Données structurées des ensembles de données (Dataset, DataCatalog, DataDownload)
Les ensembles de données sont plus faciles à identifier lorsque vous fournissez des informations complémentaires telles que leur nom, leur description, leur créateur et leurs formats de distribution en tant que données structurées. L'approche de Google en matière de découverte des ensembles de données repose sur l'utilisation de schema.org et d'autres normes de métadonnées qui peuvent être ajoutées aux pages décrivant des ensembles de données. Le but de ce balisage est d'améliorer la découverte de ces derniers dans des domaines divers tels que les sciences de la vie, les sciences sociales, le machine learning, les données civiques et gouvernementales, et plus encore. Au besoin, utilisez l'outil de recherche d'ensembles de données.
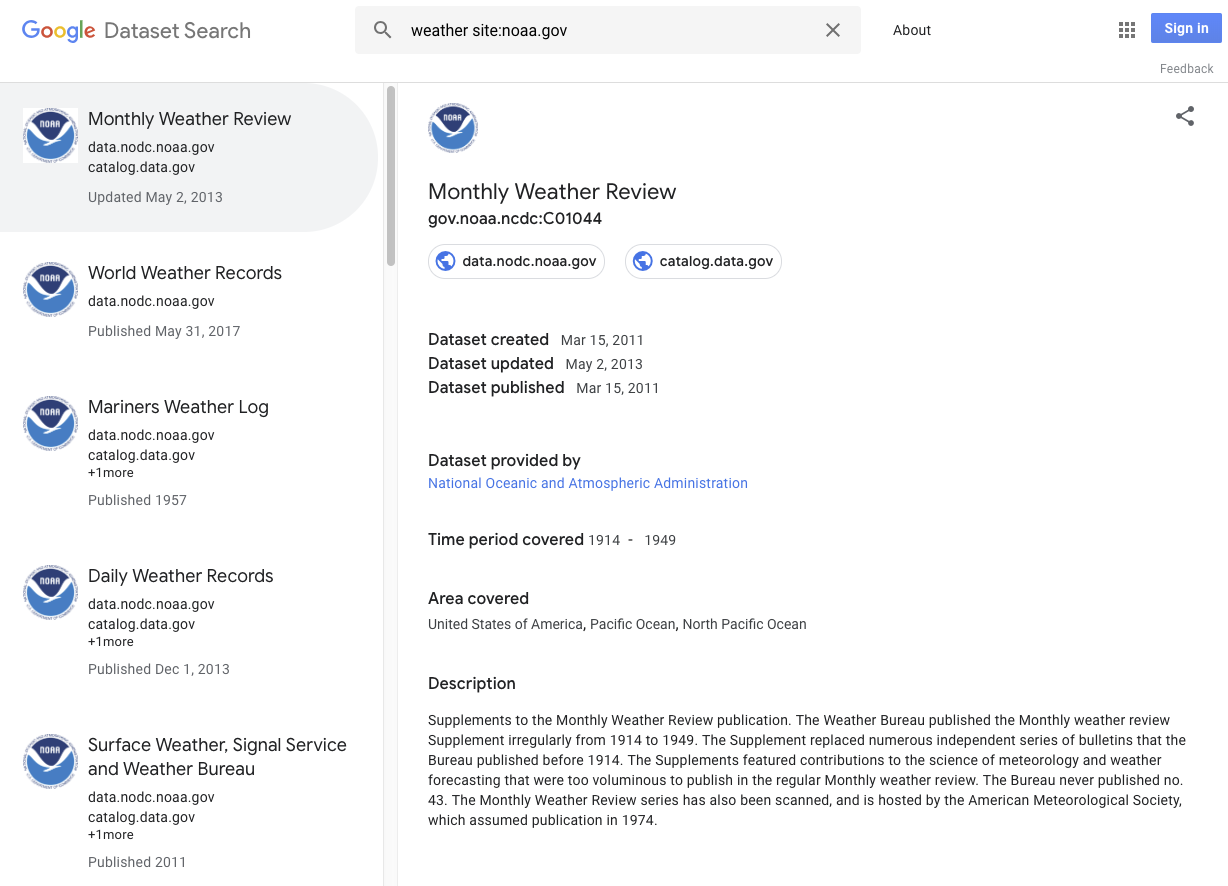
Voici quelques exemples d'ensembles de données :
- Tableau ou fichier CSV contenant des données
- Collection organisée de tableaux
- Fichier de données dans un format propriétaire
- Collection de fichiers qui constituent un ensemble de données lorsqu'ils sont réunis
- Objet structuré contenant des données dans un autre format que vous souhaitez charger dans un outil de traitement spécial
- Données de capture d'images
- Fichiers relatifs au machine learning, tels que des paramètres d'entraînement ou des définitions de la structure du réseau de neurones
Comment ajouter des données structurées
Ces données structurées représentent un format normalisé permettant de fournir des informations sur une page et de classer son contenu. En savoir plus sur le fonctionnement des données structurées
Voici, dans les grandes lignes, comment créer, tester et publier des données structurées. Pour consulter un guide détaillé sur l'ajout de données structurées à une page Web, accédez à cet atelier de programmation.
