পাইথনের একটি অন্তর্নির্মিত স্ট্রিং ক্লাস রয়েছে যার নাম "str" অনেক সুবিধাজনক বৈশিষ্ট্য সহ (এখানে "স্ট্রিং" নামে একটি পুরানো মডিউল রয়েছে যা আপনার ব্যবহার করা উচিত নয়)। স্ট্রিং লিটারেলগুলি ডাবল বা একক উদ্ধৃতি দ্বারা আবদ্ধ হতে পারে, যদিও একক উদ্ধৃতিগুলি বেশি ব্যবহৃত হয়। ব্যাকস্ল্যাশ এস্কেপগুলি একক এবং দ্বিগুণ উদ্ধৃত লিটারেল উভয়ের মধ্যেই স্বাভাবিক ভাবে কাজ করে -- যেমন \n \' \"। একটি ডবল উদ্ধৃত স্ট্রিং লিটারেলে কোনো রকম ঝগড়া ছাড়াই একক উদ্ধৃতি থাকতে পারে (যেমন "আমি এটা করিনি") এবং একইভাবে একক উদ্ধৃতি স্ট্রিং-এ ডবল কোট থাকতে পারে পাঠ্যের
পাইথন স্ট্রিংগুলি "অপরিবর্তনযোগ্য" যার অর্থ তাদের তৈরি হওয়ার পরে পরিবর্তন করা যায় না (জাভা স্ট্রিংগুলিও এই অপরিবর্তনীয় শৈলী ব্যবহার করে)। যেহেতু স্ট্রিং পরিবর্তন করা যায় না, তাই আমরা *নতুন* স্ট্রিং তৈরি করি যখন আমরা গণনা করা মান উপস্থাপন করতে যাই। সুতরাং উদাহরণস্বরূপ অভিব্যক্তি ('হ্যালো' + 'সেখানে') 2টি স্ট্রিং 'হ্যালো' এবং 'সেখানে' নেয় এবং একটি নতুন স্ট্রিং 'হ্যালোথেরে' তৈরি করে।
একটি স্ট্রিংয়ের অক্ষরগুলি স্ট্যান্ডার্ড [ ] সিনট্যাক্স ব্যবহার করে অ্যাক্সেস করা যেতে পারে এবং জাভা এবং C++ এর মতো পাইথন শূন্য-ভিত্তিক ইন্ডেক্সিং ব্যবহার করে, তাই s যদি 'হ্যালো' হয় s[1] হয় 'e'। যদি সূচীটি স্ট্রিংয়ের জন্য সীমার বাইরে থাকে, পাইথন একটি ত্রুটি উত্থাপন করে। পাইথন শৈলী (পার্লের বিপরীতে) শুধুমাত্র একটি ডিফল্ট মান তৈরি করার পরিবর্তে কি করতে হবে তা বলতে না পারলে থামতে হবে। সহজ "স্লাইস" সিনট্যাক্স (নীচে) একটি স্ট্রিং থেকে যেকোনো সাবস্ট্রিং বের করতেও কাজ করে। len(স্ট্রিং) ফাংশন একটি স্ট্রিং এর দৈর্ঘ্য প্রদান করে। [ ] সিনট্যাক্স এবং len() ফাংশন আসলে যেকোন সিকোয়েন্স টাইপ -- স্ট্রিং, লিস্ট ইত্যাদিতে কাজ করে। পাইথন চেষ্টা করে বিভিন্ন প্রকারের মধ্যে ধারাবাহিকভাবে কাজ করে। Python newbie gotcha: len() ফাংশন ব্লক করা এড়াতে একটি পরিবর্তনশীল নাম হিসাবে "len" ব্যবহার করবেন না। '+' অপারেটর দুটি স্ট্রিংকে সংযুক্ত করতে পারে। নীচের কোডে লক্ষ্য করুন যে ভেরিয়েবলগুলি পূর্ব-ঘোষিত নয় -- শুধু তাদের বরাদ্দ করুন এবং যান৷
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
জাভার বিপরীতে, '+' স্বয়ংক্রিয়ভাবে সংখ্যা বা অন্যান্য প্রকারকে স্ট্রিং ফর্মে রূপান্তর করে না। str() ফাংশন মানগুলিকে একটি স্ট্রিং ফর্মে রূপান্তর করে যাতে সেগুলিকে অন্যান্য স্ট্রিংগুলির সাথে একত্রিত করা যায়।
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
