L'encodage de Tensor creux est un attribut permettant d'encoder des informations sur les propriétés de parcimonie des Tensors, par la formalisation TACO des Tensors creux. Cet encodage est ensuite utilisé par une passe sparsifier pour générer du code creux de façon entièrement automatique à partir d'un représentation du calcul sans parcimonie, c'est-à-dire une représentation implicite est convertie en représentation creuse explicite où les boucles de co-itération fonctionnent sur un espace de stockage creux plutôt que des Tensors avec parcimonie l'encodage. Les passes de compilateur qui s'exécutent avant cette passe de sparsifier doivent prendre en compte de la sémantique des types de Tensor avec un tel encodage de parcimonie.

Dans cet encodage, nous utilisons dimension pour font référence aux axes du Tensor sémantique, et level pour faire référence aux axes du format de stockage réel, c'est-à-dire représentation opérationnelle du Tensor creux en mémoire. Le nombre de est généralement la même que le nombre de niveaux (format de stockage CSR, par exemple) ; Toutefois, l'encodage peut également mapper aux niveaux supérieurs (par exemple, pour encoder un format de stockage BSR creux par blocs) ou à des niveaux d'ordre inférieur (par exemple, pour linéariser les dimensions en tant que niveau unique dans l'espace de stockage).
L'encodage contient une carte qui fournit les éléments suivants:
- Séquence ordonnée de spécifications de dimensions, chacune définissant:
<ph type="x-smartling-placeholder">
- </ph>
- dimension-size (implicite d'après la forme de dimension du Tensor)
- Une expression-de-dimension
- Séquence ordonnée de spécifications de niveau, chacune comprenant un élément
level-type, qui définit la manière dont le niveau doit être stocké. Chaque type de niveau
se compose des éléments suivants:
<ph type="x-smartling-placeholder">
- </ph>
- Une expression de niveau, qui définit ce qui est stocké
- un level-format
- Un ensemble de propriétés de niveau qui s'appliquent au format de niveau
Chaque expression de niveau est une expression affine sur les variables de dimension. Ainsi, Les expressions "level-expressions" définissent collectivement affine la carte des coordonnées de dimension à coordonnées de niveau. Les expressions de dimension définissent collectivement la carte inverse, qui ne doit être fournie que pour les cas complexes où il est impossible de l'inférer automatiquement.
Chaque dimension peut également être associée à un SparseTensorDimSliceAttr facultatif.
Dans le format de stockage creux, nous faisons référence aux index stockés explicitement
en tant que coordonnées, et des décalages au format de stockage en tant que positions.
Les formats de niveaux acceptés sont les suivants:
- dense : toutes les entrées de ce niveau sont stockées
- compressed : seules les valeurs non nulles à ce niveau sont stockées.
- loose_compressed : sous forme compressée, mais permet un espace libre entre les régions
- singleton : variante du format compressé, dans lequel les coordonnées n'ont pas de frères.
- block2_4 : la compression utilise un encodage 2:4 par bloc 1x4.
Pour un niveau compressé, chaque intervalle de position est représenté dans un format compact
avec une limite inférieure pos(i) et une limite supérieure pos(i+1) - 1, ce qui implique
que les intervalles successifs doivent apparaître dans l'ordre, sans aucun "trou" entre
de l'IA générative. Le format compressé souple assouplit ces contraintes en représentant chaque
un intervalle de position avec une lo(i) de limite inférieure et une hi(i) de limite supérieure, qui
permet aux intervalles d'apparaître dans un ordre arbitraire et avec un espace entre eux.
Par défaut, chaque type de niveau a la propriété d'être unique (pas de doublons coordonnées à ce niveau) et ordonnées (les coordonnées apparaissent triées à ce niveau au niveau du projet). Les propriétés suivantes peuvent être ajoutées à un format de niveau pour modifier ce comportement par défaut:
- non unique : des coordonnées peuvent apparaître en double au niveau.
- nonordered : les coordonnées peuvent s'afficher dans l'ordre de l'arborescence.
En plus de la carte, les deux champs suivants sont facultatifs:
La largeur de bits requise pour le stockage de position (décalages entiers) dans le schéma de stockage creux). Une largeur étroite réduit la mémoire de stockage, tant que la largeur est suffisante définir la plage totale requise (autrement dit, le nombre maximal d'enregistrements entrées à tous les niveaux d'indirection). Les options sont
8,16,32,64ou0(valeur par défaut) pour indiquer la largeur de bits native.La largeur de bits requise pour le stockage des coordonnées (les coordonnées d'entrées stockées). Une largeur étroite réduit l'espace mémoire utilisé d'espace de stockage, tant que la largeur est suffisante pour définir la plage totale requise (voir la valeur maximale de chaque Tensor coordonnées à tous les niveaux). Les options sont
8,16,32,64, ou0par défaut pour indiquer un nombre de bits natif.
