Tutorial da linguagem C++
As primeiras seções deste tutorial abordam o material básico já apresentado nos dois últimos módulos e forneceremos mais informações sobre conceitos avançados. Nossos Neste módulo, vamos abordar a memória dinâmica e mais detalhes sobre objetos e classes. Também são apresentados alguns tópicos avançados, como herança, polimorfismo, modelos, exceções e namespaces. Vamos estudar isso mais tarde no curso avançado de C++.
Design orientado a objetos
Esta é uma excelente tutorial sobre design orientado a objetos. Vamos aplicar metodologia apresentada aqui no projeto deste módulo.
Aprenda pelo exemplo 3
Neste módulo, nosso foco é praticar mais com ponteiros, orientados por objetos, design, matrizes multidimensionais e classes/objetos. Faça o seguinte: exemplos. Não podemos enfatizar o suficiente que a chave para se tornar um bom programador é praticar, praticar e praticar!Exercício #1: Praticar mais com os ponteiros
Se precisar praticar mais com os ponteiros, leia este recurso, que abrange todos os aspectos dos indicadores e apresenta muitos exemplos de programas.
Qual é o resultado do programa abaixo? Não execute o programa, mas desenhe a imagem da memória para determinar a saída.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Depois de determinar o resultado manualmente, execute o programa para ver se você está correto.
Exercício #2: Praticar mais com classes e objetos
Se precisar praticar mais com classes e objetos, aqui é um recurso que passa pela implementação de duas classes pequenas. Faça algumas hora de fazer os exercícios.
Exercício #3: Matrizes multidimensionais
Considere o seguinte programa:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}Há uma linha neste programa marcada como "Como esta linha funciona?" Você consegue descobrir? Confira aqui nossa explicação.
Crie um programa que inicialize uma matriz de 3 dimensões e preencha a 3a dimensão. com a soma dos três índices. Confira nossa solução.
Exercício #4: Um exemplo amplo de design externo
Aqui está um resumo exemplo de design orientado a objetos, que aborda todo o do início ao fim. O código final é escrito linguagem de programação, mas você poderá lê-la de acordo com o quanto você chegaram.
Reserve um tempo para analisar todo o exemplo. É um ótimo ilustração do processo e das ferramentas de design que o auxiliam.
Teste de unidade
Introdução
Os testes são uma parte essencial do processo de engenharia de software. Um teste de unidade é um tipo específico de teste, que verifica a funcionalidade de uma única e pequena módulo do código-fonte.O teste de unidade é sempre feito pelo engenheiro e é geralmente são feitas ao mesmo tempo em que codificam o módulo. Os drivers de teste que você usadas para testar as classes do Composer e do Database são exemplos de testes de unidade.
Os testes de unidade têm as características abaixo. Ele…
- testar um componente isoladamente
- são deterministas
- geralmente são associados a uma única classe
- evitar dependências em recursos externos, por exemplo, bancos de dados, arquivos, rede
- executar com rapidez
- pode ser executado em qualquer ordem
Existem estruturas e metodologias automatizadas que fornecem suporte e consistência para testes de unidade em grandes organizações de engenharia de software. Há algumas estruturas sofisticadas de teste de unidade de código aberto, que abordaremos mais adiante nesta aula.
Os testes que ocorrem como parte do teste de unidade são ilustrados abaixo.
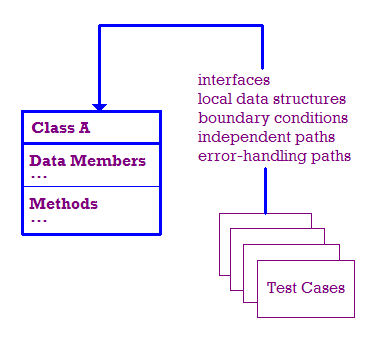
Em um mundo ideal, testamos:
- A interface do módulo é testada para garantir que as informações fluam para dentro e para fora corretamente.
- As estruturas de dados locais são examinadas para garantir que armazenam os dados corretamente.
