क्रम से लगाने का सबसे आसान तरीका, क्रम से लगाया गया(सूची) फ़ंक्शन है. यह फ़ंक्शन एक सूची लेता है और उन एलिमेंट को क्रम से लगाकर नई सूची दिखाता है. ओरिजनल सूची में कोई बदलाव नहीं हुआ है.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
किसी सूची को सॉर्ट किए गए() फ़ंक्शन में पास करना सबसे आम बात है, लेकिन असल में इसे बार-बार इस्तेमाल किए जा सकने वाले किसी भी कलेक्शन के इनपुट के तौर पर इस्तेमाल किया जा सकता है. पुराना list.sort() तरीका, नीचे दिया गया एक विकल्प है जिसके बारे में नीचे बताया गया है. क्रम से लगाया गया() फ़ंक्शन को क्रम से लगाने के मुकाबले इस्तेमाल करना आसान लगता है. इसलिए, मैं क्रम से लगाया गया() का इस्तेमाल करने का सुझाव देता हूं.
sorted() फ़ंक्शन को वैकल्पिक आर्ग्युमेंट के तौर पर पसंद के मुताबिक बनाया जा सकता है. सॉर्ट किया गया() वैकल्पिक आर्ग्युमेंट रिवर्स=सही, उदाहरण के लिए sorted(list, रिवर्स=True), इसे पीछे की ओर क्रम में लगा देता है.
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
कुंजी से पसंद के मुताबिक क्रम से लगाना=
ज़्यादा जटिल कस्टम क्रम में लगाने के लिए, sorted() ज़रूरत के तौर पर "key=" का इस्तेमाल करता है "कुंजी" दर्ज करके फ़ंक्शन है जो तुलना करने से पहले हर एलिमेंट को बदलता है. कुंजी का फ़ंक्शन एक वैल्यू लेता है और एक वैल्यू दिखाता है. साथ ही, जवाब के तौर पर "प्रॉक्सी" वैल्यू मिलती है वैल्यू का इस्तेमाल क्रम में तुलना करने के लिए किया जाता है.
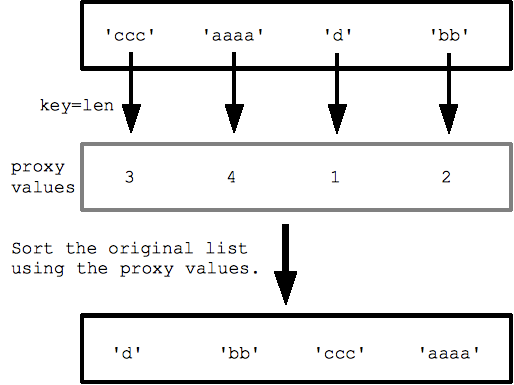
उदाहरण के लिए, स्ट्रिंग की सूची के साथ पासकोड तय करने (पहले से मौजूद Len() फ़ंक्शन) की मदद से, स्ट्रिंग को सबसे छोटे से लेकर सबसे लंबे तक, लंबाई के हिसाब से क्रम में लगाया जाता है. प्रॉक्सी लंबाई की वैल्यू की सूची पाने के लिए, क्रम से लगाया गया हर स्ट्रिंग के लिए Len() को कॉल किया जाता है. इसके बाद, वह उन प्रॉक्सी वैल्यू के साथ क्रम से लगाता है.
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
एक अन्य उदाहरण के रूप में, "str.lower" को क्योंकि पासकोड फ़ंक्शन, अपरकेस और लोअरकेस के साथ एक जैसा व्यवहार करने के लिए, क्रम को लगाने का एक तरीका है:
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
इसका इस्तेमाल, मुख्य फ़ंक्शन के तौर पर अपने MyFn में भी किया जा सकता है. जैसे:
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
ज़्यादा मुश्किल क्रम में लगाने के लिए, जैसे कि उपनाम के हिसाब से क्रम में लगाना, फिर नाम के हिसाब से क्रम में लगाना, तो itemgetter या attrgetter फ़ंक्शन का इस्तेमाल किया जा सकता है. जैसे:
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
क्रम से लगाने का तरीका
क्रम से लगाए गए() के विकल्प के तौर पर, किसी सूची में क्रम से लगाने का तरीका (() तरीका) उस सूची को बढ़ते क्रम में क्रम से लगाता है, उदाहरण के लिए list.sort(). सॉर्ट() वाला तरीका, मौजूदा सूची को बदलता है और 'कोई नहीं' दिखाता है. इसलिए, इसका इस्तेमाल इस तरह करें:
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
ऊपर सॉर्ट() के साथ एक बहुत ही आम गलतफ़हमी है -- यह क्रम में लगाई गई सूची *नहीं लौटाती* है. सॉर्ट() तरीके को किसी सूची में कॉल किया जाना चाहिए; यह किसी भी संख्या में लगाए जा सकने वाले कलेक्शन पर काम नहीं करता (लेकिन ऊपर दिया गया क्रम वाला() फ़ंक्शन किसी भी चीज़ पर काम करता है). सॉर्ट() वाला तरीका,sorted() फ़ंक्शन से पहले का है. इसलिए, हो सकता है कि आपको यह पुराने कोड में दिखे. सॉर्ट करने वाले तरीके के लिए नई सूची बनाने की ज़रूरत नहीं होती. इसलिए, अगर क्रम से लगाने वाले एलिमेंट पहले से ही सूची में मौजूद हैं, तो सूची में यह तरीका थोड़ा तेज़ हो सकता है.
