
1. ข้อควรทราบก่อนที่จะเริ่มต้น
Codelab นี้ออกแบบมาให้สร้างขึ้นจากผลลัพธ์สุดท้ายของ Codelab ก่อนหน้าในซีรีส์นี้สําหรับการตรวจหาสแปมความคิดเห็นโดยใช้ TensorFlow.js
ใน Codelab ล่าสุด คุณสร้างหน้าเว็บที่ใช้งานได้เต็มรูปแบบสําหรับบล็อกวิดีโอสมมติ คุณสามารถกรองความคิดเห็นเพื่อหาจดหมายขยะก่อนที่จะส่งไปยังเซิร์ฟเวอร์เพื่อจัดเก็บข้อมูล หรือไปยังไคลเอ็นต์อื่นๆ ที่เชื่อมต่อโดยใช้โมเดลการตรวจหาความคิดเห็นฝึกล่วงหน้าที่ขับเคลื่อนโดย TensorFlow.js ในเบราว์เซอร์
ผลลัพธ์สุดท้ายของ Codelab ดังกล่าวมีดังนี้
แม้ว่าวิธีนี้จะใช้ได้ผลเป็นอย่างดี แต่ยังมีปัญหา Edge Case ที่ไปตรวจหาไม่พบ คุณสามารถฝึกโมเดลอีกครั้งโดยคํานึงถึงสถานการณ์ที่ไม่สามารถจัดการได้
Codelab นี้มุ่งเน้นที่การประมวลผลภาษาธรรมชาติ (ศิลปะในการทําความเข้าใจภาษามนุษย์ด้วยคอมพิวเตอร์) และแสดงวิธีการแก้ไขเว็บแอปที่มีอยู่ซึ่งสร้างขึ้นมา (ขอแนะนําอย่างยิ่งให้คุณเรียกใช้ Codelab ตามลําดับ) เพื่อจัดการกับปัญหาสแปมความคิดเห็นที่เกิดขึ้นจริงได้ ซึ่งนักพัฒนาเว็บจํานวนมากต้องพบเจอกับการทํางานอัตโนมัติที่มีอยู่มากมายในเว็บแอปยอดนิยมที่มีจํานวนมากขึ้นเรื่อยๆ ในปัจจุบัน
ใน Codelab นี้ คุณจะได้พัฒนาไปอีก 1 ขั้นตอนโดยการฝึกโมเดล ML ใหม่ให้พิจารณาการเปลี่ยนแปลงของเนื้อหาข้อความสแปมที่อาจมีการเปลี่ยนแปลงเมื่อเวลาผ่านไป โดยอิงตามแนวโน้มปัจจุบันหรือหัวข้อการสนทนายอดนิยมที่ช่วยให้คุณอัปเดตโมเดลอยู่เสมอและคํานึงถึงการเปลี่ยนแปลงดังกล่าว
สิ่งที่ต้องมีก่อน
- สิ้นสุด Codelab แรกในชุดนี้เรียบร้อยแล้ว
- ความรู้เบื้องต้นเกี่ยวกับเทคโนโลยีเว็บ ซึ่งรวมถึง HTML, CSS และ JavaScript
สิ่งที่คุณจะสร้าง
คุณจะนําเว็บไซต์ที่สร้างก่อนหน้านี้มาใช้ซ้ําสําหรับบล็อกวิดีโอสมมติที่มีส่วนความคิดเห็นแบบเรียลไทม์และอัปเกรดเพื่อโหลดโมเดลการตรวจจับสแปมเวอร์ชันการฝึกที่กําหนดเองโดยใช้ TensorFlow.js เพื่อให้ทํางานได้ดียิ่งขึ้นในกรณีที่ Edge อาจเคยดําเนินการไม่สําเร็จก่อนหน้านี้ แน่นอนว่านักพัฒนาเว็บหรือวิศวกรอาจเปลี่ยน UX สมมติเพื่อใช้ซ้ําในเว็บไซต์อื่นๆ ที่คุณอาจกําลังพัฒนาอยู่ทุกวัน และปรับโซลูชันให้เหมาะกับกรณีการใช้งานของลูกค้า เช่น บล็อก ฟอรัม หรือ CMS บางรูปแบบ เช่น Drupal
มาเริ่มกันเลย...
สิ่งที่จะได้เรียนรู้
คุณจะ
- ระบุปัญหา Edge ที่โมเดลก่อนการฝึกล้มเหลว
- ฝึกโมเดลการแยกประเภทจดหมายขยะที่สร้างขึ้นโดยใช้ตัวสร้างโมเดลอีกครั้ง
- ส่งออกโมเดล Python นี้เป็นรูปแบบ TensorFlow.js เพื่อใช้ในเบราว์เซอร์
- อัปเดตโมเดลที่โฮสต์และพจนานุกรมด้วยโมเดลที่ฝึกใหม่และตรวจสอบผลลัพธ์
ทําความคุ้นเคยกับ HTML5, CSS และ JavaScript สําหรับห้องทดลองนี้ นอกจากนี้ คุณจะเรียกใช้โค้ด Python บางส่วนผ่านสมุดบันทึกและโควต้า & โควต้าสําหรับการฝึกโมเดลที่สร้างโดยใช้โปรแกรมสร้างโมเดลอีกครั้ง แต่ไม่คุ้นเคยกับ Python
2. ตั้งค่าโค้ด
คุณจะใช้ Glitch.com เพื่อโฮสต์และแก้ไขเว็บแอปพลิเคชันอีกครั้ง หากยังไม่ได้ทํา Codelab ที่จําเป็นเบื้องต้นให้เสร็จสมบูรณ์ คุณโคลนผลการค้นหาที่นี่เป็นจุดเริ่มต้นได้ หากมีข้อสงสัยเกี่ยวกับวิธีทํางานของโค้ด ขอแนะนําอย่างยิ่งให้คุณกรอกข้อมูลใน Codelab ก่อนหน้าซึ่งจะแนะนําวิธีสร้างเว็บแอปที่ใช้งานได้นี้ก่อนดําเนินการต่อ
ใน Glitch เพียงคลิกปุ่มรีมิกซ์เพื่อนํามาแยกและสร้างไฟล์ชุดใหม่ที่คุณแก้ไขได้
3. สํารวจกรณีล้ําสมัยในโซลูชันก่อนหน้า
ถ้าคุณเปิดเว็บไซต์ที่สมบูรณ์ซึ่งเพิ่งโคลนและลองพิมพ์ความคิดเห็น คุณจะสังเกตเห็นว่าเว็บไซต์ทํางานไปได้หลายแห่งตามที่ควรจะเป็น บล็อกความคิดเห็นที่ฟังดูเหมือนสแปม และอนุญาตให้ตอบกลับได้อย่างถูกต้อง
อย่างไรก็ตาม หากฝึกทักษะการลองผิดลองถูกและแบบวลีเพื่อทําลายโมเดลนี้ คุณอาจประสบความสําเร็จในบางจุดได้ ด้วยการทดลองใช้และข้อผิดพลาดเล็กๆ น้อยๆ คุณสามารถสร้างตัวอย่างด้วยตนเองได้ดังที่แสดงในตัวอย่างด้านล่าง ลองวางรายการเหล่านี้ลงในเว็บแอปที่มีอยู่ ตรวจสอบคอนโซล และดูความน่าจะเป็นที่กลับมาหากความคิดเห็นเป็นสแปม ดังนี้
ความคิดเห็นที่ชอบด้วยกฎหมายที่โพสต์โดยไม่มีปัญหา (เชิงลบจริง):
- "ว้าว ฉันชอบวิดีโอนี้มาก เยี่ยมไปเลย! สแปมความน่าจะเป็น: 47.91854%
- "ชอบที่สุดในการสาธิตเหล่านี้ ดูรายละเอียดเพิ่มเติมผู้ใช้แต่ละรายได้ สแปมความน่าจะเป็น: 47.15898%
- "ฉันจะค้นหาข้อมูลเพิ่มเติมในเว็บไซต์ได้อย่างไร ความน่าจะเป็นของสแปม: 15.32495%
ยอดเยี่ยมมาก ความน่าจะเป็นสําหรับรายการทั้งหมดข้างต้นค่อนข้างต่ํา และทําให้เป็นไปได้ผ่าน SPAM_THRESHOLD ตามค่าเริ่มต้นของความน่าจะเป็นขั้นต่ํา 75% ก่อนที่จะดําเนินการ (กําหนดใน script.js โค้ดจาก Codelab ก่อนหน้า)
มาลองเขียนความคิดเห็นเจ๋งๆ ที่ทําเครื่องหมายว่าเป็นสแปมแม้ว่า...
