স্পার্স টেনসর এনকোডিং হল টেনসরের স্পার্সিটি বৈশিষ্ট্যের তথ্য এনকোড করার একটি বৈশিষ্ট্য, যা স্পার্স টেনসরের TACO ফর্মালাইজেশন দ্বারা অনুপ্রাণিত। এই এনকোডিংটি শেষ পর্যন্ত একটি স্পার্সিফায়ার পাস দ্বারা গণনার একটি স্পার্সিটি-অজ্ঞেয়বাদী উপস্থাপনা থেকে সম্পূর্ণরূপে স্বয়ংক্রিয়ভাবে স্পার্স কোড তৈরি করতে ব্যবহৃত হয়, অর্থাৎ, একটি অন্তর্নিহিত স্পার্স উপস্থাপনা একটি স্পষ্ট স্পার্স উপস্থাপনায় রূপান্তরিত হয় যেখানে কো-ইটারেটিং লুপগুলি স্পার্স স্টোরেজ ফরম্যাটে কাজ করে একটি sparsity এনকোডিং সঙ্গে tensors. এই স্পার্সিফায়ার পাসের আগে চলা কম্পাইলার পাসগুলিকে এই ধরনের স্পার্সিটি এনকোডিং সহ টেনসর প্রকারের শব্দার্থবিদ্যা সম্পর্কে সচেতন হতে হবে।

এই এনকোডিং-এ, আমরা শব্দার্থিক টেনসরের অক্ষগুলি উল্লেখ করার জন্য মাত্রা ব্যবহার করি এবং প্রকৃত স্টোরেজ বিন্যাসের অক্ষগুলিকে বোঝাতে , অর্থাৎ, মেমরিতে স্পার্স টেনসরের অপারেশনাল উপস্থাপনা ব্যবহার করি। মাত্রার সংখ্যা সাধারণত স্তরের সংখ্যার (যেমন CSR স্টোরেজ বিন্যাস) সমান। যাইহোক, এনকোডিং উচ্চ-অর্ডার স্তরগুলিতে (উদাহরণস্বরূপ, একটি ব্লক-স্পার্স বিএসআর স্টোরেজ ফর্ম্যাট এনকোড করতে) বা নিম্ন-অর্ডার স্তরগুলিতে (উদাহরণস্বরূপ, স্টোরেজের একক স্তর হিসাবে মাত্রাগুলিকে লিনিয়ারাইজ করতে) ম্যাপ করতে পারে।
এনকোডিংটিতে একটি মানচিত্র রয়েছে যা নিম্নলিখিতগুলি প্রদান করে:
- মাত্রার স্পেসিফিকেশনের একটি আদেশকৃত ক্রম, যার প্রত্যেকটি সংজ্ঞায়িত করে:
- মাত্রা-আকার (টেনসরের মাত্রা-আকৃতি থেকে অন্তর্নিহিত)
