Princípios básicos de SEO em JavaScript
O JavaScript é uma parte importante da plataforma da Web porque conta com muitos recursos que a transformam em uma plataforma eficiente para aplicativos. Fazer com que os aplicativos da Web com tecnologia JavaScript possam ser detectados pela Pesquisa Google é importante para encontrar novos usuários e recuperar o engajamento dos existentes quando eles pesquisarem o conteúdo oferecido pelo seu aplicativo. Embora a Pesquisa Google execute JavaScript com uma versão contínua do Chromium, há algumas coisas que você pode otimizar.
Este guia descreve como a Pesquisa Google processa JavaScript e indica as práticas recomendadas para melhorar os apps da Web JavaScript para a Pesquisa Google.
Como o Google processa JavaScript
O Google processa apps da Web JavaScript em três fases principais:
- Rastreamento
- Renderização
- Indexação
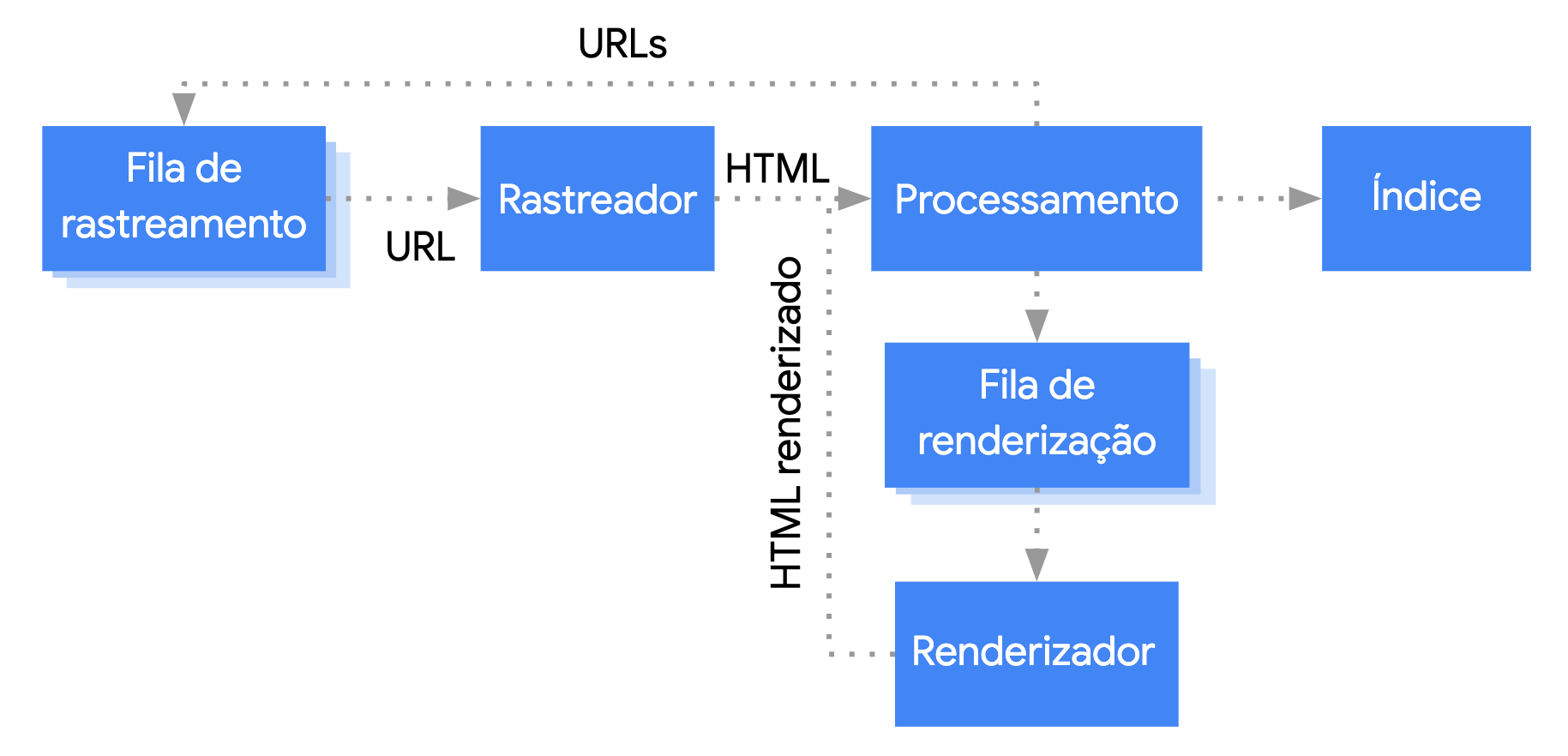
O Googlebot forma uma fila de páginas para rastreamento e renderização. Não fica imediatamente claro quando uma página está aguardando o rastreamento ou a renderização.
