ב-Python יש מחלקה מובנית של מחרוזת בשם "str" עם תכונות שימושיות רבות (יש מודול ישן יותר בשם 'מחרוזת' שבו לא כדאי להשתמש). ליטרלים של מחרוזת יכולים להיות מוקפים במירכאות כפולות או בודדות, אם כי השימוש במירכאות בודדות הוא נפוץ יותר. תווי בריחה של לוכסן הפוך פועלים כרגיל גם בליטרל יחיד וגם במירכאות כפולות - לדוגמה: \n \' \" . ליטרל של מחרוזת במירכאות כפולות יכול להכיל מירכאות בודדות ללא מאמץ (למשל, "לא אני עשיתי את זה") וכן, מחרוזת יחידה עם מירכאות כפולות יכולה להכיל מירכאות כפולות. ליטרל מחרוזת יכול להתפרס על פני מספר שורות, אבל חייב להיות לוכסן הפוך \ בסוף כל שורה כדי לסמן בתו בריחה (escape) את השורה החדשה. ליטרלים של מחרוזת בתוך מירכאות משולשות, """ או '', יכולים להתפרס על פני כמה שורות טקסט.
מחרוזות Python לא ניתנות לשינוי כלומר, לא ניתן לשנות אותם אחרי שיוצרים אותם (גם מחרוזות Java משתמשות בסגנון הזה שלא ניתן לשינוי). מכיוון שלא ניתן לשנות מחרוזות, אנחנו יוצרים מחרוזות *חדשות* כדי לייצג ערכים מחושבים. לדוגמה, הביטוי ('hello' + 'there') מקבל את 2 המחרוזות 'hello' ו'שם' ויוצרים מחרוזת חדשה 'hellothere'.
ניתן לגשת לתווים במחרוזת באמצעות התחביר הרגיל [ ], כמו ב-Java ו-C++ ב-Python נעשה שימוש באינדקס אפס, כך שאם s מוגדר 'hello' s[1] הוא e. אם האינדקס מחוץ לתחום למחרוזת, Python יציג שגיאה. סגנון Python (בניגוד ל-Perl) נעצר אם הוא לא יודע מה לעשות, במקום להמציא ערך ברירת מחדל. ה"פרוסה" השימושית התחביר (בהמשך) פועל גם לחילוץ כל מחרוזת משנה ממחרוזת. הפונקציה len(string) מחזירה את האורך של מחרוזת. למעשה, התחביר [ ] והפונקציה len() פועלים בכל סוג של רצף – מחרוזות, רשימות וכו'. שפת Python מנסה לגרום לפעולות שלה לפעול באופן עקבי בסוגים שונים. Python newbie getcha: לא להשתמש ב-"len" בתור שם של משתנה, כדי למנוע חסימה של הפונקציה len() . הסימן '+' האופרטור יכול לשרשר שתי מחרוזות. בקוד שבהמשך שימו לב לכך שמשתנים לא מוצהרים מראש. פשוט מקצים להם וממשיכים.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
בניגוד ל-Java, הסימן '+' לא ממירה באופן אוטומטי מספרים או סוגים אחרים למחרוזת. הפונקציה str() ממירה ערכים למחרוזת כדי שאפשר יהיה לשלב אותם עם מחרוזות אחרות.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
במספרים: האופרטורים הרגילים, +, /, * פועלים כרגיל. אין אופרטור ++ אבל +=, -= וכו'. אם רוצים לחלק מספרים שלמים, צריך להשתמש בשני לוכסנים, למשל: 6 // 5 הוא 1
"הדפסה" בדרך כלל הפונקציה מדפיסה פריט python אחד או יותר ואחריו שורה חדשה. A "גולמי" ליטרל המחרוזת מופיע בקידומת 'r' ומעביר את כל התווים ללא טיפול מיוחד בלוכסנים הפוכים, כך ש-r'x\nx'. הפונקציה מחזירה את האורך 4 של המחרוזת 'x\nx'. "הדפסה" יכולים להיות כמה ארגומנטים כדי לשנות את האופן שבו הוא מדפיס דברים (ראו הגדרה של פונקציית ההדפסה python.org) כמו הגדרת "end" אל "" לא תדפיס יותר שורה חדשה אחרי שתסתיים הדפסת כל הפריטים.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
שיטות שקשורות למחרוזות
לפניכם כמה משיטות המחרוזת הנפוצות ביותר. שיטה היא כמו פונקציה, אבל היא רצה 'on' לאובייקט. אם המשתנה s הוא מחרוזת, הקוד s.lower() מפעיל את השיטה lower() על אובייקט המחרוזת הזה ומחזיר את התוצאה (הרעיון הזה של שיטה שפועלת על אובייקט הוא אחד מהרעיונות הבסיסיים שמרכיבים את התכנות Object Oriented, OOP). לפניכם כמה משיטות המחרוזת הנפוצות ביותר:
- s.lower(), s.upper() – החזרת הגרסה של המחרוזת עם אותיות קטנות או גדולות
- s.strip() – מחזירה מחרוזת עם רווח לבן שהוסר מההתחלה ומהסוף
- s.isalpha()/s.isdigital()/s.isspace()... -- הפונקציה בודקת אם כל תרשימי המחרוזת הם בסוגי התווים השונים
- s.startswith('other'), s.endswith('other') – בדיקה אם המחרוזת מתחילה או מסתיימת במחרוזת הנתונה
- s.find('other') -- המערכת מחפשת את המחרוזת האחרת הנתונה (לא ביטוי רגולרי) בתוך s, ומחזירה את האינדקס הראשון שבו הוא מתחיל או -1 אם הוא לא נמצא
- s.replace('old', 'new') -- מחזירה מחרוזת שבה כל המופעים של 'old' הוחלפו ב-'new'
- s.split('delim') -- מחזירה רשימה של מחרוזות משנה שמופרדות באמצעות התו המפריד הנתון. התו המפריד הוא לא ביטוי רגולרי, הוא רק טקסט. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. כמקרה מיוחד s.split() (ללא ארגומנטים), מתפצלת כל התווים ברווח לבן.
