이제 Checks Guardrails API를 비공개 미리보기의 알파 버전으로 사용할 수 있습니다. 신청 양식을 사용하여 비공개 미리보기에 대한 액세스 권한을 요청하세요.
Guardrails API는 텍스트가 잠재적으로 유해하거나 안전하지 않은지 확인할 수 있는 API입니다. 생성형 AI 애플리케이션에서 이 API를 사용하여 사용자가 잠재적으로 유해한 콘텐츠에 노출되지 않도록 할 수 있습니다.
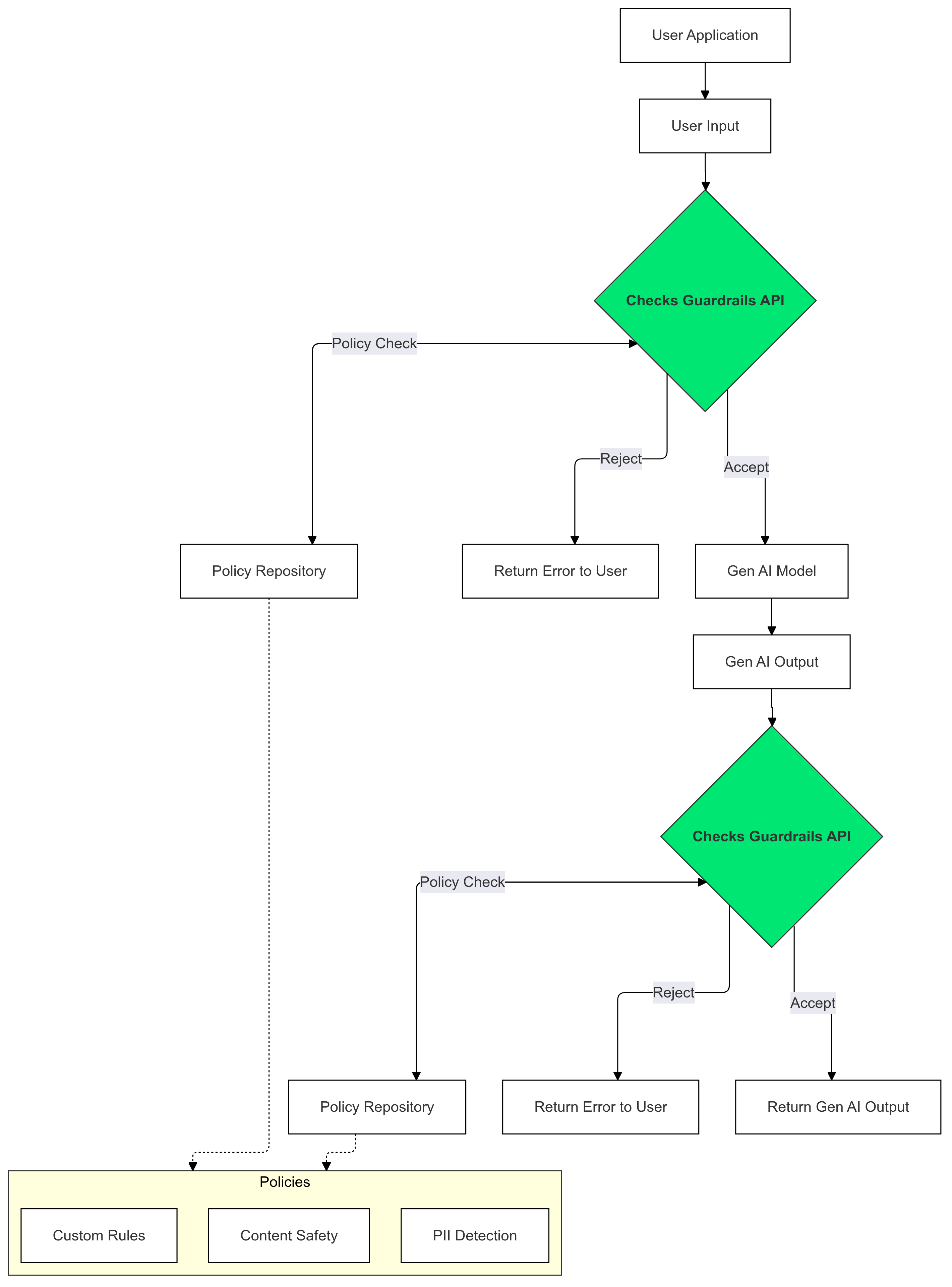
Guardrails를 사용하는 방법
생성형 AI 입력 및 출력에서 Checks Guardrails를 사용하여 정책을 위반하는 텍스트의 존재를 감지하고 완화합니다.
Guardrails를 사용하는 이유
LLM은 잠재적으로 유해하거나 부적절한 콘텐츠를 생성할 수 있습니다. Guardrails API를 생성형 AI 애플리케이션에 통합하는 것은 대규모 언어 모델 (LLM)을 책임감 있고 안전하게 사용하는 데 매우 중요합니다. 부적절한 언어, 차별적 발언, 유해성을 조장할 수 있는 콘텐츠 등 잠재적으로 유해한 다양한 출력을 필터링하여 생성된 콘텐츠와 관련된 위험을 완화하는 데 도움이 됩니다. 이렇게 하면 사용자를 보호할 뿐만 아니라 애플리케이션의 평판을 보호하고 잠재고객 간의 신뢰를 구축할 수 있습니다. 안전과 책임을 우선시하는 Guardrails를 사용하면 혁신적이고 안전한 생성형 AI 애플리케이션을 빌드할 수 있습니다.