- Ajoutez les propriétés obligatoires. En fonction du format que vous utilisez, découvrez où insérer des données structurées sur la page.
- Suivez les consignes.
- Validez votre code à l'aide de l'outil de test des résultats enrichis et corrigez les erreurs critiques, le cas échéant. Envisagez également de résoudre les problèmes non critiques que l'outil a pu signaler, car cela peut contribuer à améliorer la qualité de vos données structurées. Toutefois, ce n'est pas nécessaire pour pouvoir bénéficier des résultats enrichis.
- Déployez quelques pages où figurent vos données structurées et utilisez l'outil d'inspection d'URL pour découvrir comment Google voit la page. Assurez-vous que Google peut accéder à votre page et qu'elle n'est pas bloquée par un fichier robots.txt, la balise
noindexni par des identifiants de connexion. Si tout semble être en ordre, vous pouvez demander à Google d'explorer de nouveau vos URL. - Pour informer Google des modifications futures de vos pages, nous vous recommandons de nous envoyer un sitemap. Vous pouvez automatiser cette opération à l'aide de l'API Sitemap de la Search Console.
Supprimer un ensemble de données des résultats de recherche d'ensembles de données
Si vous ne souhaitez pas qu'un ensemble de données s'affiche dans les résultats de recherche d'ensembles de données, utilisez la balise meta robots afin de contrôler le mode d'indexation de votre ensemble de données. Notez qu'il peut s'écouler un certain temps (plusieurs jours ou semaines, selon la planification de l'exploration) avant que les modifications soient prises en compte dans la recherche d'ensembles de données.
Notre approche en matière de découverte des ensembles de données
Pour interpréter les données structurées liées aux ensembles de données dans les pages Web, nous utilisons soit le balisage Dataset de schema.org, soit des structures équivalentes représentées au format DCAT (Data Catalog Vocabulary) de W3C. Nous envisageons également de proposer un programme expérimental pour les données structurées basées sur W3C CSVW, et nous prévoyons d'évoluer et d'adapter notre approche à mesure que des bonnes pratiques émergent en matière de description des ensembles de données. Pour plus d'informations sur notre approche en matière de découverte des ensembles de données, consultez la section Faciliter la découverte des ensembles de données.
Exemples
Voici un exemple d'ensembles de données utilisant le format JSON-LD et la syntaxe schema.org (recommandée) dans l'outil de test des résultats enrichis. Le même vocabulaire schema.org peut également être utilisé dans les syntaxes RDFa 1.1 ou de microdonnées. Vous pouvez également utiliser le vocabulaire DCAT du W3C pour décrire les métadonnées. L'exemple suivant repose sur la description d'un ensemble de données réel.
Voici un exemple d'ensemble de données au format JSON-LD :
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>
Voici un exemple d'ensemble de données au format RDFa avec le vocabulaire DCAT :
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>
Consignes
Les sites doivent respecter les consignes relatives aux données structurées. Nous vous recommandons également de vous reporter aux bonnes pratiques ci-dessous en matière de sitemaps et de source et provenance.
Bonnes pratiques en matière de sitemaps
Créez un fichier sitemap pour aider Google à identifier vos URL. L'utilisation de ce fichier et du balisage sameAs permet de documenter la manière dont les descriptions des ensembles de données sont publiées sur votre site.