- একটি মাত্রা-প্রকাশ
- লেভেল স্পেসিফিকেশনের একটি অর্ডারকৃত ক্রম, যার প্রত্যেকটিতে একটি প্রয়োজনীয় লেভেল-টাইপ অন্তর্ভুক্ত থাকে, যা লেভেলটি কীভাবে সংরক্ষণ করা উচিত তা নির্ধারণ করে। প্রতিটি স্তরের প্রকারের মধ্যে রয়েছে:
- একটি স্তর-অভিব্যক্তি , যা সংজ্ঞায়িত করে কী সংরক্ষিত হয়
- একটি স্তর বিন্যাস
- স্তর-বৈশিষ্ট্যের একটি সংগ্রহ যা লেভেল-ফর্ম্যাটে প্রযোজ্য
প্রতিটি স্তর-অভিব্যক্তি মাত্রা-ভেরিয়েবলের উপর একটি affine অভিব্যক্তি। এইভাবে, স্তর-অভিব্যক্তিগুলি সম্মিলিতভাবে মাত্রা-স্থানাঙ্ক থেকে স্তর-স্থানাঙ্কে একটি affine মানচিত্র সংজ্ঞায়িত করে। মাত্রা-অভিব্যক্তিগুলি সম্মিলিতভাবে বিপরীত মানচিত্রকে সংজ্ঞায়িত করে, যা শুধুমাত্র বিস্তৃত ক্ষেত্রে প্রদান করা প্রয়োজন যেখানে এটি স্বয়ংক্রিয়ভাবে অনুমান করা যায় না।
প্রতিটি মাত্রার একটি ঐচ্ছিক SparseTensorDimSliceAttr থাকতে পারে। স্পার্স স্টোরেজ ফরম্যাটের মধ্যে, আমরা সূচকগুলি উল্লেখ করি যেগুলি স্থানাঙ্ক হিসাবে স্পষ্টভাবে সংরক্ষণ করা হয় এবং অবস্থান হিসাবে স্টোরেজ বিন্যাসে অফসেট।
সমর্থিত স্তর-ফরম্যাটগুলি নিম্নরূপ:
- ঘন : এই স্তর বরাবর সব এন্ট্রি সংরক্ষণ করা হয়
- সংকুচিত : এই স্তর বরাবর শুধুমাত্র nonzeros সংরক্ষণ করা হয়
- loose_compressed : সংকুচিত হিসাবে, কিন্তু অঞ্চলগুলির মধ্যে ফাঁকা স্থানের অনুমতি দেয়
- singleton : সংকুচিত বিন্যাসের একটি বৈকল্পিক, যেখানে স্থানাঙ্কের কোনো ভাইবোন নেই
- block2_4 : কম্প্রেশন প্রতি 1x4 ব্লকে 2:4 এনকোডিং ব্যবহার করে