- s.join(list) -- מול ה-Split(), מצרף את הרכיבים ברשימה הנתונה יחד באמצעות המחרוזת כתו מפריד. לדוגמה '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
חיפוש Google אחר "python str" אמורות להוביל אתכם אל השיטות הרשמיות של מחרוזת python.org, שבהן מפורטות כל שיטות ה-str.
ל-Python אין סוג תו נפרד. במקום זאת, ביטוי כמו s[8] מחזיר ערך string-length-1 שמכיל את התו. עם המחרוזת-length-1 הזו, האופרטורים ==, <=, ... פועלים כצפוי, לכן בעיקר לא צריך לדעת של-Python אין 'צ'אר' סקלרי נפרד. מהסוג הזה.
פרוסות מחרוזת
ה'פרוסה' התחביר הוא דרך נוחה להתייחס לחלקי משנה של רצפים – בדרך כלל מחרוזות ורשימות. החלק s [start:end] הוא הרכיבים שמתחילים בהתחלה ונמשכים עד הסוף, אבל לא כוללים את הסוף. נניח שיש לנו s = "Hello"
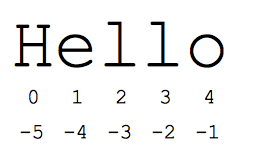
- s[1:4] הוא 'ell' -- תווים המתחילים באינדקס 1 ונמשכים עד אינדקס 4, אך לא כוללים אותו
- s[1:] הוא 'ello' -- השמטת ברירת המחדל של אחד מהאינדקסים היא תחילת המחרוזת או סוף המחרוזת
- s[:] זה 'שלום' -- השמטת שניהם תמיד תיתן לנו עותק של השלם (זו הדרך הפיתונית להעתיק רצף כמו מחרוזת או רשימה)
- s[1:100] הוא 'ello' -- אינדקס גדול מדי נחתך עד לאורך המחרוזת
מספרי האינדקס הרגילים שמבוססים על אפס מספקים גישה קלה לתווים בתחילת המחרוזת. לחלופין, Python משתמש במספרים שליליים כדי לאפשר גישה קלה לתווים שבסוף המחרוזת: s[-1] הוא התו האחרון 'o', s[-2] הוא 'l' את התו הבא, וכן הלאה. מספרי אינדקס שליליים נספרים חזרה מסוף המחרוזת:
- s[-1] הוא 'o' -- התו האחרון (1 מהסוף)
- s[-4] הוא e -- הרביעי מהסוף
- s[:-3] הוא 'הוא' -- עולה עד אך לא כולל את 3 התווים האחרונים.
- s[-3:] הוא 'llo' -- מתחיל בתו השלישי מהסוף ונמשך עד לסוף המחרוזת.
זוהי טכניקה פשוטה של פרוסות שעבור כל אינדקס n, s[:n] + s[n:] == s. הדבר פועל גם עבור n שלילי או מחוץ לתחום. אפשרות אחרת: s[:n] ו-s[n:] תמיד יחלקו את המחרוזת לשני חלקי מחרוזות, תוך שמירה על כל התווים. כפי שנראה בהמשך בקטע הרשימה, פלחים פועלים גם עם רשימות.
עיצוב מחרוזות
דבר קטן אחד ש-python יכול לעשות הוא להמיר אובייקטים באופן אוטומטי מחרוזת שמתאימה להדפסה. יש שתי דרכים מובנות לעשות את זה, הן בפורמט של מחרוזת מילוליים, שנקראים גם 'f-strings', והפעלת str.format().
ייצוג מילולי של מחרוזת בפורמט
הרבה פעמים, ייצוגים מילוליים של מחרוזות מופיעים במצבים כמו:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
התחילית של מחרוזת מילולית בפורמט 'f' היא 'f'. (כמו הקידומת 'r' שמשמשת למחרוזות גולמיות). טקסט מחוץ לסוגריים מסולסלים '{}' הוא מודפס ישירות. ביטויים הכלולים ב-'{}' הן מדפיסים בעזרת מפרט הפורמט שמתואר מפרט הפורמט. יש הרבה דברים נחמדים שאפשר לעשות עם העיצוב, כולל חיתוך לסימון מדעי ויישור לשמאל/ימינה/למרכז.