Si vous disposez d'un dépôt d'ensembles de données, vous utilisez probablement au moins deux types de pages : des pages canoniques ("pages de destination") pour chaque ensemble de données et des pages répertoriant plusieurs ensembles de données (résultats de recherche ou sous-groupe d'ensembles de données, par exemple). Nous vous conseillons d'ajouter les données structurées liées aux ensembles de données aux pages canoniques. Utilisez la propriété sameAs pour renvoyer vers la page canonique si vous ajoutez des données structurées à plusieurs copies d'un ensemble de données, telles que des fiches dans les pages de résultats de recherche.
Bonnes pratiques en matière de source et de provenance
Il est courant que les ensembles de données ouverts soient republiés, agrégés et basés sur d'autres ensembles de données. Vous trouverez ici une première ébauche de l'approche que nous adoptons pour représenter les cas dans lesquels un ensemble de données est une copie d'un autre, ou une reprise modifiée.
- Utilisez la propriété
sameAspour indiquer les URL les plus canoniques par rapport à l'original lorsque l'ensemble de données ou la description est une simple republication de documents publiés ailleurs. La valeursameAsdoit indiquer sans ambiguïté l'identité de l'ensemble de données. Autrement dit, n'utilisez pas la même valeursameAspour deux ensembles de données différents. - Utilisez la propriété
isBasedOnlorsque l'ensemble de données republié (y compris ses métadonnées) a été modifié de manière significative. - Lorsqu'un ensemble de données repose sur plusieurs originaux ou regroupe plusieurs originaux, utilisez la propriété
isBasedOn. - Optez pour la propriété
identifierafin d'associer tout identifiant d'objet numérique (DOI) ou identifiant compact pertinent. Si l'ensemble de données comporte plusieurs identifiants, utilisez plusieurs fois la propriétéidentifier. Si vous employez le format JSON-LD, ceci est représenté par la syntaxe de liste JSON.
Nous espérons peaufiner nos recommandations en fonction des commentaires que vous nous ferez parvenir, en particulier en ce qui concerne la description de la provenance, la gestion des versions et les dates associées à la publication des séries temporelles. Rejoignez les groupes de discussion de la communauté.
Recommandations en matière de propriétés textuelles
Nous vous recommandons de limiter toutes les propriétés textuelles à 5 000 caractères maximum. Google Recherche d'ensembles de données tient uniquement compte des 5 000 premiers caractères d'une propriété textuelle. Les noms et les titres ne comportent généralement que quelques mots ou une courte phrase.
Erreurs et avertissements connus
Vous pouvez rencontrer des erreurs ou des avertissements dans le cadre du test des résultats enrichis de Google, ainsi que dans d'autres systèmes de validation. Les systèmes de validation peuvent suggérer que les entreprises incluent des coordonnées, y compris une valeur contactType. Parmi les valeurs utiles figurent customer service, emergency, journalist, newsroom et public engagement.
Vous pouvez également ignorer les erreurs indiquant que csvw:Table est une valeur inattendue pour la propriété mainEntity.
Définitions des types de données structurées
Vous devez inclure les propriétés obligatoires pour que votre contenu puisse être affiché sous forme de résultat enrichi. Vous pouvez également inclure les propriétés recommandées pour ajouter d'autres informations à votre contenu et ainsi offrir une meilleure expérience utilisateur.
Vous pouvez utiliser l'outil de test des résultats enrichis pour valider le balisage.
L'accent est mis sur la description des informations relatives à un ensemble de données (ses métadonnées) et sur la représentation de son contenu. Par exemple, les métadonnées de l'ensemble de données indiquent en quoi consiste ce dernier, les variables qu'il mesure, mais aussi son auteur, etc. En revanche, elles ne contiennent pas certaines informations, comme les valeurs spécifiques des variables.
Dataset
La définition complète de Dataset est disponible sur schema.org/Dataset.
Vous pouvez décrire des informations supplémentaires sur la publication de l'ensemble de données, telles que la licence, la date de publication, son DOI ou une propriété sameAs renvoyant vers une version canonique de l'ensemble de données dans un autre dépôt. Ajoutez les propriétés identifier, license et sameAs pour les ensembles de données qui fournissent des informations sur la provenance et la licence.
