Wprowadzenie: przyczyny i łagodzenie opóźnień DNS
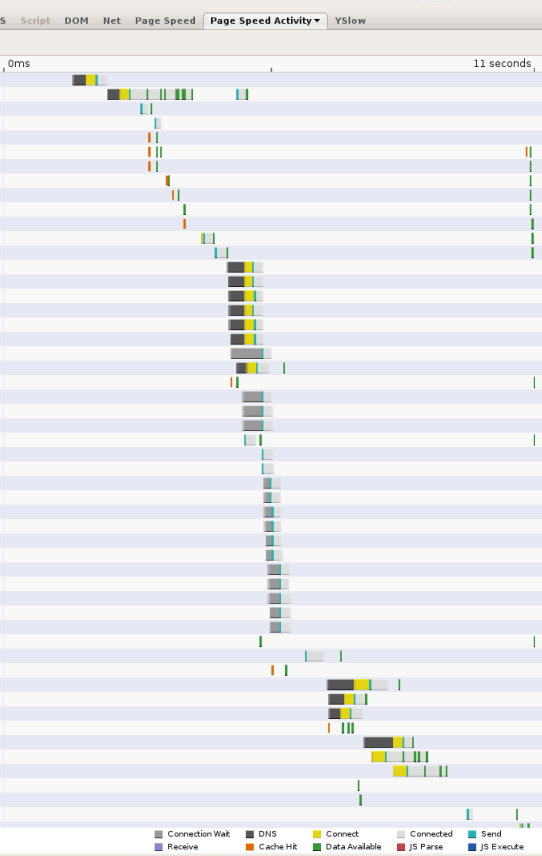
Gdy strony internetowe stają się coraz bardziej złożone i odwołują się do zasobów z wielu domen, wyszukiwania DNS mogą znacznie utrudniać przeglądanie. Za każdym razem, gdy klient chce przesłać zapytanie do resolvera DNS przez sieć, opóźnienie może być znaczne. Zależy to od odległości i liczby serwerów nazw, do których ten resolvera musi wysyłać swoje zapytania. Rzadko zdarza się to robić więcej niż 2, ale może się zdarzyć. Na przykład ten zrzut ekranu przedstawia czas podany przez narzędzie do pomiaru skuteczności stron internetowych Page Speed. Każdy słupek reprezentuje zasób, do którego odwołuje się strona, a czarne segmenty wskazują wyszukiwania DNS. Na tej stronie w ciągu pierwszych 11 sekund jej wczytywania jest 13 wyszukiwań. Chociaż kilka wyszukiwań odbywa się równolegle, zrzut ekranu pokazuje, że wymaganych jest 5 czasów wyszukiwania szeregowego, co odpowiada za kilka sekund z całkowitego 11-sekundowego czasu wczytywania strony.
Czas oczekiwania DNS składa się z 2 elementów:
- Czas oczekiwania między klientem (użytkownikiem) a serwerem rozpoznawania DNS. W większości przypadków wynika to z ograniczeń związanych z czasem błądzenia w obie strony w systemach sieciowych: odległości geograficznej między komputerami z klientem a serwerem, przeciążenia sieci, utraty pakietów i długich opóźnień w ponownym przesyłaniu (średnio 1 sekunda), przeciążonych serwerach, atakami typu DoS itp.
- Czas oczekiwania między serwerami nazw a innymi serwerami nazw.
To źródło opóźnień jest spowodowane głównie przez następujące czynniki:
- Braki w pamięci podręcznej. Jeśli odpowiedzi nie można udostępnić z pamięci podręcznej resolvera, ale wymaga rekurencyjnego wysyłania zapytań do innych serwerów nazw, dodatkowe opóźnienia w sieci są znaczne, zwłaszcza gdy serwery autorytatywne są odległe geograficznie.
- Za mało zasobów. Jeśli resolvery DNS są przeciążone, muszą umieścić w kolejce żądania i odpowiedzi dotyczące rozpoznawania nazw DNS, a potem mogą zacząć usuwać i ponownie przesyłać pakiety.
- szkodliwy ruch. Nawet wtedy, gdy usługa DNS ma nadmiarowe zasoby, ruch DoS może powodować nadmierne obciążenie serwerów. Ataki w stylu kaminskiego mogą obejmować zalanie resolverów z zapytaniami, które gwarantują ominięcie pamięci podręcznej i wymagają wychodzących żądań do rozwiązania problemu.
Naszym zdaniem współczynnik braku w pamięci podręcznej jest najpoważniejszą przyczyną opóźnienia DNS, co omówimy dokładniej poniżej.
