
1. قبل البدء
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على الالتفافات وسبب فعاليتها في سيناريوهات رؤية الكمبيوتر.
في درس البرمجة السابق، أنشأت شبكة عصبية عميقة (DNN) بسيطة للرؤية الحاسوبية الخاصة بملابس الموضة. كانت هذه القاعدة محدودة لأنّها كانت تتطلّب أن يكون عنصر الملابس هو الشيء الوحيد في الصورة، وكان يجب أن يكون في المنتصف.
بالطبع، هذا ليس سيناريو واقعيًا. يجب أن يكون بإمكان الشبكة العصبية العميقة التعرّف على قطعة الملابس في الصور التي تتضمّن عناصر أخرى أو التي لا تظهر فيها قطعة الملابس في المقدّمة وفي المنتصف. لإجراء ذلك، عليك استخدام الالتفافات.
المتطلبات الأساسية
تستند ورشة العمل البرمجية هذه إلى العمل المكتمل في جزأين سابقين، وهما مقدمة عن "مرحبًا بالعالم" في تعلُّم الآلة وإنشاء نموذج للرؤية الحاسوبية. يُرجى إكمال هذه الدروس التطبيقية قبل المتابعة.
ما ستتعلمه
- ما هي الالتفافات؟
- كيفية إنشاء خريطة ميزات
- ما هو التجميع؟
ما ستنشئه
- خريطة ميزات صورة
المتطلبات
يمكنك العثور على الرمز البرمجي لبقية الدرس العملي الذي يتم تشغيله في Colab.
يجب أيضًا تثبيت TensorFlow والمكتبات التي ثبّتها في الدرس العملي السابق.
2. ما هي الالتفافات؟
الالتفاف هو فلتر يمر فوق صورة ويعالجها ويستخرج الميزات المهمة.
لنفترض أنّ لديك صورة لشخص يرتدي حذاء رياضيًا. كيف يمكن رصد حذاء رياضي في الصورة؟ لكي يرى برنامجك الصورة على أنّها حذاء رياضي، عليك استخراج الميزات المهمة وتمييز الميزات غير الأساسية. يُطلق على هذه العملية اسم ربط الميزات.
عملية ربط الميزات بسيطة من الناحية النظرية. ستفحص كل بكسل في الصورة ثم ستنظر إلى البكسلات المجاورة له. يتم ضرب قيم وحدات البكسل هذه في الأوزان المكافئة في الفلتر.
