ה-API של Checks Guardrails זמין עכשיו בגרסת אלפא ב-private preview. כדי לבקש גישה לגרסת Private Preview, צריך למלא את טופס ההתעניינות שלנו.
Guardrails API הוא API שמאפשר לבדוק אם הטקסט עלול להזיק או לא בטוח. אתם יכולים להשתמש ב-API הזה באפליקציית ה-AI הגנרטיבי שלכם כדי למנוע מהמשתמשים להיחשף לתוכן פוגעני.
איך משתמשים בשכבות הגנה?
אתם יכולים להשתמש באמצעי ההגנה של Checks כדי לזהות ולצמצם את הסיכון להופעת טקסט שמפר את המדיניות שלכם בקלט ובפלט של ה-AI הגנרטיבי.
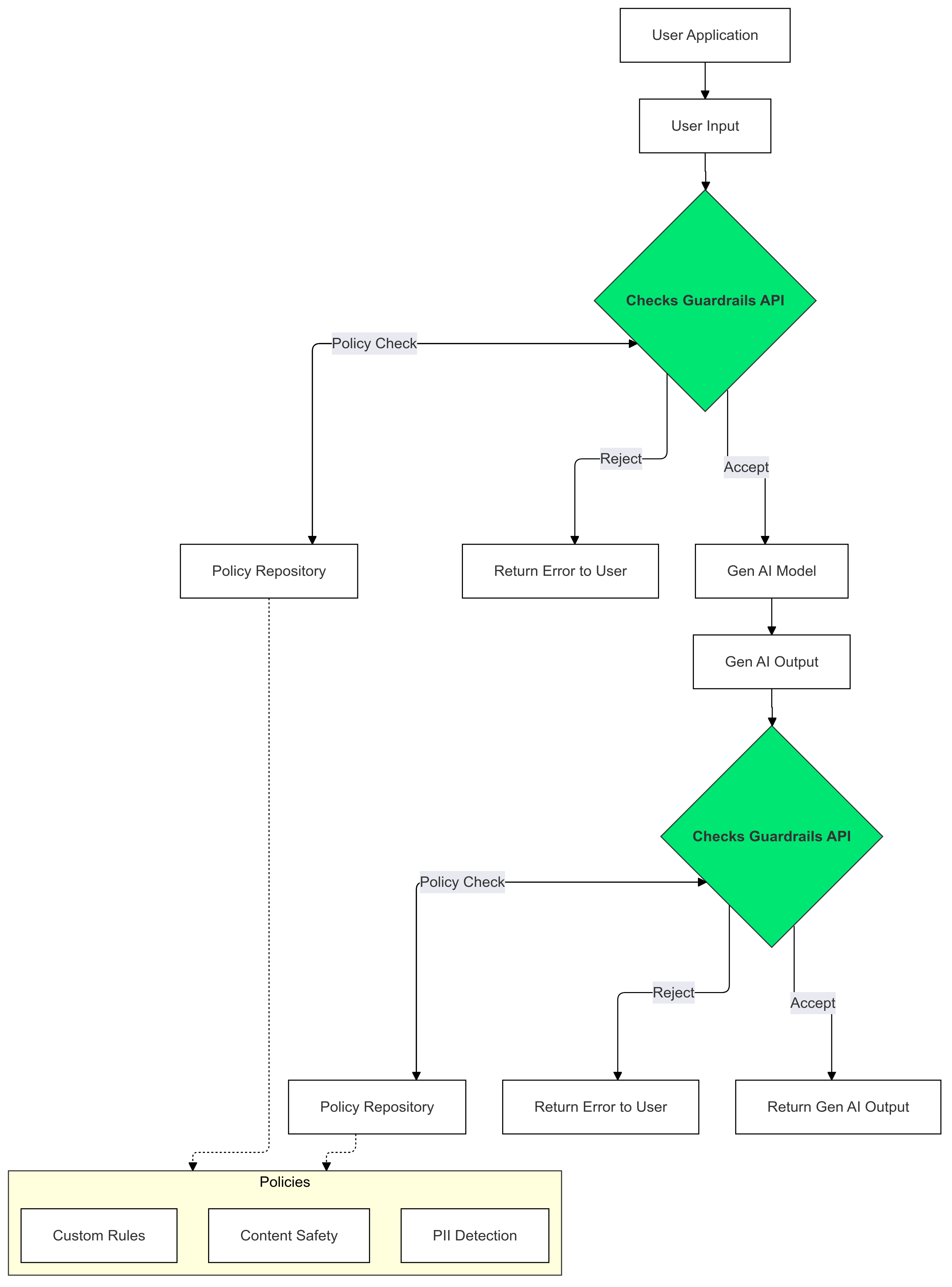
למה כדאי להשתמש באמצעי בקרה?
לפעמים מודלים מסוג LLM יכולים ליצור תוכן שעלול להיות מזיק או לא הולם. שילוב של Guardrails API באפליקציית ה-AI הגנרטיבי שלכם הוא חיוני כדי להבטיח שימוש אחראי ובטוח יותר במודלים גדולים של שפה (LLM). המסננים עוזרים לצמצם את הסיכונים שקשורים לתוכן שנוצר על ידי AI, על ידי סינון מגוון רחב של פלטים שעלולים להיות מזיקים, כולל שפה לא הולמת, הערות מפלות ותוכן שעלול להקל על גרימת נזק. השימוש ב-SSV לא רק מגן על המשתמשים, אלא גם שומר על המוניטין של האפליקציה ומחזק את האמון בקרב הקהל. הגדרות ה-Guardrails מאפשרות לכם לתת עדיפות לבטיחות ולאחריות, ולפתח אפליקציות AI גנרטיביות שהן גם חדשניות וגם בטוחות יותר.
