Python में "str" नाम का पहले से मौजूद स्ट्रिंग क्लास मौजूद होता है जिसमें कई आसान सुविधाएं हैं (यहां "string" नाम का एक पुराना मॉड्यूल है, जिसका आपको इस्तेमाल नहीं करना चाहिए). स्ट्रिंग की लिटरल वैल्यू को डबल या सिंगल कोट में रखा जा सकता है. हालांकि, आम तौर पर सिंगल कोट का इस्तेमाल ज़्यादा किया जाता है. बैकस्लैश एस्केप, सिंगल और डबल कोट किए हुए लिटरल, दोनों में सामान्य तरीके से काम करता है -- उदा. \n \ \". डबल कोट की गई स्ट्रिंग की लिटरल वैल्यू में, बिना किसी झंझट के सिंगल कोट हो सकते हैं (उदाहरण के लिए, "मैंने यह नहीं किया"). इसी तरह, एक कोट में रखी गई स्ट्रिंग में डबल कोट हो सकते हैं. स्ट्रिंग लिटरल कई लाइनों में हो सकती है, लेकिन नई लाइन से बचने के लिए हर लाइन के आखिर में बैकस्लैश \ होना चाहिए. स्ट्रिंग की लिटरल वैल्यू, तीन कोट के अंदर """ या ''' में मौजूद टेक्स्ट की कई लाइनें हो सकती हैं.
Python स्ट्रिंग "अम्यूटेबल" होती हैं इसका मतलब है कि बनाए जाने के बाद उन्हें बदला नहीं जा सकता. Java स्ट्रिंग भी इस स्टाइल का इस्तेमाल करती है. स्ट्रिंग बदली नहीं जा सकती. इसलिए, हम कंप्यूट की गई वैल्यू दिखाने के लिए *नई* स्ट्रिंग बनाते हैं. उदाहरण के लिए, एक्सप्रेशन ('hello' + 'there') को दो स्ट्रिंग 'hello' में शामिल किया जाता है और 'ऐसे' और 'hellothere' नाम की एक नई स्ट्रिंग बनाता है.
किसी स्ट्रिंग में वर्णों को स्टैंडर्ड [ ] सिंटैक्स का इस्तेमाल करके ऐक्सेस किया जा सकता है. Java और C++ की तरह, Python शून्य-आधारित इंडेक्सिंग का इस्तेमाल करता है. इसलिए, अगर s का मान 'hello' होता है s[1] का मतलब 'e' है. अगर इंडेक्स, स्ट्रिंग की सीमा से बाहर है, तो Python एक गड़बड़ी दिखाता है. Python स्टाइल (Perl के उलट) अगर यह नहीं बताए कि क्या करना है, तो इसे रोकना है, न कि सिर्फ़ डिफ़ॉल्ट वैल्यू बनाने के बजाय. आसान "स्लाइस" सिंटैक्स (नीचे) किसी स्ट्रिंग से किसी सबस्ट्रिंग को एक्सट्रैक्ट करने के लिए भी काम करता है. Len(string) फ़ंक्शन, स्ट्रिंग की लंबाई दिखाता है. [ ] सिंटैक्स और len() फ़ंक्शन असल में किसी भी क्रम प्रकार -- स्ट्रिंग, सूचियां वगैरह पर काम करते हैं.. Python, अलग-अलग तरह के डेटा पर अपने ऑपरेशन को लगातार काम करने की कोशिश करता है. Python नौसिखिया गॉचा: "Len" का इस्तेमाल न करें Len() फ़ंक्शन को ब्लॉक करने से बचने के लिए, वैरिएबल नाम के तौर पर. '+' ऑपरेटर दो स्ट्रिंग जोड़ सकता है. नीचे दिए गए कोड में ध्यान दें कि वैरिएबल पहले से तय नहीं किए गए हैं -- बस उन्हें असाइन करें और जाएं.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Java के विपरीत, '+' संख्याओं या अन्य टाइप को अपने-आप स्ट्रिंग के फ़ॉर्म में नहीं बदलता. str() फ़ंक्शन, वैल्यू को स्ट्रिंग के रूप में बदल देता है, ताकि उन्हें अन्य स्ट्रिंग के साथ जोड़ा जा सके.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