على سبيل المثال:
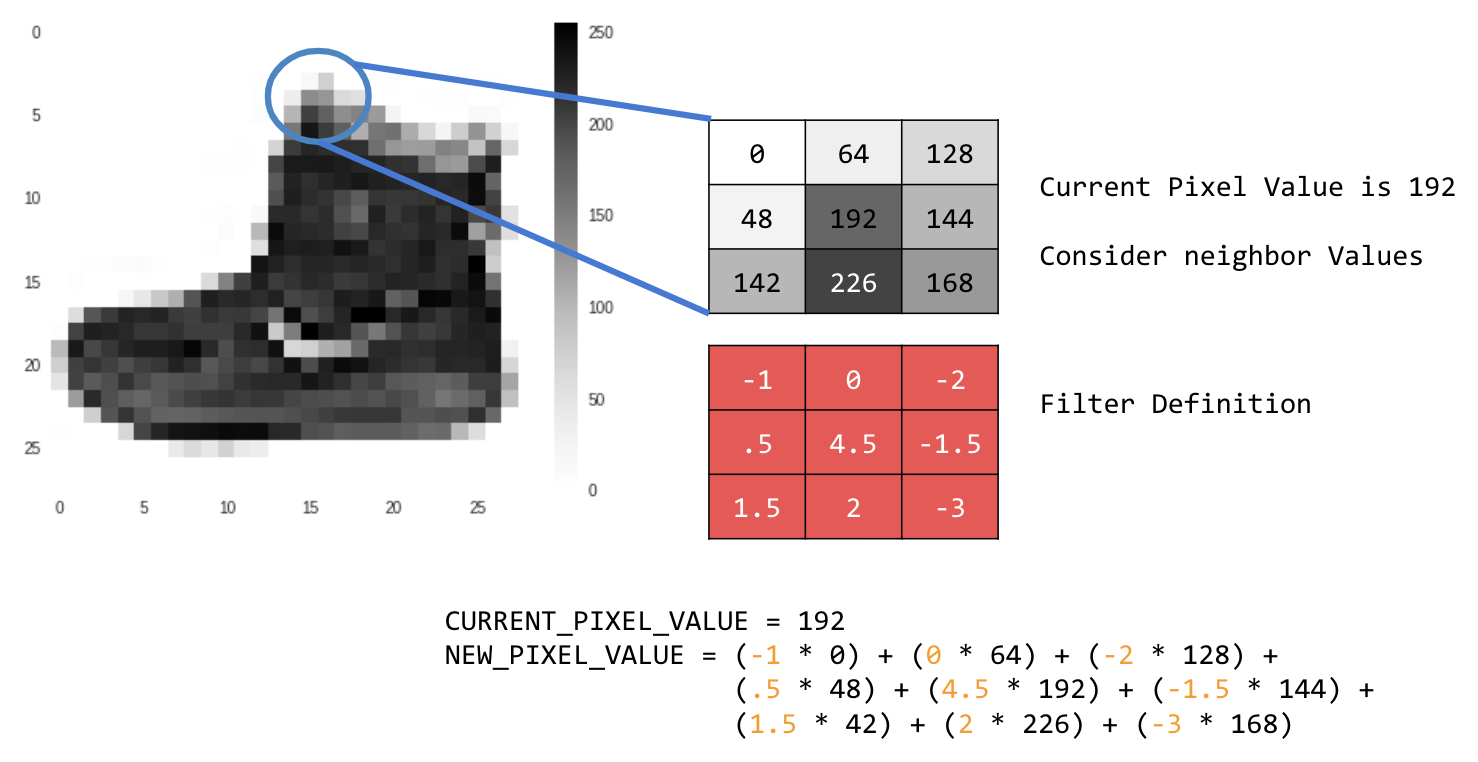
في هذه الحالة، يتم تحديد مصفوفة التفاف 3x3، أو نواة الصورة.
قيمة البكسل الحالية هي 192. يمكنك حساب قيمة البكسل الجديد من خلال النظر إلى قيم البكسلات المجاورة وضربها في القيم المحدّدة في الفلتر، ثم جعل قيمة البكسل الجديد هي المبلغ النهائي.
حان الوقت الآن لاستكشاف طريقة عمل الالتفافات من خلال إنشاء التفاف أساسي على صورة ذات تدرّج رمادي ثنائية الأبعاد.
ستوضّح ذلك باستخدام صورة الصعود من SciPy. إنّها صورة مدمجة جميلة تتضمّن الكثير من الزوايا والخطوط.
3- بدء الترميز
ابدأ باستيراد بعض مكتبات Python وصورة الصعود:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
بعد ذلك، استخدِم مكتبة Pyplot matplotlib لرسم الصورة حتى تعرف شكلها:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

يمكنك ملاحظة أنّها صورة لدرج. هناك الكثير من الميزات التي يمكنك تجربتها وعزلها. على سبيل المثال، هناك خطوط عمودية بارزة.
يتم تخزين الصورة كصفيفة NumPy، لذا يمكننا إنشاء الصورة المحوّلة من خلال نسخ هذه الصفيفة فقط. سيحتوي المتغيران size_x وsize_y على أبعاد الصورة حتى تتمكّن من تكرارها لاحقًا.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. إنشاء مصفوفة الالتفاف
أولاً، أنشئ مصفوفة التفاف (أو نواة) كمصفوفة 3x3:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
الآن، احسب وحدات البكسل الناتجة. كرِّر العملية على الصورة مع ترك هامش بمقدار بكسل واحد، واضرب كل بكسل مجاور للبكسل الحالي في القيمة المحدّدة في الفلتر.
