מדריך לשפת C++
החלקים המוקדמים של מדריך נלמד על החומר הבסיסי שכבר הוצג בשני המודולים האחרונים ונספק מידע נוסף על מושגים מתקדמים. שלנו ביחידת הלימוד הזו נתמקד בזיכרון דינמי ובפרטים נוספים על אובייקטים ומחלקות. מוצגים גם כמה נושאים מתקדמים, כמו ירושה, פולימורפיזם, תבניות, חריגים ומרחבי שמות. נלמד אותם מאוחר יותר בקורס C++ למתקדמים.
עיצוב ממוקד חפצים
זה מעולה מדריך בנושא עיצוב ממוקד אובייקטים. ניישם את שהוצגו כאן בפרויקט של יחידת הלימוד הזו.
למידה מדוגמה 3
ביחידת הלימוד הזו נתמקד בתרגול נוסף של זיהוי סמנים, התמקדות באובייקט מערכים רב-ממדיים, מחלקות/אובייקטים. עליכם לבצע את הפעולות הבאות דוגמאות. אי אפשר להדגיש מספיק שהמפתח למתכנת טוב הוא תרגול, תרגול, תרגול!תרגיל מס' 1: תרגול נוסף באמצעות מצביעים
אם אתם צריכים תרגול נוסף עם מצביעים, כדאי לקרוא את ההסבר הזה מקור מידע שמכסה את כל ההיבטים של המצביעים ומספק דוגמאות רבות לתוכניות.
מה הפלט של התוכנית הבאה? אין להפעיל את התוכנית, משרטטים את תמונת הזיכרון כדי לקבוע את הפלט.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}לאחר שקבעתם את הפלט באופן ידני, הריצו את התוכנית כדי לראות אם נכון.
תרגיל מס' 2: תרגול נוסף עם שיעורים ואובייקטים
אם אתם צריכים תרגול נוסף עם כיתות ואובייקטים, כאן משאב בתהליך ההטמעה של שתי מחלקות קטנות. רוצה לנסות? הזמן לבצע את תרגילים.
תרגיל מס' 3: מערכים רב-ממדיים
כדאי להשתמש בתוכנית הבאה:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}חלק בתוכנית הזו מסומן בתור "How does this line work? " (איך פועל הקו הזה?) - תוכל להבין את זה? כאן תמצאו את ההסבר שלנו.
כתיבת תוכנית שמאתחלת מערך בן 3 ממדים וממלאת את המימד השלישי עם הסכום של כל שלושת האינדקסים. כאן מופיע הפתרון שלנו.
תרגיל מס' 4: דוגמה לעיצוב נרחב של OO
כאן יש הסבר מפורט דוגמה לעיצוב ממוקד-אובייקט, שעוברת את כל מתחילתו ועד סופו. הקוד הסופי נכתב ב-Java בשפת התכנות, אבל תוכלו לקרוא אותה לפי המרחק הגיעו.
מומלץ להקדיש זמן לעיון בדוגמה כולה. זה מעולה איור של התהליך ושל כלי העיצוב שתומכים בו.
בדיקות יחידה (unit testing)
מבוא
הבדיקות הן חלק קריטי בתהליך הנדסת התוכנה. בדיקת יחידה (unit testing) סוג מסוים של בדיקה, שבודק את הפונקציונליות של בדיקה של קוד המקור.בדיקת יחידה תמיד מתבצעת על ידי המהנדס, בדרך כלל מתבצעת באותו זמן שבו מתכנתים את המודול. גורמי המבחן דוגמאות לבדיקות יחידות (unit testing) שמשמשות לבדיקת המחלקות Composer ו-Database.
לבדיקות היחידות יש את המאפיינים הבאים. הן...
- בדיקת רכיב בבידוד
- הם דטרמיניסטיים
- בדרך כלל ממופים לכיתה אחת
- להימנע מתלות במשאבים חיצוניים, למשל מסדי נתונים, קבצים, רשת
- לבצע במהירות
- אפשר להריץ בכל סדר שהוא
יש מתודולוגיות ומסגרות אוטומטיות שמספקות תמיכה עקביות לבדיקות יחידות בארגונים גדולים של הנדסת תוכנה. יש כמה מסגרות מתוחכמות לבדיקה של יחידות קוד פתוח, בהמשך השיעור.