একটি সংকুচিত স্তরের জন্য, প্রতিটি অবস্থানের ব্যবধান একটি নিম্নবাউন্ড pos(i) এবং একটি ঊর্ধ্বমুখী pos(i+1) - 1 সহ একটি কম্প্যাক্ট উপায়ে উপস্থাপন করা হয়, যা বোঝায় যে ধারাবাহিক ব্যবধানগুলি তাদের মধ্যে কোনও "গর্ত" ছাড়াই ক্রমানুসারে উপস্থিত হতে হবে। . ঢিলেঢালা সংকুচিত বিন্যাস প্রতিটি অবস্থানের ব্যবধানকে একটি নিম্নবাউন্ড lo(i) এবং একটি ঊর্ধ্বমুখী hi(i) দিয়ে প্রতিনিধিত্ব করে এই সীমাবদ্ধতাগুলিকে শিথিল করে, যা ব্যবধানগুলিকে স্বেচ্ছাচারী ক্রমে এবং তাদের মধ্যে কনুই রুম সহ প্রদর্শিত হতে দেয়।
ডিফল্টরূপে, প্রতিটি স্তর-প্রকারের অনন্য হওয়ার বৈশিষ্ট্য রয়েছে (সেই স্তরে কোনও সদৃশ স্থানাঙ্ক নেই) এবং আদেশ করা হয়েছে (স্থানাঙ্কগুলি সেই স্তরে সাজানো প্রদর্শিত হবে)। এই ডিফল্ট আচরণ পরিবর্তন করতে একটি স্তর বিন্যাসে নিম্নলিখিত বৈশিষ্ট্য যোগ করা যেতে পারে:
- nonunique : ডুপ্লিকেট স্থানাঙ্ক স্তরে প্রদর্শিত হতে পারে
- nonordered : স্থানাঙ্কগুলি arbribratry ক্রমে প্রদর্শিত হতে পারে
মানচিত্র ছাড়াও, নিম্নলিখিত দুটি ক্ষেত্র ঐচ্ছিক:
অবস্থান সঞ্চয়ের জন্য প্রয়োজনীয় বিটউইথ (স্পার্স স্টোরেজ স্কিমের অবিচ্ছেদ্য অফসেট)। একটি সংকীর্ণ প্রস্থ ওভারহেড স্টোরেজের মেমরি পদচিহ্নকে কমিয়ে দেয়, যতক্ষণ পর্যন্ত প্রস্থটি মোট প্রয়োজনীয় পরিসীমা নির্ধারণ করতে যথেষ্ট (যেমন, সমস্ত পরোক্ষ স্তরে সঞ্চিত এন্ট্রির সর্বাধিক সংখ্যা)। পছন্দগুলি হল