- As condições de limite são testadas para garantir que o módulo funcione corretamente nos limites que limitam ou restringem o processamento.
- Testamos caminhos independentes no módulo para garantir que cada caminho, e
assim, cada instrução no módulo é executada pelo menos uma vez.
- Por fim, precisamos verificar se os erros são tratados corretamente.
Cobertura de código
Na realidade, não podemos ter uma "cobertura de código" completa nos nossos testes. A cobertura de código é um método de análise que determina quais partes de um software foram executados (cobertos) pelo pacote de casos de teste e quais partes não foi executado. Se tentarmos atingir 100% de cobertura, passaremos mais tempo programar testes de unidade do que programar o próprio código. Considere elaborar uma unidade testa todos os caminhos independentes do seguinte. Isso pode se tornar rapidamente exponencial.
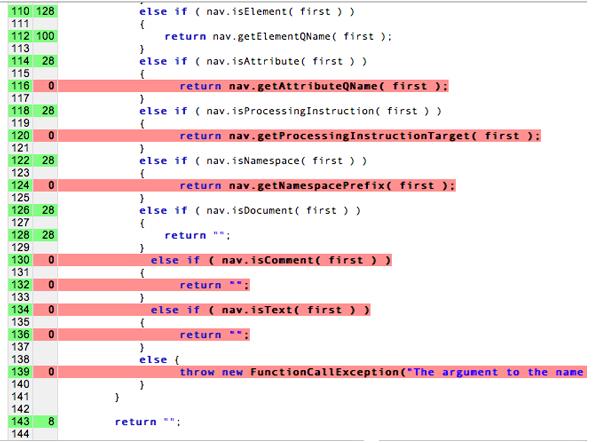
Neste diagrama, as linhas vermelhas não são testadas, é treinado e testado.
Em vez de tentar uma cobertura de 100%, nos concentramos em testes que aumentam nossa confiança se o módulo está funcionando corretamente. Testamos coisas como:
- Casos nulos
- Testes de intervalo, por exemplo, testes de valor positivo/negativo
- Casos extremos
- Casos de falha
- Testar os caminhos com maior probabilidade de serem executados na maioria das vezes
Estruturas de teste de unidade
A maioria das estruturas de teste de unidade usa declarações para testar valores durante a execução de um caminho. Declarações são instruções que verificam se uma condição é verdadeira. A resultado de uma declaração pode ser sucesso, falha não fatal ou falha fatal. Depois uma declaração for executada, o programa continuará normalmente se o resultado for de sucesso ou falha não fatal. Se ocorrer uma falha fatal, a função atual é cancelada.
Os testes consistem em código que configura o estado ou manipula seu módulo, acoplados com várias declarações que verificam os resultados esperados. Se todas as declarações em um teste forem bem-sucedidos, ou seja, retornar verdadeiro, e o teste será bem-sucedido; caso contrário ela vai falhar.
Um caso de teste contém um ou mais testes. Agrupamos testes em casos de teste que refletem a estrutura do código testado. Neste curso, vamos usar CPPUnit como nossa estrutura de teste de unidade. Com esse framework, podemos criar testes de unidade em C++ e executá-los automaticamente, fornecendo um relatório sobre o sucesso ou a falha de testes.
Instalação da unidade CPP
Baixe o código da unidade CPP SourceForge (link em inglês). Encontre um diretório apropriado e coloque o arquivo tar.gz nele. Depois, insira seguintes comandos (no Linux, Unix), substituindo o arquivo cppunit apropriado nome:
gunzip filename.tar.gz tar -xvf filename.tar
Se você estiver trabalhando no Windows, talvez seja necessário encontrar um utilitário para extrair o tar.gz . A próxima etapa é compilar as bibliotecas. Mude para o diretório cppunit. Existe um arquivo INSTALL que fornece instruções específicas. Normalmente, você precisa executar:
./configure make install
Se você encontrar problemas, consulte o arquivo INSTALL. As bibliotecas geralmente são que está no diretório "cppunit/src/cppunit". Para verificar se a compilação funcionou, acesse o diretório cppunit/examples/simple e digite "make". Se tudo estiver pronto, está tudo pronto.
