Python verfügt über eine integrierte String-Klasse namens "str" mit vielen praktischen Funktionen (es gibt ein älteres Modul namens "string", das Sie nicht verwenden sollten). String-Literale können entweder in doppelte oder einfache Anführungszeichen gesetzt werden, wobei einfache Anführungszeichen häufiger verwendet werden. Umgekehrte Schrägstriche funktionieren sowohl in einfachen als auch in doppelten Anführungszeichen wie gewohnt, z.B. \n \" \". Ein Stringliteral mit doppelten Anführungszeichen kann ohne großen Aufwand einfache Anführungszeichen enthalten (z.B. "Ich habe es nicht gemacht") und ebenso einfache Anführungszeichen können doppelte Anführungszeichen enthalten. Ein String-Literal kann sich über mehrere Zeilen erstrecken, aber am Ende jeder Zeile muss ein umgekehrter Schrägstrich \ stehen, um den Zeilenumbruch zu maskieren. Stringliterale in dreifachen Anführungszeichen (""" oder "") können mehrere Textzeilen umfassen.
Python-Strings sind „unveränderlich“, was bedeutet, dass sie nach ihrer Erstellung nicht mehr geändert werden können (auch Java-Strings verwenden diesen unveränderlichen Stil). Da Strings nicht geändert werden können, erstellen wir *neue* Strings, um berechnete Werte darzustellen. Beispielsweise übernimmt der Ausdruck ('hello' + 'there') die beiden Zeichenfolgen 'hello' und 'there' und erstellt einen neuen String 'hellothere'.
Auf Zeichen in einem String kann mit der Standardsyntax [ ] zugegriffen werden. Wie bei Java und C++ verwendet Python eine nullbasierte Indexierung. Wenn s also „hello“ ist, ist s[1] „e“. Wenn der Index für den String außerhalb des Bereichs liegt, löst Python einen Fehler aus. Der Python-Stil (im Gegensatz zu Perl) ist das Halten, wenn er nicht sagen kann, was zu tun ist, und er stellt keinen Standardwert dar. Mit der praktischen "slice"-Syntax (siehe unten) lassen sich auch alle Teilzeichenfolgen aus einer Zeichenfolge extrahieren. Die Funktion „len(string)“ gibt die Länge einer Zeichenfolge zurück. Die Syntax [ ] und die Funktion „len()“ funktionieren tatsächlich mit jedem Sequenztyp, z. B. Strings, Listen usw. Python versucht, dafür zu sorgen, dass seine Vorgänge über verschiedene Typen hinweg konsistent funktionieren. Python-Neuling: Verwenden Sie nicht „len“ als Variablennamen, damit die Funktion „len()“ nicht blockiert wird. Der Operator „+“ kann zwei Zeichenfolgen verketten. Beachten Sie im Code unten, dass die Variablen nicht im Voraus deklariert sind. Weisen Sie sie einfach zu und fahren Sie fort.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Im Gegensatz zu Java wandelt '+' Zahlen oder andere Typen nicht automatisch in Zeichenfolgenform um. Die Funktion str() wandelt Werte in eine Zeichenfolgenform um, damit sie mit anderen Zeichenfolgen kombiniert werden können.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Bei Zahlen funktionieren die Standardoperatoren +, /, * wie gewohnt. Es gibt keinen ++-Operator, aber +=, -= usw. funktionieren. Wenn eine Division nach Ganzzahl erfolgen soll, verwenden Sie zwei Schrägstriche, z.B. 6 // 5 ist 1
Die Funktion „print“ gibt normalerweise ein oder mehrere Python-Elemente gefolgt von einem Zeilenumbruch aus. Einem „raw“-String-Literal wird ein „r“ vorangestellt und es werden alle Zeichen ohne besondere Behandlung von umgekehrten Schrägstrichen übergeben. Daher wird r'x\nx' mit dem String „length-4“ „x\nx“ ausgewertet. „print“ kann mehrere Argumente benötigen, um die Ausgabe zu ändern (siehe Definition der Druckfunktion von python.org). Beispielsweise kann „end“ auf „“ gesetzt werden, um nach dem Drucken aller Elemente keinen Zeilenumbruch mehr auszugeben.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Stringmethoden
Hier sehen Sie einige der gängigsten Stringmethoden. Eine Methode ist mit einer Funktion vergleichbar, wird jedoch „auf“ einem Objekt ausgeführt. Wenn die Variable s ein String ist, führt der Code s.lower() die Methode less() für dieses Zeichenfolgenobjekt aus und gibt das Ergebnis zurück (diese Idee einer Methode, die auf einem Objekt ausgeführt wird, ist eine der Grundideen der objektorientierten Programmierung (OOP). Hier sind einige der gängigsten Stringmethoden:
- s.lower(), s.upper(): gibt die kleingeschriebene oder große Version des Strings zurück
- s.strip(): Gibt einen String zurück, bei dem Leerzeichen am Anfang und Ende entfernt wurden
- s.isalpha()/s.isdigital()/s.isspace()... -- testet, ob sich alle Zeichenfolgenzeichen in den verschiedenen Zeichenklassen befinden.