संख्याओं के लिए, स्टैंडर्ड ऑपरेटर, +, /, * सामान्य तरीके से काम करते हैं. कोई ++ ऑपरेटर नहीं है, लेकिन +=, -= वगैरह काम करते हैं. अगर आप पूर्णांक विभाजन चाहते हैं, तो 2 स्लैश का उपयोग करें -- उदा. 6 // 5 1 है
"प्रिंट" फ़ंक्शन आम तौर पर एक या उससे ज़्यादा Python आइटम प्रिंट करता है. इसके बाद एक नई लाइन होती है. एक "रॉ" स्ट्रिंग की शुरुआत में 'r' लगा होता है और बैकस्लैश के विशेष इलाज के बिना सभी वर्ण पार कर देता है, इसलिए r'x\nx' लंबाई-4 स्ट्रिंग 'x\nx' का मूल्यांकन करता है. "प्रिंट" यह चीज़ों को प्रिंट करने के तरीके को बदलने के लिए कई तर्क ले सकता है (python.org प्रिंट फ़ंक्शन की परिभाषा देखें) जैसे "end" सेटिंग चालू की जा रही है से "" ताकि सभी आइटम प्रिंट करने के बाद नई पंक्ति प्रिंट न हो.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
स्ट्रिंग के तरीके
यहां स्ट्रिंग के सबसे आम तरीकों के बारे में बताया गया है. तरीका किसी फ़ंक्शन की तरह होता है, लेकिन वह "चालू" होता है कोई ऑब्जेक्ट. अगर वैरिएबल s कोई स्ट्रिंग है, तो कोड s.lower() उस स्ट्रिंग ऑब्जेक्ट पर Low() वाला तरीका इस्तेमाल करता है और नतीजा दिखाता है. किसी ऑब्जेक्ट पर चलने वाले तरीके का यह आइडिया, उन बेसिक आइडिया में से एक है जिनसे ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग और ओओपी बनता है. यहां स्ट्रिंग के सबसे आम तरीकों के बारे में बताया गया है:
- s.lower(), s.upper() -- स्ट्रिंग के अंग्रेज़ी के छोटे या बड़े अक्षरों वाला वर्शन दिखाता है
- s.strip() -- शुरू और आखिर से खाली सफ़ेद जगह वाली स्ट्रिंग दिखाता है
- s.isalpha()/s.isडिजिट()/s.isspace()... -- जांच करता है कि सभी स्ट्रिंग वर्ण अलग-अलग वर्ण क्लास में हैं या नहीं
- s.startswith('other'), s.endswith('other') -- यह जांच करता है कि स्ट्रिंग, दी गई अन्य स्ट्रिंग से शुरू होती है या उस पर खत्म होती है
- s.find('other') -- s के अंदर दी गई अन्य स्ट्रिंग (रेगुलर एक्सप्रेशन नहीं) की खोज करता है और जहां से यह शुरू होता है वहां पहला इंडेक्स या नहीं मिलने पर -1 दिखाता है
- s.replace('old', 'new') -- वह स्ट्रिंग दिखाता है जिसमें 'old' की सभी घटनाएं होती हैं को 'नए' से बदल दिया गया है
- s.split('delim') -- दिए गए डेलिमिटर से अलग की गई सबस्ट्रिंग की सूची देता है. डीलिमिटर कोई रेगुलर एक्सप्रेशन नहीं है, यह सिर्फ़ टेक्स्ट है. 'aaa,bbb,फ़ोकस'.split(',') -> ['aaa', 'bbb', ' फ़ोकस']. एक सुविधाजनक खास केस के तौर पर, s.split() (बिना किसी तर्क के) सभी खाली सफ़ेद जगह पर बंट जाता है.
- s.join(list) -- {8}() के सामने, स्ट्रिंग का इस्तेमाल करके डीलिमिटर के तौर पर, दी गई सूची में मौजूद एलिमेंट को एक साथ जोड़ता है. उदाहरण के लिए, '---'.join(['aaa', 'bbb', 'टीसी']) -> aaa---bbb---ccc
"Python str" के लिए Google पर खोज आपको आधिकारिक python.org स्ट्रिंग तरीके पर ले जाया जाएगा, जिसमें सभी str मेथड की सूची होगी.