Exemples
Au format CSR(Compressed Sparse Row)
comme illustré ci-dessous, l'encodage de Tensor creux
serait:
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
Elle indique que first dimension (ligne) correspond à first level,
qui est un niveau dense, indiqué par la taille 4. Et le second dimension
(colonne) correspond à second level, indiqué par le tableau de positions et
de coordonnées. La valeur 3 ([1, 1] dans la matrice d'origine) est
représenté par le tableau "offset from positions" (nombre de ligne de la valeur 3
est 1 dans la matrice d'origine, car il s'agit de la deuxième paire de décalages
le numéro de colonne se trouve dans l'index [2 : 4) du tableau de coordonnées). Dans la section
le tableau de coordonnées géographiques, nous pouvons voir que le numéro de colonne de la valeur 3 est 1
la matrice d'origine.

Pour le format BSR(Block Sparse Row), le type de Tensor creux est le suivant:
#BSR = #sparse_tensor.encoding<{
map = (i, j) ->
( i floordiv 2 : dense
, j floordiv 2 : compressed
, i mod 2 : dense
, j mod 2 : dense
)
Prenons la matrice creuse suivante, avec des blocs 2x2:
Example 2x2 block storage:
+-----+-----+-----+ +-----+-----+-----+
| 1 2 | . . | 4 . | | 1 2 | | 4 0 |
| . 3 | . . | . 5 | | 0 3 | | 0 5 |
+-----+-----+-----+ => +-----+-----+-----+