ความคิดเห็นที่ถูกต้องซึ่งถูกทําเครื่องหมายว่าเป็นสแปม (การตรวจสอบที่ผิดพลาด):
- "ผู้ชมจะลิงก์ไปยังเว็บไซต์หน้ากากที่สวมใส่อยู่ไหม สแปมความเป็นไปได้: 98.46466%
- "ฉันจะซื้อเพลงนี้ใน Spotify ได้ไหม บอกใครๆ ได้เลย! ความน่าจะเป็นของสแปม: 94.40953%
- "มีคนติดต่อพร้อมด้วยรายละเอียดเกี่ยวกับวิธีดาวน์โหลด TensorFlow.jsCPDquot; สแปมความน่าจะเป็น: 83.20084%
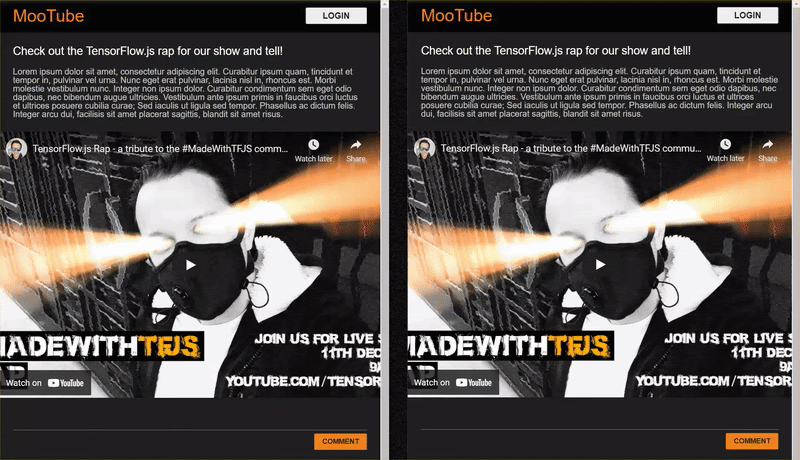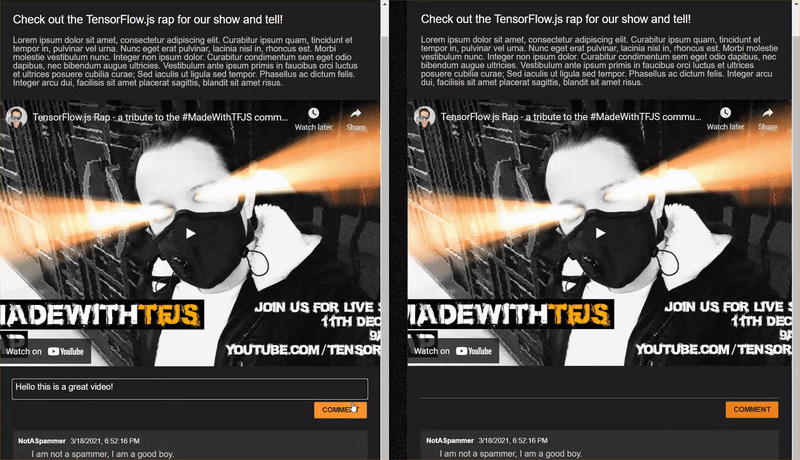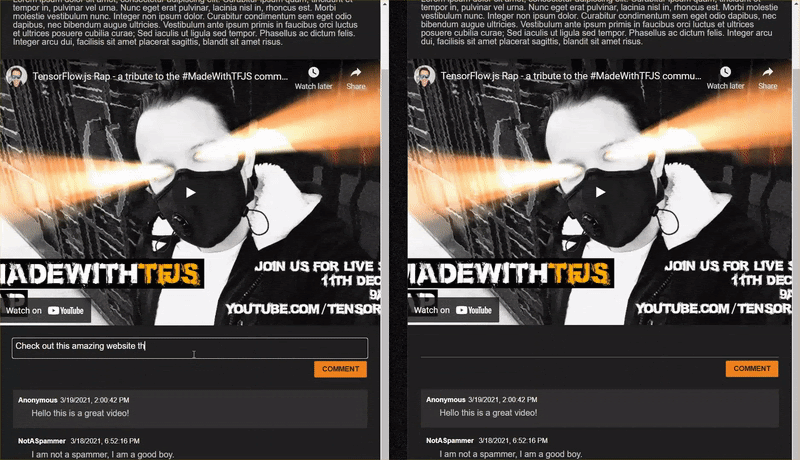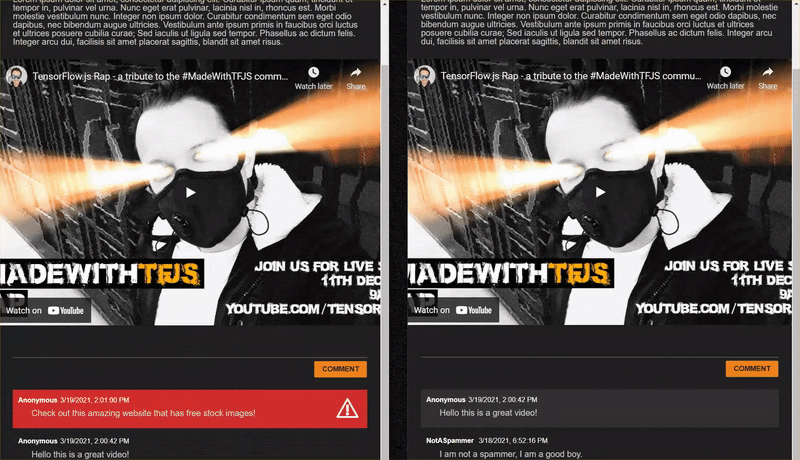
ขออภัย ดูเหมือนว่าความคิดเห็นที่ถูกต้องเหล่านี้จะได้รับการทําเครื่องหมายว่าเป็นสแปมเมื่อควรได้รับอนุญาต วิธีแก้ปัญหา
วิธีง่ายๆ อย่างหนึ่งคือเพิ่ม SPAM_THRESHOLD ให้มั่นใจกว่า 98.5% ในกรณีดังกล่าว ระบบจะโพสต์ความคิดเห็นที่ไม่ถูกต้องเหล่านี้ เมื่อพูดถึงเรื่องนี้แล้ว เรามาดูผลลัพธ์อื่นๆ ที่เป็นไปได้ด้านล่างกัน...
ความคิดเห็นที่เป็นสแปมที่มีการทําเครื่องหมายว่าเป็นสแปม (ค่าบวกตามจริง):
- "เยี่ยมไปเลย แต่ลองดูลิงก์ดาวน์โหลดบนเว็บไซต์ของฉันดีกว่า!" สแปมที่เป็นไปได้: 99.77873%
- "ฉันทราบว่าจะมีคนซื้อยาให้คุณได้เห็นเพียง pr0file สําหรับรายละเอียด" ความน่าจะเป็นของสแปม: 98.46955%
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอที่ยอดเยี่ยมยิ่งขึ้นไปอีก! http://example.com" ความน่าจะเป็นของสแปม: 96.26383%
โอเค นี่คือการทํางานที่ควรจะเป็นด้วยเกณฑ์ 75% เดิมของเรา แต่เนื่องจากในขั้นตอนก่อนหน้านี้ คุณได้เปลี่ยนให้ SPAM_THRESHOLD มั่นใจกว่า 98.5% ซึ่งหมายความว่ามีตัวอย่าง 2 รายการที่ถือว่าผ่านเกณฑ์นี้ ดังนั้นบางทีเกณฑ์ก็อาจสูงเกินไป อาจจะ 96% ดีกว่าใช่ไหม แต่หากคุณทําเช่นนั้น ความคิดเห็นหนึ่งในส่วนก่อนหน้านี้ (เป็นผลบวกเท็จ) จะถูกทําเครื่องหมายว่าเป็นสแปมเมื่อถูกให้คะแนนเป็น 98.46466%
ในกรณีนี้ คุณควรบันทึกความคิดเห็นที่เป็นสแปมจริงๆ ทั้งหมดเหล่านี้และพยายามแก้ไขข้อผิดพลาดที่เกิดขึ้นอีกครั้ง เมื่อตั้งเกณฑ์เป็น 96% จะยังคงบันทึกผลบวกจริงทั้งหมด และคุณลบผลบวกลวง 2 รายการข้างต้น ไม่แย่เกินไปหากเปลี่ยนเพียงหมายเลขเดียว
มาเริ่มกันเลย...
