ترميز Tensor المتناثر هو سمة لترميز المعلومات على خصائص تناثر مبدلات التوتر، من خلال إضفاء الطابع الرسمي على TACO للمتسابقات المتناثرة. سيتم استخدام هذا الترميز في النهاية من خلال تصريح sparsifier لإنشاء رمز متفرق بشكل تلقائي من تمثيلاً غير منطقي للعمليات الحسابية، بمعنى أن هناك بيانات متفرقة ضمنية يتم تحويله إلى تمثيل متناثر واضح حيث تعمل حلقات التكرار المشترك على مساحة تخزين متفرقة بدلاً من عناصر التوتر ذات التناثر الترميز. يجب أن تكون على دراية بكل تمريرة في برنامج تجميع المحتوى قبل إطلاقها دلالات أنواع متسابقات باستخدام هذا الترميز التناثر.

في هذا الترميز، نستخدم السمة وتشير إلى محاور المتوتر الدلالي، وlevel للإشارة إلى محاور تنسيق التخزين الفعلي، أي للتمثيل التشغيلي للموتر المتناثر في الذاكرة. عدد وأبعادها عادةً ما تكون هي نفسها عدد المستويات (مثل تنسيق تخزين CSR). ومع ذلك، يمكن أن يُعين التشفير أيضًا الأبعاد إلى مستويات طلبات أعلى (على سبيل المثال، لترميز تنسيق تخزين BSR منخفض الكتلة) أو إلى مستويات ذات ترتيب أقل (على سبيل المثال، لجعل السمات خطية كمستوى واحد في مساحة التخزين).
يتضمن التشفير خريطة توفر ما يلي:
- تسلسل مرتّب لمواصفات الأبعاد، يحدّد كلٌّ منها ما يلي:
- حجم البُعد (ضمني من شكل بُعد أداة تنسور)
- تعبيرًا عن السمة
- يشير هذا المصطلح إلى تسلسل مرتّب لمواصفات المستوى، ويتضمّن كل منها
level-type، التي تحدد كيفية تخزين المستوى. كل نوع مستوى
يتألف من:
- تعبير المستوى، الذي يحدّد ما يتم تخزينه
- تنسيق المستوى
- مجموعة من مواقع المستوى التي تنطبق على تنسيق المستوى
كل تعبير على مستوى هو تعبير تقارب عن متغيرات الأبعاد. وبالتالي، وتحدد تعبيرات المستوى بشكل جماعي خريطة ترابطية من إحداثيات البعد إلى إحداثيات المستوى. تعبيرات السمات ونحدد معًا الخريطة العكسية، والذي يجب تقديمه فقط في الحالات التي لا يمكن استنتاجها تلقائيًا.
ويمكن أن تحتوي كل سمة على SparseTensorDimSliceAttr اختيارية.
في إطار مساحة التخزين المتفرقة، نشير إلى الفهارس التي يتم تخزينها
الإحداثيات والإزاحة في تنسيق التخزين في شكل مواضع.
في ما يلي تنسيقات المستويات المتوافقة:
- dense : يتم تخزين جميع الإدخالات في هذا المستوى.
- مضغوط : يتم فقط تخزين القيم غير الصفرية على هذا المستوى.
- loose_compressed : كملف مضغوط، ولكنها تتيح مساحة خالية بين المناطق
- سينغلتون : صيغة مختلفة من التنسيق المضغوط، حيث لا يكون للإحداثيات أي أشقاء
- block2_4 : يستخدم الضغط ترميز 2:4 لكل كتلة 1×4.
بالنسبة للمستوى المضغوط، يتم تمثيل كل فاصل موضع في جدول مضغوط
قيمة الحد الأدنى pos(i) والحد الأقصى pos(i+1) - 1، ما يعني
أن الفواصل الزمنية المتتالية يجب أن تظهر بالترتيب بدون أي "ثقوب" في المنتصف
معهم. يخفف التنسيق المضغوط غير المضغوط هذه القيود من خلال تمثيل كل
فاصل موضع مع حد lo(i) منخفض وhi(i) حد أقصى، وهو
للسماح بظهور الفواصل بترتيب عشوائي مع وجود مساحة كافية بينها.
بشكل تلقائي، يتسم كل نوع مستوى بخاصية فريدة (أي أنه ليس مكررًا إحداثيات على هذا المستوى) ومرتبة (تظهر الإحداثيات مرتبة على ذلك المستوى). يمكن إضافة السمات التالية إلى تنسيق المستوى لتغييره. هذا السلوك الافتراضي:
- non unique : قد تظهر الإحداثيات المكررة على مستوى
- nonorder : قد تظهر الإحداثيات بترتيب الإشاعات.