সংখ্যার জন্য, স্ট্যান্ডার্ড অপারেটর, +, /, * স্বাভাবিক পদ্ধতিতে কাজ করে। কোন ++ অপারেটর নেই, তবে +=, -= ইত্যাদি কাজ করে। আপনি যদি পূর্ণসংখ্যা বিভাজন চান, 2টি স্ল্যাশ ব্যবহার করুন -- যেমন 6 // 5 হল 1
"মুদ্রণ" ফাংশন সাধারণত একটি নতুন লাইন অনুসরণ করে এক বা একাধিক পাইথন আইটেম প্রিন্ট করে। একটি "কাঁচা" স্ট্রিং আক্ষরিক একটি 'r' দ্বারা উপসর্গযুক্ত এবং ব্যাকস্ল্যাশের বিশেষ চিকিত্সা ছাড়াই সমস্ত অক্ষর অতিক্রম করে, তাই r'x\nx' দৈর্ঘ্য-4 স্ট্রিং 'x\nx' মূল্যায়ন করে। "প্রিন্ট" জিনিসগুলিকে কীভাবে প্রিন্ট করে তা পরিবর্তন করার জন্য বিভিন্ন যুক্তি নিতে পারে ( python.org প্রিন্ট ফাংশন সংজ্ঞা দেখুন) যেমন "এন্ড" থেকে "" সেট করা যাতে সমস্ত আইটেমগুলি প্রিন্ট করা শেষ হওয়ার পরে নতুন লাইন প্রিন্ট করা যায় না।
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
স্ট্রিং পদ্ধতি
এখানে কিছু সাধারণ স্ট্রিং পদ্ধতি রয়েছে। একটি পদ্ধতি একটি ফাংশনের মতো, তবে এটি একটি বস্তুকে "চালু" করে। যদি ভেরিয়েবল s একটি স্ট্রিং হয়, তাহলে s.lower() কোডটি সেই স্ট্রিং অবজেক্টে Lower() মেথড চালায় এবং ফলাফল প্রদান করে (কোনও অবজেক্টের উপর চলমান পদ্ধতির এই ধারণাটি হল একটি মৌলিক ধারণা যা অবজেক্ট তৈরি করে। ওরিয়েন্টেড প্রোগ্রামিং, ওওপি)। এখানে কিছু সাধারণ স্ট্রিং পদ্ধতি রয়েছে:
- s.lower(), s.upper() -- স্ট্রিং এর ছোট হাতের বা বড় হাতের সংস্করণ প্রদান করে
- s.strip() -- শুরু এবং শেষ থেকে সরানো হোয়াইটস্পেস সহ একটি স্ট্রিং প্রদান করে
- s.isalpha()/s.isdigit()/s.isspace()... -- পরীক্ষা করে যদি সমস্ত স্ট্রিং অক্ষর বিভিন্ন ক্যারেক্টার ক্লাসে থাকে
- s.startswith('other'), s.endswith('other') -- প্রদত্ত অন্য স্ট্রিং দিয়ে স্ট্রিং শুরু হয় বা শেষ হয় কিনা তা পরীক্ষা করে
- s.find('other') -- s-এর মধ্যে প্রদত্ত অন্যান্য স্ট্রিং (একটি রেগুলার এক্সপ্রেশন নয়) অনুসন্ধান করে, এবং প্রথম সূচী প্রদান করে যেখানে এটি শুরু হয় বা -1 পাওয়া না গেলে
- s.replace('পুরাতন', 'নতুন') -- একটি স্ট্রিং প্রদান করে যেখানে 'পুরানো' এর সমস্ত ঘটনা 'নতুন' দ্বারা প্রতিস্থাপিত হয়েছে
- s.split('delim') -- প্রদত্ত ডিলিমিটার দ্বারা পৃথক করা সাবস্ট্রিংগুলির একটি তালিকা প্রদান করে। ডিলিমিটার একটি নিয়মিত অভিব্যক্তি নয়, এটি কেবল পাঠ্য। 'aaa,bbb,ccc'.split(',') -> ['aa', 'bbb', 'ccc']। একটি সুবিধাজনক বিশেষ ক্ষেত্রে s.split() (কোন যুক্তি ছাড়াই) সমস্ত হোয়াইটস্পেস অক্ষরে বিভক্ত হয়।
- s.join(list) -- split(এর বিপরীতে), প্রদত্ত তালিকার উপাদানগুলিকে স্ট্রিংকে বিভাজনকারী হিসাবে ব্যবহার করে একসাথে যোগ করে। যেমন '---'.join(['aa', 'bbb', 'ccc']) -> aaa---bbb---ccc