הבדיקות שמתבצעות כחלק מבדיקת היחידה מוצגות בהמשך.
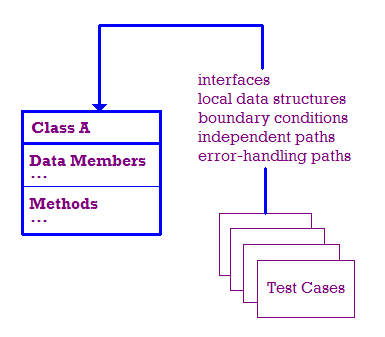
בעולם אידיאלי, אנחנו בודקים את הדברים הבאים:
- ממשק המודול נבדק כדי לוודא שהמידע עובר פנימה והחוצה בצורה נכונה.
- מבני נתונים מקומיים נבדקים כדי לוודא שהם מאחסנים נתונים כראוי.
- תנאי הגבולות נבדקים כדי לוודא שהמודול פועל כמו שצריך בגבולות שמגבילים או מגבילים את העיבוד.
- אנחנו בודקים נתיבים עצמאיים דרך המודול כדי לוודא שכל נתיב,
כך שכל הצהרה במודול מבוצעת לפחות פעם אחת.
- לבסוף, אנחנו צריכים לוודא שהשגיאות מטופלות כראוי.
רמת הכיסוי של הקוד
בפועל, אנחנו לא יכולים לקבל "כיסוי קוד" מלא בבדיקות שלנו. כיסוי קוד הוא שיטת ניתוח שקובעת אילו חלקים של תוכנה בוצעה (מכוסה) על ידי חבילת מקרי הבדיקה, ואילו חלקים לא בוצעה. אם ננסה להשיג כיסוי של 100%, נקדיש יותר זמן לכתוב בדיקות יחידה (unit testing) מאשר לכתוב את הקוד בפועל! כדאי לחשוב על יחידה את כל הנתיבים הבלתי תלויים הבאים. פעולה זו יכולה להפוך במהירות בעיה מעריכית.
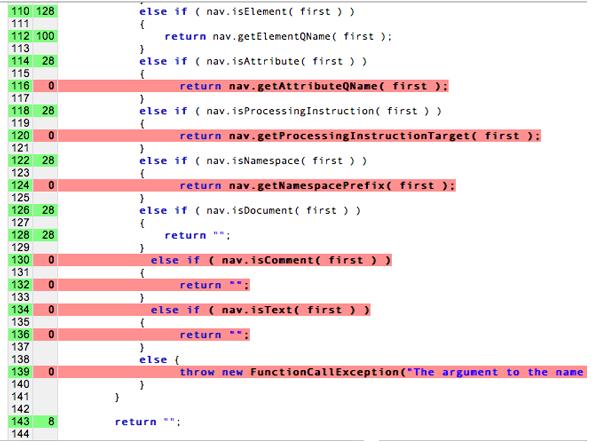
בתרשים הזה, הקווים האדומים לא נבדקים, והקווים הלא צבעוניים נבדק.
במקום לנסות כיסוי של 100%, אנחנו מתמקדים בבדיקות שמגדילות את רמת הביטחון שלנו שהמודול פועל כמו שצריך. אנחנו בודקים דברים כמו:
- אפסים
- בדיקות טווח, למשל בדיקת ערך חיובי/שלילי
- כיסויי קצה
- מקרים של כשל
- בדיקת הנתיבים שיש להם סיכוי גבוה להפעלה במשך רוב הזמן
מסגרות לבדיקת יחידות
רוב ה-frameworks של בדיקות יחידה משתמשות בטענות נכוֹנוּת (assertions) כדי לבדוק ערכים במהלך ביצוע של נתיב. טענות נכוֹנוּת הן הצהרות שבודקות אם תנאי מסוים מתקיים. תוצאה של טענת נכוֹנוּת (assertion) יכולה להיות הצלחה, כשל לא חמור או כשל חמור. אחרי מתבצעת טענת נכוֹנוּת (assertion), התוכנה תמשיך כרגיל אם התוצאה הצלחה או כשל לא חמור. אם מתרחש כשל חמור, הפונקציה הנוכחית בוטל.
