
La nueva API de Web Speech de JavaScript permite agregar fácilmente el reconocimiento de voz a tus páginas web. Esta API ofrece un gran control y flexibilidad sobre las capacidades de reconocimiento de voz en Chrome 25 y versiones posteriores. Este es un ejemplo en el que el texto reconocido aparece casi de inmediato mientras habla.
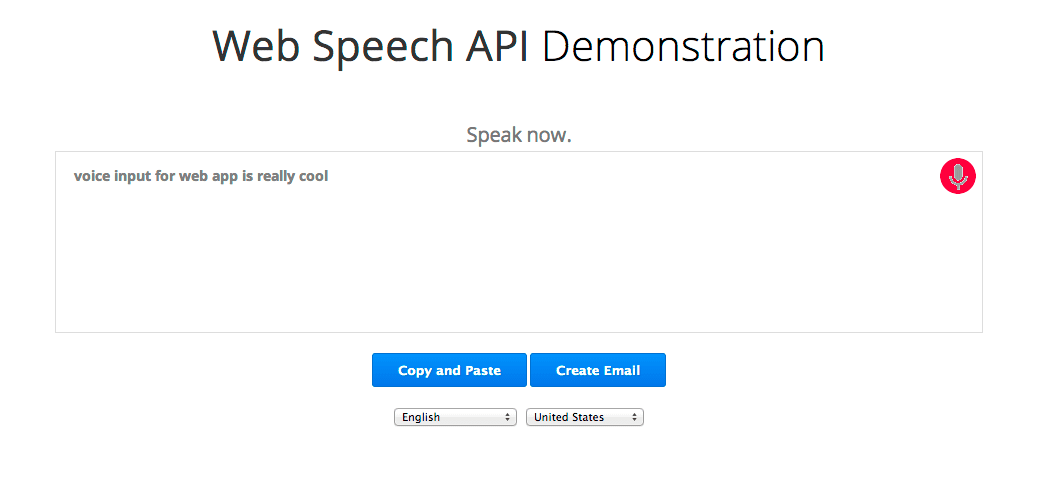
Veamos esto en detalle. Primero, verificamos si el navegador es compatible con la API de Web Speech. Para ello, verificamos si el objeto webkitSpeechRecognition existe. De lo contrario, sugerimos que el usuario actualice el navegador. (Debido a que la API aún es experimental, actualmente cuenta con un prefijo del proveedor). Por último, creamos el objeto webkitSpeechRecognition, que proporciona la interfaz de voz, y configuramos algunos de sus atributos y controladores de eventos.
if (!('webkitSpeechRecognition' in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
El valor predeterminado de continuous es falso, lo que significa que, cuando el usuario deje de hablar, finalizará el reconocimiento de voz. Este modo es ideal para texto simple, como campos de entrada cortos. En esta demostración, la configuramos como verdadera para que el reconocimiento continúe incluso si el usuario se detiene mientras habla.
El valor predeterminado para interimResults es falso, lo que significa que los únicos resultados que muestra el reconocedor son definitivos y no cambiarán. La demostración lo establece como verdadero para que obtenemos resultados provisionales y anticipados que pueden cambiar. Mire la demostración con atención. El texto gris es el texto provisional y que a veces cambia, mientras que el texto negro son respuestas del reconocedor que se marcan como finales y no cambiarán.
Para comenzar, el usuario hace clic en el botón del micrófono, que activa este código:
function startButton(event) {
...
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
Configuramos el idioma de voz del reconocedor de voz "lang" en el valor BCP-47 que el usuario seleccionó en la lista desplegable; por ejemplo, "en-US" para inglés (Estados Unidos). Si no la estableces, el valor predeterminado será el lang de la jerarquía y el elemento raíz del documento HTML. El reconocimiento de voz de Chrome admite numerosos idiomas (consulta la tabla "langs" en la fuente de la demostración), además de algunos idiomas que se leen de derecha a izquierda que no se incluyen en esta demostración, como he-IL y ar-EG.
Después de configurar el idioma, llamamos a recognition.start() para activar el reconocedor de voz. Una vez que comienza a capturar audio, llama al controlador de eventos onstart y, luego, para cada conjunto nuevo de resultados, llama al controlador de eventos onresult.
recognition.onresult = function(event) {
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
Este controlador concatena todos los resultados recibidos hasta el momento en dos cadenas: final_transcript y interim_transcript. Las cadenas resultantes pueden incluir "\n", como cuando el usuario dice "nuevo párrafo", por lo que usamos la función linebreak para convertirlas en etiquetas HTML <br> o <p>. Por último, establece estas cadenas como el internalHTML de sus elementos <span> correspondientes: final_span, que tiene estilo con texto negro, y interim_span, que tiene estilo con texto gris.
interim_transcript es una variable local y se vuelve a compilar por completo cada vez que se llama a este evento, ya que es posible que todos los resultados provisionales hayan cambiado desde el último evento onresult. Podríamos hacer lo mismo para final_transcript si iniciamos el bucle for en 0. Sin embargo, como el texto final nunca cambia, hicimos que el código sea un poco más eficiente haciendo que final_transcript sea global, de modo que este evento pueda iniciar el bucle for en event.resultIndex y solo agregar cualquier texto final nuevo.
Eso es todo. El resto del código está ahí solo para que todo se vea bien. Mantiene el estado, le muestra al usuario algunos mensajes informativos y cambia la imagen GIF en el botón del micrófono entre el micrófono estático, la imagen de barra de micrófono y la animación de micrófono con el punto rojo que parpadea.
Se muestra la imagen de barra de micrófono cuando se llama a recognition.start() y, luego, se reemplaza por animación de micrófono cuando se activa onstart. Generalmente, esto sucede tan rápido que la barra no es visible, pero la primera vez que se utiliza el reconocimiento de voz, Chrome debe solicitar permiso al usuario para usar el micrófono. En ese caso, onstart solo se activa si el usuario otorga permiso. Las páginas alojadas en HTTPS no necesitan solicitar permiso de forma reiterada, mientras que las páginas alojadas en HTTP sí lo hacen.
Por lo tanto, haz que tus páginas web cobren vida permitiéndoles escuchar a tus usuarios.
Nos encantaría recibir tus comentarios...
- Para comentarios sobre la especificación de la API de Web Speech de W3C: correo electrónico, archivo de correo, grupo de la comunidad
- Para comentarios sobre la implementación de esta especificación por parte de Chrome: correo electrónico, archivo de correo
Consulta el Informe de privacidad de Chrome para obtener información sobre cómo Google administra los datos de voz de esta API.