API مربوط به Checks Guardrails اکنون در نسخه آلفا و پیشنمایش خصوصی در دسترس است. برای دسترسی به پیشنمایش خصوصی، فرم درخواست را پر کنید.
API گاردریلز (Guardrails API) یک API است که به شما امکان میدهد بررسی کنید که آیا متن بالقوه مضر یا ناامن است یا خیر. میتوانید از این API در برنامه GenAI خود استفاده کنید تا از قرار گرفتن کاربرانتان در معرض محتوای بالقوه مضر جلوگیری کنید.
چگونه از گاردریل استفاده کنیم؟
از Checks Guardrails روی ورودیها و خروجیهای Gen AI خود استفاده کنید تا وجود متنی که سیاستهای شما را نقض میکند، شناسایی و کاهش دهید.
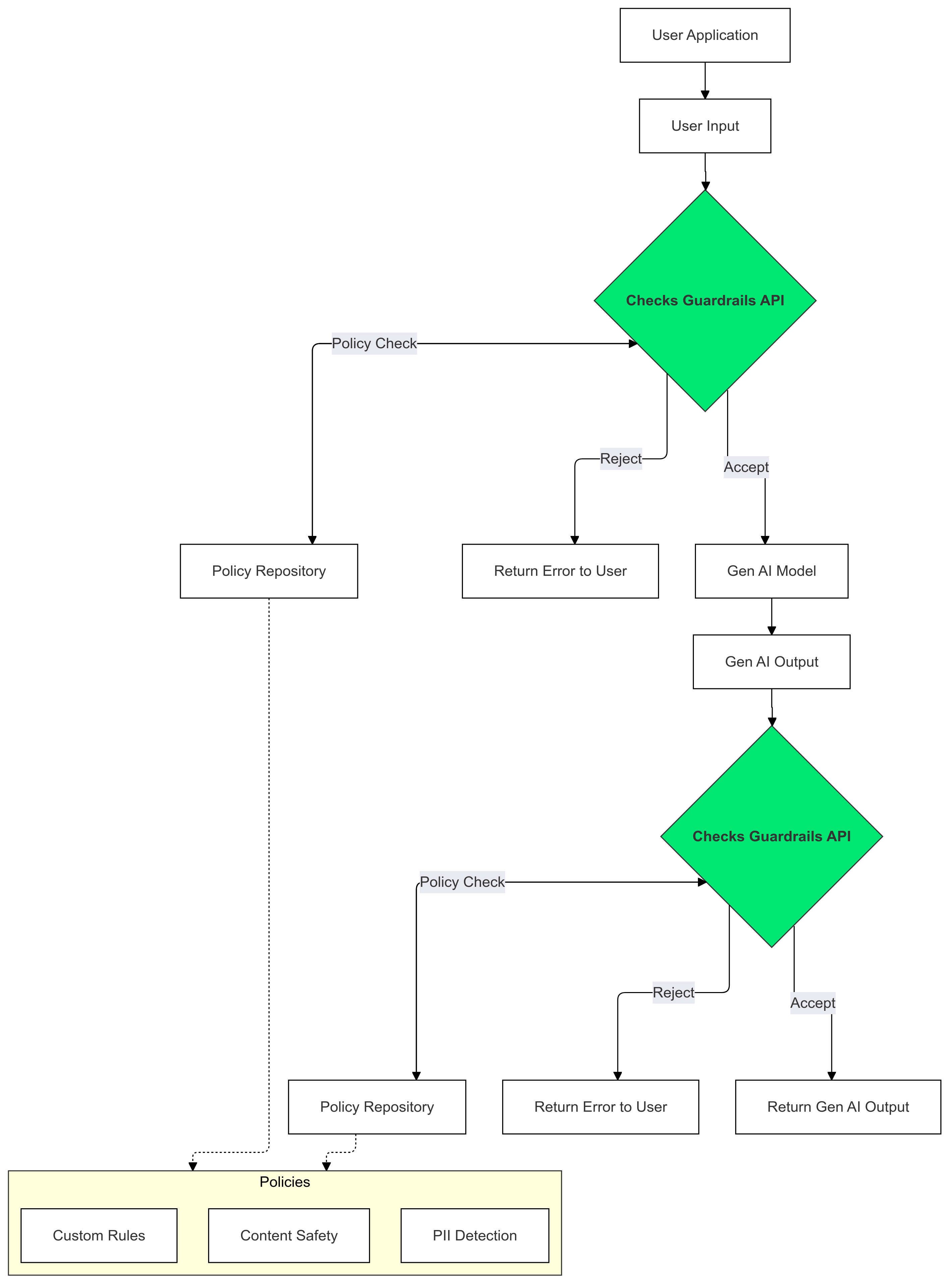
چرا از گاردریل استفاده کنیم؟
LLMها گاهی اوقات میتوانند محتوای بالقوه مضر یا نامناسب تولید کنند. ادغام API گاردریلز در برنامه GenAI شما برای اطمینان از استفاده مسئولانه و ایمنتر از مدلهای زبانی بزرگ (LLM) بسیار مهم است. این API به شما کمک میکند تا با فیلتر کردن طیف گستردهای از خروجیهای بالقوه مضر، از جمله زبان نامناسب، اظهارات تبعیضآمیز و محتوایی که میتواند آسیب را تسهیل