Tabela de hash do ditado
A eficiente estrutura da tabela de hash de chave-valor do Python é chamada de "dict". O conteúdo de um dict pode ser escrito como uma série de pares de chave-valor entre chaves { }, por exemplo: dict = {chave1:valor1, chave2:valor2, ... }. o "dict vazio" é apenas um par vazio de chaves {}.
Para procurar ou definir um valor em um dict, são usados colchetes. Por exemplo: dict['foo'] procura o valor na chave 'foo'. Strings, números e tuplas funcionam como chaves, e qualquer tipo pode ser um valor. Outros tipos podem ou não funcionar corretamente como chaves (strings e tuplas funcionam de forma limpa, já que são imutáveis). Procurar um valor que não esteja no dict gera um KeyError. Use "in" para verificar se a chave está no dict ou use dict.get(key), que retorna o valor ou None, se a chave não estiver presente (ou get(key, not-found) permite especificar o valor a ser retornado no caso não encontrado).
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
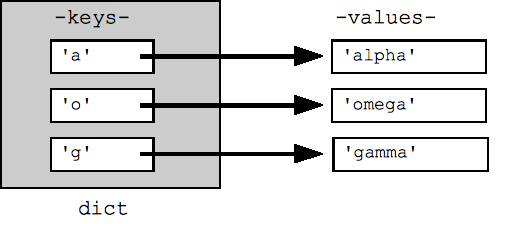
Uma repetição "for" em um dicionário faz a iteração das suas chaves por padrão. As chaves aparecerão em ordem arbitrária. Os métodos dict.keys() e dict.values() retornam listas de chaves ou valores de maneira explícita. Há também um items() que retorna uma lista de tuplas (chave, valor), que é a forma mais eficiente de examinar todos os dados de chave-valor no dicionário. Todas essas listas podem ser passadas para a função sort().
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
Observação estratégica: do ponto de vista do desempenho, o dicionário é uma das suas melhores ferramentas, e você deve usá-lo como uma maneira fácil de organizar os dados. Por exemplo, é possível ler um arquivo de registro em que cada linha começa com um endereço IP e armazenar os dados em um dict usando o endereço IP como a chave e a lista de linhas em que aparece como o valor. Depois de ler o arquivo inteiro, você pode procurar qualquer endereço IP e ver instantaneamente sua lista de linhas. O dicionário recebe dados dispersos e os transforma em algo coerente.
Formatação de ditado
O operador % funciona convenientemente para substituir valores de um dict em uma string pelo nome:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Del
"del" faz exclusões. No caso mais simples, ele pode remover a definição de uma variável, como se essa variável não tivesse sido definida. Del também pode ser usado em elementos de lista ou frações para excluir essa parte da lista e para excluir entradas de um dicionário.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
Arquivos
A função open() é aberta e retorna um identificador de arquivo que pode ser usado para ler ou gravar um arquivo da maneira habitual. O código f = open('name', 'r') abre o arquivo na variável f, pronta para operações de leitura, e usa f.close() quando concluído. Em vez de "r", use "w" para escrita, e 'a' para anexar. O padrão for-loop funciona com arquivos de texto, iterando as linhas do arquivo. Isso funciona apenas para arquivos de texto, não para arquivos binários. A técnica for-loop é uma forma simples e eficiente de analisar todas as linhas de um arquivo de texto:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
A leitura de uma linha de cada vez tem a qualidade excelente que nem todo o arquivo precisa caber na memória ao mesmo tempo - útil se você quiser ver cada linha em um arquivo de 10 gigabytes sem usar 10 gigabytes de memória. O método f.readlines() lê todo o arquivo na memória e retorna seu conteúdo como uma lista de suas linhas. O método f.read() lê todo o arquivo em uma única string, o que pode ser uma maneira prática de lidar com o texto de uma só vez, como com expressões regulares que veremos mais tarde.
Para gravação, o método f.write(string) é a maneira mais fácil de gravar dados em um arquivo de saída aberto. Ou você pode usar "imprimir" com um arquivo aberto, como "print(string, file=f)".
Arquivos Unicode
Para ler e gravar arquivos codificados em Unicode, use um modo `'t'` e especifique explicitamente uma codificação:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
Exercite o desenvolvimento incremental
Ao criar um programa em Python, não escreva tudo em uma única etapa. Em vez disso, identifique apenas um primeiro marco, por exemplo, "a primeira etapa é extrair a lista de palavras." Escreva o código para atingir esse marco e exiba suas estruturas de dados nesse ponto. Depois, execute um sys.exit(0) para que o programa não seja executado nas partes não concluídas. Assim que o código do marco estiver funcionando, você poderá trabalhar no código para o próximo marco. Ver a impressão das variáveis em um determinado estado pode ajudar você a pensar em como transformar essas variáveis para chegar ao próximo estado. O Python é muito rápido com esse padrão, o que permite fazer uma pequena alteração e executar o programa para ver como ele funciona. Aproveite esse retorno rápido para criar seu programa em pequenas etapas.
Exercício: wordcount.py
Combinar todo o material básico do Python (strings, listas, dicts, tuplas, arquivos) experimente o exercício de resumo wordcount.py nos Exercícios básicos.