ความคิดเห็นที่เป็นสแปมซึ่งได้รับอนุญาตให้โพสต์ (เชิงลบเชิงลบ)
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอที่ยอดเยี่ยมยิ่งกว่าเดิม!" สแปมความเป็นไปได้: 7.54926%
- "รับส่วนลดสําหรับคลาสฝึกออกกําลังกายของเรา ดู pr0file!" ความน่าจะเป็นของสแปม: 17.49849%
- "omg GOOG เพิ่งแสดงผลสําเร็จ มาสายเกินไป!" สแปมความน่าจะเป็น: 20.42894%
สําหรับความคิดเห็นเหล่านี้ คุณไม่สามารถดําเนินการใดๆ ได้โดยเปลี่ยนค่า SPAM_THRESHOLD เพิ่มเติม การลดเกณฑ์ของจดหมายขยะจาก 96% เหลือประมาณ 9% จะทําให้ความคิดเห็นที่ได้รับการทําเครื่องหมายว่าเป็นสแปม โดยความคิดเห็นหนึ่งจะมีคะแนน 58% แม้ว่าจะถูกต้องก็ตาม วิธีเดียวที่จะจัดการกับความคิดเห็นเช่นนี้ได้คือการฝึกโมเดลใหม่ด้วยกรณี Edge เหล่านั้นในข้อมูลการฝึกอบรม เพื่อเรียนรู้วิธีปรับมุมมองของสิ่งต่างๆ ในโลกว่าเป็นสแปมหรือไม่
แม้ว่าตัวเลือกเดียวในตอนนี้ก็คือการฝึกโมเดลใหม่ คุณก็ยังดูวิธีปรับแต่งเกณฑ์เวลาที่เหมาะสมที่จะใช้การโทรหาสแปมเพื่อปรับปรุงประสิทธิภาพได้ด้วย ในฐานะมนุษย์ 75% ค่อนข้างมั่นใจ แต่สําหรับโมเดลนี้ คุณต้องเพิ่มใกล้อีก 81.5% เพื่อประสิทธิภาพมากขึ้นในอินพุตตัวอย่าง
ไม่มีค่าเวทมนตร์ที่ดีที่ใช้งานได้ดีในรุ่นต่างๆ และต้องตั้งค่าเกณฑ์นี้สําหรับแต่ละรูปแบบหลังจากทดลองข้อมูลจริงเพื่อหาว่าสิ่งใดที่ใช้ได้ดี
อาจมีบางกรณีที่ผลบวกลวง (หรือผลบวกลบ) อาจก่อให้เกิดผลเสียร้ายแรง (เช่น ในอุตสาหกรรมการแพทย์) คุณจึงอาจปรับเกณฑ์ให้สูงมากและขอรับการตรวจสอบโดยเจ้าหน้าที่เพิ่มเติมสําหรับผู้ที่ไม่มีคุณสมบัติตามเกณฑ์ สิ่งที่คุณเลือกเป็นนักพัฒนาซอฟต์แวร์และต้องมีการทดสอบบางอย่าง
4. ฝึกโมเดลการตรวจจับสแปมความคิดเห็นอีกครั้ง
ในส่วนก่อนหน้า คุณได้ตรวจพบกรณี Edge จํานวนหนึ่งที่ล้มเหลวสําหรับโมเดล ซึ่งมีตัวเลือกเดียวคือฝึกโมเดลใหม่โดยคํานึงถึงสถานการณ์เหล่านี้ ในระบบการผลิต คุณอาจพบว่าความคิดเห็นเหล่านี้ไม่เหมาะสมเมื่อผู้ชมรายงานว่าเป็นสแปมว่าเป็นสแปม ซึ่งเข้ามาผ่านผู้ดูแลหรือผู้ตรวจสอบที่ตรวจสอบความคิดเห็นที่ได้รับแจ้งแล้วจริงๆ แล้วไม่ใช่สแปมจริงๆ และอาจทําเครื่องหมายความคิดเห็นเหล่านั้นเพื่อฝึกซ้ําได้ สมมติว่าคุณได้รวบรวมข้อมูลใหม่จํานวนมากสําหรับกรณีขอบเหล่านี้ (เพื่อให้ได้ผลลัพธ์ที่ดีที่สุดคุณควรมีประโยคใหม่เหล่านี้หากทําได้) ตอนนี้เราจะแนะนําวิธีฝึกโมเดลใหม่โดยคํานึงถึงกรณีขอบเหล่านั้น
สรุปโมเดลที่สร้างไว้ล่วงหน้า
โมเดลที่สร้างล่วงหน้าที่คุณใช้คือโมเดลที่สร้างโดยบุคคลที่สามผ่านโปรแกรมสร้างโมเดลที่ใช้โมเดล "ค่าเฉลี่ยการฝังคํา&ฟังก์ชันการทํางาน
เนื่องจากโมเดลสร้างด้วย Model Maker คุณจะต้องเปลี่ยนไปใช้ Python อีกครั้งเพื่อฝึกโมเดลอีกครั้ง จากนั้นส่งออกโมเดลที่สร้างเป็นรูปแบบ TensorFlow.js เพื่อให้คุณใช้ในเบราว์เซอร์ได้ ขอขอบคุณการสร้างโปรแกรมจําลองทําให้โมเดลของคุณใช้งานได้ง่ายมาก เพื่อให้ติดตามได้ง่ายและเราจะให้คําแนะนําคุณตลอดกระบวนการนี้ จึงไม่ต้องกังวลหากคุณไม่เคยใช้ Python มาก่อน
ห้องทดลอง
เนื่องจากคุณกังวลกับ Codelab นี้เป็นอย่างมาก และต้องการตั้งค่าเซิร์ฟเวอร์ Linux ที่มียูทิลิตี Python ต่างๆ ทั้งหมดติดตั้งอยู่ คุณสามารถเรียกใช้โค้ดผ่านเว็บเบราว์เซอร์ได้โดยใช้ "Colab Notebook" สมุดบันทึกเหล่านี้สามารถเชื่อมต่อกับ "backend" ได้ ซึ่งเป็นเพียงเซิร์ฟเวอร์ที่มีรายการบางอย่างติดตั้งไว้ล่วงหน้า จากนั้นคุณสามารถเรียกใช้โค้ดที่กําหนดเองภายในเว็บเบราว์เซอร์และดูผลลัพธ์ได้ ซึ่งมีประโยชน์มากในการสร้างต้นแบบอย่างรวดเร็วหรือใช้ในบทแนะนําลักษณะนี้