وهذا يعني أنّه سيتم ضرب قيمة البكسل المجاورة للبكسل الحالي من الأعلى ومن اليسار في العنصر العلوي الأيسر في الفلتر. بعد ذلك، اضرب النتيجة في الوزن وتأكَّد من أنّ النتيجة تتراوح بين 0 و255.
أخيرًا، حمِّل القيمة الجديدة في الصورة المحوَّلة:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5- فحص النتائج
الآن، ارسم الصورة للاطّلاع على تأثير تمرير الفلتر عليها:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

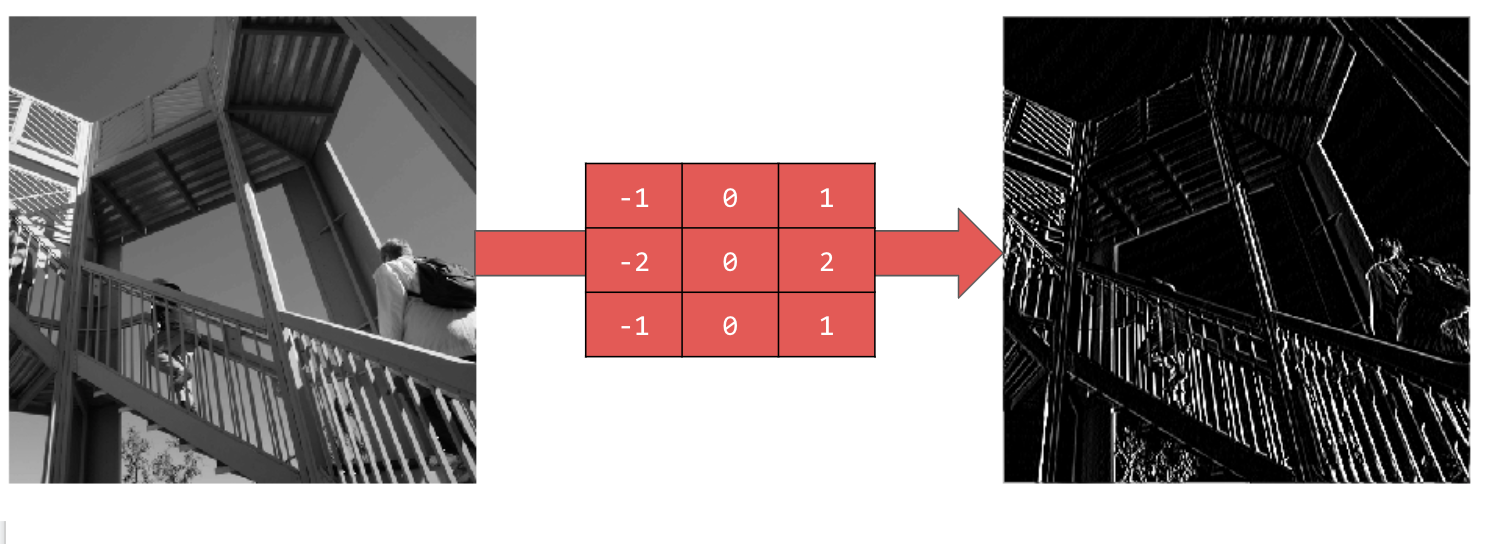
ضَع في اعتبارك قيم الفلتر التالية وتأثيرها في الصورة.