بالإضافة إلى الخريطة، الحقلان التاليان اختياريان:
معدل نقل البيانات المطلوب لتخزين الموضع (إزاحة التكامل في نظام التخزين المتفرق). العرض الضيق يقلل حجم الذاكرة مساحة التخزين الخارجية، طالما أن العرض يكفي تحدد إجمالي النطاق المطلوب (أي الحد الأقصى لعدد الإدخالات على جميع المستويات غير المباشرة). الخيارات المتاحة هي
8و1632أو64أو السمة التلقائية0للإشارة إلى عرض البت الأصلي.معدل نقل البيانات المطلوب لتخزين الإحداثيات (الإحداثيات من الإدخالات المخزنة). تقليل مساحة العرض يقلل من تأثير الذاكرة من التخزين الزائد، ما دام العرض كافيًا لتحديد إجمالي النطاق المطلوب (بمعنى القيمة القصوى لكل متوتر والتنسيق على جميع المستويات). الخيارات المتاحة هي
8و16و32.64، أو0التلقائي للإشارة إلى عرض بت أصلي.
أمثلة
بتنسيق CSR(Compressed Sparse Row)
كما هو موضح أدناه، ترميز متنزس متفرق
سيكون:
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
ويشير إلى أنّ first dimension (الصف) يشير إلى first level.
وهو مستوى dense، ويُشار إليه بالحجم 4. وsecond dimension
يعيِّن (العمود) second level، ويشار إليه بمصفوفة المواضع
صفيفة الإحداثيات. القيمة 3 ([1, 1] في المصفوفة الأصلية) هي
يتم تمثيلها بواسطة الإزاحة من مصفوفة المواضع (القيمة رقم صف 3
هو 1 في المصفوفة الأصلية بما أنه زوج الإزاحة الثاني
في الفهرس [2 : 4) في صفيف الإحداثيات). وفي
يمكننا أن نرى أن رقم عمود 3 هو 1 في
المصفوفة الأصلية.

بالنسبة إلى التنسيق BSR(Block Sparse Row)، يكون نوع متسابق متفرق هو:
#BSR = #sparse_tensor.encoding<{
map = (i, j) ->
( i floordiv 2 : dense
, j floordiv 2 : compressed
, i mod 2 : dense