| . . | 6 7 | . . | | | 6 7 | |
| . . | 8 . | . . | | | 8 0 | |
+-----+-----+-----+ +-----+-----+-----+
qui est finalement stocké au format TACO sous forme de
Stored as:
positions[1] : 0 2 3
coordinates[1] : 0 2 1
values : 1.000000 2.000000 0.000000 3.000000
4.000000 0.000000 0.000000 5.000000
6.000000 7.000000 8.000000 0.000000
Ce qui, à titre d'information, est Format de bloc NVidia présenté dans la documentation cuSparse
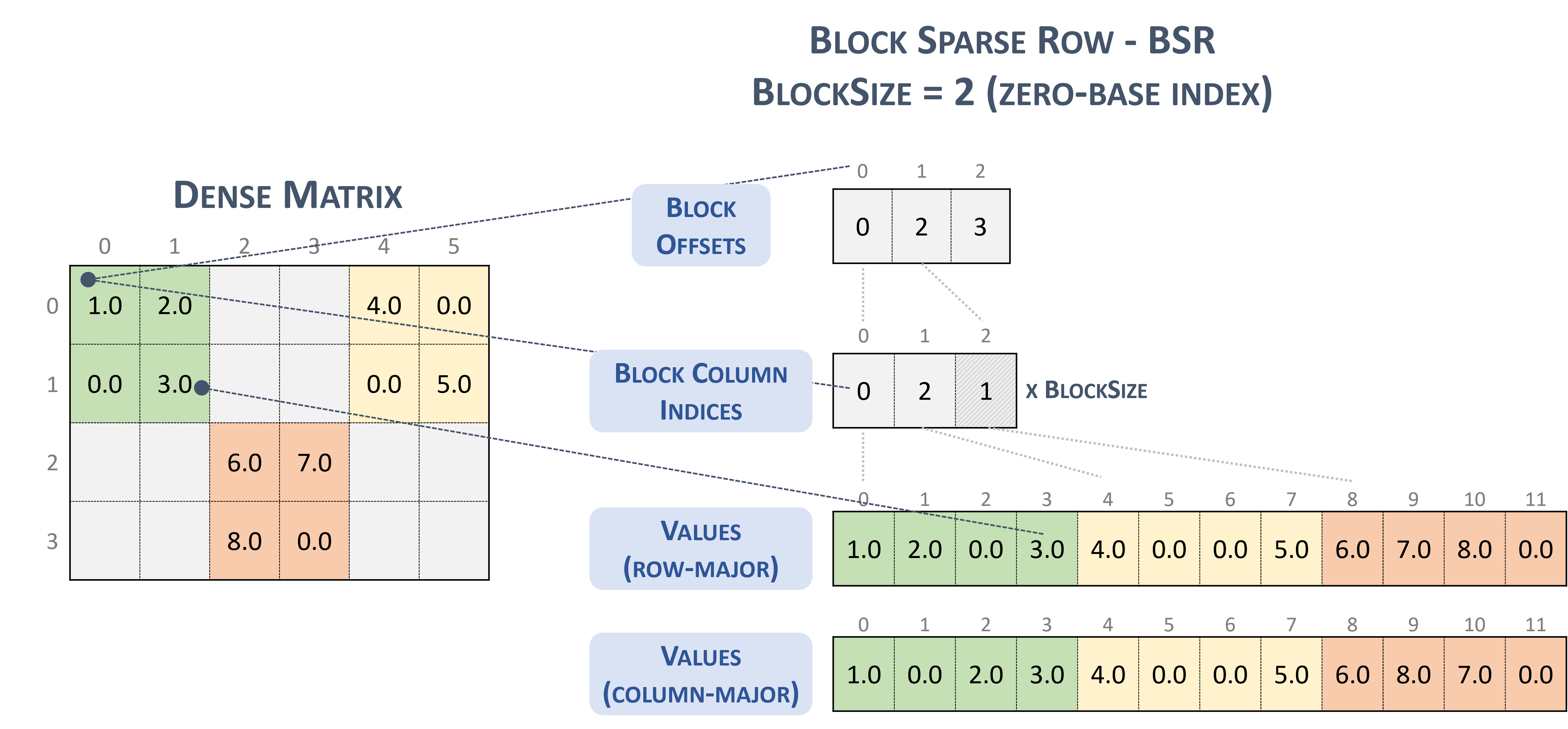
Bloquer la ligne creuse : (s.d.-b). Nvidia. https://docs.nvidia.com/cuda/cusparse/_images/bsr.png
Nous acceptons également Nvidia's 2:4 structured sparsity.
Pour ce faire, le type de Tensor creux est le suivant:
#NV_24 = #sparse_tensor.encoding<{
map = ( i, j ) -> ( i : dense,
j floordiv 4 : dense,
j mod 4 : block2_4),
crdWidth = 2 // 2-bits for each coordinate
}>
D'après l'exemple de matrice fourni dans la documentation NVidia:
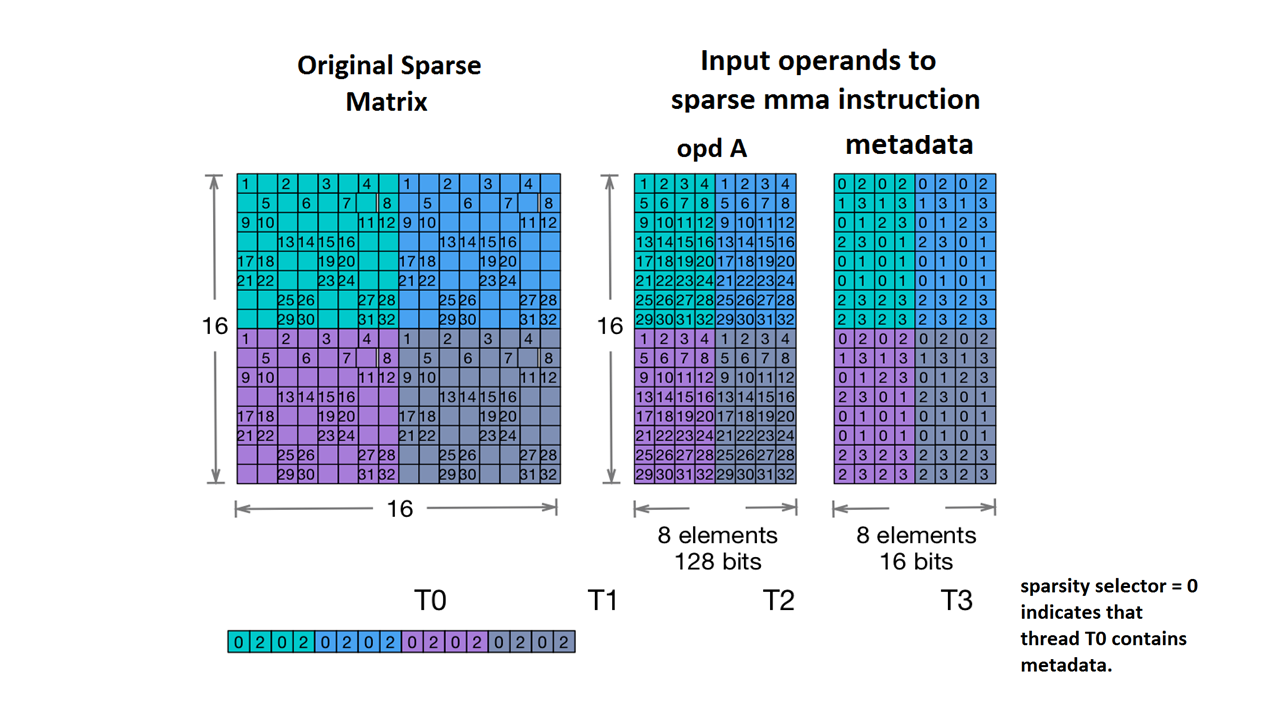
Exemple de stockage MMA creux. (s.d.). Nvidia. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-sparse-mma
Le MLIR mappe désormais cette matrice selon une mise en page identique:
coordinates[2] :
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
values :
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
Voici d'autres exemples :
// Sparse vector.