टपल्स
टपल, एलिमेंट का तय साइज़ ग्रुप होता है, जैसे कि (x, y) को-ऑर्डिनेटर. ट्यूपल, सूचियों की तरह होते हैं. हालांकि, उनमें बदलाव नहीं किया जा सकता और उनका साइज़ नहीं बदलता. ट्यूपल पूरी तरह से नहीं बदले जा सकते, क्योंकि उनमें से किसी एक एलिमेंट में बदलाव किया जा सकता है. टपल्स एक तरह से "स्ट्रक्चर" खेलते हैं Python में भूमिका होती है -- यह वैल्यू के छोटे लॉजिकल और तय साइज़ वाले बंडल को पास करने का एक आसान तरीका है. जिस फ़ंक्शन को एक से ज़्यादा वैल्यू की ज़रूरत होती है वह सिर्फ़ वैल्यू का टपल दिखा सकता है. उदाहरण के लिए, अगर मुझे 3-d निर्देशांक की सूची चाहिए, तो प्राकृतिक पाइथन को ट्यूपल की सूची माना जाएगा. यहां हर ट्यूपल का साइज़ 3 है, जिसमें एक (x, y, z) ग्रुप है.
टपल बनाने के लिए, सिर्फ़ ब्रैकेट में दी गई वैल्यू को कॉमा लगाकर अलग करें. "खाली" टपल, ब्रैकेट का सिर्फ़ एक खाली जोड़ा होता है. किसी टपल में एलिमेंट को ऐक्सेस करने का काम बिलकुल एक सूची की तरह होता है -- Len(), [ ], for, in, वगैरह. ये सभी काम एक जैसे ही होते हैं.
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
साइज़-1 टपल बनाने के लिए, लोन एलिमेंट के बाद कॉमा होना ज़रूरी है.
tuple = ('hi',) ## size-1 tuple
सिंटैक्स में यह एक मज़ेदार मामला है, लेकिन ब्रैकेट में एक्सप्रेशन रखने के सामान्य मामले से टपल में अंतर करने के लिए कॉमा की ज़रूरत होती है. कुछ मामलों में, ब्रैकेट को छोड़ा जा सकता है. साथ ही, Python को उन कॉमा से देखा जाएगा जिनके लिए आपने टपल बनाया है.
वैरिएबल के नाम वाले एक जैसे साइज़ के टपल को असाइन करने से, उससे जुड़ी सभी वैल्यू असाइन होती हैं. अगर टुपल एक जैसे साइज़ के नहीं हैं, तो इनमें गड़बड़ी होती है. यह सुविधा सूचियों के लिए भी काम करती है.
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
सूची कॉम्प्रिहेंसन (ज़रूरी नहीं)
लिस्ट कॉम्प्रिहेंसन एक ऐडवांस सुविधा है, जो कुछ मामलों में तो अच्छी होती है, लेकिन एक्सरसाइज़ के लिए इसकी ज़रूरत नहीं होती.यह सुविधा ऐसी नहीं है जिसे आपको शुरू में सीखने की ज़रूरत है. जैसे, इस सेक्शन को छोड़ा जा सकता है. सूची समझने की सुविधा, ऐसा एक्सप्रेशन लिखने का एक छोटा तरीका है जो पूरी सूची में दिखता है. मान लीजिए कि हमारे पास सूची में [1, 2, 3, 4] हैं, तो उनके स्क्वेयर की सूची की गिनती करने के लिए, सूची के बारे में यहां बताया गया है [1, 4, 9, 16]:
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
सिंटैक्स [ expr for var in list ] है -- for var in list एक सामान्य फॉर-लूप जैसा दिखता है, लेकिन इसमें कोलन (:) नहीं होता. हर एलिमेंट के लिए, बाईं ओर मौजूद expr का आकलन एक बार किया जाता है, ताकि नई सूची की वैल्यू दी जा सके. यहां स्ट्रिंग का एक उदाहरण दिया गया है. इसमें हर स्ट्रिंग को '!!!' के साथ अपर केस में बदला जाता है जोड़ा गया:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
नतीजे को सटीक बनाने के लिए, लूप की दाईं ओर if टेस्ट जोड़ा जा सकता है. if टेस्ट का आकलन हर एलिमेंट के लिए किया जाता है. इसमें सिर्फ़ वे एलिमेंट शामिल होते हैं जिनकी जांच सही हुई है.
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
कसरत: list1.py
इस सेक्शन के कॉन्टेंट की प्रैक्टिस करने के लिए, list1.py में बाद में दिए गए उन सवालों को आज़माएं, जो क्रम से लगाने और ट्यूपल (बेसिक एक्सरसाइज़ में) का इस्तेमाल करते हैं.