کند، خطرات مرتبط با محتوای تولید شده را کاهش دهید. این امر نه تنها از کاربران شما محافظت میکند، بلکه از اعتبار برنامه شما نیز محافظت میکند و اعتماد را در بین مخاطبان شما تقویت میکند. با اولویت دادن به ایمنی و مسئولیت، گاردریلز به شما این امکان را میدهد تا برنامههای GenAI بسازید که هم نوآورانه و هم ایمنتر باشند.
شروع به کار
این راهنما دستورالعملهایی برای استفاده از API گاردریلز جهت شناسایی و فیلتر کردن محتوای نامناسب در برنامههای شما ارائه میدهد. این API طیف وسیعی از سیاستهای از پیش آموزشدیده را ارائه میدهد که میتوانند انواع مختلف محتوای بالقوه مضر، مانند سخنان نفرتپراکن، خشونت و مطالب صریح جنسی را شناسایی کنند. همچنین میتوانید با تعیین آستانه برای هر سیاست، رفتار API را سفارشی کنید.
پیشنیازها
- پروژه گوگل کلود شما برای پیشنمایش خصوصی Checks AI Safety تأیید شود. اگر هنوز این کار را نکردهاید، با استفاده از فرم علاقهمندی ما درخواست دسترسی دهید.
- فعال کردن API بررسیها
- مطمئن شوید که میتوانید با استفاده از راهنمای مجوز ما، درخواستهای مجاز ارسال کنید.