תחילת העבודה
במדריך הזה מוסבר איך להשתמש ב-Guardrails API כדי לזהות ולסנן תוכן לא הולם באפליקציות. ה-API מציע מגוון של כללי מדיניות שאומנו מראש ויכולים לזהות סוגים שונים של תוכן שעלול להיות מזיק, כמו דברי שטנה, אלימות וחומרים מיניים בוטים. אפשר גם להתאים אישית את אופן הפעולה של ה-API על ידי הגדרת ספי ערכים לכל כלל מדיניות.
דרישות מוקדמות
- הפרויקט שלכם ב-Google Cloud אושר להשתתפות בגרסת טרום-השקה פרטית של Checks AI Safety. אם עדיין לא עשיתם זאת, אתם יכולים לבקש גישה באמצעות טופס ההתעניינות.
- מפעילים את Checks API.
- חשוב לוודא שאתם יכולים לשלוח בקשות מורשות באמצעות מדריך ההרשאה שלנו.
כללי מדיניות נתמכים
| שם מדיניות | תיאור המדיניות | ערך ה-Enum של ה-API של סוג המדיניות |
|---|---|---|
| תוכן מסוכן | תוכן שמאפשר גישה למוצרים, לשירותים ולפעילויות מזיקים, מקדם אותם או עוזר לבצע אותם. | DANGEROUS_CONTENT |
| בקשת פרטים אישיים מזהים (PII) וציטוט שלהם | תוכן שמבקש או חושף מידע אישי רגיש או נתונים של אדם מסוים. | PII_SOLICITING_RECITING |
| הטרדה | תוכן זדוני, מאיים, בריוני או פוגעני כלפי אדם או אנשים אחרים. | HARASSMENT |
| תוכן מיני בוטה | תוכן מיני בוטה. | SEXUALLY_EXPLICIT |
| דברי שטנה | תוכן שנחשב באופן כללי לדברי שטנה. | HATE_SPEECH |
| מידע רפואי | אסור לפרסם תוכן שמספק גישה להנחיות או לייעוץ רפואי מזיק, מקדם אותם או מאפשר אותם. | MEDICAL_INFO |
| אלימות ופציעות קשות | תוכן שכולל תיאורים מפורטים של אלימות ריאליסטית ו/או שפיכות דמים. | VIOLENCE_AND_GORE |
| שפה מגונה או גסה | אסור לפרסם תוכן שכולל שפה גסה, בוטה או פוגענית. | OBSCENITY_AND_PROFANITY |
קטעי קוד
Python
מריצים את הפקודה pip install
google-api-python-client כדי להתקין את לקוח Python של Google API.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
Go
כדי להתקין את Checks API Go Client, מריצים את הפקודה go get google.golang.org/api/checks/v1alpha.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
REST
הערה: בדוגמה הזו נעשה שימוש בoauth2l כלי CLI.
מחליפים את YOUR_GCP_PROJECT_ID במזהה הפרויקט ב-Google Cloud שקיבל גישה ל-Guardrails API.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
דוגמה לתשובה
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
תרחישים לדוגמה
אפשר לשלב את Guardrails API באפליקציית ה-LLM שלכם במגוון דרכים, בהתאם לצרכים הספציפיים ולמוכנות שלכם לקחת סיכונים. הנה כמה דוגמאות לתרחישי שימוש נפוצים:
No Guardrail Intervention - Logging
בתרחיש הזה, נעשה שימוש ב-Guardrails API ללא שינויים בהתנהגות האפליקציה. עם זאת, הפרות מדיניות אפשריות מתועדות לצורך מעקב וביקורת. אפשר להשתמש במידע הזה גם כדי לזהות סיכוני בטיחות פוטנציאליים של מודלים גדולים של שפה (LLM).
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
Go
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
הגבלת השימוש נחסמה על סמך מדיניות
בדוגמה הזו, Guardrails API חוסם קלט לא בטוח של משתמשים ותגובות של מודלים. הוא בודק את שניהם בהשוואה למדיניות בטיחות מוגדרת מראש (למשל, דברי שטנה, תוכן מסוכן). כך נמנע מצב שבו ה-AI יוצר פלט שעלול להיות מזיק, והמשתמשים לא נחשפים לתוכן לא הולם.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
Go
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
העברת פלט של LLM ל-Guardrails
בדוגמאות הבאות, אנחנו מעבירים פלט מ-LLM ל-Guardrails API. אפשר להשתמש בזה כדי לקצר את זמן הטעינה הנתפס של המשתמשים. הגישה הזו עלולה להוביל לתוצאות חיוביות שגויות בגלל הקשר לא מלא, ולכן חשוב שלפלט של ה-LLM יהיה מספיק הקשר כדי שהמערכת תבצע הערכה מדויקת לפני הפעלת ה-API.
קריאות סינכרוניות של שכבות הגנה
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
Go
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
הפעלות אסינכרוניות של שכבות הגנה
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
Go
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
שאלות נפוצות
מה עושים אם מגיעים למגבלות המכסה של Guardrails API?
כדי לבקש הגדלה של המכסה, צריך לשלוח בקשה באימייל לכתובת checks-support@google.com. חשוב לכלול באימייל את הפרטים הבאים:
- מספר הפרויקט שלכם ב-Google Cloud: כך נוכל לזהות במהירות את החשבון שלכם.
- פרטים על תרחיש השימוש: הסבר על אופן השימוש ב-Guardrails API.
- כמות המכסה הרצויה: מציינים כמה מכסה נוספת אתם צריכים.