Les propriétés prises en charge par Google sont les suivantes :
| Propriétés obligatoires | |
|---|---|
description
|
Text
Court résumé décrivant un ensemble de données. Consignes
|
name
|
Text
Nom descriptif d'un ensemble de données. Par exemple, "Épaisseur de neige dans l'hémisphère nord". Consignes
Approche conseillée : Approche déconseillée : |
| Propriétés recommandées | |
|---|---|
alternateName
|
Text
Autres noms utilisés pour faire référence à cet ensemble de données, tels que des alias ou des abréviations. Exemple (au format JSON-LD) : "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person ou
Organization
Créateur ou auteur de cet ensemble de données. Pour identifier des personnes de manière unique, utilisez l'ID ORCID comme valeur de la propriété
"creator": [
{
"@type": "Person",
"sameAs": "https://orcid.org/0000-0000-0000-0000",
"givenName": "Jane",
"familyName": "Foo",
"name": "Jane Foo"
},
{
"@type": "Person",
"sameAs": "https://orcid.org/0000-0000-0000-0001",
"givenName": "Jo",
"familyName": "Bar",
"name": "Jo Bar"
},
{
"@type": "Organization",
"sameAs": "https://ror.org/xxxxxxxxx",
"name": "Fictitious Research Consortium"
}
]
|
citation
|
Text ou CreativeWork
Identifie les articles universitaires recommandés par le fournisseur de données en plus de l'ensemble de données lui-même. Fournissez la citation pour l'ensemble de données lui-même avec d'autres propriétés, comme "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Consignes supplémentaires
|
funder
|
Person ou
Organization
Personne ou organisation qui fournit une assistance financière pour cet ensemble de données. Pour identifier des personnes de manière unique, utilisez l'ID ORCID comme valeur de la propriété
"funder": [
{
"@type": "Person",
"sameAs": "https://orcid.org/0000-0000-0000-0002",
"givenName": "Jane",
"familyName": "Funder",
"name": "Jane Funder"
},
{
"@type": "Organization",
"sameAs": "https://ror.org/yyyyyyyyy",
"name": "Fictitious Funding Organization"
}
]
|
hasPart ou isPartOf
|
URL ou
Dataset
Si l'ensemble de données est une collection d'ensembles de données plus petits, utilisez la propriété
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license": "https://creativecommons.org/publicdomain/zero/1.0/",
"creator": {
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license": "https://creativecommons.org/publicdomain/zero/1.0/",
"creator": {
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
]
"isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text ou PropertyValue
Identifiant, tel qu'un DOI ou un identifiant compact. Si l'ensemble de données comporte plusieurs identifiants, utilisez plusieurs fois la propriété |
isAccessibleForFree
|
Boolean
Indique si l'ensemble de données est accessible sans payer. |
keywords
|
Text
Mots clés résumant l'ensemble de données. |
license
|
URL ou CreativeWorkLicence sous laquelle l'ensemble de données est distribué. Exemple : "license" : "https://creativecommons.org/publicdomain/zero/1.0/"
"license" : {
"@type": "CreativeWork",
"name": "Custom license",
"url": "https://example.com/custom_license"
}
Consignes supplémentaires
|
measurementTechnique
|
Text ou URL
Technique, technologie ou méthodologie utilisée dans un ensemble de données, qui peut correspondre aux variables décrites dans |
sameAs
|
URL
URL d'une page Web de référence qui indique clairement l'identité de l'ensemble de données. |
spatialCoverage |
Text ou Place
Vous pouvez fournir un seul point décrivant l'aspect spatial de l'ensemble de données. Incluez cette propriété uniquement si l'ensemble de données présente une dimension spatiale (par exemple, un seul point où toutes les mesures ont été collectées ou les coordonnées du cadre de délimitation d'une zone). Points
"spatialCoverage:" {
"@type": "Place",
"geo": {
"@type": "GeoCoordinates",
"latitude": 39.3280,
"longitude": 120.1633
}
}
Formes Utilisez
"spatialCoverage:" {
"@type": "Place",
"geo": {
"@type": "GeoShape",
"box": "39.3280 120.1633 40.445 123.7878"
}
}
Les points dans les propriétés Lieux désignés "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Les données de l'ensemble de données couvrent un intervalle de temps spécifique. Incluez cette propriété uniquement si l'ensemble de données présente une dimension temporelle. Schema.org utilise la norme ISO 8601 pour décrire les intervalles de temps et les points temporels. Vous pouvez décrire les dates différemment en fonction de l'intervalle de l'ensemble de données. Indiquez les intervalles ouverts avec deux décimales ( Date unique "temporalCoverage" : "2008" Période "temporalCoverage" : "1950-01-01/2013-12-18" Période ouverte "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text ou PropertyValue
Variable que cet ensemble de données mesure (par exemple, la température ou la pression). |
version
|
Text ou Number
Numéro de version de l'ensemble de données. |
url
|
URL
Emplacement d'une page décrivant l'ensemble de données. |
DataCatalog
La définition complète de DataCatalog est disponible sur schema.org/DataCatalog.