- s.startswith('other'), s.endswith('other') - testet, ob die Zeichenfolge mit der angegebenen Zeichenfolge beginnt oder endet
- s.find('other') - sucht nach der angegebenen anderen Zeichenfolge (kein regulärer Ausdruck) innerhalb von s und gibt den ersten Index, bei dem er beginnt, oder -1 zurück, wenn er nicht gefunden wird
- s.replace('old', 'new') – gibt einen String zurück, bei dem alle Vorkommen von "old" durch "new" ersetzt wurden
- s.split('delim') - gibt eine Liste von Teilzeichenfolgen zurück, die durch das angegebene Trennzeichen getrennt sind. Das Trennzeichen ist kein regulärer Ausdruck, sondern nur Text. 'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. Als praktischen Sonderfall teilt s.split() (ohne Argumente) alle Leerzeichen auf.
- s.join(list) -- Gegenteil von "split()" verknüpft die Elemente in der angegebenen Liste mithilfe der Zeichenfolge als Trennzeichen. Beispiel: '---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
Wenn Sie auf Google nach „python str“ suchen, sollten Sie zu den offiziellen python.org-String-Methoden gelangen, in denen alle str-Methoden aufgeführt sind.
Python hat keinen separaten Zeichentyp. Stattdessen gibt ein Ausdruck wie s[8] einen string-length-1 zurück, der das Zeichen enthält. Mit diesem string-length-1 funktionieren die Operatoren ==, <=, ... alle erwartungsgemäß, sodass Sie meistens nicht wissen müssen, dass Python keinen separaten skalaren "char"-Typ hat.
String-Slices
Die „Slice“-Syntax ist eine praktische Möglichkeit, auf Unterteile von Sequenzen zu verweisen, in der Regel Strings und Listen. Das Segment s[start:end] ist die Elemente, die am Anfang beginnen und sich bis zum Ende erstrecken. Angenommen, wir haben s = "Hallo".
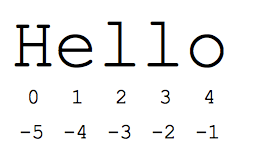
- s[1:4] ist "ell" - Zeichen beginnen bei Index 1 und erstrecken sich bis Index 4, jedoch nicht eingeschlossen
- s[1:] ist 'ello' -- der Index wird standardmäßig am Anfang oder am Ende der Zeichenfolge weggelassen.
- s[:] ist „Hallo“ – wenn beide weggelassen werden, erhalten wir eine Kopie des Ganzen (dies ist die Python-Methode, um eine Sequenz wie einen String oder eine Liste zu kopieren).
- s[1:100] ist 'ello' - ein zu großer Index wird auf die Zeichenfolgenlänge gekürzt.