8,16,32,64, বা, ডিফল্ট,0নেটিভ বিটউইথ নির্দেশ করতে।স্থানাঙ্ক সঞ্চয়ের জন্য প্রয়োজনীয় বিটউইথ (সঞ্চিত এন্ট্রিগুলির স্থানাঙ্ক)। একটি সংকীর্ণ প্রস্থ ওভারহেড স্টোরেজের মেমরি পদচিহ্নকে কমিয়ে দেয়, যতক্ষণ পর্যন্ত প্রস্থটি মোট প্রয়োজনীয় পরিসীমা নির্ধারণের জন্য যথেষ্ট (যেমন প্রতিটি স্তরে প্রতিটি টেনসর সমন্বয়ের সর্বোচ্চ মান)। পছন্দগুলি হল
8,16,32,64, বা, ডিফল্ট,0একটি নেটিভ বিটউইথ নির্দেশ করতে।
উদাহরণ
নিচে দেখানো CSR(Compressed Sparse Row) ফরম্যাটে, স্পার্স টেনসর এনকোডিং হবে:
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
এটি নির্দেশ করে যে first dimension (সারি) মানচিত্র first level , যা একটি dense স্তর, আকার 4 দ্বারা নির্দেশিত। এবং second dimension (কলাম) মানচিত্র second level , অবস্থান অ্যারে এবং স্থানাঙ্ক অ্যারে দ্বারা নির্দেশিত৷ মান 3 ( মূল ম্যাট্রিক্সে [1, 1] ) পজিশন অ্যারে থেকে অফসেট দ্বারা উপস্থাপিত হয় (মূল ম্যাট্রিক্সে 3 এর সারি সংখ্যা 1 কারণ এটি দ্বিতীয় অফসেট জোড়া এবং এর কলাম নম্বরটি সূচকে থাকে [2 : 4) স্থানাঙ্ক অ্যারে)। এবং স্থানাঙ্ক অ্যারেতে, আমরা দেখতে পাচ্ছি যে মান 3 এর কলাম নম্বর মূল ম্যাট্রিক্সে 1 ।

BSR(Block Sparse Row) ফরম্যাটের জন্য, স্পারস টেনসরের ধরন হল:
#BSR = #sparse_tensor.encoding<{
map = (i, j) ->
( i floordiv 2 : dense
, j floordiv 2 : compressed
, i mod 2 : dense
, j mod 2 : dense
)
2x2 ব্লক সহ নিম্নলিখিত স্পার্স ম্যাট্রিক্স বিবেচনা করুন:
Example 2x2 block storage:
+-----+-----+-----+ +-----+-----+-----+
| 1 2 | . . | 4 . | | 1 2 | | 4 0 |
