W ofercie raportowania atrybucji wprowadziliśmy szereg zmian, które mają związek z opiniami społeczności – od zmian w mechanizmie interfejsu API po nowe funkcje.
Historia zmian
- 7 lutego 2022 roku: dodano sekcję dotyczącą przekierowania aktywatora nagłówka.
- 27 stycznia 2022 r.: pierwsza publikacja artykułu.
Dla kogo jest ten post?
Ten post jest dla Ciebie:
- jeśli znasz już interfejs API – na przykład obserwujesz lub uczestniczysz w dyskusjach na temat repozytorium WICG i chcesz zrozumieć zbiór zmian wprowadzonych w ofercie pakietowej w styczniu 2022 r.
- Jeśli używasz interfejsu Attribution Reporting API w wersji demonstracyjnej lub w eksperymencie w wersji produkcyjnej.
Jeśli dopiero zaczynasz korzystać z tego interfejsu API lub jeszcze z nim nie testujesz, przejdź od razu do wprowadzenia do interfejsu API.
Migracja do przodu
Po wprowadzeniu tych zmian w Chrome: jeśli korzystasz z raportów na poziomie zdarzenia pochodzących z interfejsu Attribution Reporting API w wersji demonstracyjnej lub w ramach eksperymentu w środowisku produkcyjnym (test origin), musisz edytować kod, aby interfejs API nadal działał. Możesz też skorzystać z nowych funkcji.
W tym artykule znajdziesz też informacje o zmianach w raportach zbiorczych. Jeśli jednak wprowadzisz te zmiany, nie będą one wymagały żadnych działań ani migracji, ponieważ w tej chwili nie ma jeszcze implementacji w przeglądarce umożliwiającej gromadzenie danych w raportach zbiorczych.
Zmiany nazw
Raporty podsumowujące i raporty zbiorcze
Raporty zbiorcze nazywamy teraz raportami podsumowującymi.
Raporty podsumowujące to ostateczne wyniki zbiorcze wielu raportów zbiorczych, które wcześniej były nazywane danymi opublikowanymi lub materiałami na histogramie.
Zmiany mechanizmu interfejsów API
Rejestracja źródła na podstawie nagłówka (raporty na poziomie zdarzenia)
Co się zmienia i dlaczego?
Gdy użytkownik wyświetli lub kliknie reklamę, przeglądarka – lokalnie na urządzeniu użytkownika – rejestruje to zdarzenie razem z parametrami specyficznymi dla raportowania atrybucji (np. parametry attributionsourceeventid, attributiondestination, attributionexpiry i inne). Wartości tych parametrów ustawia Adtech.
Sposób konfigurowania tych parametrów ulegnie zmianie.
W poprzedniej ofercie parametry musiały być umieszczone po stronie klienta: w tagach kotwicy jako atrybuty HTML lub jako argumenty wywołania opartego na języku JS. Parametry musiały być znane w momencie kliknięcia lub wyświetlenia.
W nowej ofercie pakietowej wartość tych parametrów jest definiowana na serwerze AdTech.
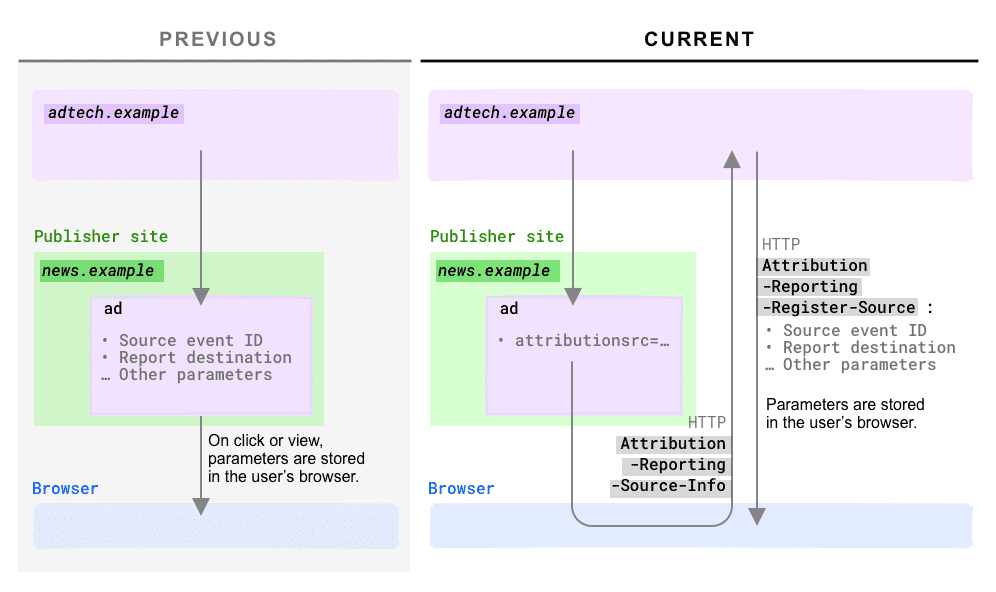
Ma to wiele zalet, zwłaszcza jeśli chodzi o bezpieczeństwo. Mechanizm nagłówka zapewnia źródło raportowania (zwykle jest to AdTech) nad tym, czy źródło atrybucji jest zarejestrowane w jego zakresie. Częściowo eliminuje to obawy o oszustwa, ponieważ dzięki tej zmianie prawdziwa przeglądarka nigdy nie zarejestruje źródła bez zgody źródła raportowania.