Braki w pamięci podręcznej
Nawet jeśli resolver ma dużą ilość zasobów lokalnych, trudno jest uniknąć podstawowych opóźnień związanych z komunikacją ze zdalnymi serwerami nazw. Innymi słowy, zakładając, że resolver jest wystarczająco dobrze udostępniony, aby trafienia z pamięci podręcznej nie zajmowały czasu po stronie serwera, braki w pamięci podręcznej są bardzo kosztowne ze względu na czas oczekiwania. Aby rozwiązać problem, resolver musi skontaktować się z co najmniej jednym, ale często z kilkoma zewnętrznymi serwerami nazw. Podczas pracy robota indeksującego Googlebot zaobserwowaliśmy, że serwery nazw, które odpowiadają, zajmują średnio 130 ms. Jednak pełne 4–6% żądań po prostu przekracza limit czasu, ponieważ następuje utrata pakietów UDP i serwery są nieosiągalne. Jeśli uwzględnimy awarie, takie jak utrata pakietów, martwe serwery nazw, błędy konfiguracji DNS itp., rzeczywisty średni czas pełnego rozwiązania wynosi 300–400 ms. Jednak występują duże różnice i opóźnienie.
Choć odsetek niepowodzeń w pamięci podręcznej może się różnić w zależności od serwera DNS, braki w pamięci podręcznej są zasadniczo trudne do uniknięcia z tych powodów:
- Rozmiar i rozwój internetu W miarę rozwoju internetu, zarówno przez dodawanie nowych użytkowników, jak i nowych witryn, większość treści ma minimalne zainteresowanie. Chociaż kilka witryn (a co za tym idzie – nazwy DNS) jest bardzo popularnych, większość z nich może być interesująca jedynie niewielu użytkowników i jest rzadko otwierana. Większość żądań powoduje braki w pamięci podręcznej.
- Niskie wartości TTL. Trend w kierunku niższych wartości TTL DNS oznacza, że rozwiązania wymagają częstszego wyszukiwania.
- Izolacja pamięci podręcznej. Serwery DNS znajdują się zwykle za systemami równoważenia obciążenia, które losowo przypisują zapytania do różnych maszyn. Dzięki temu każdy serwer używa osobnej pamięci podręcznej, zamiast ponownie używać rozdzielczości z pamięci podręcznej z puli współdzielonej.
Łagodzenie
W publicznym serwerze DNS Google wdrożyliśmy kilka metod przyspieszenia czasu wyszukiwania DNS. Niektóre z nich są dość standardowe, a inne mają charakter eksperymentalny:
- Zapewnij odpowiednią obsługę serwerów, aby przetwarzać obciążenia związane z ruchem klientów, w tym ruchem złośliwym.
- Zapobieganie DoS i atakom wzmacniającym. Choć jest to głównie problem związany z bezpieczeństwem i w mniejszym stopniu wpływa na działanie zamkniętych resolverów, zapobieganie atakom DoS zwiększa też wydajność, ponieważ eliminuje dodatkowy ruch związany z serwerami DNS. Informacje o metodach, które stosujemy, aby zminimalizować ryzyko ataków, znajdziesz na stronie poświęconej korzyściom związanym z bezpieczeństwem.
- Równoważenie obciążenia na potrzeby współdzielonego pamięci podręcznej – pozwala poprawić zagregowaną częstotliwość trafień w pamięci podręcznej w klastrze obsługującym.
- Globalny zasięg w zależności od tego, czy wszyscy użytkownicy są w pobliżu.
Zapewnij odpowiednie udostępnianie klastrów
Mechanizmy rozpoznawania nazw DNS w pamięci podręcznej muszą wykonywać bardziej kosztowne operacje niż autorytatywne serwery nazw, ponieważ wiele odpowiedzi nie może być udostępnianych z pamięci. Zamiast tego wymagają komunikacji z innymi serwerami nazw i dlatego wymagają dużej ilości danych wejściowych i wyjściowych w sieci. Co więcej, mechanizmy rozpoznawania otwartego są bardzo narażone na próby zatrucia pamięci podręcznej, które zwiększają odsetek przypadków braku w pamięci podręcznej (takie ataki wysyłają konkretnie żądania fałszywych nazw, których nie można rozwiązać z pamięci podręcznej), oraz na ataki DoS, które zwiększają obciążenie związane z ruchem. Jeśli resolvery nie są odpowiednio udostępniane i nie nadążają za obciążeniem, może to mieć bardzo negatywny wpływ na wydajność. Pakiety są usuwane i trzeba je ponownie przesłać, żądania serwerów nazw są umieszczane w kolejce itd. Wszystkie te czynniki wpływają na opóźnienia.