Python में अलग से कोई वर्ण टाइप नहीं होता. इसके बजाय, s[8] जैसा एक्सप्रेशन, वर्ण वाली स्ट्रिंग की लंबाई-1 देता है. स्ट्रिंग-length-1 के साथ, ऑपरेटर ==, <=, ... आपकी उम्मीद के मुताबिक काम करते हैं, इसलिए ज़्यादातर आपको यह जानने की ज़रूरत नहीं है कि Python के लिए अलग से कोई स्केलर "char" नहीं होता टाइप करें.
स्ट्रिंग स्लाइस
"स्लाइस" सिंटैक्स, सीक्वेंस के सब-पार्ट के बारे में बताने का एक आसान तरीका है -- आम तौर पर, स्ट्रिंग और लिस्ट. स्लाइस s[start:end] ऐसा एलिमेंट है जो शुरुआत से शुरू होता है और आगे तक फैला होता है. हालांकि, इसमें एंड एलिमेंट शामिल नहीं होता. मान लीजिए कि हमारे पास s = "नमस्ते" है
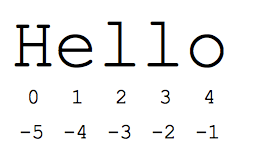
- s[1:4] 'ell' है -- इंडेक्स 1 से शुरू होने वाले और इंडेक्स 4 तक बढ़ाए गए वर्ण, लेकिन इंडेक्स 4 को शामिल नहीं करते हैं
- s[1:] 'ello' है -- किसी भी इंडेक्स को डिफ़ॉल्ट तौर पर स्ट्रिंग के प्रारंभ या अंत में छोड़ने पर
- s[:] 'नमस्ते' है -- दोनों को छोड़ने से हमें हमेशा पूरी चीज़ की एक कॉपी मिल जाती है (यह किसी स्ट्रिंग या सूची जैसे अनुक्रम को कॉपी करने का पाइथोनिक तरीका है)
- s[1:100] 'ello' है -- बहुत बड़ा इंडेक्स स्ट्रिंग लंबाई तक छोटा कर दिया जाता है
स्टैंडर्ड शून्य-आधारित इंडेक्स नंबर, स्ट्रिंग की शुरुआत के पास वर्णों को आसानी से ऐक्सेस करने की सुविधा देते हैं. एक विकल्प के तौर पर, Python, स्ट्रिंग के आखिर में वर्णों को आसानी से ऐक्सेस करने के लिए, नेगेटिव नंबर का इस्तेमाल करता है: s[-1] आखिरी वर्ण 'o' है और s[-2] 'l' होता है अगला वर्ण, और इसी तरह जारी रहेगा. नेगेटिव इंडेक्स नंबर को स्ट्रिंग के आखिर से गिना जाता है:
- s[-1] 'o' है -- आखिरी वर्ण (आखिर से पहला)
- s[-4] 'e' है -- आख़िर से चौथा
- s[:-3] 'He' है -- आखिरी तीन वर्णों तक जाना, लेकिन शामिल नहीं करना.
- s[-3:] 'llo' है -- अंत से तीसरे वर्ण से शुरू करके स्ट्रिंग के अंत तक फैली होती है.
यह किसी भी इंडेक्स n, s[:n] + s[n:] == s के लिए स्लाइस की सटीक सच्चाई है. यह n नेगेटिव या दूसरी सीमाओं के लिए भी काम करता है. इसके अलावा, दूसरा तरीका यह है कि s[:n] और s[n:] स्ट्रिंग को हमेशा दो स्ट्रिंग हिस्सों में बांटें, जिसमें सभी वर्ण सुरक्षित हों. जैसा कि हम बाद में सूची सेक्शन में देखेंगे, स्लाइस भी सूचियों के साथ काम करते हैं.
