پایتون یک کلاس رشته داخلی به نام "str" با بسیاری از ویژگی های مفید دارد (یک ماژول قدیمی به نام "string" وجود دارد که نباید از آن استفاده کنید). لفظ های رشته ای را می توان با دو یا تک نقل قول محصور کرد، اگرچه از گیومه های تکی بیشتر استفاده می شود. اسلشهای بک اسلش به روش معمول در هر دو لفظ نقلقولشده تکی و دوگانه کار میکنند - به عنوان مثال \n \' \". رشته میتواند شامل دو نشاندهنده باشد از متن
رشته های پایتون "تغییر ناپذیر" هستند، به این معنی که نمی توان آنها را پس از ایجاد تغییر داد (رشته های جاوا نیز از این سبک تغییرناپذیر استفاده می کنند). از آنجایی که رشتهها را نمیتوان تغییر داد، رشتههای *جدید* را میسازیم تا مقادیر محاسبهشده را نشان دهیم. بنابراین برای مثال عبارت ('hello' + 'there') دو رشته 'hello' و 'there' را می گیرد و یک رشته جدید 'hellother' می سازد.
کاراکترهای یک رشته با استفاده از دستور استاندارد [ ] قابل دسترسی هستند، و مانند جاوا و C++، پایتون از نمایه سازی مبتنی بر صفر استفاده می کند، بنابراین اگر s 'hello' باشد s[1] 'e' است. اگر ایندکس خارج از محدوده رشته باشد، پایتون خطایی ایجاد می کند. سبک پایتون (برخلاف پرل) این است که اگر نتواند بگوید چه کاری باید انجام دهد، متوقف میشود، نه اینکه فقط یک مقدار پیشفرض ایجاد کند. نحو مفید "slice" (در زیر) همچنین برای استخراج هر زیر رشته ای از یک رشته کار می کند. تابع len(string) طول یک رشته را برمی گرداند. نحو [ ] و تابع len() در واقع روی هر نوع دنباله ای کار می کنند - رشته ها، لیست ها و غیره. پایتون سعی می کند عملیات خود را به طور مداوم در انواع مختلف انجام دهد. Python newbie gotcha: برای جلوگیری از مسدود کردن تابع len() از "len" به عنوان نام متغیر استفاده نکنید. عملگر '+' می تواند دو رشته را به هم متصل کند. در کد زیر توجه کنید که متغیرها از قبل اعلام نشده اند -- فقط به آنها اختصاص دهید و بروید.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
برخلاف جاوا، '+' به طور خودکار اعداد یا انواع دیگر را به شکل رشته ای تبدیل نمی کند. تابع str() مقادیر را به شکل رشته ای تبدیل می کند تا بتوان آنها را با رشته های دیگر ترکیب کرد.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
برای اعداد، عملگرهای استاندارد +، /، * به روش معمول کار می کنند. عملگر ++ وجود ندارد، اما +=، -= و غیره کار می کنند. اگر تقسیم عدد صحیح می خواهید، از 2 اسلش استفاده کنید - مثلا 6 // 5 برابر 1 است
تابع "print" معمولاً یک یا چند آیتم پایتون را به دنبال یک خط جدید چاپ می کند. یک رشته «خام» با یک «r» پیشوند داده میشود و همه نویسهها را بدون برخورد خاصی با اسلشهای معکوس عبور میدهد، بنابراین r'x\nx به طول-4 رشته «x\nx» ارزیابی میشود. "print" می تواند چندین آرگومان برای تغییر نحوه چاپ اشیاء داشته باشد (به تعریف تابع چاپ python.org مراجعه کنید) مانند تنظیم "end" روی "" تا دیگر پس از اتمام چاپ همه موارد، خط جدیدی چاپ نشود.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
روش های رشته ای
در اینجا برخی از رایج ترین روش های رشته ای آورده شده است. یک متد مانند یک تابع است، اما "روی" یک شی اجرا می شود. اگر متغیر s یک رشته باشد، کد s.lower() متد low() را روی آن شی رشته اجرا می کند و نتیجه را برمی گرداند (این ایده متدی که بر روی یک شی اجرا می شود یکی از ایده های اساسی است که Object را می سازد. برنامه نویسی گرا، OOP). در اینجا برخی از رایج ترین روش های رشته ای آورده شده است:
- s.lower()، s.upper() -- نسخه کوچک یا بزرگ رشته را برمی گرداند.
- s.strip() -- رشته ای را با فضای خالی از ابتدا و انتهای آن حذف می کند
- s.isalpha()/s.isdigit()/s.isspace()... -- تست می کند که آیا همه کاراکترهای رشته در کلاس های کاراکتر مختلف هستند یا خیر
- s.startswith('other'), s.endswith('other') -- آزمایش می کند که آیا رشته با رشته داده شده دیگر شروع یا پایان می یابد
- s.find('other') -- رشته دیگر داده شده (نه یک عبارت منظم) را در s جستجو می کند و اولین فهرست را از جایی که شروع می کند یا -1 را در صورت یافت نشدن برمی گرداند.