"python str" এর জন্য একটি গুগল অনুসন্ধান আপনাকে অফিসিয়াল python.org স্ট্রিং পদ্ধতিতে নিয়ে যাবে যা সমস্ত str পদ্ধতির তালিকা করে।
পাইথনের আলাদা অক্ষরের ধরন নেই। পরিবর্তে s[8] এর মত একটি অভিব্যক্তি অক্ষর ধারণকারী একটি স্ট্রিং-দৈর্ঘ্য-1 প্রদান করে। সেই স্ট্রিং-লেংথ-১ এর সাথে, অপারেটরগুলি ==, <=, ... আপনার প্রত্যাশা অনুযায়ী সমস্ত কাজ করে, তাই বেশিরভাগ ক্ষেত্রে আপনাকে জানার দরকার নেই যে পাইথনের একটি পৃথক স্কেলার "char" টাইপ নেই।
স্ট্রিং স্লাইস
"স্লাইস" সিনট্যাক্স হল সিকোয়েন্সের উপ-অংশগুলি উল্লেখ করার একটি সহজ উপায় -- সাধারণত স্ট্রিং এবং তালিকা। স্লাইস s[start:end] হল সেই উপাদানগুলি যা শুরুতে শুরু হয় এবং শেষ পর্যন্ত প্রসারিত হয় কিন্তু শেষ পর্যন্ত নয়। ধরুন আমাদের কাছে s = "হ্যালো" আছে
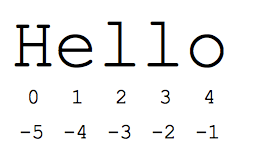
- s[1:4] হল 'ell' -- অক্ষরগুলি সূচী 1 থেকে শুরু হয় এবং সূচী 4 পর্যন্ত প্রসারিত হয় না
- এস
- s[:] হল 'হ্যালো' -- উভয় বাদ দিলে সর্বদা আমাদের পুরো জিনিসটির একটি অনুলিপি পাওয়া যায় (এটি একটি স্ট্রিং বা তালিকার মতো একটি ক্রম অনুলিপি করার পাইথনিক উপায়)
- s[1:100] হল 'ello' -- একটি সূচক যা খুব বড় তা স্ট্রিং দৈর্ঘ্যে ছোট করা হয়
স্ট্যান্ডার্ড শূন্য-ভিত্তিক সূচক সংখ্যাগুলি স্ট্রিংয়ের শুরুর কাছাকাছি অক্ষরগুলিতে সহজে অ্যাক্সেস দেয়। একটি বিকল্প হিসাবে, স্ট্রিং এর শেষে অক্ষরগুলিতে সহজে অ্যাক্সেস দিতে পাইথন নেতিবাচক সংখ্যা ব্যবহার করে: s[-1] হল শেষ অক্ষর 'o', s[-2] হল 'l' পরবর্তী-থেকে-শেষ char, এবং তাই. নেতিবাচক সূচক সংখ্যা স্ট্রিং শেষ থেকে ফিরে গণনা করা হয়:
- s[-1] হল 'o' -- শেষ অক্ষর (শেষ থেকে ১ম)
- s[-4] হল 'e' -- শেষ থেকে ৪র্থ
- s[:-3] হল 'He' -- পর্যন্ত যাচ্ছে কিন্তু শেষ ৩টি অক্ষর অন্তর্ভুক্ত নয়।
- s[-3:] হল 'llo' -- শেষ থেকে 3য় অক্ষর দিয়ে শুরু এবং স্ট্রিংয়ের শেষ পর্যন্ত প্রসারিত।
এটি স্লাইসের একটি ঝরঝরে সত্য যে কোনো সূচকের জন্য n, s[:n] + s[n:] == s । এটি এমনকি এন নেতিবাচক বা সীমার বাইরে কাজ করে। অথবা অন্য উপায়ে s[:n] এবং s[n:] সর্বদা স্ট্রিংটিকে দুটি স্ট্রিং অংশে ভাগ করুন, সমস্ত অক্ষর সংরক্ষণ করুন। যেমনটি আমরা পরে তালিকা বিভাগে দেখব, স্লাইসগুলি তালিকার সাথেও কাজ করে।
স্ট্রিং বিন্যাস
পাইথন একটি পরিষ্কার জিনিস যা করতে পারে তা হল স্বয়ংক্রিয়ভাবে বস্তুগুলিকে মুদ্রণের জন্য উপযুক্ত একটি স্ট্রিংয়ে রূপান্তর করা। এটি করার জন্য দুটি অন্তর্নির্মিত উপায় হল ফর্ম্যাট করা স্ট্রিং লিটারেল, যাকে "f-স্ট্রিংস"ও বলা হয় এবং str.format() বলা হয়।
ফরম্যাট করা স্ট্রিং লিটারেল