בבדיקות יש קוד שמגדיר את המצב או מבצע שינויים במודול, בצימוד עם כמה טענות שמאמתות את התוצאות הצפויות. אם כל הטענות נכונות בבדיקה אם היא הצליחה, כלומר מוחזרת, ואז היא מצליחה. אחרת נכשל.
מקרה בדיקה מכיל בדיקה אחת או יותר. אנחנו מקבצים את הבדיקות למקרי בדיקה לשקף את המבנה של הקוד שנבדק. בקורס הזה נשתמש CPPUnit כמסגרת לבדיקת יחידה שלנו. באמצעות המסגרת הזו, אנחנו יכולים לכתוב בדיקות יחידה ב-C++ ולהריץ אותם באופן אוטומטי, תוך מתן דוח על ההצלחה או הכישלון של בדיקות.
התקנת CPPUnit
אפשר להוריד את הקוד CPPUnit מ- SourceForge. מוצאים ספרייה מתאימה ומציבים בה את קובץ tar.gz. לאחר מכן, מזינים את הפקודות הבאות (ב-Linux, Unix) מחליפות את קובץ ה-cppunit המתאים שם:
gunzip filename.tar.gz tar -xvf filename.tar
אם אתם עובדים ב-Windows, ייתכן שתצטרכו למצוא כלי עזר לחילוץ tar.gz. . השלב הבא הוא להדר את הספריות. שינוי לספריית cppunit. יש שם קובץ INSTALL שמספק הוראות ספציפיות. בדרך כלל, שצריך להריץ:
./configure make install
אם תיתקלו בבעיות, יש לעיין בקובץ INSTALL. בדרך כלל הספריות נמצאת בספרייה cppunit/src/cppunit. כדי לבדוק שהקומפילציה עבדה, נכנסים לספרייה cppunit/examples/simple ומקלידים 'make'. אם המיקום הכל הולך ומורכב, אז הכול מוכן.
יש מדריך מעולה כאן. עברו על המדריך הזה ויוצרים מחלקה של מספרים מרוכבים ואת המחלקה בדיקות יחידה (unit testing). יש כמה דוגמאות נוספות בספרייה cppunit/examples.
למה עליי לעשות זאת...
בדיקת יחידות היא פעולה חיונית בתחום, מכמה סיבות. היתרה שלך כבר קיימת סיבה אחת: אנחנו צריכים דרך כלשהי לבדוק את העבודה שלנו בפיתוח של קוד. גם כשאנחנו מפתחים תוכנית קטנה מאוד, אנחנו באופן אינסטימנטלי לכתוב סוג של בודק או מנהל התקן כדי לוודא שהתוכנה שלנו עושה את מה שמצופה.
מניסיון רב, המהנדסים יודעים שהסיכויים שתוכנית תעבוד בניסיון הראשון, הם קטנים מאוד. בדיקות יחידה (unit testing) מתבססות על הרעיון הזה בדיקה עצמית שאפשר לחזור עליה. טענות הנכוֹנוּת (assertions) מחליפות את בדיקת הפלט. ובגלל שקל לפרש את התוצאות עובר או נכשל), ניתן להריץ את הבדיקות שוב ושוב, כל עוד רשת ביטחון שבזכותה הקוד עמיד יותר לשינויים.
נסח את זה במונחים קונקרטיים: בפעם הראשונה שאתם שולחים את הקוד המוגמר CVS, זה עובד מושלם. והוא ממשיך לפעול בצורה מושלמת למשך זמן מה. לאחר מכן יום אחד, מישהו אחר ישנה את הקוד. במוקדם או מאוחר יותר שמישהו יישבר בקוד שלכם. את חושבת שהם יבחינו בעצמם? לא סביר. אבל כאשר לכתוב בדיקות יחידה (unit testing), יש מערכות שיכולות להריץ אותן באופן אוטומטי, כל יום. המערכות האלה נקראות מערכות אינטגרציה רציפה. אז כשהמהנדס X יפרו את הקוד, המערכת תשלח אליו אימיילים זדוניים עד שהם יפתרו את הבעיה. את זה. אפילו אם המהנדס X הוא אתה!
