_tensor.encoding<{
map = ( i, j ) -> ( i : dense,
j floordiv 4 : dense,
j mod 4 : block2_4),
crdWidth = 2 // 2-bits for each coordinate
}>
Data la matrice di esempio fornita nella documentazione di NVidia:
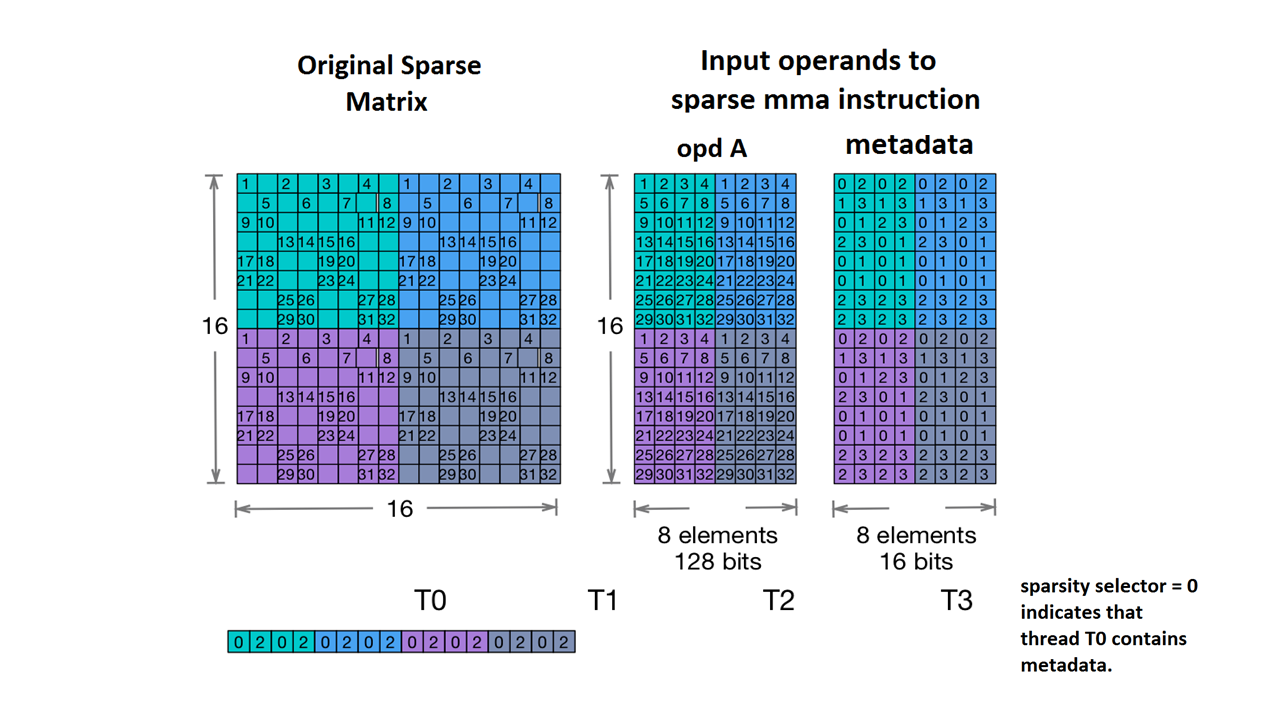
Esempio di archiviazione MMA sparsa. (nessuna data). Nvidia. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-sparse-mma
L'MLIR ora mappa questa matrice a un layout identico:
coordinates[2] :
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
values :
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
Altri esempi:
// Sparse vector.
#SparseVector = #sparse_tensor.encoding<{
map = (i) -> (i : compressed)
}>
... tensor<?xf32, #SparseVector> ...
// Sorted coordinate scheme.
#SortedCOO = #sparse_tensor.encoding<{
map = (i, j) -> (i : compressed(nonunique), j : singleton)
}>
... tensor<?x?xf64, #SortedCOO> ...
// Batched sorted coordinate scheme, with high encoding.
#BCOO = #sparse_tensor.encoding<{
map = (i, j, k) -> (i : dense, j : compressed(nonunique, high), k : singleton)
}>
... tensor<10x10xf32, #BCOO> ...
// Compressed sparse row.
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
... tensor<100x100xbf16, #CSR> ...
// Doubly compressed sparse column storage with specific bitwidths.
#DCSC = #sparse_tensor.encoding<{
map = (i, j) -> (j : compressed, i : compressed),
posWidth = 32,
crdWidth = 8
}>
... tensor<8x8xf64, #DCSC> ...
// Block sparse row storage (2x3 blocks).
#BSR = #sparse_tensor.encoding<{
map = ( i, j ) ->
( i floordiv 2 : dense,
j floordiv 3 : compressed,
i mod 2 : dense,
j mod 3 : dense
)
}>
... tensor<20x30xf32, #BSR> ...
// Same block sparse row storage (2x3 blocks) but this time
// also with a redundant reverse mapping, which can be inferred.
#BSR_explicit = #sparse_tensor.encoding<{
map = { ib, jb, ii, jj }
( i = ib * 2 + ii,
j = jb * 3 + jj) ->
( ib = i floordiv 2 : dense,
jb = j floordiv 3 : compressed,
ii = i mod 2 : dense,
jj = j mod 3 : dense)
}>
... tensor<20x30xf32, #BSR_explicit> ...
// ELL format.
// In the simple format for matrix, one array stores values and another
// array stores column indices. The arrays have the same number of rows
// as the original matrix, but only have as many columns as
// the maximum number of nonzeros on a row of the original matrix.
// There are many variants for ELL such as jagged diagonal scheme.
// To implement ELL, map provides a notion of "counting a
// dimension", where every stored element with the same coordinate
// is mapped to a new slice. For instance, ELL storage of a 2-d
// tensor can be defined with the mapping (i, j) -> (#i, i, j)
// using the notation of [Chou20]. Lacking the # symbol in MLIR's
// affine mapping, we use a free symbol c to define such counting,
// together with a constant that denotes the number of resulting
// slices. For example, the mapping [c](i, j) -> (c * 3 * i, i, j)
// with the level-types ["dense", "dense", "compressed"] denotes ELL
// storage with three jagged diagonals that count the dimension i.
#ELL = #sparse_tensor.encoding<{
map = [c](i, j) -> (c * 3 * i : dense, i : dense, j : compressed)
}>
... tensor<?x?xf64, #ELL> ...
// CSR slice (offset = 0, size = 4, stride = 1 on the first dimension;
// offset = 0, size = 8, and a dynamic stride on the second dimension).
#CSR_SLICE = #sparse_tensor.encoding<{
map = (i : #sparse_tensor<slice(0, 4, 1)>,
j : #sparse_tensor<slice(0, 8, ?)>) ->
(i : dense, j : compressed)
}>
... tensor<?x?xf64, #CSR_SLICE> ...