আপনি প্রায়শই এমন পরিস্থিতিতে ব্যবহৃত ফর্ম্যাট করা স্ট্রিং লিটারেলগুলি দেখতে পাবেন:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
একটি বিন্যাসিত আক্ষরিক স্ট্রিং 'f' এর সাথে উপসর্গযুক্ত (যেমন 'r' উপসর্গটি কাঁচা স্ট্রিংয়ের জন্য ব্যবহৃত হয়)। কোঁকড়া ধনুর্বন্ধনী '{}'-এর বাইরের যেকোনো লেখা সরাসরি প্রিন্ট করা হয়। '{}'-এর মধ্যে থাকা অভিব্যক্তিগুলি বিন্যাস স্পেসিফিকেশনে বর্ণিত ফর্ম্যাট স্পেসিফিকেশন ব্যবহার করে প্রিন্ট করা হয়। ছেঁটে ফেলা এবং বৈজ্ঞানিক স্বরলিপিতে রূপান্তর এবং বাম/ডান/সেন্টার অ্যালাইনমেন্ট সহ ফর্ম্যাটিং দিয়ে আপনি অনেকগুলি ঝরঝরে জিনিস করতে পারেন৷
f-স্ট্রিংগুলি খুব দরকারী যখন আপনি অবজেক্টের একটি টেবিল মুদ্রণ করতে চান এবং বিভিন্ন অবজেক্ট অ্যাট্রিবিউটের প্রতিনিধিত্বকারী কলামগুলি সারিবদ্ধ করতে চান
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
স্ট্রিং %
Python-এর একটি পুরানো printf()-এর মতো একটি স্ট্রিং একত্রিত করার সুবিধা রয়েছে। % অপারেটর বাম দিকে একটি প্রিন্টএফ-টাইপ ফরম্যাট স্ট্রিং নেয় (%d int, %s স্ট্রিং, %f/%g ফ্লোটিং পয়েন্ট), এবং ডানদিকে একটি টিপলে মানানসই মান (একটি টিপল আলাদা করা মান দিয়ে তৈরি হয় কমা, সাধারণত বন্ধনীর ভিতরে গোষ্ঠীবদ্ধ):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
উপরের লাইনটি লম্বা ধরনের -- ধরুন আপনি একে আলাদা লাইনে ভাঙ্গতে চান। আপনি অন্যান্য ভাষার মতো '%'-এর পরে লাইনটিকে বিভক্ত করতে পারবেন না, যেহেতু ডিফল্টভাবে পাইথন প্রতিটি লাইনকে একটি পৃথক বিবৃতি হিসাবে বিবেচনা করে (প্লাস সাইডে, এজন্য আমাদের প্রতিটিতে সেমি-কোলন টাইপ করার দরকার নেই। লাইন)। এটি ঠিক করার জন্য, বন্ধনীর একটি বাইরের সেটে পুরো অভিব্যক্তিটি আবদ্ধ করুন -- তারপর অভিব্যক্তিটিকে একাধিক লাইন বিস্তৃত করার অনুমতি দেওয়া হয়। এই কোড-ক্রস-লাইন কৌশলটি নীচে বিশদ বিশদ বিভিন্ন গ্রুপিং গঠনের সাথে কাজ করে: ( ), [ ], { }।
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
এটা ভাল, কিন্তু লাইন এখনও একটু দীর্ঘ. পাইথন আপনাকে একটি লাইনকে টুকরো টুকরো করে কাটতে দেয়, যা পরে এটি স্বয়ংক্রিয়ভাবে সংযুক্ত হবে। সুতরাং, এই লাইনটিকে আরও ছোট করতে, আমরা এটি করতে পারি:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
স্ট্রিংস (ইউনিকোড বনাম বাইট)
নিয়মিত পাইথন স্ট্রিংগুলি ইউনিকোড।
পাইথন প্লেইন বাইটের সমন্বয়ে গঠিত স্ট্রিংকেও সমর্থন করে (স্ট্রিং লিটারেলের সামনে উপসর্গ 'b' দ্বারা চিহ্নিত) যেমন:
> byte_string = b'A byte string' > byte_string b'A byte string'