เพียงไปที่ colab.research.google.com และคุณจะเห็นหน้าจอต้อนรับตามที่แสดงด้านล่างนี้
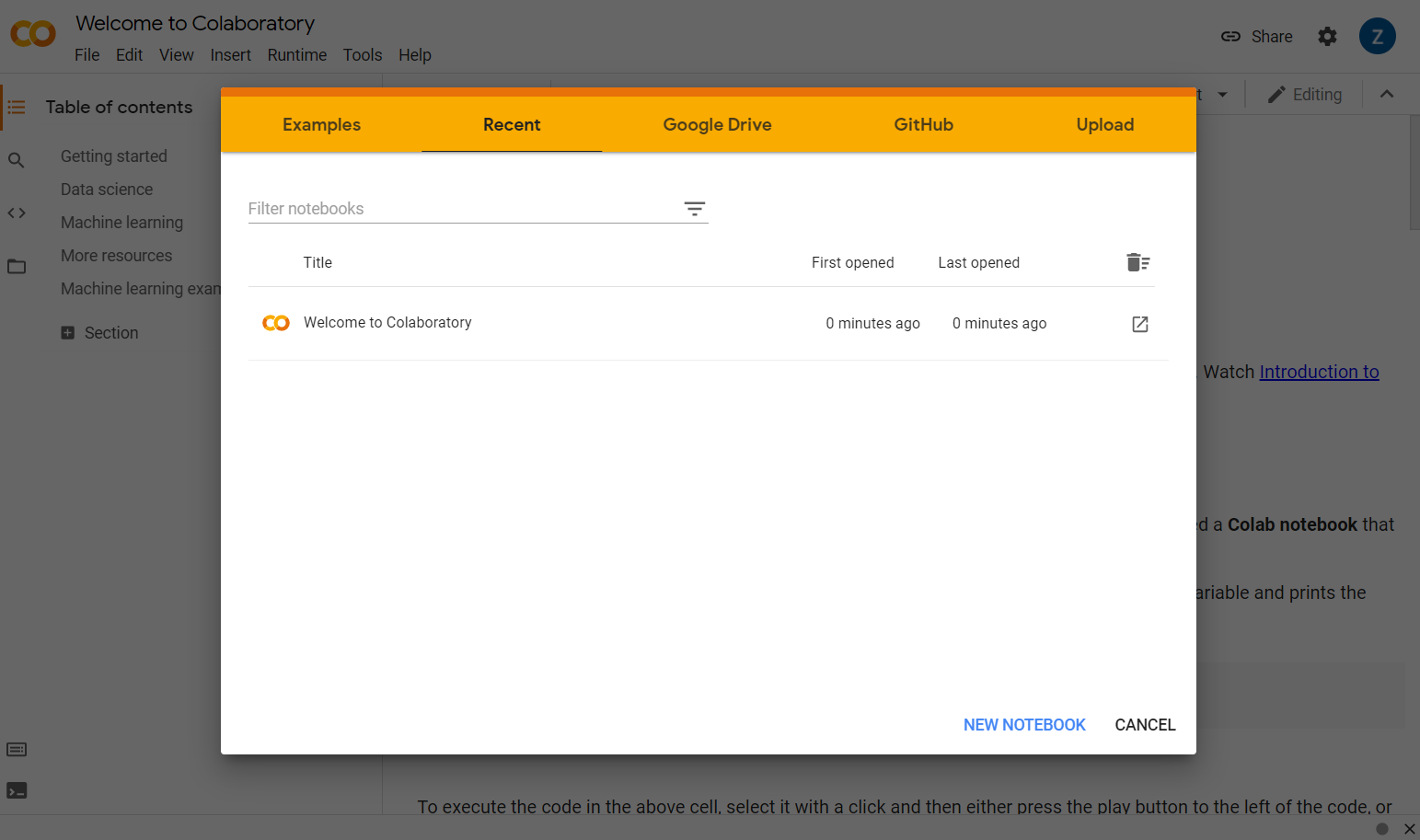
คลิกปุ่มสมุดบันทึกใหม่ที่ด้านขวาล่างของหน้าต่างป๊อปอัป และคุณจะเห็น Colab ที่ว่างเปล่าเช่นนี้
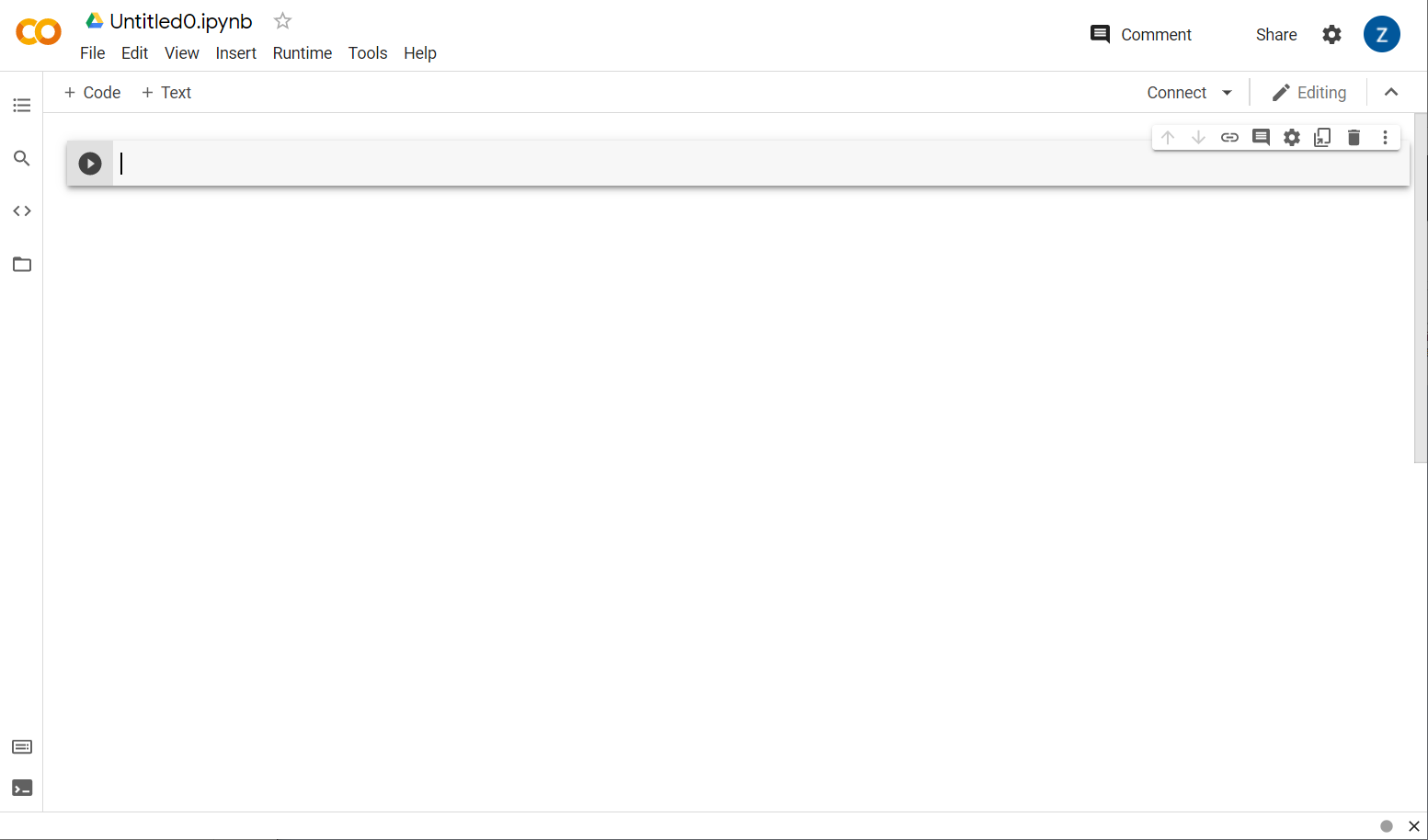
เยี่ยมเลย ขั้นตอนถัดไปคือการเชื่อมต่อ Colab ส่วนหน้ากับเซิร์ฟเวอร์แบ็กเอนด์บางรายการเพื่อให้เรียกใช้โค้ด Python ได้ โดยคลิกเชื่อมต่อที่ด้านขวาบน แล้วเลือกเชื่อมต่อรันไทม์ที่โฮสต์
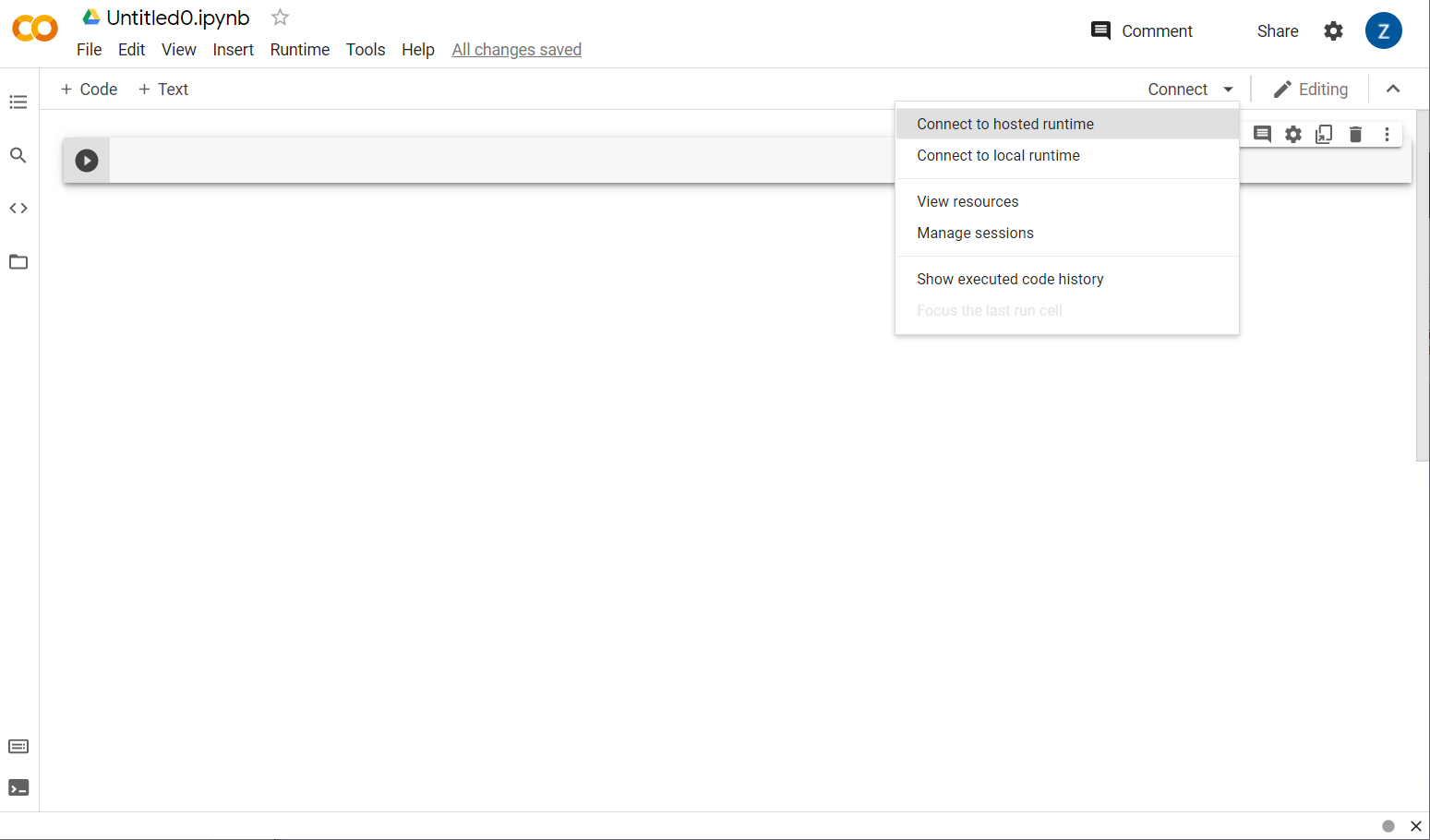
เมื่อเชื่อมต่อแล้ว คุณควรเห็นไอคอน RAM และดิสก์ปรากฏในตําแหน่งดังนี้
เยี่ยมมาก คุณเริ่มเขียนโค้ดใน Python เพื่อฝึกโมเดลสร้างโมเดลอีกครั้งได้ เพียงทำตามขั้นตอนด้านล่างนี้
ขั้นตอนที่ 1
คัดลอกเซลล์ด้านล่างในเซลล์แรกที่ว่างเปล่า โปรแกรมนี้จะติดตั้ง TensorFlow Lite Model Maker โดยใช้ Python' Package Manager ชื่อ "pip" (คล้ายกับ npm ซึ่งผู้อ่านส่วนใหญ่ของห้องทดลองโค้ดนี้อาจคุ้นเคยกับระบบนิเวศ JS มากกว่า)
!pip install -q tflite-model-maker
แต่การวางโค้ดลงในเซลล์จะไม่เรียกใช้ จากนั้น วางเมาส์ไว้เหนือเซลล์สีเทาที่คุณวางโค้ดด้านบนไว้ แล้วไอคอน "play" ขนาดเล็กจะปรากฏทางด้านซ้ายของเซลล์ตามที่ไฮไลต์ด้านล่างนี้
 คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ไปในเซลล์
คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ไปในเซลล์
คุณจะเห็นว่าเครื่องมือสร้างโมเดลกําลังติดตั้งอยู่
เมื่อการเรียกใช้เซลล์นี้เสร็จสมบูรณ์ดังที่แสดงแล้ว ให้ไปยังขั้นตอนถัดไปที่ด้านล่าง
ขั้นตอนที่ 2
ต่อไปให้เพิ่มเซลล์โค้ดใหม่ตามที่แสดงไว้เพื่อวางโค้ดบางส่วนหลังจากเซลล์แรกและเรียกใช้แยกต่างหาก
เซลล์ต่อไปที่เรียกใช้จะมีการนําเข้าจํานวนหนึ่งที่โค้ดในสมุดบันทึกส่วนที่เหลือต้องใช้ คัดลอกและวางด้านล่างในเซลล์ใหม่ที่สร้างขึ้น
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
ยอดเยี่ยมมาก ถึงแม้จะไม่คุ้นเคยกับ Python คุณเพียงแค่นําเข้ายูทิลิตีบางรายการและฟังก์ชันตัวสร้างโมเดลที่จําเป็นสําหรับตัวแยกประเภทสแปม นอกจากนี้ จะตรวจสอบว่าคุณกําลังใช้ TensorFlow 2.x ซึ่งเป็นข้อกําหนดในการใช้ Model Maker หรือไม่
สุดท้าย เช่น ให้เรียกใช้เซลล์โดยกดปุ่ม "play" ขณะวางเคอร์เซอร์เหนือเซลล์ แล้วเพิ่มเซลล์โค้ดใหม่สําหรับขั้นตอนถัดไป
ขั้นตอนที่ 3
ถัดจากนั้น คุณจะดาวน์โหลดข้อมูลจากเซิร์ฟเวอร์ระยะไกลลงในอุปกรณ์ และตั้งค่าตัวแปร training_data เป็นเส้นทางของไฟล์ในเครื่องที่ดาวน์โหลดมาได้ ดังนี้
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/jm_blog_comments_extras.csv', extract=False)
โปรแกรมสร้างโมเดลจะฝึกโมเดลจากไฟล์ CSV แบบง่ายอย่างไฟล์ที่ดาวน์โหลดมาได้ คุณเพียงแค่ระบุคอลัมน์ที่จะเก็บข้อความและคอลัมน์ที่ติดป้ายกํากับ และดูวิธีได้จากขั้นตอนที่ 5 คุณสามารถดาวน์โหลดไฟล์ CSV ได้ด้วยตนเองโดยตรงเพื่อดูว่ามีไฟล์ใดที่ต้องการบ้าง
เมื่อสังเกตแล้วจะเห็นว่าไฟล์นี้เป็นของ jm_blog_comments_extras.csv - ไฟล์นี้เป็นเพียงข้อมูลการฝึกเดิมที่เราใช้ในการสร้างโมเดลสแปมความคิดเห็นแรกที่รวมไว้กับข้อมูลเคสขอบใหม่ซึ่งคุณค้นพบเท่านั้นที่รวมอยู่ในไฟล์เดียว คุณต้องมีข้อมูลการฝึกอบรมเดิมที่ใช้ฝึกโมเดลด้วย นอกเหนือจากประโยคใหม่ที่ต้องการเรียนรู้
ไม่บังคับ: หากดาวน์โหลดไฟล์ CSV นี้และตรวจสอบโค้ด 2-3 บรรทัดสุดท้ายเพื่อดูตัวอย่างของ Edge Case ที่ทํางานไม่ปกติมาก่อน แล้วเพิ่มข้อมูลเหล่านี้ลงไปในตอนท้ายของข้อมูลการฝึกอบรมที่มีอยู่ ซึ่งเป็นโมเดลที่ฝึกไว้ล่วงหน้า
ดําเนินการเซลล์นี้ จากนั้นเมื่อเรียกใช้เสร็จสิ้นแล้ว เพิ่มเซลล์ใหม่ แล้วไปยังขั้นตอนที่ 4