| . 3 | . . | . 5 | | 0 3 | | 0 5 |
+-----+-----+-----+ => +-----+-----+-----+
| . . | 6 7 | . . | | | 6 7 | |
| . . | 8 . | . . | | | 8 0 | |
+-----+-----+-----+ +-----+-----+-----+
যা শেষ পর্যন্ত TACO-স্বাদ বিন্যাসে সংরক্ষণ করা হয়
Stored as:
positions[1] : 0 2 3
coordinates[1] : 0 2 1
values : 1.000000 2.000000 0.000000 3.000000
4.000000 0.000000 0.000000 5.000000
6.000000 7.000000 8.000000 0.000000
যা, ঘটনাক্রমে, আক্ষরিক অর্থে cuSparse ডকুমেন্টেশনে উপস্থাপিত NVidia ব্লক বিন্যাস।
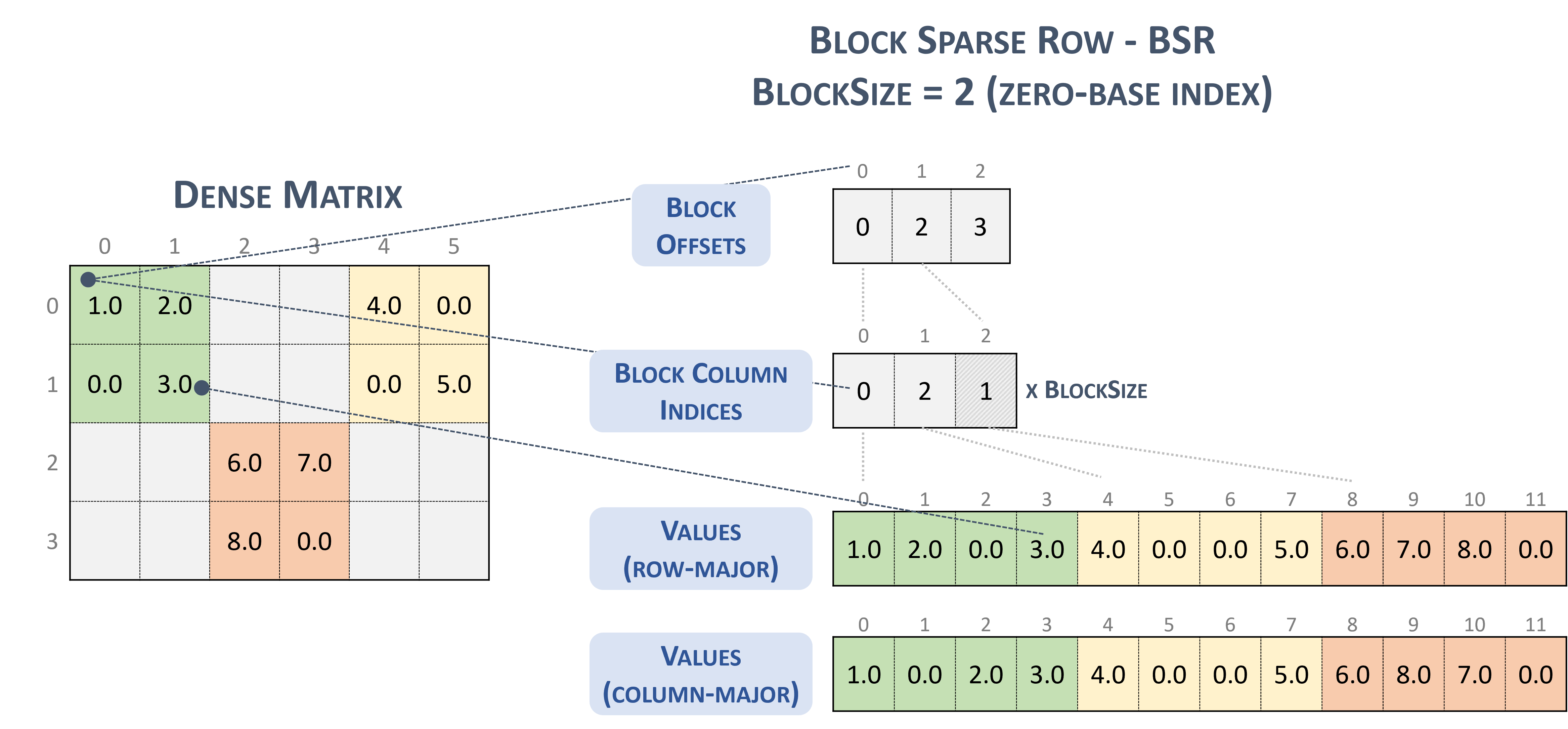
স্পার্স সারি ব্লক করুন । (nd-b)। এনভিডিয়া। https://docs.nvidia.com/cuda/cusparse/_images/bsr.png
এছাড়াও আমরা Nvidia's 2:4 structured sparsity সমর্থন করি।
এর জন্য স্পারস টেনসরের ধরনটি নিম্নরূপ:
#NV_24 = #sparse_tensor.encoding<{
map = ( i, j ) -> ( i : dense,
j floordiv 4 : dense,
j mod 4 : block2_4),
crdWidth = 2 // 2-bits for each coordinate
}>
NVidia ডকুমেন্টেশনে দেওয়া নমুনা ম্যাট্রিক্স দেওয়া হয়েছে:
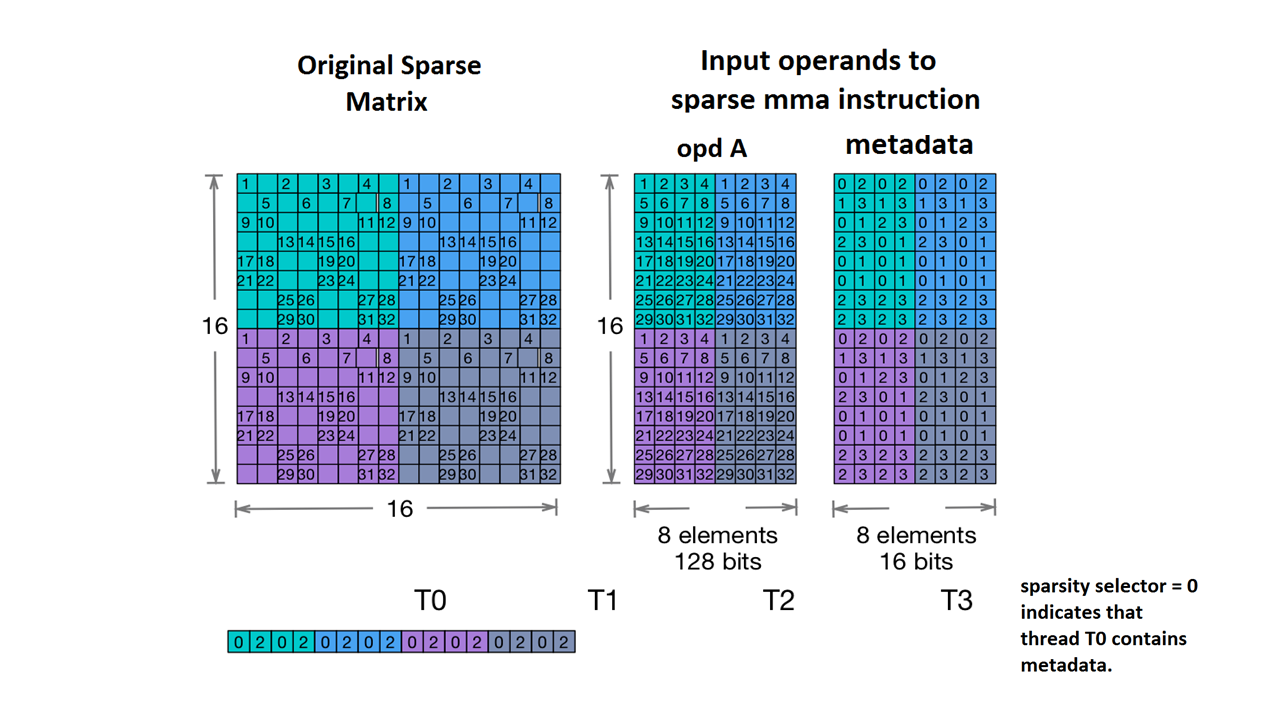
স্পার্স এমএমএ স্টোরেজ উদাহরণ । (nd)। এনভিডিয়া। https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-sparse-mma
MLIR এখন এই ম্যাট্রিক্সটিকে একটি অভিন্ন লেআউটে ম্যাপ করে:
coordinates[2] :
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
values :
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
আরো উদাহরণ:
// Sparse vector.