, j mod 2 : dense
)
بالنظر إلى المصفوفة المتناثرة التالية التي تضم كتل 2×2:
Example 2x2 block storage:
+-----+-----+-----+ +-----+-----+-----+
| 1 2 | . . | 4 . | | 1 2 | | 4 0 |
| . 3 | . . | . 5 | | 0 3 | | 0 5 |
+-----+-----+-----+ => +-----+-----+-----+
| . . | 6 7 | . . | | | 6 7 | |
| . . | 8 . | . . | | | 8 0 | |
+-----+-----+-----+ +-----+-----+-----+
والذي يتم تخزينه في النهاية بتنسيق بنكهة TACO
Stored as:
positions[1] : 0 2 3
coordinates[1] : 0 2 1
values : 1.000000 2.000000 0.000000 3.000000
4.000000 0.000000 0.000000 5.000000
6.000000 7.000000 8.000000 0.000000
والذي، بالصدفة، هو تنسيق كتلة NVidia المقدم في وثائق cuSparse.
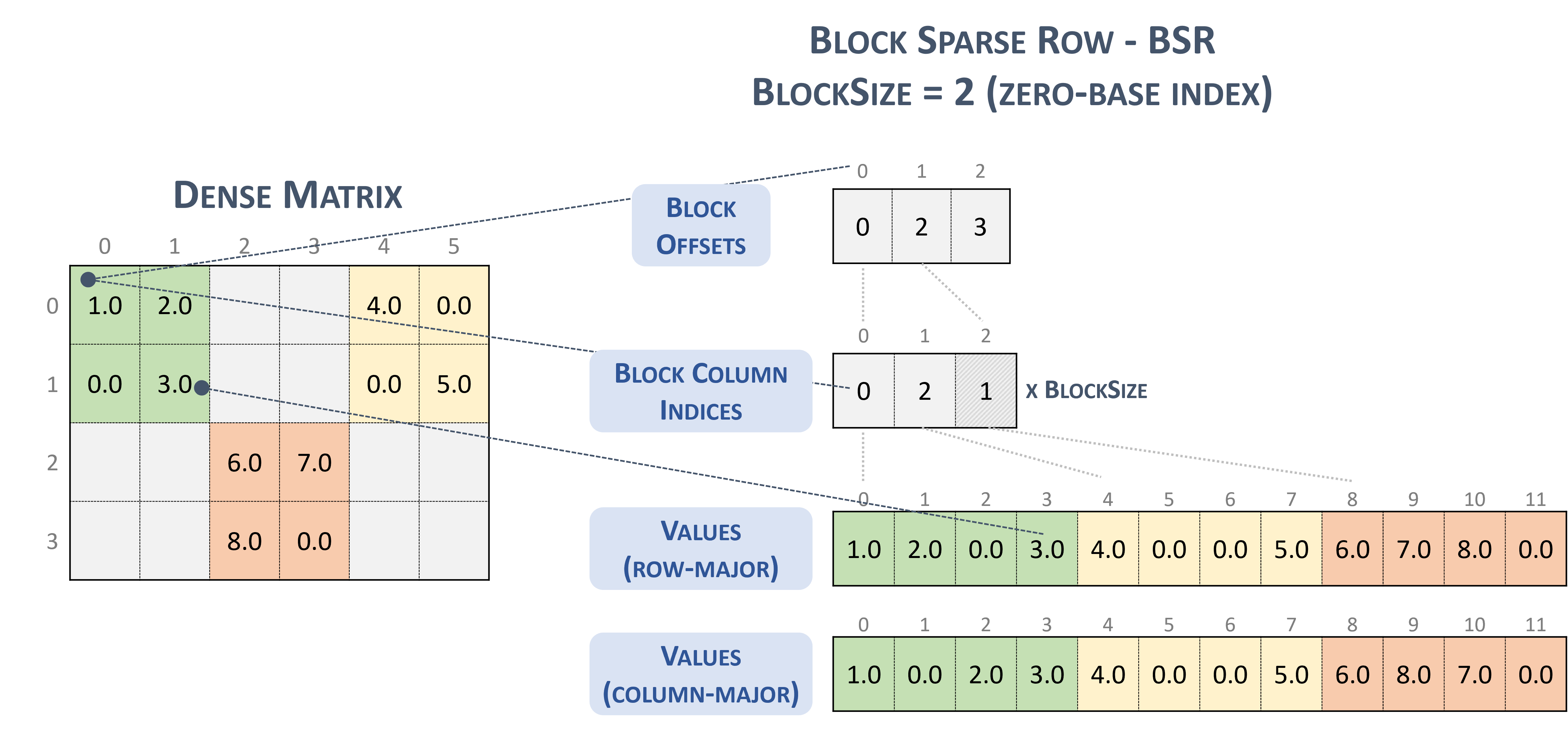
حظر صف متناثر: (n.d.-b). Nvidia. https://docs.nvidia.com/cuda/cusparse/_images/bsr.png
نتيح أيضًا استخدام السمة Nvidia's 2:4 structured sparsity.
في ما يلي نوع مؤشر التنس الموزِّع لهذا الغرض:
#NV_24 = #sparse_tensor.encoding<{
map = ( i, j ) -> ( i : dense,
j floordiv 4 : dense,
j mod 4 : block2_4),
crdWidth = 2 // 2-bits for each coordinate
}>
بالنظر إلى نموذج المصفوفة الواردة في وثائق NVidia:
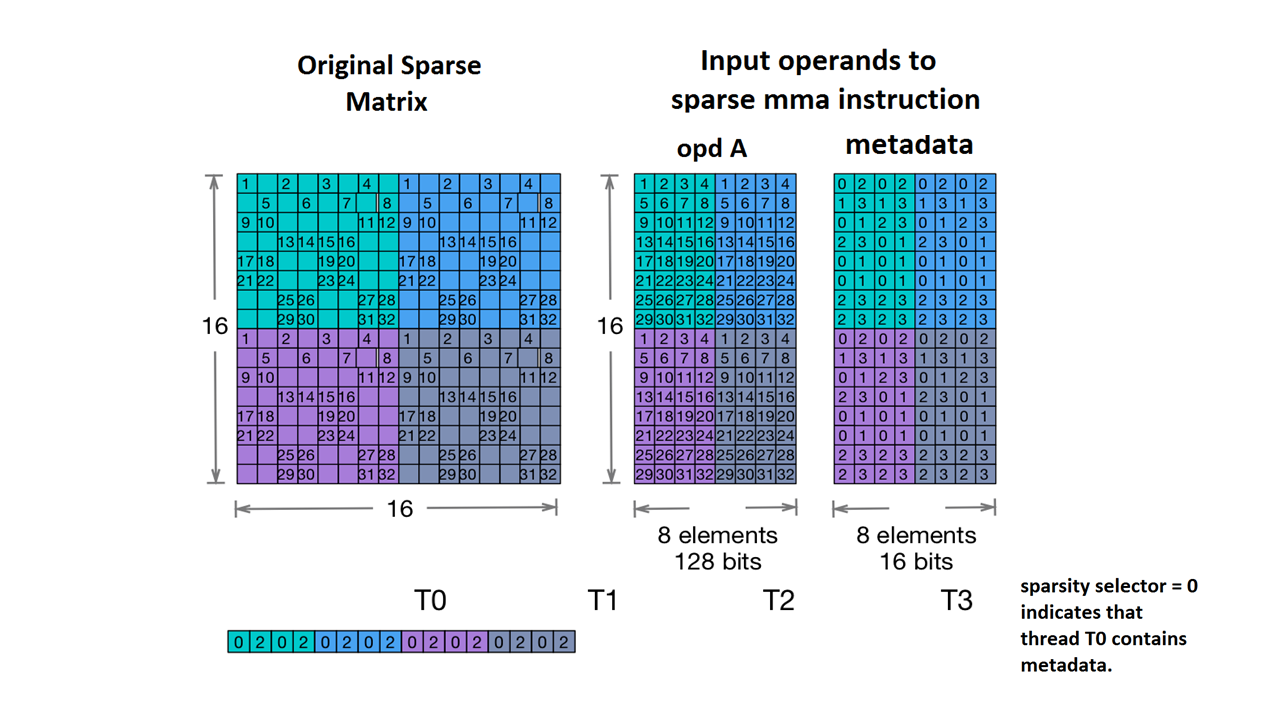
مثال على مساحة تخزين MMA قليلة. (بلا تاريخ) Nvidia. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-sparse-mma
يربط MLIR الآن هذه المصفوفة بتنسيق مماثل:
coordinates[2] :
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
values :
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
مزيد من الأمثلة:
// Sparse vector.