Há um excelente tutorial disponível aqui. Siga este tutorial e crie a classe de número complexa e a respectiva e testes de unidade. Há vários outros exemplos no diretório cppunit/examples.
Por que eu tenho que fazer isso???
Os testes de unidade são muito importantes no setor por vários motivos. Você está já familiarizados com um motivo: precisamos de alguma forma de verificar nosso trabalho enquanto desenvolvimento de código. Mesmo quando estamos desenvolvendo um programa muito pequeno, escrever algum tipo de verificador ou driver para se certificar de que o programa faça o que é esperado.
Por uma longa experiência, os engenheiros sabem que as chances de um programa funcionar na primeira tentativa são muito pequenas. Os testes de unidade compilam essa ideia, autoverificações e repetíveis dos programas. As declarações substituem o uso ao inspecionar a saída. E, como os resultados são fáceis de interpretar, o teste passa ou falha), os testes podem ser executados repetidamente, fornecendo uma rede de segurança que torna seu código mais resiliente a mudanças.
Vamos colocar isso em termos concretos: quando você envia seu código finalizado pela primeira vez CVS, funciona perfeitamente. E ela continua funcionando perfeitamente por um tempo. Depois, um dia, outra pessoa altera seu código. Mais cedo ou mais tarde, alguém vai quebrar seu código. Você acha que eles perceberão por conta própria? Não é provável. Mas quando você é possível programar testes de unidade, há sistemas que podem executá-los automaticamente todos os dias. Eles são chamados de sistemas de integração contínua. Então, quando esse engenheiro X quebrar seu código, o sistema enviará e-mails mal-intencionados para eles até que eles corrijam reimplantá-lo. Mesmo que o engenheiro X seja VOCÊ!
Além de ajudar você a desenvolver e manter softwares seguros diante de mudanças, o teste de unidade:
- Cria uma especificação executável e uma documentação que permanecem sincronizadas. com o código. Em outras palavras, você pode ler um teste de unidade para aprender sobre o que que o módulo suporta.
- Ajuda você a separar os requisitos da implementação. Porque você está declarando comportamento visível externamente, você tem a oportunidade de pensar sobre isso explicitamente em vez de misturar ideias sobre como implementar o comportamento.
- Oferece suporte a experimentos. Se você tiver uma rede de segurança para alertar quando você tiver violado o comportamento de um módulo, é mais provável que experimente algumas coisas e reconfigurar seus designs.
- Melhora seus designs. Escrever testes de unidade completos geralmente exige a tornar seu código mais testável. Os códigos testáveis geralmente são mais modulares do que os não testáveis. o código-fonte.
- Mantém a qualidade alta. Um pequeno bug em um sistema crítico pode fazer com que perder milhões de dólares ou, pior ainda, a felicidade ou a confiança do usuário. A que os testes de unidade oferecem, reduzem essa possibilidade. Capturando insetos cedo, elas também permitem que as equipes de QA gastem tempo em tarefas mais sofisticadas cenários de falha em vez de relatar falhas óbvias.
Reserve um tempo para criar testes de unidade usando o CPPUnit para o aplicativo de banco de dados do Composer. Consulte o diretório cppunit/examples/ para receber ajuda.
Como o Google Funciona
IntroduçãoImagine um monge da Idade Média olhando para os milhares de manuscritos em os arquivos do mosteiro dele."Onde está aquela de Aristóteles..."

Felizmente para ele, os manuscritos são organizados por conteúdo e inscritos com símbolos especiais para facilitar a recuperação das informações contidas em cada um. Sem essa organização, seria muito difícil encontrar os manuscrito.
Atividade de armazenar e recuperar informações escritas de grandes coleções é chamada de recuperação de informações (IR, na sigla em inglês). Essa atividade tem se tornado importante ao longo dos séculos, especialmente com invenções como o papel e o prensam. Antes era algo em que apenas algumas pessoas estavam ocupadas. Agora, No entanto, centenas de milhões de pessoas se envolvem na recuperação de informações a cada quando usam um mecanismo de pesquisa ou pesquisam no computador.