Jak działa rejestracja źródeł?
- W przypadku danej reklamy narzędzie Adtech musi teraz zdefiniować konkretny atrybut po stronie klienta
attributionsrc. Wartość tego atrybutu to adres URL, do którego przeglądarka prześle żądanie. To żądanie będzie zawierać nowy nagłówek HTTPAttribution-Reporting-Source-Info, którego wartośćnavigationlubevent,określa, czy źródłem było odpowiednio kliknięcie czy wyświetlenie. - Po otrzymaniu tego żądania serwer śledzenia kliknięć/wyświetleń powinien odpowiedzieć, wysyłając nagłówek HTTP
Attribution-Reporting-Register-Source, który zawiera odpowiednie parametry atrybucji. Źródło, które zwraca ten nagłówek, jest teraz źródłem raportowania (dawniej zdefiniowanym jako
attributionreportto).Nagłówek odpowiedzi HTTP
Attribution-Reporting-Register-Source:{ "source_event_id": "267630968326743374", "destination": "https://toasters.example", "expiry": "604800000" }
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Rejestrowanie źródeł atrybucji
Dołącz do dyskusji publicznej
Reguła atrybucji na podstawie nagłówka (raporty na poziomie zdarzenia)
Co się zmienia i dlaczego?
Tak jak w przypadku rejestracji kliknięcia lub wyświetlenia, nowa oferta pakietowa zmienia regułę atrybucji – gdy technologia AdTech nakazuje przeglądarce zarejestrowanie konwersji – na metodę opartą na nagłówku.
Ten mechanizm jest zgodny z rejestracją źródła opartą na nagłówku i jest bardziej konwencjonalny niż używany wcześniej mechanizm przekierowania.
Dodatkowo w nowej ofercie pakietowej na stronie konwersji wymagany jest atrybut attributionsrc.
Uzasadnienie jest kwestią uprawnień: w poprzedniej ofercie witryna po stronie reguły (zwykle jest to witryna reklamodawcy) miała ogólną kontrolę nad funkcją za pomocą nagłówka Permissions-Policy, ale nie miała na poziomie elementu szczegółowej kontroli nad tym, czy element może wysyłać żądanie do strony, która ostatecznie spowodowałaby atrybucję. attributionsrc to zmienia: ten obowiązkowy znacznik
umożliwia reklamodawcy monitorowanie, a tym samym kontrolę nad tym, które elementy mogą aktywować atrybucję.
Zwróć uwagę, że po stronie źródła (zwykle jest to witryna wydawcy) dostępne są elementy sterujące dla całej strony za pomocą Permissions-Policy oraz elementy sterujące dla całego elementu za pomocą attributionsrc.
Jak działa atrybucja?
Po otrzymaniu żądania piksela i ustaleniu, że należy sklasyfikować go jako konwersję, Adtech powinien wysłać w odpowiedzi nowy nagłówek HTTPAttribution-Reporting-Register-Event-Trigger.
Wartość tego nagłówka określa, jak należy traktować zdarzenie aktywujące jako obiekt JSON. Są to te same informacje, które zostały określone jako parametry zapytania w poprzedniej ofercie pakietowej.
Nagłówek odpowiedzi HTTP Attribution-Reporting-Register-Event-Trigger:
[{
trigger_data: (unsigned 3-bit integer),
trigger_priority: (signed 64-bit integer),
deduplication_key: (signed 64-bit integer)
}]
Przekierowanie (opcjonalnie)
Opcjonalnie serwer Adtech może utworzyć odpowiedź zawierającą zapytanie Attribution-Reporting-Register-Event-Trigger jako odpowiedź przekierowującą.