מחרוזות f הן שימושיות מאוד כשרוצים להדפיס טבלה של אובייקטים העמודות שמייצגות מאפייני אובייקטים שונים ליישור כמו
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
% מחרוזת
ב-Python יש גם מתקן ישן יותר דמוי Printf() , שבו אפשר להרכיב מחרוזת. האופרטור % לוקח מחרוזת של פורמט Printf בצד שמאל (%d int, מחרוזת %s, נקודה צפה של %f/%g), ואת הערכים התואמים ב-tuple בצד ימין (צבעוני מורכב מערכים שמופרדים בפסיקים, שמקובצים בדרך כלל בתוך סוגריים):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
השורה שלמעלה די ארוכה – נניח שרוצים לחלק אותה לשורות נפרדות. לא ניתן פשוט לפצל את הקו אחרי ה-'%' כפי שקורה בשפות אחרות, מכיוון שכברירת מחדל Python מתייחס לכל שורה כהצהרה נפרדת (בצד השני, זו הסיבה שאנחנו לא צריכים להקליד נקודה ופסיק בכל שורה). כדי לתקן את הבעיה הזו, צריך לתחום את הביטוי כולו בקבוצה חיצונית של סוגריים – ואז אפשר להתפרס על פני מספר שורות. השיטה הזו של מעבר בין שורות פועלת עם מבנים שונים של קיבוץ, שמפורטים בהמשך: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
עדיף, אבל השורה עדיין ארוכה במקצת. בעזרת Python אפשר לחתוך שורה למעלה למקטעים, ואז לשרשר אותם באופן אוטומטי. כדי שהשורה הזו תהיה קצרה עוד יותר, נוכל לעשות את זה:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
מחרוזות (Unicode לעומת בייטים)
מחרוזות Python רגילות הן Unicode.
שפת Python תומכת גם במחרוזות שמורכבות מבייטים פשוטים (מסומנים על ידי הקידומת 'b' לפני ליטרל של מחרוזת) כמו:
> byte_string = b'A byte string' > byte_string b'A byte string'
מחרוזת Unicode היא סוג אובייקט שונה ממחרוזת בייט, אבל ספריות שונות כמו ביטויים רגולריים פועלים בצורה תקינה אם הם מועברים מאחד מסוגי המחרוזת.
כדי להמיר מחרוזת Python רגילה לבייטים, צריך להפעיל את השיטה encode() במחרוזת. בכיוון השני, שיטת פענוח קוד (()decode של מחרוזת בייטים) ממירה בייטים פשוטים מקודדים למחרוזת Unicode:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
בקטע של קריאת קבצים, יש דוגמה שמראה איך לפתוח קובץ טקסט בקידוד מסוים ולקרוא מחרוזות Unicode.
אם דוח
ב-Python לא נעשה שימוש ב-{ } כדי לתחום בלוקים של קוד עבור if/loops/function וכו'. במקום זאת, שפת Python משתמשת בנקודתיים (:) ובכניסות פסקה/רווח לבן כדי לקבץ הצהרות. המבחן הבוליאני של if לא צריך להופיע בסוגריים (הפרש גדול מ-C++/Java), והוא יכול לכלול סעיפים *elif* ו-*else* (מינון: אורך המילה "elif" זהה למילה "else").
כל ערך יכול לשמש כ-if-test. ערך ה-"אפס" ערכים כולם נספרים כ-false: ללא, 0, מחרוזת ריקה, רשימה ריקה, מילון ריק. יש גם סוג בוליאני עם שני ערכים: True ו-False (מומרים ל-in, ל-1 ול-0). פעולות ההשוואה הרגילות של Python הן: ==, !=, <, <=, >, >=. בניגוד ל-Java ו-C, == עמוס מדי כדי לעבוד כראוי עם מחרוזות. האופרטורים הבוליאניים הם המילים המאויתות *and*, *or*, *not* (ב-Python לא נעשה שימוש בסגנון C && || !). כך הקוד עשוי להיראות עבור אפליקציית בריאות שמספקת המלצות למשקאות במהלך היום – שימו לב איך כל קטע של הצהרות מסוג 'אז/אחר' מתחיל ב-: וההצהרות מקובצות לפי כניסה שלהן:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
לדעתי, השמטה של ":" הוא שגיאת התחביר הכי נפוצה שלי כשאני מקליד את הקוד מהסוג הזה, כנראה כי זה דבר נוסף שצריך להקליד לעומת הרגלי C++/Java שלי. כמו כן, אל תכניסו את הבדיקה הבוליאנית בסוגריים – זהו הרגלי C/Java. אם הקוד קצר, אפשר להוסיף את הקוד באותה השורה אחרי ":", כך (זה חל גם על פונקציות, לולאות וכו'), אם כי יש אנשים שמרגישים שעדיף להזין דברים בשורות נפרדות.
if time_hour < 10: print('coffee') else: print('water')
תרגיל: string1.py
כדי לתרגל את החומר בקטע הזה, נסו את התרגיל string1.py בתרגילים בסיסיים.