Quando o Google busca um URL da fila de rastreamento com uma solicitação HTTP, ele primeiro confere se você permitiu o rastreamento. O Googlebot lê o arquivo robots.txt. Quando ele marca o URL como não permitido, o Googlebot pula a solicitação HTTP desse URL e o ignora.
Depois o Google analisa a resposta de outros URLs no atributo href dos links HTML e os adiciona à fila de rastreamento. Para impedir que links sejam detectados, use o mecanismo nofollow.
Rastrear um URL e analisar a resposta HTML funciona bem para sites clássicos ou páginas renderizadas no servidor, em que o HTML na resposta HTTP inclui todo o conteúdo. Alguns sites JavaScript usam o modelo de shell do app, em que o HTML inicial não inclui o conteúdo em si. Nesses casos, o Google precisa executar JavaScript para acessar os recursos da página que ele gera.
O Googlebot forma uma fila com todas as páginas a serem renderizadas, a menos que um cabeçalho ou tag meta robots diga para não indexar a página. Ela pode ficar na fila por alguns segundos ou mais. Quando os recursos do Google permitem, uma versão headless do Chromium renderiza a página e executa JavaScript. O Google analisa novamente o HTML renderizado em busca de links e forma uma fila com os URLs encontrados para rastreamento. Ele também usa o HTML renderizado para indexar a página.
A renderização prévia ou no servidor ainda é uma ótima ideia, porque deixa os sites mais rápidos para usuários e rastreadores, e nem todos os bots executam JavaScript.
Descreva sua página com títulos e snippets exclusivos
Os elementos <title> descritivos e exclusivos e as metadescrições relevantes ajudam
os usuários a identificar rapidamente o melhor resultado para os próprios objetivos. Explicamos como fazer
bons elementos <title> e
metadescrições nas nossas diretrizes.
É possível usar o JavaScript para definir ou alterar a metadescrição e o elemento <title>.
A Pesquisa Google talvez mostre um link de título diferente com base na consulta do usuário.
Isso acontece quando essas strings têm pouca relevância para o conteúdo da página ou quando encontramos alternativas nela que correspondam melhor à consulta de pesquisa. Saiba mais sobre por que o título dos resultados da pesquisa talvez seja diferente do elemento <title> da página.
Escreva código compatível
Os navegadores contam com muitas APIs, e JavaScript é uma linguagem em rápida evolução. O Google tem algumas limitações de compatibilidade com APIs e recursos JavaScript. Para garantir que seu código seja compatível com o Google, siga nossas diretrizes para solução de problemas com JavaScript.
Recomendamos o uso de exibição diferencial e polyfills se você detectar a falta de uma API necessária do navegador. Como alguns recursos do navegador não são compatíveis com polyfill, consulte a documentação relacionada para ver possíveis limitações.
Use códigos de status HTTP significativos
O Googlebot usa códigos de status HTTP para descobrir se algo deu errado ao rastrear a página.
Para informar ao Googlebot que a página não pode ser rastreada nem indexada, use um código de status significativo, como
404 para páginas não encontradas ou 401
para aquelas protegidas por login. Você pode usar códigos de status HTTP para que o Google saiba que uma página foi movida para um novo URL e atualiza o índice.
Veja uma lista de códigos de status HTTP e como eles afetam a Pesquisa Google.
Evite erros soft 404 em apps de página única
Em apps de página única renderizados no lado do cliente, o roteamento geralmente também é implementado nesse mesmo lado.
Nesse caso, pode ser impossível ou impraticável usar códigos de status HTTP significativos.
Para evitar erros soft 404 ao
usar a renderização e o roteamento no lado do cliente, siga uma destas estratégias:
- Use um redirecionamento JavaScript para um URL a que o servidor responda com um código de status HTTP
404, como/not-found. - Use JavaScript para adicionar um
<meta name="robots" content="noindex">às páginas de erro.
Veja um exemplo de código para a abordagem de redirecionamento:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/not-found'; // redirect to 404 page on the server.
}
})
Veja um exemplo de código para a abordagem da tag noindex:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
Use a API History em vez de fragmentos
O Google só vai poder rastrear seu link se ele for um elemento HTML <a> com um atributo href.