Dzięki temu osoby trzecie mogą obserwować zdarzenie konwersji i nakazywać przeglądarce jego przypisanie.
Przekierowywanie jest opcjonalne. Nie jest potrzebne, gdy zarówno AdTech, jak i firma zewnętrzna mają piksele na stronie.
Więcej informacji znajdziesz w artykule Raporty innych firm.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Dołącz do dyskusji publicznej
Brak workletu (raporty zbiorcze)
Co się zmienia i dlaczego?
W poprzedniej ofercie raportów agregowanych dostęp do raportów był wymagany do wywołania workletu (mechanizmu opartego na języku JavaScript) służącego do generowania tych raportów.
W nowej ofercie pakietowej nie jest wymagany żaden robot. Zamiast tego Adtech będzie definiować deklaratywnie – za pomocą nagłówków HTTP – reguły, których przeglądarka powinna używać do generowania raportów zbiorczych.
Nowa oferta oferuje szereg korzyści:
- Implementacja w przeglądarkach: nowy projekt, w przeciwieństwie do projektu worklet, jest znacznie prostszy, ponieważ nie wymaga nowego środowiska wykonawczego w przeglądarkach.
- Interfejs programisty: nowy projekt opiera się na nagłówkach, które są powszechnie używane i powszechnie znane programistom – w przeciwieństwie do workletów. Jest on też ściśle dopasowany do interfejsu API do rejestracji źródła, dzięki czemu interfejs API jest łatwiejszy w obsłudze i opanowaniu.
- Wdrożenie: nowy wygląd umożliwia korzystanie z raportów zbiorczych w większej liczbie dotychczasowych systemów pomiarowych. Wiele rozwiązań analitycznych działa tylko w protokole HTTP: polega na żądaniach obrazów (pikseli) niewymagających dostępu do JavaScriptu. Ponieważ jednak metoda workletu wymagała dostępu do JavaScriptu, migracja z niektórych systemów pomiarowych może być trudna.
- Wytrzymałość: nowy wygląd pomaga ograniczyć utratę danych, ponieważ łatwiej jest zintegrować ją z semantyką
keepalive, na przykład gdy kliknięcie lub wyświetlenie jest rejestrowane, gdy użytkownik opuszcza stronę.
Jak działa mechanizm bez workletu?
Ten mechanizm deklaracyjny opiera się na nagłówkach HTTP, tak jak rejestracja źródła na poziomie zdarzenia i nagłówek aktywatora atrybucji. Więcej informacji na ten temat znajdziesz w następnych sekcjach.
Dołącz do dyskusji publicznej
Rejestracja źródła na podstawie nagłówka (raporty zbiorcze)
Zaproponowano nowy mechanizm rejestracji źródła na potrzeby raportu zbiorczego. Mechanizm ten jest taki sam jak w przypadku rejestracji źródła na poziomie zdarzenia.
Inna jest tylko nazwa nagłówka: Attribution-Reporting-Register-Aggregatable-Source.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Reguła atrybucji opartej na nagłówku (raporty zbiorcze)
Zaproponowaliśmy nowy mechanizm rejestracji źródła w raporcie zbiorczym. Mechanizm ten jest taki sam jak reguła atrybucji na poziomie zdarzenia.
Inna jest tylko nazwa nagłówka: Attribution-Reporting-Register-Aggregatable-Trigger-Data.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Nowe funkcje
Raportowanie firm zewnętrznych (raporty na poziomie zdarzenia i raporty zbiorcze)
Co się zmienia i dlaczego?
Dwa aspekty nowej oferty pakietowej pomagają w lepszym obsługiwaniu przypadków użycia raportowania firm zewnętrznych:
- Opcjonalnie technologie AdTech mogą przekierowywać żądania sieciowe do innych serwerów technologii reklamowych, co pozwala tym usługom korzystać z własnego źródła i aktywować rejestrację. Jest to typowy sposób konfigurowania firm zewnętrznych. Ułatwia to wdrożenie interfejsu API między innymi w istniejących systemach raportowania innych firm.
- Źródła raportowania – zwykle technologie reklamowe – nie mają już większości limitów prywatności. Jest to przydatne w sytuacjach, gdy wiele technologii reklamowych współpracuje z tymi samymi wydawcami lub reklamodawcami.