Les ensembles de données sont souvent publiés dans des référentiels contenant de nombreux autres ensembles de données. Le même ensemble de données peut être inclus dans plusieurs référentiels. Vous pouvez faire référence à un catalogue de données auquel cet ensemble de données appartient en le référençant directement à l'aide des propriétés suivantes :
| Propriétés recommandées | |
|---|---|
includedInDataCatalog
|
DataCatalog
Catalogue auquel appartient l'ensemble de données.
|
DataDownload
La définition complète de DataDownload est disponible sur schema.org/DataDownload. Outre les propriétés de l'ensemble de données, ajoutez les propriétés suivantes pour les ensembles de données offrant des options de téléchargement.
La propriété distribution décrit comment récupérer l'ensemble de données proprement dit, car l'URL renvoie souvent vers la page de destination qui le décrit. La propriété distribution précise où obtenir les données et dans quel format. Cette propriété peut contenir plusieurs valeurs (par exemple, une version CSV peut être disponible sous une URL, et une version Excel sous une autre).
| Propriétés obligatoires | |
|---|---|
distribution.contentUrl
|
URL
Lien de téléchargement. |
| Propriétés recommandées | |
|---|---|
distribution
|
DataDownload
Description de l'emplacement de téléchargement de l'ensemble de données et du format de fichier à télécharger.
|
distribution.encodingFormat
|
Text ou URL
Format de fichier de la distribution.
|
Ensembles de données tabulaires
Un ensemble de données tabulaire se caractérise par une grille de lignes et de colonnes. Avec les pages incorporant des ensembles de données tabulaires, vous pouvez également créer un balisage plus explicite, en vous appuyant sur l'approche de base. À ce stade, nous interprétons une variante de CSVW ("CSV on the Web", voir W3C), fournie parallèlement au contenu tabulaire destiné à l'utilisateur sur la page HTML.
Voici un exemple présentant un petit tableau codé au format CSVW JSON-LD. Le test des résultats enrichis comporte des erreurs connues.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2016",
"csvw:primaryKey": "2016"
},
{
"csvw:value": "2015",
"csvw:primaryKey": "2015"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2016"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2015"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2016"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2015"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2016"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2015"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2016"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2015"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>
Suivre les résultats enrichis avec la Search Console
La Search Console est un outil qui vous permet de suivre les performances de vos pages dans la recherche Google. Il n'est pas nécessaire de vous inscrire à la Search Console pour figurer dans les résultats de recherche Google. Cependant, en vous inscrivant, vous comprendrez mieux la façon dont Google interprète votre site et serez plus à même de l'améliorer. Nous vous recommandons de consulter la Search Console dans les cas suivants :
- Après avoir déployé des données structurées pour la première fois
- Après avoir publié de nouveaux modèles ou après avoir mis à jour votre code
- Lors des analyses régulières du trafic
Après avoir déployé des données structurées pour la première fois
Une fois que Google a indexé vos pages, recherchez les problèmes à l'aide du rapport sur l'état des résultats enrichis. Idéalement, il y aura une augmentation du nombre d'articles valides et pas d'augmentation du nombre d'articles non valides. Si vous détectez des problèmes au niveau des données structurées :
- Corrigez les éléments non valides.
- Inspectez une URL active pour vérifier si le problème persiste.
- Demandez la validation à l'aide du rapport d'état.
