L'API Checks Guardrails è ora disponibile in versione alpha in anteprima privata. Richiedi l'accesso all'anteprima privata utilizzando il nostro modulo di interesse.
L'API Guardrails è un'API che ti consente di verificare se il testo è potenzialmente dannoso o non sicuro. Puoi utilizzare questa API nella tua applicazione GenAI per impedire ai tuoi utenti di essere esposti a contenuti potenzialmente dannosi.
Come utilizzare i guardrail
Utilizza i controlli di protezione sugli input e sugli output dell'AI generativa per rilevare e mitigare la presenza di testo che viola le tue norme.
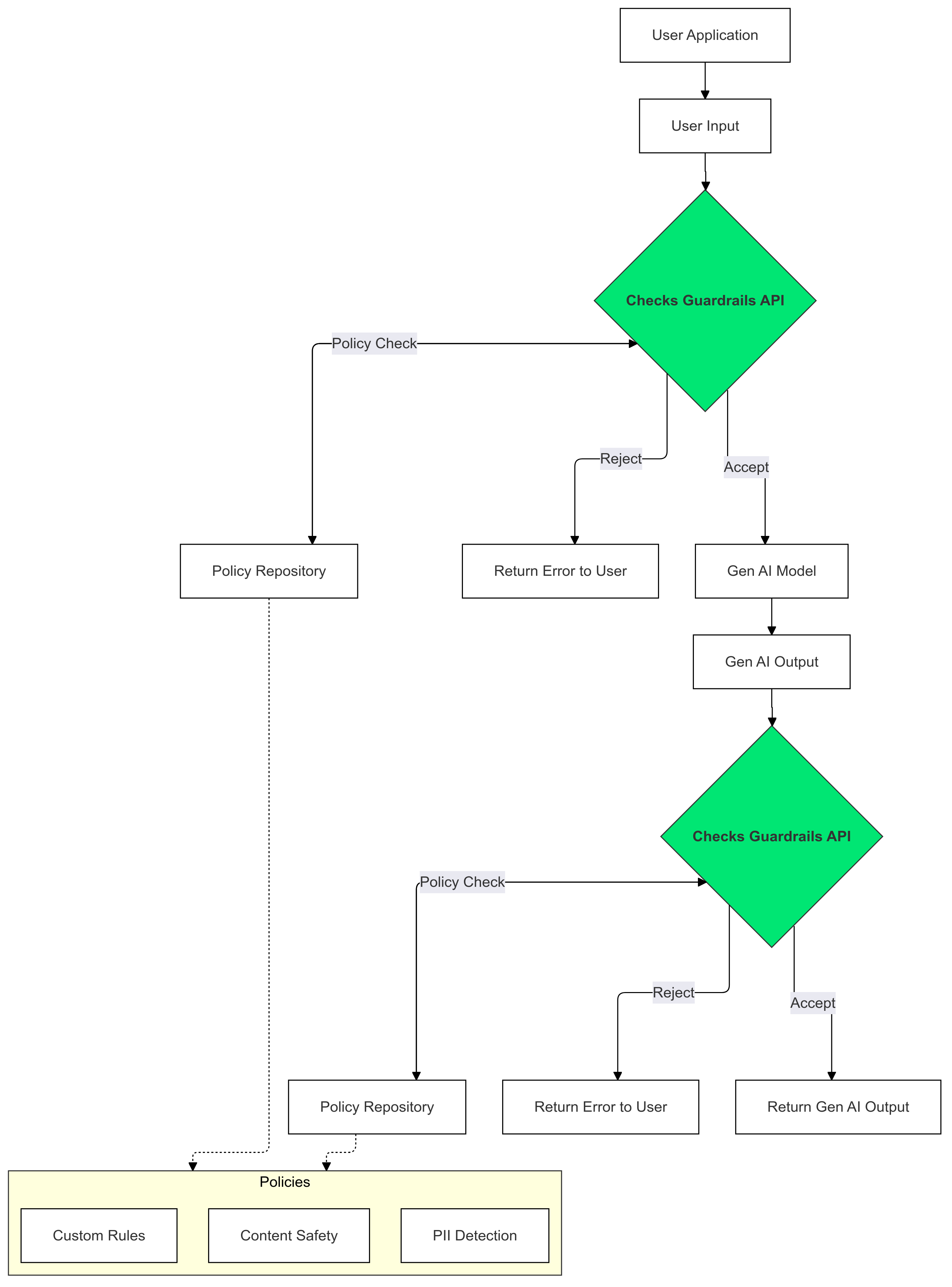
Perché utilizzare i guardrail?
A volte gli LLM possono generare contenuti potenzialmente dannosi o inappropriati. L'integrazione dell'API Guardrails nella tua applicazione GenAI è fondamentale per garantire un utilizzo responsabile e più sicuro dei modelli linguistici di grandi dimensioni (LLM). Ti aiuta a mitigare i rischi associati ai contenuti generati filtrando un'ampia gamma di output potenzialmente dannosi, tra cui linguaggio inappropriato, osservazioni discriminatorie e contenuti che potrebbero facilitare danni. In questo modo non solo proteggi i tuoi utenti, ma salvaguardi anche la reputazione della tua applicazione e promuovi la fiducia del tuo pubblico. Dando la priorità alla sicurezza e alla responsabilità, le misure di protezione ti consentono di creare applicazioni di AI generativa innovative e più sicure.