Jak działa raportowanie firm zewnętrznych?
W nowej ofercie rejestracja źródła bazująca na odpowiedziach i aktywator zależą od nagłówków HTTP. W przypadku tych żądań technologia AdTech może wykorzystać przekierowania HTTP.
Jeśli żądanie kliknięcia lub wyświetlenia w witrynie wydawcy (rejestracja źródła) zostanie później przekierowane do wielu stron, każda z nich może zarejestrować to wyświetlenie lub kliknięcie (zdarzenie źródłowe).
Również technika reklamowa może przekierować określone żądanie atrybucji wysłane z witryny odsyłającej, co umożliwia wielu innym podmiotom zarejestrowanie konwersji (reguły atrybucji).
Każda ze stron może uzyskać dostęp do swoich raportów i konfigurować je na podstawie odrębnych danych.
Zarejestruj wiele aktywatorów bez przekierowań
Możesz też zarejestrować wiele reguł atrybucji bez używania przekierowań, dodając wiele elementów piksela po stronie konwersji (po jednym na regułę).
Dołącz do dyskusji publicznej
pomiar konwersji po obejrzeniu (raporty na poziomie zdarzenia i raporty zbiorcze)
Co się zmienia i dlaczego?
W nowej ofercie pakietowej pomiary wyświetleń i kliknięć działają w ujednolicony sposób:
registerattributionsrc, czyli atrybut powiązany z widokiem danych, który nakazuje przeglądarce rejestrowanie wyświetleń obok kliknięć, nie jest już częścią oferty pakietowej.- Mechanizmy ochrony prywatności są teraz ujednolicone w przypadku kliknięć i wyświetleń. Szczegółowe informacje na ten temat można znaleźć w sekcji Szum i przejrzystość.
Proponowana zmiana jest zgodna z nowym mechanizmem rejestracji opartym na nagłówku. Upraszcza to też pracę programistów, ponieważ obsługuje pomiar liczby kliknięć i konwersji po obejrzeniu.
Jak działa pomiar konwersji po wyświetleniu?
Pomiary po wyświetleniu i współczynnik klikalności opierają się na rejestracji opartej na nagłówku.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Raporty na poziomie zdarzenia (zarówno w przypadku kliknięć, jak i wyświetleń)
Dołącz do dyskusji publicznej
Debugowanie i analiza skuteczności (raporty na poziomie zdarzenia i raporty zbiorcze)
Co się zmienia i dlaczego?
Dodaliśmy do oferty mechanizm debugowania, który pomoże deweloperom w wykrywaniu błędów i porównywaniu skuteczności funkcji Attribution Reporting z istniejącymi rozwiązaniami pomiarowymi z wykorzystaniem plików cookie.
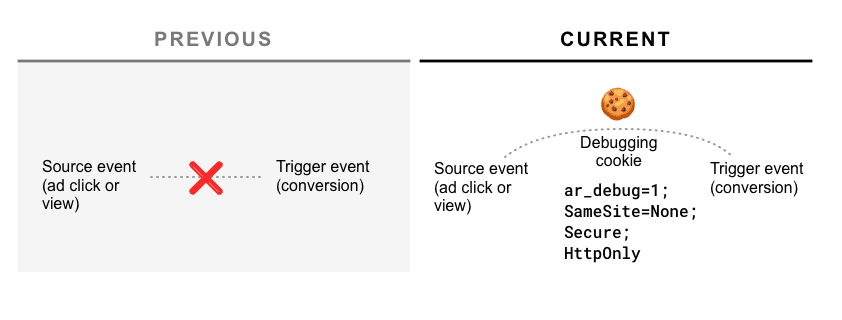
Jak działa debugowanie?
Rejestracja źródła i aktywatora będzie akceptować nowy parametr debug_key, 64-bitową nieoznaczoną liczbę całkowitą (czyli dużą liczbę).
Jeśli raport zostanie utworzony przy użyciu kluczy źródła i aktywatorów debugowania, a plik cookie Samesite=None ar_debug=1 będzie znajdować się u źródła w swoim pliku cookie źródła raportowania i aktywować podczas rejestracji, do punktu końcowego .well-known/attribution-reporting/debug zostanie wysłany raport debugowania (JSON):
{
"source_debug_key": 1234567890987,
"trigger_debug_key": 4567654345028
}
Raporty na poziomie zdarzenia i raporty zbiorcze będą też zawierać te 2 nowe parametry, dzięki czemu będzie można je powiązać z właściwym raportem debugowania.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Opcjonalnie: rozszerzone raporty na temat debugowania
Dołącz do dyskusji publicznej
możliwości filtrowania (raporty na poziomie zdarzenia i raporty zbiorcze);
Co się zmienia i dlaczego?