시작하기
이 가이드에서는 Guardrails API를 사용하여 애플리케이션에서 부적절한 콘텐츠를 감지하고 필터링하는 방법을 설명합니다. 이 API는 증오심 표현, 폭력, 선정적인 자료와 같은 다양한 유형의 잠재적으로 유해한 콘텐츠를 식별할 수 있는 다양한 사전 학습된 정책을 제공합니다. 각 정책의 기준점을 설정하여 API의 동작을 맞춤설정할 수도 있습니다.
기본 요건
- Checks AI Safety 비공개 미리보기에 대해 Google Cloud 프로젝트를 승인받습니다. 아직 승인받지 않았다면 신청 양식을 사용하여 액세스 권한을 요청하세요.
- Checks API를 사용 설정합니다.
- 승인 가이드를 사용하여 승인된 요청을 보낼 수 있는지 확인합니다.
지원되는 정책
| 정책 이름 | 정책 설명 | 정책 유형 API 열거형 값 |
|---|---|---|
| 위험한 콘텐츠 | 유해한 상품, 서비스, 활동에 대한 액세스를 촉진, 홍보 또는 지원하는 콘텐츠입니다. | DANGEROUS_CONTENT |
| PII 요청 및 인용 | 개인의 민감한 개인 정보 또는 데이터를 요청하거나 공개하는 콘텐츠입니다. | PII_SOLICITING_RECITING |
| 괴롭힘 | 다른 개인을 대상으로 악의적이거나, 위협적이거나, 괴롭히거나, 학대하는 콘텐츠입니다. | HARASSMENT |
| 선정적 | 본질적으로 선정적인 콘텐츠입니다. | SEXUALLY_EXPLICIT |
| 증오심 표현 | 일반적으로 증오심 표현으로 간주되는 콘텐츠입니다. | HATE_SPEECH |
| 의료 정보 | 유해한 의료 조언 또는 안내에 대한 액세스를 촉진, 홍보 또는 지원하는 콘텐츠는 금지됩니다. | MEDICAL_INFO |
| 폭력적이거나 잔인한 콘텐츠 | 사실적인 폭력 또는 잔인한 콘텐츠에 대한 불필요한 설명이 포함된 콘텐츠입니다. | VIOLENCE_AND_GORE |
| 저속한 콘텐츠 및 욕설 | 저속하거나, 모욕적이거나, 불쾌감을 주는 언어가 포함된 콘텐츠는 금지됩니다. | OBSCENITY_AND_PROFANITY |
코드 스니펫
Python
pip install
google-api-python-client를 실행하여 Google API Python 클라이언트를 설치합니다.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
Go
go get google.golang.org/api/checks/v1alpha를 실행하여 Checks API Go 클라이언트를 설치합니다.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
REST
참고: 이 예에서는 oauth2l CLI 도구를 사용합니다.
YOUR_GCP_PROJECT_ID를 Guardrails API에 대한 액세스 권한이 부여된 Google Cloud 프로젝트 ID로 바꿉니다.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
샘플 응답
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
사용 사례
Guardrails API는 특정 요구사항 및 위험 허용 범위에 따라 다양한 방식으로 LLM 애플리케이션에 통합할 수 있습니다. 다음은 몇 가지 일반적인 사용 사례입니다.
Guardrail 개입 없음 - 로깅
이 시나리오에서는 앱의 동작을 변경하지 않고 Guardrails API가 사용됩니다. 하지만 모니터링 및 감사 목적으로 잠재적인 정책 위반이 로깅됩니다. 이 정보는 잠재적인 LLM 안전 위험을 식별하는 데 추가로 사용할 수 있습니다.
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
Go
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
정책에 따라 Guardrail이 차단됨
이 예에서는 Guardrails API가 안전하지 않은 사용자 입력 및 모델 응답을 차단합니다. 사전 정의된 안전 정책 (예: 증오심 표현, 위험한 콘텐츠)에 대해 모두 확인합니다. 이렇게 하면 AI가 잠재적으로 유해한 출력을 생성하지 못하도록 하고 사용자가 부적절한 콘텐츠를 접하지 않도록 보호할 수 있습니다.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
Go
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
LLM 출력을 Guardrails로 스트리밍
다음 예에서는 LLM의 출력을 Guardrails API로 스트리밍합니다. 이렇게 하면 사용자가 인식하는 지연 시간을 줄일 수 있습니다. 이 접근 방식은 컨텍스트가 불완전하여 거짓양성을 유발할 수 있으므로 API를 호출하기 전에 Guardrails가 정확하게 평가할 수 있도록 LLM 출력에 충분한 컨텍스트가 포함되어야 합니다.
동기 Guardrails 호출
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
Go
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
비동기 Guardrails 호출
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
Go
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
FAQ
Guardrails API의 할당량 한도에 도달한 경우 어떻게 해야 하나요?
할당량 증가를 요청하려면 요청과 함께 checks-support@google.com으로 이메일을 보내세요. 이메일에 다음 정보를 포함하세요.
- Google Cloud 프로젝트 번호: 이 번호를 통해 계정을 빠르게 식별할 수 있습니다.
- 사용 사례에 관한 세부정보: Guardrails API를 사용하는 방법을 설명합니다.
- 원하는 할당량: 필요한 추가 할당량을 지정합니다.