ขั้นตอนที่ 4
เมื่อใช้ Model Maker คุณจะไม่สร้างโมเดลตั้งแต่ต้น โดยทั่วไปคุณใช้โมเดลที่มีอยู่ซึ่งคุณจะต้องปรับแต่งให้เข้ากับความต้องการของคุณ
Model Maker ให้การฝังโมเดลก่อนการเรียนรู้จํานวนมากที่คุณสามารถใช้ได้ แต่วิธีที่ง่ายที่สุดและเร็วที่สุดในการเริ่มต้นใช้งานคือ average_word_vec ซึ่งเป็นสิ่งที่คุณใช้ใน Codelab ก่อนหน้าในการสร้างเว็บไซต์ โค้ดมีดังนี้
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
เริ่มเรียกใช้เมื่อวางลงในเซลล์ใหม่ได้เลย
การทําความเข้าใจเกี่ยวกับ
num_words
พารามิเตอร์
นี่คือจํานวนคําที่คุณต้องการให้โมเดลใช้ คุณอาจคิดว่า ยิ่งมากเท่าไร ก็ยิ่งดีต่อความถี่ตามคําที่ใช้ หากใช้ทุกคําในคอร์สที่สมบูรณ์ โมเดลอาจต้องเรียนรู้และสมดุลระหว่างน้ําหนักของคําที่ใช้เพียงครั้งเดียว ซึ่งก็ไม่มีประโยชน์มากนัก & เพื่อให้คุณปรับแต่งโมเดลตามจํานวนคําที่ต้องการได้โดยใช้พารามิเตอร์ num_words ตัวเลขที่น้อยกว่าที่นี่จะมีรูปแบบน้อยกว่าและเร็วกว่า แต่ก็อาจมีความแม่นยําน้อยกว่า เนื่องจากจดจําคําได้น้อยกว่า ตัวเลขที่ใหญ่กว่าที่นี่จะมีรุ่นที่ใหญ่กว่าและช้ากว่า การค้นหาจุดที่น่าสนใจคือกุญแจสําคัญและขึ้นอยู่กับคุณในฐานะวิศวกรแมชชีนเลิร์นนิง เพื่อหาว่ารูปแบบใดเหมาะกับกรณีการใช้งานของคุณที่สุด
การทําความเข้าใจเกี่ยวกับ
wordvec_dim
พารามิเตอร์
พารามิเตอร์ wordvec_dim คือจํานวนมิติข้อมูลที่คุณต้องการใช้สําหรับเวกเตอร์ของคําแต่ละคํา โดยพื้นฐานแล้ว มิติข้อมูลเหล่านี้มีลักษณะที่แตกต่างกัน (ซึ่งสร้างโดยอัลกอริทึมแมชชีนเลิร์นนิงเมื่อฝึก) โดยคําหนึ่งๆ จะวัดได้ด้วยโปรแกรมที่จะใช้เพื่อลองและเชื่อมโยงคําที่คล้ายกันในลักษณะที่มีความหมาย
เช่น หากคุณมีมิติข้อมูลว่า "medical" คําหนึ่งๆ เป็นคําอย่าง "pills" อาจได้คะแนนสูงในมิติข้อมูลนี้ รวมทั้งเชื่อมโยงกับคําที่มีคะแนนสูงอื่นๆ เช่น "xray" แต่ "cat" จะให้คะแนนในมิติข้อมูลนี้ต่ํา ดูเหมือนว่า &"มิติข้อมูลทางการแพทย์&เครื่องหมายคําพูดนั้นมีประโยชน์ในการระบุสแปมเมื่อใช้ร่วมกับมิติข้อมูลอื่นๆ ที่เป็นไปได้ซึ่งคุณอาจตัดสินใจที่จะใช้นัยสําคัญ
ในกรณีของคําที่มีคะแนนสูงในมิติข้อมูล&อัญประกาศ เครื่องหมายรูปเป็นรูปที่ 2 อาจคิดว่ามิติข้อมูลที่ 2 ที่เชื่อมคําเข้ากับร่างกายมนุษย์อาจเป็นประโยชน์ คําต่างๆ เช่น "leg", "arm", "neck" อาจได้คะแนนสูงที่นี่และในเชิงการแพทย์ก็ค่อนข้างสูงเช่นกัน
จากนั้นโมเดลจะใช้มิติข้อมูลเหล่านี้เพื่อเปิดใช้การตรวจจับคําที่มีแนวโน้มเกี่ยวข้องกับสแปมมากขึ้น อีเมลสแปมอาจมีแนวโน้มว่ามีคําที่เป็นทั้งส่วนประกอบทางการแพทย์และร่างกายของมนุษย์
กฎสําคัญที่กําหนดจากการวิจัยคือรากที่ 4 ของจํานวนคําที่ใช้ได้ผลดีกับพารามิเตอร์นี้ ดังนั้น หากฉันใช้คํา 2, 000 คํา จุดเริ่มต้นที่ดีสําหรับสิ่งนี้คือ 7 มิติข้อมูล คุณยังสามารถเปลี่ยนจํานวนคําที่ใช้ได้ด้วยหากเปลี่ยนจํานวนคํา
การทําความเข้าใจเกี่ยวกับ
seq_len
พารามิเตอร์
โดยทั่วไป โมเดลจะเข้มงวดมากเมื่อป้อนค่า สําหรับรูปแบบภาษา โมเดลภาษาดังกล่าวจะแยกประเภทประโยคที่มีความยาวคงที่ได้ ค่านี้กําหนดโดยพารามิเตอร์ seq_len ซึ่งย่อมาจาก "length type' เมื่อคุณแปลงคําเป็นตัวเลข (หรือโทเค็น) ประโยคจะกลายเป็นลําดับของโทเค็นเหล่านี้ โมเดลของคุณจะได้รับการฝึก (ในกรณีนี้) เพื่อจําแนกและจดจําประโยคที่มีโทเค็น 20 รายการ หากประโยคยาวกว่านี้ ระบบจะตัดข้อความให้สั้นลง หากวิดีโอมีขนาดสั้นลง ระบบจะเติมโค้ดเช่นเดียวกับใน Codelab แรกในซีรีส์นี้
ขั้นตอนที่ 5 - โหลดข้อมูลการฝึก
