학습률 및 수렴
이 실습은 여러 플레이그라운드 실습 중 첫 번째 실습입니다. 플레이그라운드는 머신러닝 원칙을 가르치기 위해 이 과정을 위해 특별히 개발되었습니다. 이 과정의 각 플레이그라운드 실습에는 포함된 플레이그라운드가 포함되어 있습니다. 사전 설정된 인스턴스입니다
각 플레이그라운드 연습에서는 데이터 세트를 생성합니다. 이 항목의 라벨 데이터 세트에는 두 개의 가능한 값이 있습니다. 이 두 가지는 스팸과 스팸이 아닌 나무 또는 건강한 나무와 병든 나무의 비교 값을 가질 수 있습니다. 대부분의 연습의 목표는 다양한 초매개변수를 조정하여 빌드하는 것입니다. 하나의 모델을 성공적으로 분류 (분리 또는 구분)하는 모델 다른 라벨 값을 선택할 수 있습니다. 대부분의 데이터 세트에는 노이즈의 양을 성공적으로 분류하지 못하게 하는 모든 예시를 보여줍니다.
모델 시각화에 대한 설명을 보려면 더하기 아이콘을 클릭하세요.
각 플레이그라운드 실습에는 현재 예측 가능한 모델의 상태입니다. 다음은 시각화의 예입니다.
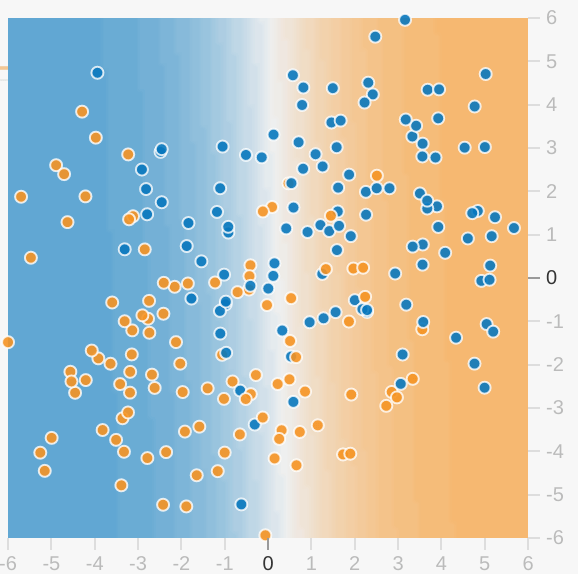
모델 시각화에 대해 다음 사항에 유의하세요.
- 각 축은 특정 특성을 나타냅니다. 스팸과 스팸이 아닌 경우 특성은 단어 수, 이메일 수신자 수 이메일
- 각 점은 다음과 같이 데이터의 한 가지 예에 대한 특성 값을 표시합니다. 이메일
- 점의 색상은 예가 속한 클래스를 나타냅니다. 예를 들어 파란색 점은 스팸이 아닌 이메일을 나타내고 주황색 점은 스팸 이메일을 나타냅니다.
- 배경 색상은 모델이 예측한 예의 위치를 나타냅니다. 찾아낼 수 있습니다. 파란색 점 주위에 파란색 배경 모델이 해당 예를 정확하게 예측한다는 의미입니다. 반대로 파란색 점 주위에 주황색 배경이 표시되면 모델이 잘못 예측한 것입니다
- 파란색과 주황색 배경은 조정됩니다. 예를 들어, 시각화가 파란색으로 계속 켜져 있지만 점차 가운데에서 흰색으로 흐려집니다. 볼 수 있습니다 색상 강도는 색상 강도를 나타내는 가중치를 할당합니다. 파란색으로 계속 켜져 있으면 모델이 하늘색은 모델이 그것의 추측에 대해 매우 확신하고 있음을 의미하고 신뢰도가 떨어질 수도 있습니다 (그림에 표시된 모델 시각화는 잘못된 예측이 될 수 있습니다)
시각화를 사용하여 모델의 진행 상황을 판단합니다. ('매우 좋음 - 대부분의 파란색 점 배경이 파란색입니다.' 또는 "이런! 파란색 점의 배경이 주황색입니다.') 색상 외에도 플레이그라운드 모델의 현재 손실도 숫자로 표시합니다. ("이런! 손실은 감소하지 않고 증가합니다.')
이 실습의 인터페이스는 세 가지 버튼을 제공합니다.
| 아이콘 | 이름 | 기능 |
|---|---|---|
|
|
재설정 | 반복을 0으로 재설정합니다. 모델에 있던 가중치를 재설정합니다. 있습니다. |
|
|
단계 | 반복을 한 단계 진행합니다. 반복할 때마다 모델은 때로는 미묘하게, 때로는 크게 변화합니다. |
|
|
재생성 | 새 데이터 세트를 생성합니다. 반복을 재설정하지 않습니다. |
첫 번째 플레이그라운드 실습에서는 학습률을 낮춥니다.
작업 1: 화면 오른쪽 상단의 학습률 메뉴를 플레이그라운드. 학습률이 3으로 매우 높게 지정되어 있습니다. 관찰 '단계'를 클릭하여 높은 학습률이 모델에 미치는 영향 10번 또는 20번 누르면 됩니다. 각 초기 반복을 반복할 때마다 모델이 크게 변화합니다. 심지어 앱이 약간 불안정해지거나 후에 나타납니다. 다음 라인도 실행 중인 것을 확인하세요. x1 및 x2에서 모델 시각화로 변경할 수 있습니다. Kubernetes의 이 선은 모델에서 해당 특성의 가중치를 나타냅니다. 다시 말해 굵은 선은 높은 가중치를 나타냅니다.
작업 2: 다음을 수행합니다.
- 재설정 버튼을 누릅니다.
- 학습률을 낮춥니다.
- 단계 버튼을 여러 번 누릅니다.
낮은 학습률이 수렴에 어떤 영향을 미쳤나요? 그런 다음 모델이 수렴하는 데 필요한 단계 수 및 모델이 얼마나 원활하게 모델이 점진적으로 수렴합니다. 보다 낮은 값을 실험하여 학습률과 일치합니다. 학습률이 너무 느려 쓸모가 없다고 생각하시나요? 실습 바로 아래에서 토론을 찾아보세요.)