يمنحك استخدام [-1,0,1,-2,0,2,-1,0,1] مجموعة قوية جدًا من الخطوط العمودية:
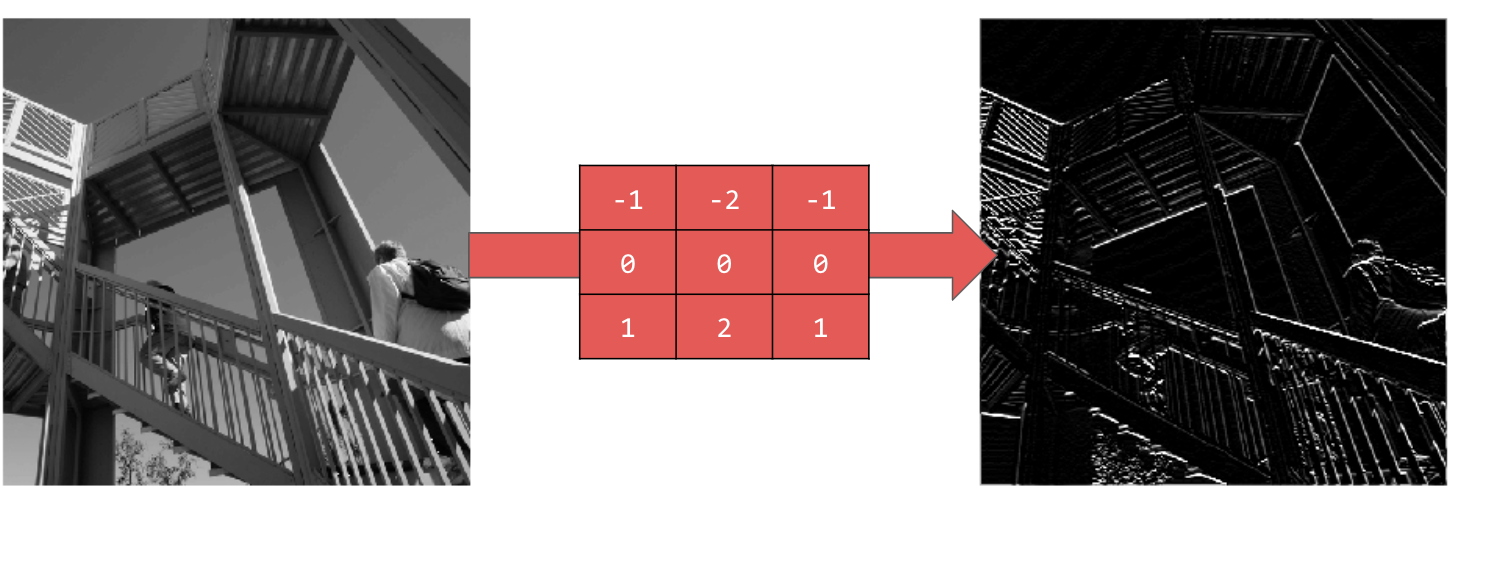
يؤدي استخدام [-1,-2,-1,0,0,0,1,2,1] إلى إنشاء خطوط أفقية:
استكشِف قيمًا مختلفة! جرِّب أيضًا فلاتر بأحجام مختلفة، مثل 5x5 أو 7x7.
6. فهم ميزة "تجميع الاشتراكات"
بعد تحديد الميزات الأساسية للصورة، ماذا تفعل؟ كيف تستخدم خريطة الميزات الناتجة لتصنيف الصور؟
على غرار الالتفافات، يساعد التجميع بشكل كبير في رصد الميزات. تؤدي طبقات التجميع إلى تقليل إجمالي كمية المعلومات في الصورة مع الحفاظ على الميزات التي يتم رصدها على أنّها متوفرة.
تتوفّر عدة أنواع مختلفة من تجميع العينات، ولكنّك ستستخدم نوعًا يُعرف باسم "تجميع العينات إلى الحدّ الأقصى".