Die standardmäßigen nullbasierten Indexnummern ermöglichen einen einfachen Zugriff auf Zeichen am Anfang des Strings. Alternativ verwendet Python negative Zahlen, um einfachen Zugriff auf die Zeichen am Ende des Strings zu ermöglichen: s[-1] ist das letzte Zeichen "o", s[-2] ist "l" das nächste Zeichen usw. Negative Indexnummern werden vom Ende des Strings zurückgezählt:
- s[-1] ist "o" – letztes Zeichen (1. vom Ende)
- s[-4] ist 'e' – 4. vom Ende
- s[:-3] ist "Er" – bis zu, aber ohne die letzten drei Zeichen.
- s[-3:] ist "llo" – beginnt mit dem dritten Zeichen vom Ende und erstreckt sich bis zum Ende der Zeichenfolge.
Es ist eine übersichtliche Struktur von Segmenten, die für jeden Index n s[:n] + s[n:] == s ist. Dies funktioniert auch für n negative oder außerhalb des gültigen Bereichs. Oder anders ausgedrückt: s[:n] und s[n:] unterteilen die Zeichenfolge immer in zwei Zeichenfolgenteile, sodass alle Zeichen erhalten bleiben. Wie wir später im Listenabschnitt sehen werden, funktionieren Segmente auch mit Listen.
Stringformatierung
Mit Python kann u. a. Objekte automatisch in einen für den Druck geeigneten String konvertiert werden. Zwei integrierte Möglichkeiten dafür sind formatierte Stringliterale, auch „f-Strings“ genannt, und das Aufrufen von str.format().
Formatierte Stringliterale
Häufig werden formatierte Stringliterale in folgenden Situationen verwendet:
value = 2.791514
print(f'approximate value = {value:.2f}') # approximate value = 2.79
car = {'tires':4, 'doors':2}
print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Ein formatierter Literalstring hat das Präfix „f“ (wie das Präfix „r“ für Rohstrings). Text außerhalb der geschweiften Klammern '{}' wird direkt ausgedruckt. Ausdrücke in {} werden mithilfe der Formatspezifikation ausgegeben, die in der Formatspezifikation beschrieben wird.Die Formatierung bietet viele praktische Funktionen, wie etwa Kürzung, Umwandlung in wissenschaftliche Notation und links-/rechts-/zentrierte Ausrichtung.
f-Strings sind sehr nützlich, um eine Tabelle mit Objekten auszudrucken und die Spalten für verschiedene Objektattribute
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70},
{'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400},
{'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},]
for person in address_book:
print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}')
# N.X. || 15 Jones St || 70
# J.P. || 1005 5th St || 400
# A.A. || 200001 Bdwy || 5
Zeichenfolge %
Python verfügt auch über eine ältere printf()-ähnliche Möglichkeit, einen String zu erstellen. Der % -Operator nimmt eine Printf-Format-Zeichenfolge auf der linken Seite (%d Ganzzahl, %s Zeichenfolge, %f/%g Gleitkommazahl) und die übereinstimmenden Werte in einem Tupel auf der rechten Seite an (ein Tupel besteht aus Werten, die durch Kommas getrennt und in der Regel in Klammern gruppiert sind):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Die obige Zeile ist recht lang. Angenommen, Sie möchten sie in separate Zeilen aufteilen. Sie können die Zeile nicht einfach nach dem '%' aufteilen, wie dies in anderen Sprachen der Fall wäre, da Python standardmäßig jede Zeile als separate Anweisung behandelt (auf der Plus-Seite, ist dies der Grund, warum wir nicht in jede Zeile Semikolons eingeben müssen). Um dieses Problem zu beheben, setzen Sie den gesamten Ausdruck in einen äußeren Satz Klammern. Dann darf der Ausdruck mehrere Zeilen umfassen. Diese Code-a-Cross-Lines-Technik funktioniert mit den verschiedenen nachfolgend beschriebenen Gruppierungskonstrukten: ( ), [ ], { }.
# Add parentheses to make the long line work:
text = (
"%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down."
% (3, 'huff', 'puff', 'house'))
Das ist besser, aber die Schlange ist immer noch ein bisschen lang. Mit Python können Sie eine Zeile in Blöcke zerschneiden, die dann automatisch verkettet werden. Um diese Zeile noch zu verkürzen, können wir Folgendes tun:
# Split the line into chunks, which are concatenated automatically by Python
text = (
"%d little pigs come out, "
"or I'll %s, and I'll %s, "
"and I'll blow your %s down."