Obsługują one ważne przypadki użycia we współczesnym ekosystemie reklamowym, więc zarówno w raportach na poziomie zdarzenia, jak i raportach zbiorczych (z uwzględnieniem wszystkich) obsługiwanych przypadków użycia:
- Filtrowanie konwersji:służy do filtrowania konwersji na podstawie informacji po stronie źródła. Na przykład wybierz inne dane o regułach (dane o konwersjach) dla kliknięć i wyświetleń reklam.
- Niezgodność atrybucji: filtruje konwersje, które zostały niewłaściwie przypisane. To specyficzny typ filtrowania konwersji. Możesz np. odfiltrowywać konwersje, które są dopasowywane do nieprawidłowego kliknięcia lub wyświetlenia reklamy ze względu na ustawiony w interfejsie API zakres docelowy +1.
Jak działają funkcje filtrowania? (w przypadku raportów na poziomie zdarzenia)
Opcjonalne pole source_data w obiekcie JSON po stronie źródła może określać elementy, które będą później używane przez przeglądarkę podczas konwersji w celu zastosowania logiki filtrowania.
{
source_event_id: "267630968326743374",
destination: "https://toasters.example",
expiry: "604800000"
source_data: {
conversion_subdomain: ["electronics.megastore"
"electronics2.megastore"],
product: "198764",
// Note that "source_type" will be automatically generated as one of {"navigation", "event"}
}
}
Rejestracja aktywatora będzie teraz akceptować opcjonalny nagłówek Attribution-Reporting-Filters.
Nagłówek odpowiedzi HTTP Attribution-Reporting-Filters:
{
"conversion_subdomain": "electronics.megastore",
"directory": "/store/electronics"
}
Możesz też rozszerzyć nagłówek Attribution-Reporting-Register-Event-Trigger o pole filters, aby filtrować selektywnie i ustawić trigger_data na podstawie source_data.
Jeśli klucze w kluczach dopasowania JSON filtrów w source_data są
całkowicie zignorowane, jeśli przecięcie jest puste.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Dołącz do dyskusji publicznej
Zmiany w ochronie prywatności
Szum i przejrzystość (raporty na poziomie zdarzenia i raporty zbiorcze)
Co się zmienia i dlaczego?
W nowej ofercie ulepszyliśmy jeden z mechanizmów ochrony prywatności w raportach: raporty są objęte losową odpowiedzią.
Oznacza to, że niektóre rzeczywiste konwersje będą raportowane prawidłowo, a przez pewien czas niektóre konwersje rzeczywiste zostaną pominięte lub dodane zostaną fałszywe konwersje.
Ta nowa metoda ma kilka zalet:
- Ujednolica mechanizm ochrony prywatności kliknięć i wyświetleń.
- Jest to prostsze niż mechanizm, w którym dane aktywujące (dane o konwersjach) i szum linku źródła reguły są rozdzielone.
- Ustanawia platformę ochrony prywatności, która z odpowiednimi ustawieniami szumu sprawia, że żadna strona nie może polegać na interfejsie API, aby mieć pewność, że dany użytkownik dokonał konwersji (lub nie) w przypadku określonej reklamy.
Ten nowy mechanizm zastępuje poprzedni, w którym w 5% przypadków dane aktywujące (dane konwersji) zostały zastąpione losową wartością.
Do treści raportu (pole randomized_trigger_rate) dodaliśmy też wartość prawdopodobieństwa otrzymania losowej odpowiedzi. To pole określa prawdopodobieństwo (od 0 do 1), że źródło podlega losowej odpowiedzi.
Ma to 2 główne korzyści:
- Dzięki temu informacje o podstawowym działaniu przeglądarki są transparent dla podmiotów, które otrzymają raporty (zazwyczaj w przypadku technologii reklamowych).
- Przyda się w przyszłości, w której interfejs API będzie obsługiwany w różnych przeglądarkach: różne przeglądarki mogą zdecydować się na stosowanie różnych poziomów szumu w zależności od swoich celów w zakresie prywatności, a strony, które będą zajmować się raportem, będą musiały mieć wgląd w to.
Jak działa szum?