स्ट्रिंग फ़ॉर्मैटिंग
Python एक शानदार चीज़ कर सकता है, वह है ऑब्जेक्ट को अपने-आप प्रिंट करने के लिए उपयुक्त स्ट्रिंग. ऐसा करने के दो पहले से मौजूद तरीके फ़ॉर्मैट की गई स्ट्रिंग हैं लिटरल, जिसे "f-strings" और str.format() को शुरू करना भी कहा जाता है.
फ़ॉर्मैट की गई स्ट्रिंग की लिटरल वैल्यू
आपको इन स्थितियों में अक्सर फ़ॉर्मैट की गई स्ट्रिंग की लिटरल वैल्यू दिखेंगी:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
फ़ॉर्मैट की गई लिटरल स्ट्रिंग की शुरुआत 'f' से होती है (जैसे रॉ स्ट्रिंग के लिए इस्तेमाल किया जाने वाला 'r' प्रीफ़िक्स). कर्ली ब्रैकेट '{}' के बाहर का कोई भी टेक्स्ट दस्तावेज़ को सीधे प्रिंट किया जाता है. '{}' में शामिल एक्सप्रेशन हैं प्रिंट करने के लिए फ़ॉर्मैट की खास जानकारी दी गई है. फ़ॉर्मैटिंग की मदद से, छोटे-छोटे बहुत काम किए जा सकते हैं. जैसे, काट-छांट करना और को साइंटिफ़िक नोटेशन और बाएं/दाएं/सेंटर अलाइनमेंट में बदलने की सुविधा मिलती है.
f-स्ट्रिंग तब बहुत काम आती हैं, जब आपको ऑब्जेक्ट की टेबल को प्रिंट करना हो और अलग-अलग ऑब्जेक्ट एट्रिब्यूट को दिखाने वाले कॉलम, जिन्हें अलाइन किया जाना है
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
स्ट्रिंग %
Python में किसी स्ट्रिंग को एक साथ रखने के लिए, Printf() जैसी पुरानी सुविधा भी मौजूद है. % ऑपरेटर बाईं ओर एक Printf-type फ़ॉर्मैट स्ट्रिंग (%d int, %s स्ट्रिंग, %f/%g फ़्लोटिंग पॉइंट) और दाईं ओर के ट्यूपल में मिलान करने वाली वैल्यू लेता है (एक ट्यूपल, कॉमा से अलग की गई वैल्यू से बना होता है, जो आम तौर पर ब्रैकेट में ग्रुप होता है):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
ऊपर दी गई लाइन एक तरह की लंबी है -- मान लीजिए कि आपको इसे अलग-अलग लाइन में बांटना है. आप '%' के बाद केवल पंक्ति को विभाजित नहीं कर सकते जैसा कि अन्य लैंग्वेज में होता है, क्योंकि डिफ़ॉल्ट रूप से Python हर लाइन को एक अलग स्टेटमेंट की तरह मानता है (प्लस साइड पर, इसलिए हमें हर लाइन में सेमी-कोलन लिखने की ज़रूरत नहीं होती). इसे ठीक करने के लिए, पूरे एक्सप्रेशन को ब्रैकेट के बाहरी सेट में बंद करें -- फिर एक्सप्रेशन को एक से ज़्यादा लाइनों में फैलाना होगा. कोड-अक्रॉस-लाइन तकनीक नीचे बताए गए अलग-अलग ग्रुपिंग कंस्ट्रक्ट के साथ काम करती है: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
यह बेहतर है, लेकिन लाइन अब भी थोड़ी लंबी है. Python से, एक लाइन को छोटे-छोटे टुकड़ों में काटने की सुविधा मिलती है. इसके बाद, ये अपने-आप जुड़ जाते हैं. इस लाइन को और छोटा करने के लिए, हम यह काम कर सकते हैं:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
स्ट्रिंग (यूनिकोड बनाम बाइट)
सामान्य Python स्ट्रिंग यूनिकोड होती हैं.