#SparseVector = #sparse_tensor.encoding<{
map = (i) -> (i : compressed)
}>
... tensor<?xf32, #SparseVector> ...
// Sorted coordinate scheme.
#SortedCOO = #sparse_tensor.encoding<{
map = (i, j) -> (i : compressed(nonunique), j : singleton)
}>
... tensor<?x?xf64, #SortedCOO> ...
// Batched sorted coordinate scheme, with high encoding.
#BCOO = #sparse_tensor.encoding<{
map = (i, j, k) -> (i : dense, j : compressed(nonunique, high), k : singleton)
}>
... tensor<10x10xf32, #BCOO> ...
// Compressed sparse row.
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
... tensor<100x100xbf16, #CSR> ...
// Doubly compressed sparse column storage with specific bitwidths.
#DCSC = #sparse_tensor.encoding<{
map = (i, j) -> (j : compressed, i : compressed),
posWidth = 32,
crdWidth = 8
}>
... tensor<8x8xf64, #DCSC> ...
// Block sparse row storage (2x3 blocks).
#BSR = #sparse_tensor.encoding<{
map = ( i, j ) ->
( i floordiv 2 : dense,
j floordiv 3 : compressed,
i mod 2 : dense,
j mod 3 : dense
)
}>
... tensor<20x30xf32, #BSR> ...
// Same block sparse row storage (2x3 blocks) but this time
// also with a redundant reverse mapping, which can be inferred.
#BSR_explicit = #sparse_tensor.encoding<{
map = { ib, jb, ii, jj }
( i = ib * 2 + ii,
j = jb * 3 + jj) ->
( ib = i floordiv 2 : dense,
jb = j floordiv 3 : compressed,
ii = i mod 2 : dense,
jj = j mod 3 : dense)
}>
... tensor<20x30xf32, #BSR_explicit> ...
// ELL format.
// In the simple format for matrix, one array stores values and another
// array stores column indices. The arrays have the same number of rows
// as the original matrix, but only have as many columns as
// the maximum number of nonzeros on a row of the original matrix.
// There are many variants for ELL such as jagged diagonal scheme.
// To implement ELL, map provides a notion of "counting a
// dimension", where every stored element with the same coordinate
// is mapped to a new slice. For instance, ELL storage of a 2-d
// tensor can be defined with the mapping (i, j) -> (#i, i, j)
// using the notation of [Chou20]. Lacking the # symbol in MLIR's
// affine mapping, we use a free symbol c to define such counting,
// together with a constant that denotes the number of resulting
// slices. For example, the mapping [c](i, j) -> (c * 3 * i, i, j)
// with the level-types ["dense", "dense", "compressed"] denotes ELL
// storage with three jagged diagonals that count the dimension i.
#ELL = #sparse_tensor.encoding<{
map = [c](i, j) -> (c * 3 * i : dense, i : dense, j : compressed)
}>
... tensor<?x?xf64, #ELL> ...
// CSR slice (offset = 0, size = 4, stride = 1 on the first dimension;
// offset = 0, size = 8, and a dynamic stride on the second dimension).
#CSR_SLICE = #sparse_tensor.encoding<{
map = (i : #sparse_tensor<slice(0, 4, 1)>,
j : #sparse_tensor<slice(0, 8, ?)>) ->
(i : dense, j : compressed)
}>
... tensor<?x?xf64, #CSR_SLICE> ...