W nowej ofercie pakietowej, w momencie zarejestrowania źródła (tj. po zarejestrowaniu kliknięcia lub wyświetlenia reklamy), przeglądarka losowo określa, czy będzie przypisywać konwersje i przesyłać raporty dotyczące tego kliknięcia lub wyświetlenia reklamy zgodnie z prawdą, czy też generować fałszywe dane wyjściowe.
Fałszywe dane wyjściowe mogą być następujące:
- Brak raportów – bez względu na to, czy użytkownik dokona konwersji;
- Jeden lub kilka fałszywych zgłoszeń – niezależnie od tego, czy użytkownik dokona konwersji.
W fałszywych raportach dane reguły (dane o konwersjach) są losowe: losowa, 3-bitowa wartość dla kliknięć (dowolna liczba z zakresu od 0 do 7) oraz losowa, 1-bitowa wartość dla wyświetleń (0 lub 1).
Podobnie jak prawdziwe raporty, fałszywe zgłoszenia nie są wysyłane natychmiast po dokonaniu konwersji przez użytkownika. Są one wysyłane na koniec losowego okna raportowania.
Istnieją 3 okna raportowania kliknięć (2 dni, 7 dni lub 30 dni po kliknięciu). Każdy fałszywy raport jest losowo przypisywany do jednego z okresów raportowania.
Niezależnie od tego, jak wspomnieliśmy w poprzedniej ofercie, kolejność raportów w danym okresie jest losowa.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Przykłady fałszywych konwersji
Dołącz do dyskusji publicznej
Ograniczenia raportowania (raporty na poziomie zdarzenia i raporty zbiorcze)
Co się zmienia i dlaczego?
Nowa oferta wyraźnie ogranicza liczbę podmiotów, które mogą dokonywać pomiarów zdarzeń między 2 witrynami.
- Proponujemy ograniczenie maksymalnej liczby unikalnych źródeł raportowania (zwykle technologii reklamowych), które mogą rejestrować źródła na {publisher, advertiser}, do 100 na 30 dni. Ten licznik będzie zwiększany o każde kliknięcie lub wyświetlenie reklamy (zdarzenie źródłowe), nawet w przypadku nieprzypisanych.
- Maksymalna liczba unikalnych źródeł raportowania (zwykle technologii reklamowych), które mogą wysyłać raporty na {wydawcę, reklamodawcę}, powinna wynosić 10 na 30 dni. Ten licznik będzie zwiększany o każdą przypisaną konwersję.
Limity te są na tyle wysokie, aby nie ograniczały możliwości pomiaru konwersji żadnemu podmiotowi, ale na tyle niskie, aby pomóc w łagodzeniu niektórych form nadużyć związanych z interfejsami API.
Raportowanie limitów czasu oczekiwania / częstotliwości
Co się zmienia i dlaczego?
Okres oczekiwania na raportowanie to mechanizm ochrony prywatności, który ogranicza ilość wszystkich informacji wysyłanych za pomocą tego interfejsu API w danym okresie.
W nowej ofercie pakietowej można zaplanować 100 raportów na {source site, destination, raportowania origin} (zwykle {publisher, advertiser, adtech}) na okres 30 dni.
Po przekroczeniu tego limitu przeglądarka przestanie planować raporty zgodne z podaną wartością {source site, destination, Reporting origin} (zwykle {publisher, advertiser, adtech}) – aż do momentu, gdy liczba raportów z ostatnich 30 dni spadnie poniżej 100 w przypadku tego {witryny źródłowej, miejsca docelowego, źródła raportowania}.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Limity czasu oczekiwania / liczby żądań w raportach
Ograniczenie miejsc docelowych (tylko raporty na poziomie zdarzenia)
Co się zmienia i dlaczego?
Ograniczenie miejsc docelowych jest modyfikowane tak, aby uwzględniać źródło raportowania (zwykle jest to technologia reklamowa) objętego zakresem: {publisher, adtech} może zezwolić na używanie 100 unikalnych oczekujących miejsc docelowych (zwykle witryn reklamodawców lub witryn, w których mają nastąpić konwersje).
To ochrona prywatności, która ogranicza ponowne odtwarzanie historii przeglądania.
Więcej informacji znajdziesz w wyjaśnieniu technicznym
Ograniczenie liczby unikalnych miejsc docelowych uwzględnionych przez oczekujące źródła
Wszystkie zasoby
- Zobacz Raportowanie atrybucji.
- Przeczytaj artykuł Co warto wiedzieć o interfejsie API.
Źródłem obrazu w nagłówku jest Diana Polekhina na kanale Unsplash.