Python, प्लेन बाइट से बनी स्ट्रिंग के साथ भी काम करता है (किसी स्ट्रिंग की लिटरल वैल्यू के सामने 'b' प्रीफ़िक्स से दिखाया जाता है) पसंद:
> byte_string = b'A byte string' > byte_string b'A byte string'
यूनिकोड स्ट्रिंग, बाइट स्ट्रिंग से अलग तरह का ऑब्जेक्ट होता है, लेकिन इसमें कई लाइब्रेरी होती हैं, जैसे कि किसी भी तरह की स्ट्रिंग पास करने पर रेगुलर एक्सप्रेशन सही तरीके से काम करता है.
किसी सामान्य Python स्ट्रिंग को बाइट में बदलने के लिए, स्ट्रिंग पर encode() तरीके को कॉल करें. दूसरी दिशा में जाने पर, बाइट स्ट्रिंग decode() वाला तरीका, कोड में बदली गई प्लेन बाइट को यूनिकोड स्ट्रिंग में बदल देता है:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
फ़ाइल-रीडिंग सेक्शन में, एक उदाहरण दिया गया है. इसमें, कोड में बदलने के तरीके वाली टेक्स्ट फ़ाइल को खोलने और यूनिकोड स्ट्रिंग को पढ़ने का तरीका दिखाया गया है.
अगर स्टेटमेंट
Python, if/loops/फ़ंक्शन वगैरह के लिए कोड के ब्लॉक को बंद करने के लिए { } का इस्तेमाल नहीं करता. इसके बजाय, Python, स्टेटमेंट को ग्रुप करने के लिए कोलन (:) और इंडेंटेशन/व्हाइटस्पेस का इस्तेमाल करता है. if के लिए बूलियन टेस्ट का ब्रैकेट (C++/Java से बड़ा अंतर) में होना ज़रूरी नहीं है. साथ ही, इसमें *elif* और *else* क्लॉज़ हो सकते हैं (स्मरणिक: शब्द "elif" शब्द "else" शब्द के बराबर है).
किसी भी वैल्यू को if-test के तौर पर इस्तेमाल किया जा सकता है. "शून्य" सभी वैल्यू को गलत के तौर पर गिना जाता है: कोई नहीं, 0, खाली स्ट्रिंग, खाली सूची, खाली शब्दकोश. बूलियन टाइप भी होता है, जिसकी दो वैल्यू होती हैं: True और False (Int में बदली जाने वाली वैल्यू 1 और 0 होती है). Python में तुलना के लिए सामान्य ऑपरेशन होते हैं: ==, !=, <, <=, >, >=. Java और C के उलट, स्ट्रिंग के साथ सही तरीके से काम करने के लिए == ओवरलोड हो जाता है. बूलियन ऑपरेटर, *और*, *या*, *न* लिखे गए शब्दों को कहते हैं. Python, C-style && { ! का इस्तेमाल नहीं करता. यहां बताया गया है कि दिन भर पीने की चीज़ों से जुड़े सुझाव देने वाले सेहत से जुड़े ऐप्लिकेशन के लिए कोड कैसा दिखेगा -- ध्यान दें कि फिर/अन्य स्टेटमेंट का हर एक ब्लॉक : से कैसे शुरू होता है और स्टेटमेंट को उनके इंडेंट के हिसाब से ग्रुप में बांटा जाता है:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
मुझे लगता है कि चलाने के बारे में ज़्यादा जानकारी मौजूद है. ऊपर दिए गए कोड को टाइप करते समय, सिंटैक्स में होने वाली मेरी सबसे आम गलती है. ऐसा शायद इसलिए है, क्योंकि यह मेरी C++/Java की आदतों के मुकाबले टाइप करने की एक अतिरिक्त चीज़ है. साथ ही, बूलियन टेस्ट को ब्रैकेट में न डालें -- यह एक C/Java आदत है. अगर कोड छोटा है, तो आप " के बाद उसी लाइन में कोड रख सकते हैं", इस तरह (यह फ़ंक्शन, लूप वगैरह पर भी लागू होता है), हालांकि कुछ लोगों को लगता है कि चीज़ों को अलग-अलग लाइन में रखना ज़्यादा आसान है.
if time_hour < 10: print('coffee') else: print('water')
व्यायाम: string1.py
इस सेक्शन के कॉन्टेंट की प्रैक्टिस करने के लिए, सामान्य कसरतों में string1.py कसरत करें.