Em apps de página única com roteamento no lado do cliente, use a API History para implementar o roteamento entre diferentes visualizações do seu app da Web. Para garantir que o Googlebot possa analisar e extrair os URLs, evite usar fragmentos para carregar conteúdos diferentes da página. O exemplo a seguir é uma prática não recomendada porque o Googlebot não consegue resolver os URLs de maneira confiável:
<nav>
<ul>
<li><a href="#/products">Our products</a></li>
<li><a href="#/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p>
</div>
<script>
window.addEventListener('hashchange', function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById('placeholder').innerHTML = load(pageToLoad);
});
</script>
Em vez disso, implemente a API History para conferir se os URLs são acessíveis ao Googlebot:
<nav>
<ul>
<li><a href="/products">Our products</a></li>
<li><a href="/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute('href');
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById('placeholder').innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage));
</script>
Injete a tag de link rel="canonical" corretamente
Embora não seja recomendado, é possível injetar uma tag de link rel="canonical" com JavaScript.
A Pesquisa Google vai selecionar o URL canônico injetado ao renderizar a página.
Veja um exemplo de como injetar uma tag de link rel="canonical" com JavaScript:
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
Use as tags meta robots com cuidado
Você pode impedir que o Google indexe uma página ou siga links usando a tag meta robots.
Por exemplo, adicionar a seguinte tag meta à parte de cima da página impede que o Google a indexe:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Você pode usar o JavaScript para adicionar uma tag meta robots a uma página ou mudar o conteúdo dela. O código de exemplo a seguir mostra como mudar a tag meta robots com JavaScript para impedir a indexação da página atual caso uma chamada de API não retorne o conteúdo.
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
Ao encontrar noindex na tag meta robots antes de executar JavaScript, o Google não vai renderizar nem indexar a página.
Use armazenamento em cache de longa duração
O Googlebot armazena muitos dados em cache para reduzir
as solicitações de rede e o uso de recursos. O WRS pode ignorar cabeçalhos de armazenamento em cache. Talvez isso leve o WRS a usar
recursos desatualizados de JavaScript ou CSS. A técnica de impressão digital de conteúdo evita esse problema
ao criar uma referência à parte do nome do arquivo relativa ao conteúdo, como main.2bb85551.js.
A impressão digital depende do conteúdo do documento. Por isso, cada atualização gera um
nome de arquivo diferente. Consulte o guia web.dev sobre estratégias de armazenamento em cache de longa duração para saber mais.
Use dados estruturados
Ao utilizar dados estruturados nas suas páginas, use o JavaScript para gerar o JSON-LD exigido e injetá-lo na página. Teste sua implementação para evitar problemas.
Siga as práticas recomendadas para componentes da Web
O Google é compatível com componentes da Web. Quando o Google renderiza uma página, ele nivela o conteúdo shadow DOM e light DOM. Isso significa que o Google só pode visualizar conteúdo visível no HTML renderizado. Para garantir que o Google ainda possa ver seu conteúdo depois que ele for renderizado, use o Teste de pesquisa aprimorada ou a Ferramenta de inspeção de URL e confira o HTML renderizado.
Se o conteúdo não estiver visível no HTML renderizado, ele não vai ser indexado pelo Google.
O exemplo a seguir cria um componente da Web que exibe o conteúdo light DOM dentro do shadow DOM. Uma maneira de garantir que o conteúdo shadow DOM e o light DOM sejam exibidos no HTML renderizado é usar um elemento Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Após a renderização, o Google vai poder indexar o seguinte conteúdo:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Corrija imagens e conteúdo de carregamento lento
As imagens podem demandar muita largura de banda e desempenho. Uma boa estratégia é usar carregamento lento para carregar imagens somente quando o usuário estiver prestes a vê-las. Para implementar o recurso de modo otimizado para a pesquisa, siga nossas diretrizes para o carregamento lento.
Design para acessibilidade
Crie páginas para os usuários, não somente para os mecanismos de pesquisa. Quando estiver projetando o site, pense nas necessidades dos usuários, inclusive daqueles que talvez não usem um navegador compatível com JavaScript (por exemplo, pessoas que usam leitores de tela ou dispositivos móveis menos avançados). Para testar a acessibilidade, abra o site em um navegador somente de texto (como o Lynx) ou com JavaScript desativado. Visualizar o site como somente texto também pode ajudar a identificar outros conteúdos que talvez não sejam vistos com facilidade pelo Google, como texto incorporado em imagens.