Introdução à recuperação de informações

Dr. Seuss escreveu 46 livros infantis ao longo de 30 anos. Seus livros contavam de gatos, vacas e elefantes, de quem é, sorridentes e lorax. Você se lembra quais criaturas estavam em qual história? Se você não for um familiar responsável, apenas as crianças podem contar qual conjunto de histórias do Dr. Seuss tem as criaturas:
(COW e BEE) ou CROWS
Vamos aplicar alguns modelos clássicos de recuperação de informações para resolver esse problema. problema.
Uma abordagem óbvia é a força bruta: pegue todas as 46 histórias de Dr. Seuss e comece leitura. Para cada livro, anote quais contêm as palavras COW e BEE, e ao mesmo tempo, procure livros que contenham a palavra CROWS. Computadores são muito mais rápido nisso do que nós. Se tivermos todo o texto dos livros do Dr. Seuss em formato digital, por exemplo, como arquivos de texto, basta usar o comando grep nos arquivos. Para um pequena coleção como os livros do Dr. Seuss, essa técnica funciona bem.
No entanto, há muitas situações em que precisamos de mais. Por exemplo, a coleção de todos os dados on-line atualmente são muito grandes para serem processados pelo grep. Nós também não queremos apenas os documentos que correspondam à condição, já nos acostumamos a classificando-os de acordo com a relevância.
Outra abordagem além de grep é criar um índice dos documentos em uma coleção antes de realizar a pesquisa. Um índice nas IR é semelhante a um índice no de um livro didático. Fazemos uma lista de todas as palavras (ou termos) em cada A história do Dr. Seuss, sem palavras como "o", "e" e outros conjuntivos, preposições etc. (chamadas de palavras de parada). Em seguida, representamos essas informações de modo a facilitar a localização dos termos e a identificação as histórias em que estão.
Uma representação possível é uma matriz com as histórias na parte superior e os termos listados em cada linha. Um “1” em uma coluna indica que o termo aparece na história daquela coluna.
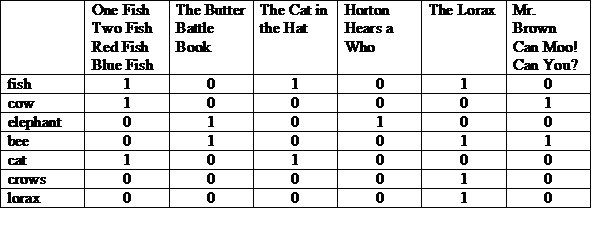
Cada linha ou coluna é vista como um vetor de bit. O vetor de bit de uma linha indica em quais matérias o termo aparece. O vetor de bit de uma coluna indica quais termos aparecem na história.
Voltando ao nosso problema original:
(COW e BEE) ou CROWS
Pegamos os vetores de bit para esses termos e primeiro fazemos uma operação bit a bit AND e depois fazemos um bit a bit OR no resultado.
(100001 e 010011) ou 000010 = 000011
A resposta: "Sr. Marrom pode muuuuuuu! Você consegue?" e “O Lorax”. Esta é uma ilustração do modelo de recuperação booleana, que é um modelo de “correspondência exata”.
Suponha que expandíssemos a matriz para incluir todas as histórias do Dr. Seuss e todas termos relevantes nas matérias. A matriz cresceria consideravelmente, e um importante observação é que a maioria das entradas seria 0. Uma matriz provavelmente não é o melhor representação do índice. Precisamos encontrar uma maneira de armazenar apenas os números 1.
Algumas melhorias
A estrutura usada em IR para resolver esse problema é chamada de índice invertido. Mantemos um dicionário de termos e, para cada termo, temos uma lista que registre os documentos em que o termo ocorre. Essa lista é chamada de postagens lista. Uma lista com links simples funciona bem para representar essa estrutura, conforme mostrado a seguir.