בנוסף לעזרה בפיתוח של תוכנות, ולאחר מכן בשמירה על הבטיחות של התוכנה לאור השינוי, בדיקת יחידה:
- יצירת מפרט הפעלה ותיעוד שנשאר מסונכרן בקוד. במילים אחרות, אתם יכולים לקרוא מבחן יחידה כדי להבין ההתנהגות שנתמכת במודול.
- עוזר לכם להבדיל בין הדרישות לבין ההטמעה. כי את/ה מצהיר/ה על התנהגות גלויה לגורמים חיצוניים, יש לך הזדמנות לחשוב על זה בצורה מפורשת במקום לשלב רעיונות לגבי האופן שבו ניתן ליישם את ההתנהגות.
- תומך בניסויים. אם יש לכם רשת ביטחון שתתריע בפניכם אם השבתתם את ההתנהגות של מודול, יש סיכוי גבוה יותר לנסות דברים ולהגדיר מחדש את העיצובים.
- משפר את העיצובים. בדרך כלל, כדי לכתוב מבחנים יסודיים של היחידה צריך כדי שניתן יהיה לבדוק את הקוד בקלות רבה יותר. לרוב קוד שניתן לבדוק הוא מודולרי יותר מאשר קוד שלא ניתן לבדיקה
- שמירה על איכות גבוהה. באג קטן במערכת קריטית עלול לגרום לחברה לאבד מיליוני דולרים, או אפילו גרוע יותר, את שביעות הרצון או האמון של המשתמשים. רשת הביטחון שבדיקות יחידה מפחיתות אפשרות זו. על ידי איתור באגים בשלב מוקדם, הם גם מאפשרים לצוותי ה-QA לבזבז זמן על כשלים, במקום לדווח על כשלים ברורים.
כדאי להקדיש זמן לכתיבת בדיקות יחידה באמצעות CPPUnit עבור אפליקציית מסד הנתונים של Composer. לקבלת עזרה, אפשר לעיין בספרייה cppunit/examples/ .
הסבר על Google
מבואדמיינו נזיר בימי הביניים מביט באלפי כתבי יד בארכיון המנזר שלו."Where is that is that by Aristotle... "

למזלו, כתבי היד מסודרים לפי תוכן וחרוטים עם סמלים מיוחדים כדי לאפשר אחזור של המידע שכלול של כל אחת מהן. ללא ארגון כזה, יהיה קשה מאוד למצוא את כתב יד.
הפעילות של אחסון ואחזור מידע כתוב מאוספים גדולים נקראת אחזור מידע (IR). הפעילות הזו הולכת וגדלה שהיו חשובים במשך מאות שנים, במיוחד עם המצאות כמו נייר ודפוס יש להקיש. בעבר היא הייתה מקום שרק מעט אנשים היו בו. עכשיו, אבל מאות מיליוני אנשים מעורבים באחזור מידע בכל כשהם משתמשים במנוע חיפוש או מבצעים חיפוש במחשב.
תחילת העבודה עם אחזור מידע

ד"ר סוס כתב 46 ספרי ילדים במשך 30 שנה. סיפרו את הספרים שלו של חתולים, פרות ופילים, כמו חתולים, מוחות ולרקסים. זכור לך באילו יצורים כללו יצורים? רק ילדים יכולים להיות הורים, מספרות באיזה סיפורים של ד"ר סוס יש את היצורים:
(COW ו-BEE) או CROWS
ניישם כמה מודלים קלאסיים לאחזור מידע כדי לעזור לנו לפתור את הבעיה הזו .
גישה ברורה היא כוחה של ד"ר סוס: מקבלים את כל 46 הסיפורים של ד"ר סוס, ומתחילים קריאה. עבור כל ספר, שימו לב אילו מילים מכילות את המילים COW ו-BEE, וגם במקביל, לחפש ספרים שכוללים את המילה CROWS. מחשבים הם הרבה יותר יותר מהר מאיתנו. אם יש לנו את כל הטקסט מהספרים של ד"ר סוס בפורמט דיגיטלי, למשל בקובצי טקסט, אנחנו יכולים פשוט לעבור בין הקבצים. עבור קטן כמו הספרים של ד"ר סוס, הטכניקה הזו עובדת כמו שצריך.
עם זאת, יש מצבים רבים שבהם אנחנו צריכים יותר. לדוגמה, האוסף מכל הנתונים שקיימים כרגע באינטרנט, גדול מדי מכדי ש-gRep. אנחנו גם לא רוצה רק את המסמכים שתואמים למצב שלנו, התרגלנו כדי שהם יקבלו דירוג לפי הרלוונטיות שלהם.