كرِّر العملية على الصورة، وفي كل نقطة، ضع في اعتبارك البكسل والجيران المباشرين على اليمين والأسفل والأسفل على اليمين. خذ أكبر هذه القيم (ومن هنا جاءت تسمية التجميع الأقصى) وحمِّلها في الصورة الجديدة. وبالتالي، سيكون حجم الصورة الجديدة ربع حجم الصورة القديمة. 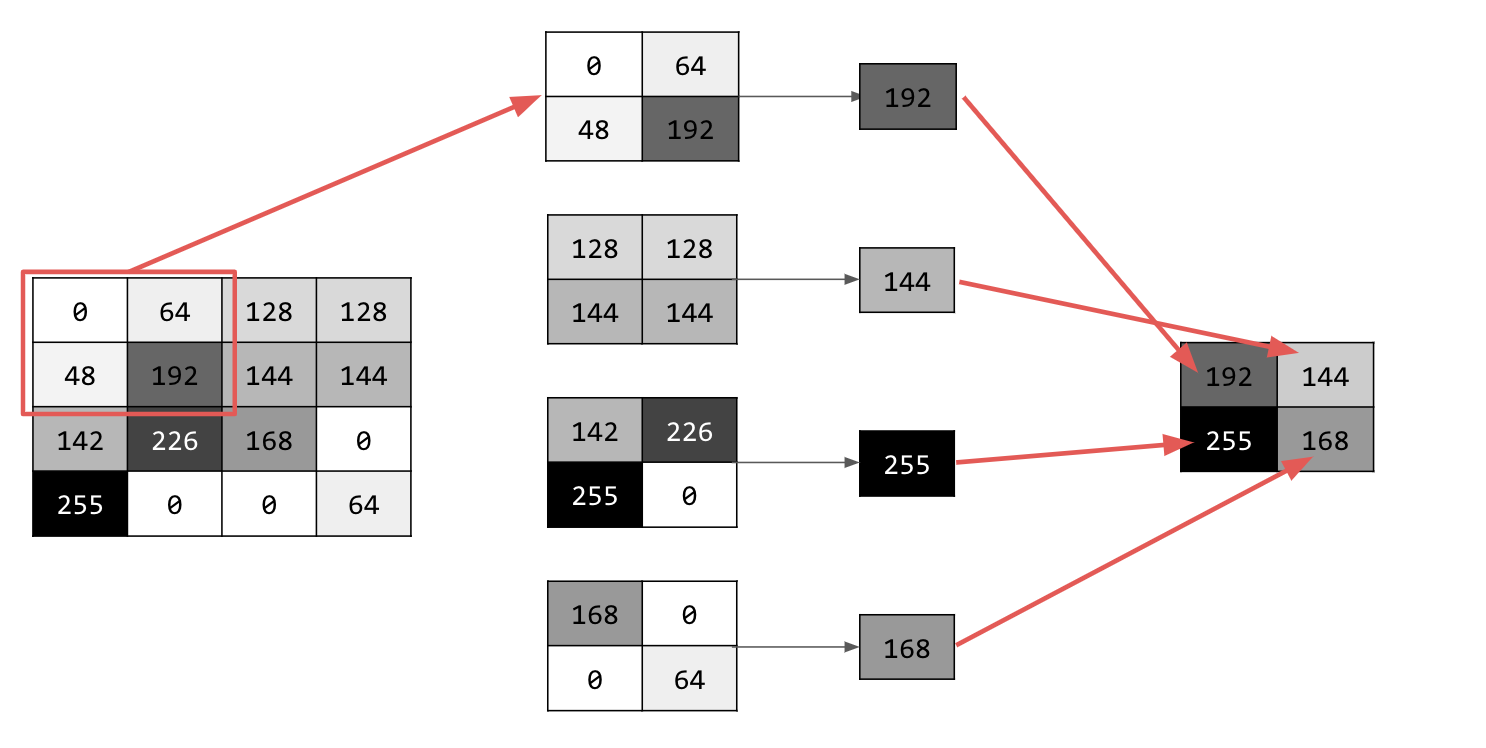
7. كتابة رمز برمجي للتجميع
سيعرض الرمز التالي تجميعًا (2, 2). نفِّذها للاطّلاع على الناتج.
ستلاحظ أنّه على الرغم من أنّ حجم الصورة ربع حجم الصورة الأصلية، إلا أنّها احتفظت بجميع الميزات.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

لاحظ محاور هذا الرسم البياني. أصبحت الصورة الآن 256x256، أي ربع حجمها الأصلي، وتم تحسين الميزات التي تم رصدها على الرغم من أنّ الصورة تحتوي الآن على بيانات أقل.
8. تهانينا
لقد أنشأت نموذج رؤية الكمبيوتر الأول. لمعرفة كيفية تحسين نماذج رؤية الكمبيوتر بشكل أكبر، انتقِل إلى إنشاء شبكات عصبونية التفافية (CNN) لتحسين رؤية الكمبيوتر.