Après avoir publié de nouveaux modèles ou après avoir mis à jour votre code
Lorsque vous apportez des modifications importantes à votre site Web, surveillez l'augmentation des éléments non valides dans les données structurées.- Si vous constatez une augmentation du nombre d'éléments non valides, vous avez peut-être déployé un nouveau modèle qui ne fonctionne pas, ou votre site interagit différemment et de façon incorrecte avec le modèle déjà disponible.
- Si vous constatez une diminution du nombre d'éléments valides (sans augmentation du nombre d'éléments non valides), vous n'intégrez peut-être plus de données structurées dans vos pages. Utilisez l'outil d'inspection d'URL pour identifier la cause du problème.
Lors des analyses régulières du trafic
Analysez votre trafic de recherche Google à l'aide du rapport sur les performances. Les données indiquent la fréquence à laquelle votre page s'affiche en tant que résultat enrichi dans la recherche Google, ainsi que la fréquence à laquelle les internautes cliquent dessus et la position moyenne à laquelle vous apparaissez dans les résultats de recherche. Vous pouvez également extraire automatiquement ces résultats avec l'API Search Console.Dépannage
Si vous ne parvenez pas à mettre en œuvre ou à déboguer des données structurées, voici quelques ressources susceptibles de vous aider.
- Si vous utilisez un système de gestion de contenu (CMS) ou si une autre personne s'occupe de votre site, demandez à la personne en charge de vous aider. Veillez à lui transmettre tous les messages de la Search Console qui détaillent le problème.
- Google ne garantit pas que les fonctionnalités basées sur les données structurées apparaîtront dans les résultats de recherche. Pour consulter la liste des raisons courantes pour lesquelles Google n'affiche pas toujours votre contenu dans un résultat enrichi, reportez-vous aux consignes générales relatives aux données structurées.
- Vos données structurées comportent peut-être une erreur. Consultez la liste des erreurs de données structurées.
- Si vous avez reçu une action manuelle de données structurées concernant votre page, ces données seront ignorées (mais la page concernée apparaîtra peut-être toujours dans les résultats de recherche Google). Pour résoudre les problèmes de données structurées, utilisez le rapport sur les actions manuelles.
- Consultez à nouveau les consignes pour déterminer si votre contenu est bien conforme. Le problème peut être dû à une page contenant du spam ou à l'utilisation de balises qui en contiennent. Toutefois, il est possible qu'il ne s'agisse pas d'un problème de syntaxe et que le test des résultats enrichis ne puisse pas identifier le problème.
- Découvrez comment résoudre les problèmes liés aux résultats enrichis manquants ou à une baisse du nombre total de résultats enrichis.
- Prévoyez un certain temps avant que la réexploration et la réindexation soient effectuées. Gardez à l'esprit qu'il faut souvent compter plusieurs jours après la publication d'une page pour que Google puisse la trouver et l'explorer. Pour toute question d'ordre général sur l'exploration et l'indexation, consultez les FAQ sur l'exploration et l'indexation dans la recherche Google.
- Posez une question sur le forum Google Search Central.
Un ensemble de données spécifique n'apparaît pas dans les résultats de recherche d'ensembles de données
error Cause du problème : soit votre site n'inclut pas dans la page de données structurées qui décrivent les ensembles de données, soit la page n'a pas encore été explorée.
done Résolution du problème
- Copiez le lien de la page qui devrait s'afficher dans les résultats de recherche d'ensembles de données, puis ajoutez-le dans l'outil de test des résultats enrichis. Si le message "Cette page n'est pas éligible aux résultats enrichis connus par ce test" ou "Tous les balisages ne sont pas éligibles aux résultats enrichis" apparaît, cela signifie qu'aucun balisage d'ensemble de données n'est disponible sur la page ou que le balisage est incorrect. Pour résoudre le problème, consultez la section Comment ajouter des données structurées.
- Si la page est balisée, elle n'a peut-être pas encore été explorée. Vous pouvez vérifier l'état de l'exploration dans la Search Console.
Le logo de l'entreprise est manquant ou ne s'affiche pas correctement dans les résultats
error Cause du problème : soit vous n'avez pas appliqué le balisage schema.org pour les logos d'entreprise, soit vous n'avez pas fourni les informations appropriées sur votre établissement à Google.
done Résolution du problème
- Ajoutez des données structurées à votre page.
- Fournissez des informations sur votre entreprise à Google.