גישה אחרת מלבד gRep היא ליצור אינדקס של המסמכים באוסף מראש לביצוע החיפוש. מדד ב-IR דומה למדד בחלק האחורי של ספר לימוד. אנחנו יוצרים רשימה של כל המילים (או המונחים) בכל אחת מהמילים את סיפורו של ד"ר סוס, בלי מילים כמו "את", "ו" וכל קשרים אחרים, מילות יחס וכו' (המילים האלה נקראות מילים מעצורות). לאחר מכן אנחנו מייצגים את המידע הזה באופן שיאפשר למצוא את המונחים ולזהות הסיפורים שהם מכילים.
אחד מהייצוגים האפשריים הוא מטריצה עם הסיפורים שלמעלה, המונחים שמופיעים בכל שורה. המספר 1 בעמודה מציין שהמונח מופיע בסיפור של אותה עמודה.
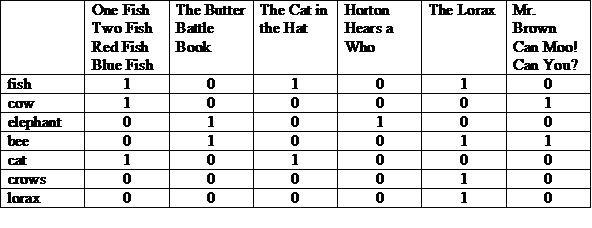
אנחנו יכולים לראות כל שורה או עמודה בתור וקטור ביט. וקטור ביט של שורה מציין שבהם מופיע המונח. וקטור ביט של עמודה מציין אילו מונחים מופיעים בסיפור.
בחזרה לבעיה המקורית שלנו:
(COW ו-BEE) או CROWS
אנחנו לוקחים את הווקטורים של הסיביות עבור המונחים האלה, וקודם עושים קצת AND, ואז או קצת יותר חכמה לגבי התוצאה.
(100001 ו-010011) או 000010 = 000011
התשובה: "מר. Brown Can Moo! תוכל?" ו-The Lorax. זהו איור של מודל אחזור בוליאני, שהוא מודל "התאמה מדויקת".
נניח שהחלטנו להרחיב את המטריצה ולכלול את כל הסיפורים של ד"ר סוס ואת כל הסיפורים מונחים רלוונטיים בכתבות. המטריצה תגדל באופן משמעותי, ערך התצפית הוא שרוב הערכים יהיו 0. מטריצה היא כנראה לא הכי טובה מייצגים את האינדקס. אנחנו צריכים למצוא דרך לאחסן רק את הדפים האלה.
שיפורים מסוימים
המבנה שמשמש ב-IR כדי לפתור את הבעיה הזו נקרא אינדקס הפוך. אנחנו שומרים מילון של מונחים, ולאחר מכן לכל מונח יש רשימה שמתעד את המסמכים שבהם המונח מופיע. הרשימה הזו נקראת פוסטים list. רשימה שמקושרת בנפרד עוזרת לייצג את המבנה הזה, כפי שמוצג כאן שלמטה.
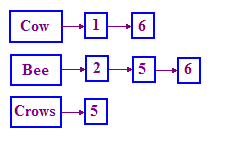
אם אינך מכיר רשימות מקושרות, פשוט ערוך חיפוש ב-Google ב"מקושרים"
ב-C++ ', ותמצאו משאבים רבים שמתארים איך ליצור מפתח כזה,
ואופן השימוש בו. נעסוק בנושא הזה בהרחבה במודול מאוחר יותר.
שימו לב שאנחנו משתמשים במזהי מסמכים (DocIDs) במקום בשם של מסיפורים. אנחנו גם ממיינים את מזהי המסמכים האלה כי כך קל לעבד שאילתות.
איך אנחנו מעבדים שאילתה? בשביל הבעיה המקורית, קודם כל מצאנו את הפוסטים של COW ואז את רשימת הפרסומים של BEE. לאחר מכן אנחנו "ממזגים" אותם יחד:
- נהל את הסמנים בשתי הרשימות ועבר בין שתי רשימות הפרסומים בו-זמנית.