% (3, 'huff', 'puff', 'house'))
Strings (Unicode im Vergleich zu Byte)
Normale Python-Strings sind Unicode-Strings.
Python unterstützt auch Strings, die aus einfachen Byte bestehen (gekennzeichnet durch das Präfix "b" vor einem Stringliteral), wie beispielsweise:
> byte_string = b'A byte string' > byte_string b'A byte string'
Ein Unicode-String ist ein anderer Objekttyp als ein Bytestring. Verschiedene Bibliotheken wie reguläre Ausdrücke funktionieren jedoch ordnungsgemäß, wenn beide Stringtypen übergeben werden.
Um einen regulären Python-String in Byte umzuwandeln, rufen Sie die Methode „Encode()“ für den String auf. Umgekehrt wandelt die Bytestring-decode()-Methode codierte Klarbyte in einen Unicode-String um:
> ustring = 'A unicode \u018e string \xf1'
> b = ustring.encode('utf-8')
> b
b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix.
> t = b.decode('utf-8') ## Convert bytes back to a unicode string
> t == ustring ## It's the same as the original, yay!
True
Im Abschnitt zum Lesen von Dateien finden Sie ein Beispiel, das zeigt, wie Sie eine Textdatei mit einer gewissen Codierung öffnen und Unicode-Strings auslesen.
If-Anweisung
Python verwendet { } nicht zum Umschließen von Codeblöcken für if/loops/function usw. Stattdessen verwendet Python den Doppelpunkt (:) und Einrückung/Leerraum, um Anweisungen zu gruppieren. Der boolesche Test für ein if muss nicht in Klammern gesetzt werden (großer Unterschied zu C++/Java), und es kann *elif*- und *else*-Klauseln enthalten (Gedächtnis: das Wort "elif" hat die gleiche Länge wie das Wort "else").
Jeder Wert kann als if-Test verwendet werden. Die „Null“-Werte werden alle als „false“ gezählt: None, 0, leerer String, leere Liste, leeres Wörterbuch. Es gibt auch einen booleschen Typ mit zwei Werten: True und False (in eine Ganzzahl umgewandelt, sind diese 1 und 0). Python verfügt über die üblichen Vergleichsoperationen: ==, !=, <, <=, >, >=. Im Gegensatz zu Java und C ist == überlastet, um korrekt mit Zeichenfolgen zu funktionieren. Die booleschen Operatoren sind die ausgeschriebenen Wörter *and*, *or*, *not* (Python verwendet nicht den C-Stil && || !). So könnte der Code für eine Gesundheits-App aussehen, die im Laufe des Tages Getränkeempfehlungen bereitstellt. Beachten Sie, dass jeder Block von dann/else-Anweisungen mit einem „:“ beginnt und die Anweisungen nach ihrer Einrückung gruppiert sind:
if time_hour >= 0 and time_hour <= 24:
print('Suggesting a drink option...')
if mood == 'sleepy' and time_hour < 10:
print('coffee')
elif mood == 'thirsty' or time_hour < 2:
print('lemonade')
else:
print('water')
Ich habe festgestellt, dass das Weglassen von ":" mein häufigster Syntaxfehler bei der Eingabe der obigen Art von Code ist. Wahrscheinlich ist das eine zusätzliche Eingabe im Vergleich zu meinen C++/Java-Gewohnheiten. Setzen Sie den booleschen Test auch nicht in Klammern - das ist eine C/Java-Gewohnheit. Wenn der Code kurz ist, können Sie den Code in die gleiche Zeile nach ":" einfügen, wie hier dargestellt (dies gilt auch für Funktionen, Schleifen usw.), auch wenn es für manche Menschen besser lesbar ist, Elemente in separaten Zeilen zu platzieren.
if time_hour < 10: print('coffee')
else: print('water')
Übung: string1.py
Um das Material in diesem Abschnitt zu üben, versuchen Sie es mit der Übung string1.py in den Grundlagenübungen.