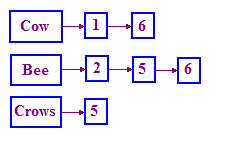
Se você não estiver familiarizado com as listas vinculadas, faça uma pesquisa no Google sobre "links
lista em C++", e você encontrará muitos recursos que descrevem como criá-la,
e como ela é usada. Vamos abordar isso com mais detalhes em um módulo futuro.
Usamos IDs de documentos (DocIDs) em vez do nome do história. Também classificamos esses DocIDs, já que isso facilita o processamento de consultas.
Como processamos uma consulta? Para o problema original, primeiro encontramos os posts COW e a lista de postagens do BEE. Em seguida, nós os “mesclamos”:
- Mantenha os marcadores nas duas listas e analise as duas listas de postagens. ao mesmo tempo.
- Em cada etapa, compare o DocID apontado pelos dois ponteiros.
- Se forem iguais, coloque esse DocID em uma lista de resultados; caso contrário, avance o ponteiro. apontando para o docID menor.
Veja como criar um índice invertido:
- Atribua um DocID a cada documento de interesse.
- Para cada documento, identifique seus termos relevantes (tokenize).
- Para cada termo, crie um registro que consiste no termo, o DocID em que é encontrado e uma frequência nesse documento. Pode haver várias registros de um termo específico se ele aparecer em mais de um documento.
- Classifique os registros por termo.
- Criar o dicionário e a lista de ofertas processando registros únicos para um termo e também combinar os diversos registros para termos que aparecem em mais mais de um documento. Crie uma lista vinculada de DocIDs (em ordem de classificação). Cada também tem uma frequência, que é a soma das frequências em todos os registros de um termo.
O projeto
Encontre vários documentos de texto simples longos para experimentar. A projeto é criar um índice invertido a partir dos documentos, usando os algoritmos descritas acima. Também será necessário criar uma interface para a entrada de consultas e um mecanismo para processá-las. Encontre um parceiro de projeto no fórum.
Aqui está um possível processo para concluir este projeto:
- A primeira coisa a fazer é definir uma estratégia para identificar termos nos documentos. Faça uma lista de todas as palavras finais que você imaginar e escreva uma função que lê as palavras nos arquivos, salva os termos e elimina as palavras irrelevantes. Pode ser necessário adicionar mais palavras irrelevantes à lista conforme você analisa a lista de termos de uma iteração.
- Crie casos de teste de CPPUnit para testar sua função e um makefile para trazer tudo para seu build. Verifique seus arquivos no formato CVS, especialmente se de trabalhar com parceiros. Você pode pesquisar como abrir sua instância do CVS para engenheiros remotos.
- Adicionar processamento para incluir dados de local, ou seja, em qual arquivo e onde o arquivo é um termo localizado? Você pode querer descobrir um cálculo para definir o número da página ou o número do parágrafo.
- Crie casos de teste de CPPUnit para testar essa funcionalidade extra.
- Criar um índice invertido e armazenar os dados de local no registro de cada termo.
- Crie mais casos de teste.
- Criar uma interface para permitir que um usuário insira uma consulta.
- Usando o algoritmo de pesquisa descrito acima, processe o índice invertido e retornam os dados de localização ao usuário.
- Não deixe de incluir também casos de teste para essa parte final.
Como fizemos em todos os projetos, use o fórum e o chat para encontrar parceiros e compartilhar ideias.
Um recurso extra
Uma etapa de processamento comum em muitos sistemas de IR é chamada de stemming. A A ideia principal por trás da derivação é que os usuários que pesquisam informações sobre “recuperação” também terá interesse em documentos com informações contendo “recuperar”, “recuperado”, “recuperando” e assim por diante. Os sistemas podem ser suscetíveis a erros devido a uma má derivação, então isso é um pouco complicado. Por exemplo, um usuário interessado na “recuperação de informações” pode receber um documento intitulado “Informações sobre Recuperadores” devido à derivação. Um algoritmo útil para derivação é o Algoritmo Porter.