- בכל שלב, משווים את ה-docID שאליו מצביעים שני המצביעים.
- אם הם זהים, יש להוסיף את ה-DocsID לרשימת התוצאות, אחרת לקדם את הסמן שמצביעים על ה-docID הקטן יותר.
כך ניתן לבנות אינדקס הפוך:
- מקצים DocID לכל מסמך רצוי.
- מציינים את המונחים הרלוונטיים לכל מסמך (יצירת אסימון).
- עבור כל מונח, יוצרים רשומה שכוללת את המונח ואת ה-DocsID שבו מופיע המונח נמצא, והתדירות במסמך הזה. חשוב לשים לב, יכולות להיות מספר רשומות של מונח מסוים אם הן מופיעות בכמה מסמכים.
- ממיינים את הרשומות לפי מונח.
- צור את רשימת המילון והפרסומים על ידי עיבוד רשומות בודדות עבור וגם שילוב של מספר הרשומות עבור מונחים שמופיעים ממסמך אחד. יוצרים רשימה מקושרת של מזהי DocID (בסדר ממוין). כל אחד יש גם תדירות שהיא סכום התדרים בכל הרשומות לתקופה מסוימת.
הפרויקט
מוצאים כמה מסמכים ארוכים בטקסט ללא הצפנה שאפשר להתנסות בהם. הוא ליצור אינדקס הפוך מהמסמכים, באמצעות האלגוריתמים שתוארו למעלה. תצטרכו גם ליצור ממשק לקלט של שאילתות ומנוע לעיבוד שלהם. תוכלו למצוא שותף לפרויקטים בפורום.
הנה תהליך אפשרי להשלמת הפרויקט:
- הדבר הראשון שצריך לעשות הוא להגדיר אסטרטגיה לזיהוי מונחים במסמכים. הכן רשימה של כל מילות המעצור שאפשר לחשוב עליהן וכתוב פונקציה קורא את המילים בקבצים, שומר את המונחים ומבטל את מילות העצירה. ייתכן שתצטרכו להוסיף לרשימה עוד מילות עצירה בזמן שתבדקו את הרשימה במונחים של איטרציה.
- כתבו מקרי בדיקה ל-CPPUnit כדי לבדוק את הפונקציה שלכם, ו-Makefile שיביא את כל מה שאתם צריכים יחד ל-build שלכם. לבדוק את הקבצים ב-CVS, במיוחד אם בעבודה עם שותפים. כדאי לבדוק איך פותחים מופע של CVS ועד למהנדסים מרחוק.
- הוספת עיבוד כדי לכלול נתוני מיקום, כלומר איזה קובץ ואיפה הקובץ הוא מונח? אולי כדאי לבצע חישוב כדי להגדיר במספר הדף או במספר הפסקה.
- כתבו מקרי בדיקה של CPPUnit כדי לבדוק את הפונקציונליות הנוספת הזו.
- יוצרים אינדקס הפוך ושומרים את נתוני המיקום ברשומה של כל מונח.
- כדאי לכתוב עוד מקרי בדיקה.
- לעצב ממשק שמאפשר למשתמש להזין שאילתה.
- באמצעות אלגוריתם החיפוש המתואר למעלה, מעבדים את האינדקס ההפוך יחזיר את נתוני המיקום למשתמש.
- הקפידו לכלול גם מקרי בדיקה עבור החלק הסופי הזה.
כמו שעשינו בכל הפרויקטים, השתמשו בפורום ובצ'אט כדי למצוא שותפים לפרויקטים ולשתף רעיונות.
תכונה נוספת
שלב עיבוד נפוץ במערכות IR רבות נקרא יצירת גזע. הרעיון העיקרי שעומד מאחורי חילוץ הוא שמשתמשים שמחפשים מידע על "אחזור" יתעניין גם במסמכים שיש בהם מידע שמכיל "אחזור", 'אחזור', 'אחזור' וכו'. מערכות יכולות להיות חשופות לשגיאות עקב לגזע גרוע, אז זה קצת מסובך. לדוגמה, משתמש שמתעניין ב'אחזור מידע' עשוי לקבל מסמך שהכותרת שלו היא 'מידע על אחזורים" בגלל גזע. אלגוריתם שימושי להגרלה היא אלגוריתם של ניוד.