سیاستهای پشتیبانیشده
| نام سیاست | شرح سیاست | نوع سیاست API مقدار شمارشی |
|---|---|---|
| محتوای خطرناک | محتوایی که دسترسی به کالاها، خدمات و فعالیتهای مضر را تسهیل، ترویج یا ممکن میسازد. | DANGEROUS_CONTENT |
| درخواست و تلاوت PII | محتوایی که اطلاعات یا دادههای شخصی حساس یک فرد را درخواست یا فاش کند. | PII_SOLICITING_RECITING |
| آزار و اذیت | محتوایی که مخرب، تهدیدآمیز، قلدرمآبانه یا توهینآمیز نسبت به فرد یا افراد دیگر باشد. | HARASSMENT |
| صریح جنسی | محتوایی که ماهیت جنسی آشکاری دارد. | SEXUALLY_EXPLICIT |
| نفرتپراکنی | محتوایی که عموماً به عنوان گفتار نفرتپراکن پذیرفته میشود. | HATE_SPEECH |
| اطلاعات پزشکی | محتوایی که دسترسی به توصیهها یا راهنماییهای پزشکی مضر را تسهیل، ترویج یا ممکن میسازد، ممنوع است. | MEDICAL_INFO |
| خشونت و خونریزی | محتوایی که شامل توصیفات بیمورد از خشونت واقعگرایانه و/یا خونریزی باشد. | VIOLENCE_AND_GORE |
| فحش و ناسزا | محتوایی که حاوی الفاظ رکیک، توهینآمیز یا توهینآمیز باشد، ممنوع است. | OBSCENITY_AND_PROFANITY |
قطعه کدها
پایتون
با اجرای دستور pip install google-api-python-client کلاینت پایتون Google API را نصب کنید.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
برو
با اجرای دستور go get google.golang.org/api/checks/v1alpha ، کلاینت Checks API Go را نصب کنید.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
استراحت
نکته: این مثال از ابزار oauth2l CLI استفاده میکند.
به جای YOUR_GCP_PROJECT_ID ، شناسه پروژه Google Cloud خود را که به آن دسترسی به Guardrails API داده شده است، قرار دهید.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
پاسخ نمونه
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
موارد استفاده
API گاردریلز میتواند به روشهای مختلفی، بسته به نیازهای خاص و میزان ریسکپذیری شما، در برنامهی LLM شما ادغام شود. در اینجا چند نمونه از موارد استفادهی رایج آورده شده است:
بدون دخالت گاردریل - قطع درختان
در این سناریو، از API گاردریلز بدون هیچ تغییری در رفتار برنامه استفاده میشود. با این حال، نقضهای احتمالی سیاستها برای اهداف نظارت و حسابرسی ثبت میشوند. این اطلاعات میتواند برای شناسایی خطرات احتمالی ایمنی LLM نیز مورد استفاده قرار گیرد.
پایتون
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
برو
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
گاردریل بر اساس یک سیاست مسدود شده است
در این مثال، API گاردریلز ورودیهای ناامن کاربر و پاسخهای مدل را مسدود میکند. این API هر دو را در برابر سیاستهای ایمنی از پیش تعریفشده (مثلاً سخنان نفرتانگیز، محتوای خطرناک) بررسی میکند. این امر مانع از تولید خروجیهای بالقوه مضر توسط هوش مصنوعی شده و کاربران را از مواجهه با محتوای نامناسب محافظت میکند.
پایتون
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
برو
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
خروجی LLM را به Guardrails منتقل کنید
در مثالهای زیر، ما خروجی را از یک LLM به API مربوط به Guardrails منتقل میکنیم. این میتواند برای کاهش تأخیر درک شده توسط کاربر استفاده شود. این رویکرد میتواند به دلیل ناقص بودن زمینه، منجر به تشخیصهای مثبت کاذب شود، بنابراین مهم است که خروجی LLM زمینه کافی برای Guardrails داشته باشد تا قبل از فراخوانی API، ارزیابی دقیقی انجام دهد.
تماسهای گاردریل همزمان
پایتون
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
برو
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
فراخوانیهای ناهمزمان گاردریلها
پایتون
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
برو
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
سوالات متداول
اگر به محدودیت سهمیه API گاردریلز رسیده باشم، چه کاری باید انجام دهم؟
برای درخواست افزایش سهمیه، درخواست خود را به آدرس ایمیل checks-support@google.com ارسال کنید. اطلاعات زیر را در ایمیل خود ذکر کنید:
- شماره پروژه Google Cloud شما: این به ما کمک میکند تا حساب شما را به سرعت شناسایی کنیم.
- جزئیات مربوط به مورد استفاده شما: نحوه استفاده از API گاردریلز را توضیح دهید.
- میزان سهمیه مورد نظر: مشخص کنید که به چه میزان سهمیه اضافی نیاز دارید.