ก่อนหน้านี้คุณดาวน์โหลดไฟล์ CSV ตอนนี้ถึงเวลาใช้เครื่องมือโหลดข้อมูลเพื่อเปลี่ยนข้อมูลนี้เป็นข้อมูลการฝึกที่โมเดลจดจําได้แล้ว
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
ถ้าคุณเปิดไฟล์ CSV ในเครื่องมือแก้ไข คุณจะเห็นว่าแต่ละบรรทัดมีค่าเพียง 2 ค่า และอธิบายข้อความด้วยข้อความในบรรทัดแรกของไฟล์ โดยทั่วไป แต่ละรายการจะถือเป็น "คอลัมน์' คุณจะเห็นว่าคําอธิบายสําหรับคอลัมน์แรกเป็น commenttext และรายการแรกในแต่ละบรรทัดคือข้อความความคิดเห็น
ในทํานองเดียวกัน ตัวบ่งชี้สําหรับคอลัมน์ที่ 2 คือ spam และคุณจะเห็นว่ารายการที่สองในแต่ละบรรทัดคือ TRUE หรือ FALSE เพื่อระบุว่าข้อความนั้นถือเป็นสแปมความคิดเห็นหรือไม่ พร็อพเพอร์ตี้อื่นๆ จะตั้งค่าข้อมูลจําเพาะของโมเดลที่คุณสร้างในขั้นตอนที่ 4 พร้อมกับอักขระตัวคั่น ซึ่งในกรณีนี้จะเป็นคอมมาเนื่องจากไฟล์คั่นด้วยคอมมา นอกจากนี้ คุณยังตั้งค่าให้พารามิเตอร์สับเปลี่ยนแบบสุ่มเพื่อจัดเรียงข้อมูลการฝึกอบรมใหม่ เพื่อให้ข้อมูลที่อาจคล้ายกันหรือรวบรวมกันกระจายออกไปแบบสุ่มผ่านชุดข้อมูล
จากนั้นจะใช้ data.split() เพื่อแบ่งข้อมูลออกเป็นการฝึกและข้อมูลทดสอบ โดย .9 จะระบุว่า 90% ของชุดข้อมูลจะใช้สําหรับการฝึก ส่วนที่เหลือจะใช้ในการทดสอบ
ขั้นตอนที่ 6 - สร้างโมเดล
เพิ่มเซลล์อื่นที่เราจะเพิ่มโค้ดเพื่อสร้างโมเดลดังนี้
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
การดําเนินการนี้จะสร้างโมเดลตัวแยกข้อความด้วยเครื่องมือสร้างโมเดล และคุณระบุข้อมูลการฝึกอบรมที่ต้องการใช้ (ซึ่งกําหนดไว้ในขั้นตอนที่ 4) ข้อมูลจําเพาะของโมเดล (ซึ่งตั้งค่าไว้ในขั้นตอนที่ 4) และจํานวน Epoch อีกจํานวนหนึ่งในกรณีนี้ 50
หลักการสําคัญของแมชชีนเลิร์นนิงคือเป็นรูปแบบการจับคู่รูปแบบ ในขั้นต้น ระบบจะโหลดน้ําหนักที่ฝึกล่วงหน้าแล้วสําหรับคําต่างๆ และพยายามจัดกลุ่มค่าเหล่านี้เข้าด้วยกันด้วย "การคาดคะเน '" รายการใดที่จัดกลุ่มไว้ด้วยกันจะระบุสแปมและที่ใดที่ไม่ได้แสดง เป็นครั้งแรกที่ใกล้กับ 50:50 น. โมเดลใกล้จะเริ่มต้นดังที่แสดงด้านล่าง

จากนั้นจะวัดผลลัพธ์ของตัวแปรและเปลี่ยนน้ําหนักของโมเดลเพื่อปรับแต่งการคาดการณ์ และจะลองอีกครั้ง นี่คือ Epoch ดังนั้น หากระบุ epoch==50 ค่าจะผ่าน "loop'" 50 ครั้งตามที่แสดง

ดังนั้นเมื่อคุณไปถึงยุคที่ 50 โมเดลจะรายงานความแม่นยําในระดับที่สูงกว่ามาก ในกรณีนี้ 99.1%
ขั้นตอนที่ 7 - ส่งออกโมเดล
เมื่อทําการฝึกอบรมเสร็จแล้ว คุณจะส่งออกโมเดลได้ TensorFlow จะฝึกโมเดลในรูปแบบของตัวเองและจําเป็นต้องแปลงเป็นรูปแบบ TensorFlow.js เพื่อใช้ในหน้าเว็บ เพียงวางสิ่งต่อไปนี้ในเซลล์ใหม่และเรียกใช้
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
หลังจากเรียกใช้โค้ดนี้ หากคุณคลิกไอคอนโฟลเดอร์เล็กๆ ทางด้านซ้ายของ Colab ระบบจะนําคุณไปยังโฟลเดอร์ที่คุณส่งออกไปด้านบน (ในไดเรกทอรีราก คุณอาจต้องเพิ่มระดับ) และค้นหาแพ็กเกจไฟล์ ZIP ที่ส่งออกไปใน ModelFiles.zip
ดาวน์โหลดไฟล์ ZIP นี้ลงในคอมพิวเตอร์ของคุณเนื่องจากคุณจะใช้ไฟล์เหล่านั้นเหมือนกับ Codelab แรก
เยี่ยมเลย ส่วน Python สิ้นสุดลงแล้ว คุณสามารถกลับไปยัง JavaScript ที่คุณรู้จักและชื่นชอบได้แล้ว ในที่สุด
5. การแสดงผลโมเดลแมชชีนเลิร์นนิงใหม่
ขณะนี้คุณพร้อมที่จะโหลดโมเดลแล้ว ก่อนที่จะทําเช่นนั้นได้ คุณต้องอัปโหลดไฟล์โมเดลใหม่ที่ดาวน์โหลดมาก่อนหน้านี้ใน Codelab เพื่อให้โฮสต์และใช้งานได้ในโค้ดของคุณ
ขั้นแรก ให้แตกไฟล์ ZIP ของโมเดลที่เพิ่งดาวน์โหลดจากสมุดบันทึก Model Maker Colab ที่คุณเพิ่งเรียกใช้ คุณควรเห็นไฟล์ต่อไปนี้อยู่ในโฟลเดอร์ต่างๆ
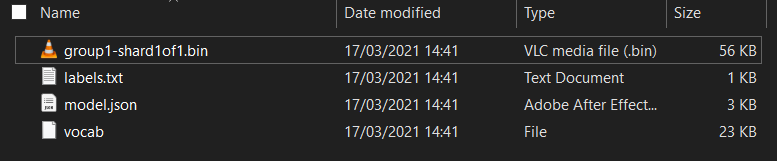
ที่นี่มีอะไร