- s.replace('old', 'new') -- رشته ای را برمی گرداند که در آن همه رخدادهای 'old' با 'new' جایگزین شده اند.
- s.split('delim') -- لیستی از رشته های فرعی را که توسط جداکننده داده شده از هم جدا شده اند را برمی گرداند. جداکننده یک عبارت منظم نیست، فقط یک متن است. 'aaa,bbb,ccc'.split(',') -> ['aaa'، 'bbb'، 'ccc']. به عنوان یک مورد خاص مناسب، s.split() (بدون آرگومان) روی همه کاراکترهای فضای خالی تقسیم می شود.
- s.join(list) -- در مقابل split()، عناصر موجود در لیست داده شده را با استفاده از رشته به عنوان جداکننده به یکدیگر می پیوندد. به عنوان مثال '--'. join(['aaa'، 'bbb'، 'ccc']) -> aaa---bbb---ccc
جستجوی Google برای "python str" باید شما را به روش های رشته رسمی python.org هدایت کند که تمام متدهای str را فهرست می کند.
پایتون نوع کاراکتر جداگانه ای ندارد. در عوض عبارتی مانند s[8] یک رشته طول-1 حاوی کاراکتر را برمی گرداند. با آن string-length-1، عملگرهای ==، <=، ... همگی همانطور که انتظار دارید کار می کنند، بنابراین بیشتر لازم نیست بدانید که پایتون یک نوع اسکالر جداگانه "char" ندارد.
برش رشته
نحو "برش" یک راه مفید برای ارجاع به بخش های فرعی از دنباله ها است - معمولاً رشته ها و لیست ها. برش s[start:end] عناصری است که از ابتدا شروع میشوند و تا پایان گسترش مییابند اما شامل پایان نمیشوند. فرض کنید s = "Hello" داریم
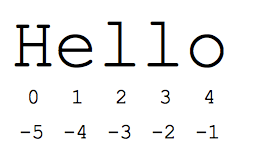
- s[1:4] «الل» است -- کاراکترهایی که از شاخص 1 شروع می شوند و تا شاخص 4 گسترش می یابند اما شامل آن نمی شوند.
- s[1:] 'ello' است -- حذف هر یک از ایندکسهای پیشفرض در ابتدا یا انتهای رشته
- s[:] "Hello" است -- حذف هر دو همیشه یک کپی از کل چیز را به ما می دهد (این روش پایتونیک برای کپی کردن یک دنباله مانند یک رشته یا لیست است)
- s [1:100] 'ello' است -- شاخصی که خیلی بزرگ است به طول رشته کوتاه می شود
اعداد شاخص مبتنی بر صفر استاندارد دسترسی آسان به کاراکترهای نزدیک به ابتدای رشته را می دهد. به عنوان جایگزین، پایتون از اعداد منفی برای دسترسی آسان به نویسههای انتهای رشته استفاده میکند: s[-1] آخرین char 'o'، s[-2] 'l' بعدی به آخرین است. کاراکتر و غیره اعداد شاخص منفی از انتهای رشته به عقب می شمارند:
- s[-1] 'o' است -- آخرین کاراکتر (اول از پایان)
- s[-4] 'e' است -- 4 از انتها
- s[:-3] 'او' است -- به 3 کاراکتر آخر می رود اما شامل نمی شود.
- s[-3:] 'llo' است -- که با کاراکتر 3 از انتها شروع می شود و تا انتهای رشته ادامه می یابد.
این یک حقیقت واقعی از برش ها است که برای هر شاخص n، s[:n] + s[n:] == s . این حتی برای n منفی یا خارج از محدوده کار می کند. یا به روش دیگری s[:n] و s[n:] همیشه رشته را به دو قسمت رشته تقسیم کنید و همه کاراکترها را حفظ کنید. همانطور که بعداً در بخش لیست خواهیم دید، برش ها با لیست ها نیز کار می کنند.
قالب بندی رشته
یکی از کارهای تمیزی که پایتون می تواند انجام دهد این است که به طور خودکار اشیا را به رشته ای مناسب برای چاپ تبدیل می کند. دو روش داخلی برای انجام این کار عبارتند از فرمتبندیشده رشتهای که «f-strings» نیز نامیده میشود، و فراخوانی str.format().
حروف رشته ای قالب بندی شده
غالباً کلمات رشتهای قالببندی شده را میبینید که در موقعیتهایی مانند:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
یک رشته تحت اللفظی قالب بندی شده با «f» پیشوند می شود (مانند پیشوند «r» که برای رشته های خام استفاده می شود). هر متنی خارج از بریس های فرفری '{}' مستقیماً چاپ می شود. عبارات موجود در "{}" با استفاده از مشخصات فرمت شرح داده شده در مشخصات قالب چاپ می شوند. کارهای منظم زیادی وجود دارد که میتوانید با قالببندی انجام دهید، از جمله کوتاه کردن و تبدیل به نماد علمی و تراز چپ/راست/مرکز.
رشتههای f زمانی بسیار مفید هستند که میخواهید جدولی از اشیاء را چاپ کنید و میخواهید ستونهایی که ویژگیهای شیء مختلف را نشان میدهند مانند آن تراز شوند.