Per iniziare
Questa guida fornisce istruzioni per l'utilizzo dell'API Guardrails per rilevare e filtrare i contenuti inappropriati nelle tue applicazioni. L'API offre una serie di norme preaddestrate che possono identificare diversi tipi di contenuti potenzialmente dannosi, come incitamento all'odio, violenza e materiale sessualmente esplicito. Puoi anche personalizzare il comportamento dell'API impostando le soglie per ogni criterio.
Prerequisiti
- Il tuo progetto Google Cloud deve essere approvato per l'anteprima privata di Checks AI Safety. Se non l'hai ancora fatto, richiedi l'accesso utilizzando il nostro modulo di interesse.
- Attiva l'API Checks.
- Assicurati di poter inviare richieste autorizzate utilizzando la nostra guida all'autorizzazione.
Norme supportate
| Nome norma | Descrizione della norma | Valore enum API Tipo di norma |
|---|---|---|
| Contenuti pericolosi | Contenuti che facilitano, promuovono o consentono l'accesso a beni, servizi e attività dannosi. | DANGEROUS_CONTENT |
| Richiesta e recitazione di PII | Contenuti che richiedono o rivelano dati o informazioni personali sensibili di un individuo. | PII_SOLICITING_RECITING |
| Molestie | Contenuti dannosi, intimidatori, prepotenti o illeciti rivolti a un altro individuo o gruppo. | HARASSMENT |
| Contenuti sessualmente espliciti | Contenuti di natura sessualmente esplicita. | SEXUALLY_EXPLICIT |
| Incitamento all'odio | Contenuti generalmente accettati come incitamento all'odio. | HATE_SPEECH |
| Informazioni mediche | Sono vietati i contenuti che facilitano, promuovono o consentono l'accesso a consigli o indicazioni mediche dannosi. | MEDICAL_INFO |
| Violenza e spargimenti di sangue | Contenuti che includono descrizioni senza costi di violenza realistica e/o scene cruente. | VIOLENCE_AND_GORE |
| Oscenità e linguaggio volgare | Sono vietati i contenuti che utilizzano un linguaggio volgare, blasfemo o offensivo. | OBSCENITY_AND_PROFANITY |
Snippet di codice
Python
Installa il client Python dell'API di Google eseguendo pip install
google-api-python-client.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
Go
Installa il client Go dell'API Checks eseguendo
go get google.golang.org/api/checks/v1alpha.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
REST
Nota: questo esempio utilizza lo strumento CLI oauth2l.
Sostituisci YOUR_GCP_PROJECT_ID con il tuo ID progetto Google Cloud a cui è stato concesso l'accesso all'API Guardrails.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
Esempio di risposta
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
Casi d'uso
L'API Guardrails può essere integrata nella tua applicazione LLM in vari modi, a seconda delle tue esigenze specifiche e della tua tolleranza al rischio. Ecco alcuni esempi di casi d'uso comuni:
Nessun intervento di guardrail - Registrazione
In questo scenario, l'API Guardrails viene utilizzata senza apportare modifiche al comportamento dell'app. Tuttavia, le potenziali violazioni delle norme vengono registrate ai fini del monitoraggio e del controllo. Queste informazioni possono essere ulteriormente utilizzate per identificare potenziali rischi per la sicurezza degli LLM.
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
Go
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
Guardrail bloccato in base a una policy
In questo esempio, l'API Guardrails blocca gli input dell'utente e le risposte del modello non sicuri. Controlla sia le norme di sicurezza predefinite (ad es. incitamento all'odio, contenuti pericolosi). In questo modo, l'AI non genera output potenzialmente dannosi e gli utenti non visualizzano contenuti inappropriati.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
Go
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
Trasmettere l'output dell'LLM a Guardrails
Negli esempi seguenti, trasmettiamo l'output di un LLM all'API Guardrails. Può essere utilizzato per ridurre la latenza percepita dall'utente. Questo approccio può introdurre falsi positivi a causa di un contesto incompleto, pertanto è importante che l'output dell'LLM abbia un contesto sufficiente per consentire a Guardrails di effettuare una valutazione accurata prima di chiamare l'API.
Chiamate sincrone di guardrail
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
Go
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
Chiamate asincrone delle linee guida
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
Go
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
Domande frequenti
Cosa devo fare se ho raggiunto i limiti di quota per l'API Guardrails?
Per richiedere un aumento della quota, invia un'email all'indirizzo checks-support@google.com. Nella tua email includi le seguenti informazioni:
- Il numero del tuo progetto Google Cloud: ci aiuta a identificare rapidamente il tuo account.
- Dettagli sul tuo caso d'uso: spiega come utilizzi l'API Guardrails.
- Importo della quota desiderata: specifica la quota aggiuntiva di cui hai bisogno.