model.json- เป็นหนึ่งในไฟล์ที่ประกอบขึ้นเป็นโมเดล TensorFlow.js ที่ผ่านการฝึกแล้ว คุณจะอ้างอิงไฟล์นี้เฉพาะในโค้ด JSgroup1-shard1of1.bin- ไฟล์นี้เป็นไฟล์ไบนารีที่มีข้อมูลที่บันทึกไว้ส่วนใหญ่สําหรับโมเดล TensorFlow.js ที่ส่งออกและจะต้องโฮสต์ไว้ที่อื่นในเซิร์ฟเวอร์เพื่อให้ดาวน์โหลดในไดเรกทอรีเดียวกับmodel.jsonด้านบนvocab- ไฟล์แปลกที่ไม่มีนามสกุลนี้มาจาก Model Maker ที่แสดงวิธีเข้ารหัสคําในประโยคเพื่อให้โมเดลเข้าใจวิธีใช้ คุณจะได้รับข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ในส่วนถัดไปlabels.txt- ส่วนนี้จะมีเพียงชื่อคลาสที่โมเดลคาดการณ์ สําหรับโมเดลนี้ หากคุณเปิดไฟล์นี้ในเครื่องมือแก้ไขข้อความ จะมีเพียง "false" &"true" ซึ่งระบุ &&tt;ไม่ใช่สแปม" หรือ"spam" เป็นผลลัพธ์การคาดคะเน
โฮสต์ไฟล์โมเดล TensorFlow.js
ขั้นแรก ให้วางไฟล์ model.json และ *.bin ที่สร้างขึ้นในเว็บเซิร์ฟเวอร์ เพื่อให้คุณเข้าถึงไฟล์เหล่านั้นได้ผ่านหน้าเว็บ
ลบไฟล์โมเดลที่มีอยู่
เมื่อคุณสร้างผลลัพธ์ของ Codelab แรกในชุดหนังสือนี้ คุณจะต้องลบไฟล์โมเดลที่มีอยู่ที่อัปโหลดก่อน หากคุณกําลังใช้ Glitch.com เพียงแค่ตรวจสอบแผงไฟล์ทางด้านซ้ายสําหรับ model.json และ group1-shard1of1.bin คลิกเมนูแบบเลื่อนลง 3 จุดสําหรับแต่ละไฟล์ แล้วเลือก ลบ ตามที่แสดง:
การอัปโหลดไฟล์ใหม่ไปยัง Glitch
เยี่ยมเลย แล้วอัปโหลดวิดีโอใหม่ ดังนี้
- เปิดโฟลเดอร์ assets ในแผงด้านซ้ายของโปรเจ็กต์ Glitch และลบเนื้อหาเก่าที่อัปโหลดหากมีชื่อเหมือนกัน
- คลิกอัปโหลดเนื้อหาแล้วเลือก
group1-shard1of1.binเพื่ออัปโหลดไปยังโฟลเดอร์นี้ ซึ่งควรมีลักษณะดังนี้เมื่ออัปโหลดแล้ว
- เยี่ยมเลย ทําแบบเดียวกันนี้สําหรับไฟล์ Model.json ด้วย ดังนั้นไฟล์ 2 ไฟล์ควรอยู่ในโฟลเดอร์เนื้อหาดังนี้
- หากคลิกไฟล์
group1-shard1of1.binที่คุณเพิ่งอัปโหลด คุณจะสามารถคัดลอก URL ไปยังตําแหน่งของไฟล์ได้ คัดลอกเส้นทางนี้ดังที่แสดงด้านล่างนี้
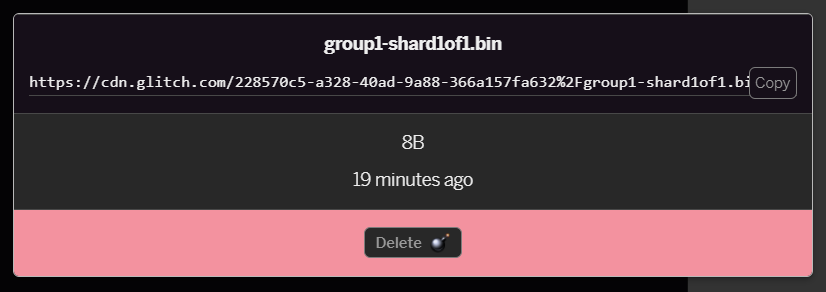
- ที่ด้านซ้ายล่างของหน้าจอ ให้คลิกเครื่องมือ > เทอร์มินัล รอให้หน้าต่างเทอร์มินัลโหลดขึ้นมา
- เมื่อโหลดสิ่งต่อไปนี้แล้ว ให้กด Enter เพื่อเปลี่ยนไดเรกทอรีเป็นโฟลเดอร์
www
เทอร์มินัล:
cd www
- จากนั้นใช้
wgetเพื่อดาวน์โหลดไฟล์ 2 ไฟล์ที่เพิ่งอัปโหลดโดยแทนที่ URL ด้านล่างด้วย URL ที่คุณสร้างสําหรับไฟล์ในโฟลเดอร์ของ Glitch (ตรวจสอบโฟลเดอร์เนื้อหาสําหรับ URL ที่กําหนดเองของแต่ละไฟล์)
โปรดทราบว่าการเว้นวรรคระหว่าง URL ทั้งสองและ URL ที่คุณต้องใช้จะแตกต่างจาก URL ที่แสดง แต่มีลักษณะคล้ายกัน:
เทอร์มินัล
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
ยอดเยี่ยม! คุณได้สร้างสําเนาของไฟล์ที่อัปโหลดไปยังโฟลเดอร์ www แล้ว
แต่ตอนนี้ระบบจะดาวน์โหลดชื่อแปลกๆ หากคุณพิมพ์ ls ในเทอร์มินัลแล้วกด Enter คุณจะเห็นข้อความดังนี้

- การใช้คําสั่ง
mvจะเปลี่ยนชื่อไฟล์ พิมพ์ข้อมูลต่อไปนี้ลงในคอนโซลแล้วกด Enter หลังจากแต่ละบรรทัด
เทอร์มินัล:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- สุดท้าย ให้รีเฟรชโปรเจ็กต์ Glitch โดยพิมพ์
refreshในเทอร์มินัลแล้วกด Enter
เทอร์มินัล:
refresh
เมื่อรีเฟรช คุณจะเห็น model.json และ group1-shard1of1.bin ในโฟลเดอร์ www ของอินเทอร์เฟซผู้ใช้
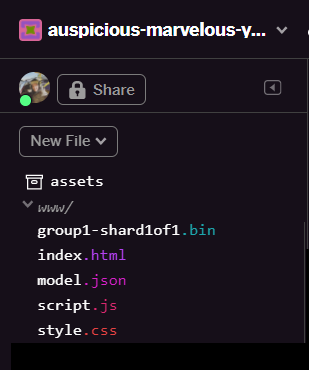
เยี่ยมเลย ขั้นตอนสุดท้ายคือการอัปเดตไฟล์ dictionary.js
- แปลงไฟล์ Vocab ที่ดาวน์โหลดไว้ใหม่เป็นรูปแบบ JS ที่ถูกต้องด้วยตนเองด้วยเครื่องมือแก้ไขข้อความหรือใช้เครื่องมือนี้แล้วบันทึกผลลัพธ์เป็น