Dlatego resolvery DNS muszą być udostępniane na potrzeby obsługi danych wejściowych i wyjściowych o dużej ilości danych. Obejmuje to również obsługę potencjalnych ataków DDoS, w przypadku których jedynym skutecznym rozwiązaniem jest nadmiarowe udostępnienie wielu maszyn. Jednocześnie ważne jest, aby podczas dodawania maszyn nie zmniejszać częstotliwości trafień w pamięci podręcznej. Wymaga to wdrożenia skutecznej zasady równoważenia obciążenia, którą omówimy poniżej.
Równoważenie obciążenia na potrzeby wspólnego buforowania
Skalowanie infrastruktury resolvera przez dodanie maszyn może wręcz przeciwdziałać i zmniejszyć częstotliwość trafień w pamięci podręcznej, jeśli równoważenie obciążenia nie jest wykonywane prawidłowo. W typowym wdrożeniu wiele maszyn znajduje się za systemem równoważenia obciążenia, który równomiernie rozdziela ruch między wszystkie maszyny, korzystając z prostego algorytmu, takiego jak algorytm karuzelowy. W efekcie każdy komputer ma własną, niezależną pamięć podręczną, dzięki czemu dane przechowywane w pamięci podręcznej są odizolowane od innych komputerów. Jeśli każde przychodzące zapytanie jest rozłożone na maszynę losową, w zależności od charakteru ruchu efektywny współczynnik niewykorzystanych w pamięci podręcznej może zostać proporcjonalnie zwiększony. Na przykład w przypadku nazw z długimi wartościami TTL, w przypadku których wielokrotnie są wysyłane zapytania, wskaźnik niewykorzystania pamięci podręcznej może zostać zwiększony o liczbę maszyn w klastrze. W przypadku nazw z bardzo krótkimi wartościami TTL, o rzadkich zapytaniach lub takich, które powodują niebuforowanie odpowiedzi (0 wartości TTL i błędów) na odsetek niepowodzeń w pamięci podręcznej nie wpływa dodawanie maszyn.
Aby zwiększyć współczynnik trafień dla nazw zapisanych w pamięci podręcznej, należy zadbać o równoważenie obciążenia serwerów, aby pamięć podręczna nie była fragmentowana. W publicznym DNS Google mamy 2 poziomy buforowania. W jednej puli maszyn, bardzo blisko użytkownika, znajduje się mała pamięć podręczna dla poszczególnych maszyn zawierająca najpopularniejsze nazwy. Jeśli nie można zrealizować zapytania z tej pamięci podręcznej, jest ono wysyłane do innej puli maszyn, które partycjonują pamięć podręczną według nazw. W przypadku tej pamięci podręcznej drugiego poziomu wszystkie zapytania o tę samą nazwę są wysyłane do tej samej maszyny, której nazwa jest albo nie jest przechowywana.
Dystrybuowanie klastrów obsługujących w celu zapewnienia szerokiego zasięgu geograficznego
W przypadku zamkniętych resolverów nie jest to problemem. W przypadku otwartych mechanizmów rozpoznawania nazw im serwery znajdują się bliżej użytkowników, tym mniejsze opóźnienie po stronie klienta. Poza tym wystarczający zasięg geograficzny może pośrednio skrócić całkowity czas oczekiwania, ponieważ serwery nazw zwykle zwracają wyniki zoptymalizowane pod kątem lokalizacji resolvera DNS. Oznacza to, że jeśli dostawca treści hostuje powielone witryny na całym świecie, jego serwery nazw zwracają adres IP znajdujący się najbliżej resolvera DNS.
Publiczny serwer DNS Google jest hostowany w centrach danych na całym świecie i używa routingu typu Anycast do kierowania użytkowników do najbliższego geograficznie centrum danych.
Dodatkowo Google Public DNS obsługuje podsieć klienta EDNS (ECS), rozszerzenie protokołu DNS służące do resolverów przekierowujących lokalizację klienta do serwerów nazw. Funkcja ta może zwracać odpowiedzi wrażliwe na lokalizację zoptymalizowane pod kątem rzeczywistego adresu IP klienta, a nie adresu IP resolvera. Szczegółowe informacje znajdziesz w odpowiedziach na najczęstsze pytania. Publiczny DNS Google automatycznie wykrywa serwery nazw, które obsługują podsieć klienta EDNS.