#SparseVector = #sparse_tensor.encoding<{
map = (i) -> (i : compressed)
}>
... tensor<?xf32, #SparseVector> ...
// Sorted coordinate scheme.
#SortedCOO = #sparse_tensor.encoding<{
map = (i, j) -> (i : compressed(nonunique), j : singleton)
}>
... tensor<?x?xf64, #SortedCOO> ...
// Batched sorted coordinate scheme, with high encoding.
#BCOO = #sparse_tensor.encoding<{
map = (i, j, k) -> (i : dense, j : compressed(nonunique, high), k : singleton)
}>
... tensor<10x10xf32, #BCOO> ...
// Compressed sparse row.
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
... tensor<100x100xbf16, #CSR> ...
// Doubly compressed sparse column storage with specific bitwidths.
#DCSC = #sparse_tensor.encoding<{
map = (i, j) -> (j : compressed, i : compressed),
posWidth = 32,
crdWidth = 8
}>
... tensor<8x8xf64, #DCSC> ...
// Block sparse row storage (2x3 blocks).
#BSR = #sparse_tensor.encoding<{
map = ( i, j ) ->
( i floordiv 2 : dense,
j floordiv 3 : compressed,
i mod 2 : dense,
j mod 3 : dense
)
}>
... tensor<20x30xf32, #BSR> ...
// Same block sparse row storage (2x3 blocks) but this time
// also with a redundant reverse mapping, which can be inferred.
#BSR_explicit = #sparse_tensor.encoding<{
map = { ib, jb, ii, jj }
( i = ib * 2 + ii,
j = jb * 3 + jj) ->
( ib = i floordiv 2 : dense,
jb = j floordiv 3 : compressed,
ii = i mod 2 : dense,
jj = j mod 3 : dense)
}>
... tensor<20x30xf32, #BSR_explicit> ...
// ELL format.
// In the simple format for matrix, one array stores values and another
// array stores column indices. The arrays have the same number of rows
// as the original matrix, but only have as many columns as
// the maximum number of nonzeros on a row of the original matrix.
// There are many variants for ELL such as jagged diagonal scheme.
// To implement ELL, map provides a notion of "counting a
// dimension", where every stored element with the same coordinate
// is mapped to a new slice. For instance, ELL storage of a 2-d
// tensor can be defined with the mapping (i, j) -> (#i, i, j)
// using the notation of [Chou20]. Lacking the # symbol in MLIR's
// affine mapping, we use a free symbol c to define such counting,
// together with a constant that denotes the number of resulting
// slices. For example, the mapping [c](i, j) -> (c * 3 * i, i, j)
// with the level-types ["dense", "dense", "compressed"] denotes ELL
// storage with three jagged diagonals that count the dimension i.
#ELL = #sparse_tensor.encoding<{
map = [c](i, j) -> (c * 3 * i : dense, i : dense, j : compressed)
}>
... tensor<?x?xf64, #ELL> ...
// CSR slice (offset = 0, size = 4, stride = 1 on the first dimension;
// offset = 0, size = 8, and a dynamic stride on the second dimension).
#CSR_SLICE = #sparse_tensor.encoding<{
map = (i : #sparse_tensor<slice(0, 4, 1)>,
j : #sparse_tensor<slice(0, 8, ?)>) ->
(i : dense, j : compressed)
}>
... tensor<?x?xf64, #CSR_SLICE> ...