dictionary.jsในโฟลเดอร์wwwหากมีไฟล์dictionary.jsอยู่แล้ว ก็แค่คัดลอกและวางเนื้อหาใหม่ทับลงไปแล้วบันทึกไฟล์นั้น
ไชโย คุณได้อัปเดตไฟล์ที่เปลี่ยนแปลงทั้งหมดแล้ว และหากคุณพยายามใช้เว็บไซต์แล้ว คุณจะสังเกตเห็นวิธีที่โมเดลที่ฝึกซ้ําควรคํานึงถึงตัวพิมพ์เล็กหรือใหญ่ที่ค้นพบและเรียนรู้จากดังที่ปรากฏ ดังนี้
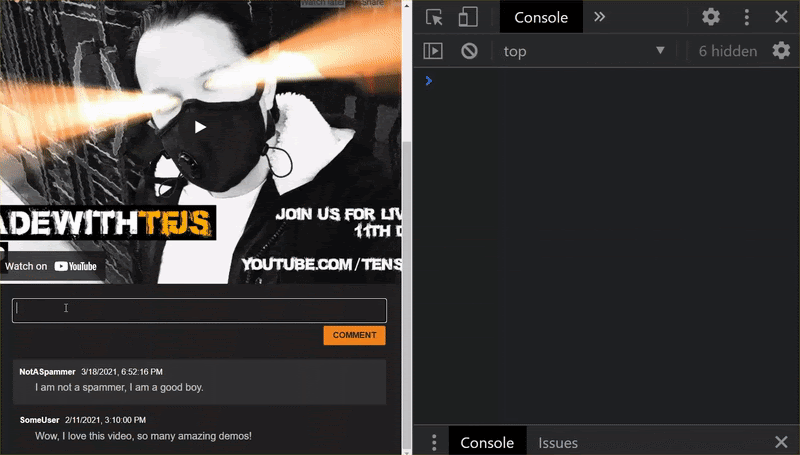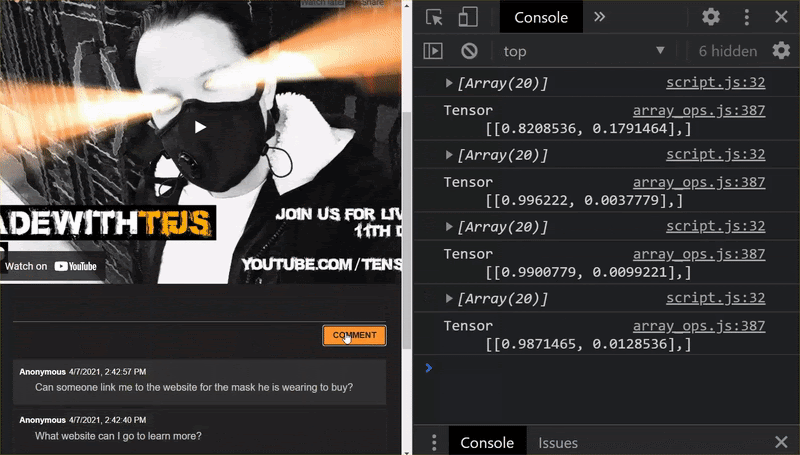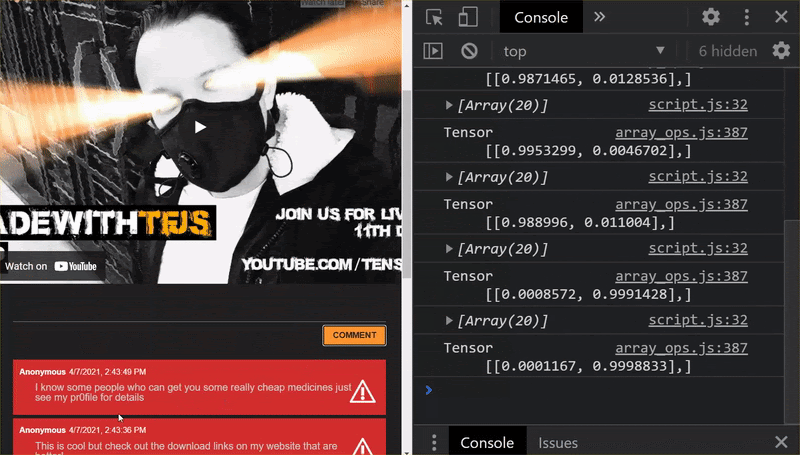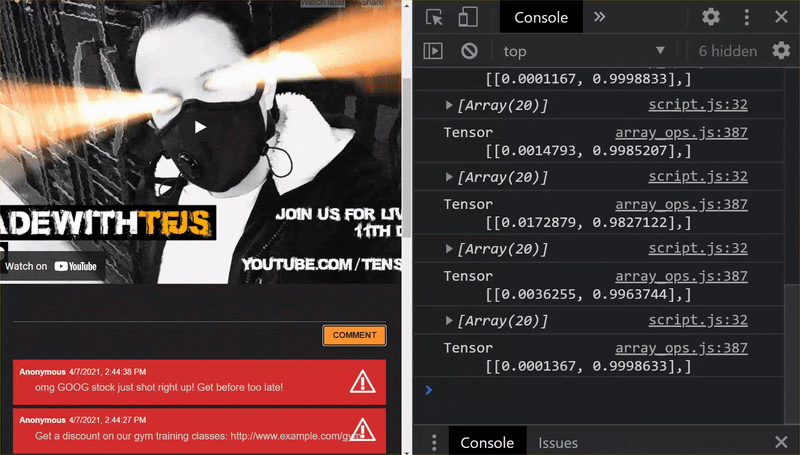
ในขณะนี้คุณจะเห็นได้ว่า 6 กลุ่มแรกการจัดประเภทถูกต้องว่าไม่ใช่สแปม ส่วนกลุ่มที่ 2 ของ 6 ทั้งหมดมีการระบุว่าเป็นสแปม สมบูรณ์แบบ
มาลองช่วยกันแปลว่ารูปแบบโดยทั่วไปดีหรือไม่ แต่เดิมจะมีประโยคที่ไม่สําเร็จ เช่น
"หุ้น GOOG เพิ่งแสดงผลได้ถูกต้อง มาสายเกินไป"
ขณะนี้ คุณจัดประเภทว่าเป็นจดหมายขยะได้อย่างถูกต้องแล้ว แต่จะเกิดอะไรขึ้นหากคุณเปลี่ยนเป็น
"หุ้น XYZ จึงมีมูลค่าเพิ่มขึ้น ซื้อเลยก่อนที่จะสายเกินไป"
ในหน้านี้ ระบบจะคาดคะเน 98% ว่าน่าจะเป็นจดหมายขยะจริงๆ แม้ว่าคุณจะเปลี่ยนสัญลักษณ์หุ้นหรือข้อความให้ถูกต้องเล็กน้อยก็ตาม
แน่นอนว่าหากพยายามสร้างรูปแบบใหม่ๆ นี้ คุณจะสามารถทําได้ และจะพบว่าสามารถรวบรวมข้อมูลการฝึกอบรมได้มากยิ่งขึ้น เพื่อจะได้โอกาสที่ดีที่สุดในการจับภาพการเปลี่ยนแปลงที่ไม่เหมือนใครของสถานการณ์ที่พบบ่อยซึ่งคุณอาจพบทางออนไลน์ ใน Codelab ในอนาคต เราจะแสดงวิธีปรับปรุงโมเดลด้วยข้อมูลสดอย่างต่อเนื่องเมื่อมีการแจ้งว่าไม่เหมาะสม
6. ยินดีด้วย
ยินดีด้วย คุณได้ฝึกการฝึกโมเดลแมชชีนเลิร์นนิงที่มีอยู่อีกครั้งเพื่ออัปเดตตัวเองให้ทํางานได้ ในกรณีที่ล้ําสมัยและพบการเปลี่ยนแปลงเหล่านั้นในเบราว์เซอร์ด้วย TensorFlow.js สําหรับแอปพลิเคชันในชีวิตจริง
สรุป
ใน Codelab นี้ คุณทําสิ่งต่อไปนี้ได้
- ค้นพบปัญหา Edge ที่ไม่ทํางานเมื่อใช้โมเดลสแปมความคิดเห็นที่เขียนไว้ล่วงหน้า
- ฝึกโมเดล Maker Maker ให้คํานึงถึงกรณีขอบที่คุณค้นพบ
- ส่งออกโมเดลที่ผ่านการฝึกใหม่ให้อยู่ในรูปแบบ TensorFlow.js
- อัปเดตเว็บแอปเพื่อใช้ไฟล์ใหม่
ขั้นตอนถัดไปที่ควรทํา
การอัปเดตนี้ใช้งานได้ดี แต่เช่นเดียวกับเว็บแอปนั้น การเปลี่ยนแปลงจะเกิดขึ้นเมื่อเวลาผ่านไป แต่จะดีกว่าเดิมหากแอปมีการปรับปรุงอย่างต่อเนื่องเมื่อเวลาผ่านไปแทนที่เราจะต้องดําเนินการด้วยตนเองทุกครั้ง คุณคิดว่ากระบวนการอัตโนมัติจะช่วยให้คุณฝึกโมเดลใหม่โดยอัตโนมัติได้อย่างไร เช่น เมื่อมีความคิดเห็นใหม่ 100 ความคิดเห็นซึ่งจัดประเภทผิด ใส่หมวกวิศวกรรมทั่วไปของเว็บไว้ และคุณอาจทราบวิธีสร้างไปป์ไลน์เพื่อดําเนินการโดยอัตโนมัติ หากไม่ใช่ก็ไม่ต้องกังวล ให้มองหา Codelab ถัดไปในชุดที่จะแสดงวิธีการให้คุณทราบ
แชร์สิ่งที่คุณทํากับเรา
นอกจากนี้ คุณยังขยายขอบเขตของสิ่งที่คุณทําอยู่สําหรับกรณีการใช้งานครีเอทีฟโฆษณาอื่นๆ ได้อย่างง่ายดายด้วย และขอแนะนําให้คุณคิดนอกกรอบและพยายามทําให้ถูกแฮ็กต่อไป
อย่าลืมติดแท็กเราบนโซเชียลมีเดียโดยใช้แฮชแท็ก #MadeWithTFJS เพื่อเพิ่มโอกาสให้โปรเจ็กต์ของคุณได้แสดงบนบล็อก TensorFlow หรือแม้กระทั่งกิจกรรมในอนาคต เราอยากเห็นสิ่งที่คุณทํา
เปิดตัว Codelab ใน TensorFlow.js เพื่อเจาะลึกมากขึ้น
- ใช้โฮสติ้งของ Firebase เพื่อติดตั้งใช้งานและโฮสต์โมเดล TensorFlow.js จํานวนมาก
- สร้างเว็บแคมอัจฉริยะโดยใช้โมเดลการตรวจจับออบเจ็กต์ที่สร้างไว้ล่วงหน้าด้วย TensorFlow.js
เว็บไซต์ที่ควรชําระเงิน
- เว็บไซต์อย่างเป็นทางการของ TensorFlow.js
- โมเดลที่สร้างไว้ล่วงหน้าของ TensorFlow.js
- TensorFlow.js API
- TensorFlow.js Show & Tell - หาแรงบันดาลใจและดูสิ่งที่คนอื่นสร้างขึ้น