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
رشته %
پایتون همچنین دارای یک تسهیلات قدیمی مانند printf() برای کنار هم قرار دادن یک رشته است. عملگر % یک رشته با فرمت printf در سمت چپ (%d int، %s رشته، %f/%g ممیز شناور) می گیرد و مقادیر منطبق را در یک تاپل در سمت راست می گیرد (یک تاپل از مقادیر جدا شده با کاما، معمولاً در داخل پرانتز گروه بندی می شوند:
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
خط بالا به نوعی طولانی است -- فرض کنید می خواهید آن را به خطوط جداگانه تقسیم کنید. شما نمی توانید همانطور که در زبان های دیگر ممکن است فقط خط را بعد از '%' تقسیم کنید، زیرا به طور پیش فرض پایتون هر خط را به عنوان یک دستور جداگانه در نظر می گیرد (از طرف دیگر، به همین دلیل است که ما نیازی به تایپ نیم کالن در هر کدام نداریم. خط). برای رفع این مشکل، کل عبارت را در یک مجموعه بیرونی از پرانتز قرار دهید - سپس عبارت اجازه دارد چندین خط را در بر بگیرد. این تکنیک کد در سراسر خطوط با ساختارهای گروه بندی مختلف که در زیر توضیح داده شده است کار می کند: ( )، [ ]، { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
این بهتر است، اما خط هنوز کمی طولانی است. پایتون به شما این امکان را میدهد که یک خط را به تکههایی تقسیم کنید، که سپس به طور خودکار به هم متصل میشوند. بنابراین، برای کوتاهتر کردن این خط، میتوانیم این کار را انجام دهیم:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
رشته ها (یونیکد در مقابل بایت)
رشته های پایتون معمولی یونیکد هستند.
پایتون همچنین از رشتههای متشکل از بایتهای ساده (که با پیشوند «b» در مقابل یک رشته به معنای واقعی کلمه مشخص میشود) پشتیبانی میکند:
> byte_string = b'A byte string' > byte_string b'A byte string'
رشته یونیکد نوع متفاوتی از شی با رشته بایت است، اما کتابخانه های مختلف مانند عبارات منظم در صورت عبور از هر یک از رشته ها به درستی کار می کنند.
برای تبدیل یک رشته معمولی پایتون به بایت، متد ()encode روی رشته را فراخوانی کنید. در جهت دیگر، متد ()decode رشته بایت، بایتهای ساده کدگذاری شده را به رشته یونیکد تبدیل میکند:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
در بخش خواندن فایل، مثالی وجود دارد که نشان می دهد چگونه یک فایل متنی را با مقداری رمزگذاری باز کنید و رشته های یونیکد را بخوانید.
اگر بیانیه
پایتون از {} برای محصور کردن بلوکهای کد برای if/loops/function و غیره استفاده نمیکند. در عوض، پایتون از دو نقطه (:) و تورفتگی/فضای فاصله برای گروهبندی عبارات استفاده میکند. آزمون بولی برای if نیازی به داخل پرانتز نیست (تفاوت زیادی با C++/Java) و می تواند دارای بندهای *elif* و *else* باشد (مانمونیک: کلمه "elif" به اندازه کلمه "" است. دیگری").
هر مقدار را می توان به عنوان یک آزمون if استفاده کرد. مقادیر "صفر" همگی نادرست به حساب می آیند: هیچ، 0، رشته خالی، لیست خالی، فرهنگ لغت خالی. همچنین یک نوع Boolean با دو مقدار وجود دارد: True و False (تبدیل شده به int، اینها 1 و 0 هستند). پایتون عملیات مقایسه معمولی را دارد: ==، !=، <، <=، >، >=. بر خلاف جاوا و C، == برای کار درست با رشته ها بیش از حد بارگذاری می شود. عملگرهای بولی کلمات نوشته شده *and*، *or*، *not* هستند (پایتون از C-style && || ! استفاده نمی کند). در اینجا کد ممکن است برای یک برنامه بهداشتی که در طول روز توصیههای نوشیدنی ارائه میکند به نظر برسد - توجه کنید که چگونه هر بلوک از عبارت then/else با یک شروع میشود و عبارات بر اساس تورفتگی گروهبندی میشوند:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
من متوجه شدم که حذف ":" رایج ترین اشتباه نحوی من هنگام تایپ نوع کد بالا است، احتمالاً زیرا این یک چیز اضافی برای تایپ در مقابل عادات C++/Java من است. همچنین، تست بولی را در پرانتز قرار ندهید - این یک عادت C/Java است. اگر کد کوتاه است، میتوانید کد را در همان خط بعد از ":" قرار دهید، مانند این (این برای توابع، حلقهها و غیره نیز صدق میکند)، اگرچه برخی افراد احساس میکنند که فاصله دادن چیزها در خطوط جداگانه خواناتر است.
if time_hour < 10: print('coffee') else: print('water')
تمرین: string1.py
برای تمرین مطالب این بخش، تمرین string1.py را در تمرینات پایه امتحان کنید.