একটি ইউনিকোড স্ট্রিং একটি বাইট স্ট্রিং থেকে একটি ভিন্ন ধরনের অবজেক্ট কিন্তু বিভিন্ন লাইব্রেরি যেমন রেগুলার এক্সপ্রেশন সঠিকভাবে কাজ করে যদি যেকোনো ধরনের স্ট্রিং পাস করা হয়।
একটি নিয়মিত পাইথন স্ট্রিংকে বাইটে রূপান্তর করতে, স্ট্রিংয়ের এনকোড() পদ্ধতিতে কল করুন। অন্য দিকে যাওয়া, বাইট স্ট্রিং ডিকোড() পদ্ধতি এনকোড করা প্লেইন বাইটকে ইউনিকোড স্ট্রিংয়ে রূপান্তর করে:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
ফাইল-পঠন বিভাগে, একটি উদাহরণ রয়েছে যা দেখায় কিভাবে কিছু এনকোডিং সহ একটি পাঠ্য ফাইল খুলতে হয় এবং ইউনিকোড স্ট্রিংগুলি পড়তে হয়।
যদি বিবৃতি
পাইথন if/loops/function ইত্যাদির জন্য কোডের ব্লকগুলি ঘেরাও করতে { } ব্যবহার করে না। পরিবর্তে, Python গ্রুপ স্টেটমেন্টে কোলন (:) এবং ইন্ডেন্টেশন/হোয়াইটস্পেস ব্যবহার করে। একটি if এর জন্য বুলিয়ান পরীক্ষাটি বন্ধনীতে থাকা প্রয়োজন নেই (C++/Java থেকে বড় পার্থক্য), এবং এতে *elif* এবং *else* ক্লজ থাকতে পারে (স্মৃতিবিদ্যা: শব্দটি "elif" শব্দের সমান দৈর্ঘ্য। অন্য")।
যে কোন মান একটি if-পরীক্ষা হিসাবে ব্যবহার করা যেতে পারে। "শূন্য" মানগুলি সমস্ত মিথ্যা হিসাবে গণনা করে: কোনটিই নয়, 0, খালি স্ট্রিং, খালি তালিকা, খালি অভিধান৷ দুটি মান সহ একটি বুলিয়ান টাইপ রয়েছে: সত্য এবং মিথ্যা (একটি int-এ রূপান্তরিত, এগুলি হল 1 এবং 0)। পাইথনের স্বাভাবিক তুলনামূলক ক্রিয়াকলাপ রয়েছে: ==, !=, <, <=, >, >=। Java এবং C এর বিপরীতে, == স্ট্রিংগুলির সাথে সঠিকভাবে কাজ করার জন্য ওভারলোড করা হয়। বুলিয়ান অপারেটর হল * এবং*, *বা*, *নট* (পাইথন C-স্টাইল && ||!) ব্যবহার করে না। সারা দিন পানীয় সুপারিশ প্রদানকারী স্বাস্থ্য অ্যাপের জন্য কোডটি কেমন হতে পারে তা এখানে রয়েছে -- লক্ষ্য করুন কিভাবে তারপরের/অন্য বিবৃতিগুলির প্রতিটি ব্লক একটি দিয়ে শুরু হয়: এবং বিবৃতিগুলি তাদের ইন্ডেন্টেশন দ্বারা গোষ্ঠীবদ্ধ করা হয়:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
আমি দেখতে পেলাম যে উপরের ধরণের কোডে টাইপ করার সময় ":" বাদ দেওয়া আমার সবচেয়ে সাধারণ সিনট্যাক্স ভুল, সম্ভবত যেহেতু এটি টাইপ করা একটি অতিরিক্ত জিনিস বনাম আমার C++/জাভা অভ্যাস। এছাড়াও, বুলিয়ান পরীক্ষা বন্ধনীতে রাখবেন না -- এটি একটি C/Java অভ্যাস। যদি কোডটি সংক্ষিপ্ত হয়, তাহলে আপনি কোডটিকে ":" এর পরে একই লাইনে রাখতে পারেন (এটি ফাংশন, লুপ, ইত্যাদির ক্ষেত্রেও প্রযোজ্য), যদিও কিছু লোক মনে করে যে এটি আলাদা লাইনে স্থান দেওয়া আরও পাঠযোগ্য।
if time_hour < 10: print('coffee') else: print('water')
ব্যায়াম: string1.py
এই বিভাগের উপাদান অনুশীলন করতে, মৌলিক অনুশীলনের মধ্যে string1.py ব্যায়াম চেষ্টা করুন।