#SparseVector = #sparse_tensor.encoding<{
map = (i) -> (i : compressed)
}>
... tensor<?xf32, #SparseVector> ...
// Sorted coordinate scheme.
#SortedCOO = #sparse_tensor.encoding<{
map = (i, j) -> (i : compressed(nonunique), j : singleton)
}>
... tensor<?x?xf64, #SortedCOO> ...
// Batched sorted coordinate scheme, with high encoding.
#BCOO = #sparse_tensor.encoding<{
map = (i, j, k) -> (i : dense, j : compressed(nonunique, high), k : singleton)
}>
... tensor<10x10xf32, #BCOO> ...
// Compressed sparse row.
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
... tensor<100x100xbf16, #CSR> ...
// Doubly compressed sparse column storage with specific bitwidths.
#DCSC = #sparse_tensor.encoding<{
map = (i, j) -> (j : compressed, i : compressed),
posWidth = 32,
crdWidth = 8
}>
... tensor<8x8xf64, #DCSC> ...
// Block sparse row storage (2x3 blocks).
#BSR = #sparse_tensor.encoding<{
map = ( i, j ) ->
( i floordiv 2 : dense,
j floordiv 3 : compressed,
i mod 2 : dense,
j mod 3 : dense
)
}>
... tensor<20x30xf32, #BSR> ...
// Same block sparse row storage (2x3 blocks) but this time
// also with a redundant reverse mapping, which can be inferred.
#BSR_explicit = #sparse_tensor.encoding<{
map = { ib, jb, ii, jj }
( i = ib * 2 + ii,
j = jb * 3 + jj) ->
( ib = i floordiv 2 : dense,
jb = j floordiv 3 : compressed,
ii = i mod 2 : dense,
jj = j mod 3 : dense)
}>
... tensor<20x30xf32, #BSR_explicit> ...
// ELL format.
// In the simple format for matrix, one array stores values and another
// array stores column indices. The arrays have the same number of rows
// as the original matrix, but only have as many columns as
// the maximum number of nonzeros on a row of the original matrix.
// There are many variants for ELL such as jagged diagonal scheme.
// To implement ELL, map provides a notion of "counting a
// dimension", where every stored element with the same coordinate
// is mapped to a new slice. For instance, ELL storage of a 2-d
// tensor can be defined with the mapping (i, j) -> (#i, i, j)
// using the notation of [Chou20]. Lacking the # symbol in MLIR's
// affine mapping, we use a free symbol c to define such counting,
// together with a constant that denotes the number of resulting
// slices. For example, the mapping [c](i, j) -> (c * 3 * i, i, j)
// with the level-types ["dense", "dense", "compressed"] denotes ELL
// storage with three jagged diagonals that count the dimension i.
#ELL = #sparse_tensor.encoding<{
map = [c](i, j) -> (c * 3 * i : dense, i : dense, j : compressed)
}>
... tensor<?x?xf64, #ELL> ...
// CSR slice (offset = 0, size = 4, stride = 1 on the first dimension;
// offset = 0, size = 8, and a dynamic stride on the second dimension).
#CSR_SLICE = #sparse_tensor.encoding<{
map = (i : #sparse_tensor<slice(0, 4, 1)>,
j : #sparse_tensor<slice(0, 8, ?)>) ->
(i : dense, j : compressed)
}>
... tensor<?x?xf64, #CSR_SLICE> ...