ในส่วนนี้ เราจะต่อยอดการสร้าง การฝึกอบรม และการประเมินโมเดลกัน ในขั้นตอนที่ 3 เราเลือกใช้โมเดล N Ngram หรือโมเดลลําดับโดยใช้อัตราส่วน S/W
ได้เวลาเขียนอัลกอริทึมการแยกประเภทและฝึกฝน เราจะใช้ TensorFlow กับ tf.keras API เพื่อดําเนินการนี้
การสร้างโมเดลแมชชีนเลิร์นนิงด้วย Keras นั้นเป็นเรื่องของการประกอบเลเยอร์ต่างๆ บล็อกการประมวลผลข้อมูล ซึ่งคล้ายกับการต่อชิ้นส่วนตัวต่อเลโก้ เลเยอร์เหล่านี้ช่วยให้เราระบุลําดับการเปลี่ยนรูปแบบที่ เราต้องการทํากับข้อมูลได้ เมื่ออัลกอริทึมการเรียนรู้ของเราป้อนอินพุตข้อความเดียวและส่งออกการจัดประเภทเดียว เราก็สามารถสร้างเลเยอร์เชิงเส้นในชั้นต่างๆ ได้โดยใช้ รูปแบบตามลําดับ API
รูปที่ 9: เลเยอร์เชิงเส้นของเลเยอร์
เราจะสร้างเลเยอร์อินพุตและเลเยอร์ขั้นกลางต่างออกไป โดยขึ้นอยู่กับว่าเราสร้าง N-Ggram หรือโมเดลต่อเนื่องหรือไม่ แต่ไม่ว่าเลเยอร์จะเป็นประเภทใดก็ตาม เลเยอร์สุดท้ายจะเหมือนกันสําหรับแต่ละโจทย์ปัญหา
การสร้างเลเยอร์สุดท้าย
เมื่อมีเพียง 2 คลาส (การจัดประเภทไบนารี) โมเดลของเราควรแสดงคะแนนความน่าจะเป็นเพียงคะแนนเดียว เช่น เอาต์พุต 0.2 สําหรับตัวอย่างอินพุตที่ระบุหมายความว่า "ความเชื่อมั่น 20% ว่าตัวอย่างนี้อยู่ในคลาสแรก (คลาส 1) และ 80% ที่ขณะนี้อยู่ในคลาสที่ 2 (คลาส 0)" หากต้องการเอาต์พุตคะแนนความน่าจะเป็น ฟังก์ชันฟังก์ชันเปิดใช้งานของเลเยอร์ล่าสุดควรเป็น
ฟังก์ชันฟังก์ชัน sigmoid และ
ฟังก์ชันการสูญเสีย1 1
เมื่อมีมากกว่า 2 คลาส (การจัดประเภทแบบหลายคลาส) โมเดลของเราควรแสดงคะแนนความน่าจะเป็น 1 คะแนนต่อชั้นเรียน ผลรวมของคะแนนเหล่านี้ควรเป็น 1 เช่น เอาต์พุต {0: 0.2, 1: 0.7, 2: 0.1} หมายความว่า"20% มั่นใจว่าตัวอย่างนี้อยู่ในคลาส 0 และ 70% ระบุว่าอยู่ในคลาส 1 และ 10% อยู่ในคลาส 2"หากต้องการเอาต์พุตคะแนนเหล่านี้ ฟังก์ชันการเปิดใช้งานของเลเยอร์สุดท้ายควรเป็น Softmax และฟังก์ชันการสูญเสียที่ใช้ฝึกโมเดลควรเป็นโมเดลเอนโทรปีแบบหมวดหมู่ (ดูรูปที่ 10 ทางขวา)
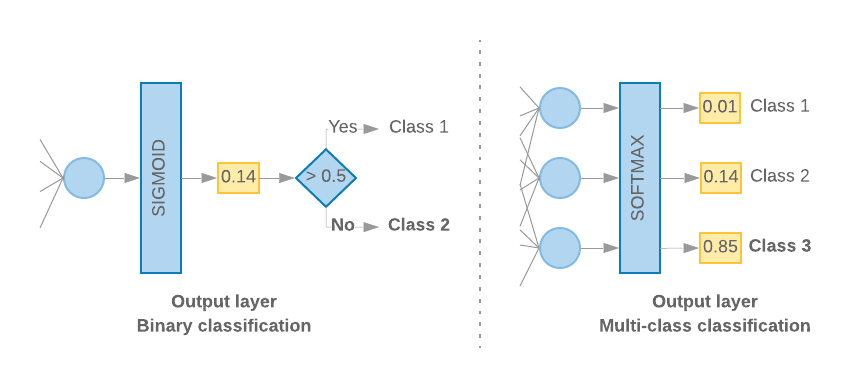
รูปที่ 10: เลเยอร์สุดท้าย
โค้ดต่อไปนี้จะกําหนดฟังก์ชันที่ใช้จํานวนคลาสเป็นอินพุต และส่งจํานวนหน่วยเลเยอร์ที่เหมาะสม (1 หน่วยสําหรับการจัดประเภทไบนารี หรือ 1 หน่วยสําหรับแต่ละคลาส) และฟังก์ชันการเปิดใช้งานที่เหมาะสม
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
ทั้ง 2 ส่วนต่อไปนี้จะอธิบายการสร้างเลเยอร์โมเดลที่เหลือสําหรับโมเดล N Ngram และโมเดลลําดับ
เมื่ออัตราส่วน S/W น้อย เราพบว่าโมเดล n-gram มีประสิทธิภาพดีกว่าโมเดลลําดับ โมเดลลําดับจะดีขึ้นเมื่อมีเวกเตอร์ที่หนาแน่นและหนาแน่นจํานวนมาก นั่นเป็นเพราะว่าผู้ชมเรียนรู้การฝังความสัมพันธ์แบบแน่นหนา
และเกิดขึ้นได้ดีที่สุดกับตัวอย่างหลายๆ แบบ
สร้างแบบจําลอง N-gram [ตัวเลือก A]
เราอ้างอิงถึงโมเดลที่ประมวลผลโทเค็นโดยอิสระ (ไม่คํานึงถึงลําดับคํา) เป็นโมเดล N กรัม โมเดลหลายเลเยอร์ที่เรียบง่าย (รวมถึงการถดถอยแบบโลจิสติกส์) เครื่องเพิ่มไล่ระดับสี และโมเดลเครื่องเวกเตอร์ ทั้งหมดนี้อยู่ในหมวดหมู่นี้ และไม่สามารถใช้ประโยชน์จากข้อมูลการจัดลําดับข้อความได้
เราเปรียบเทียบประสิทธิภาพของโมเดล n-gram บางโมเดลที่กล่าวถึงข้างต้น และสังเกตเห็นว่าโมเดลที่มีหลายเลเยอร์ (MLP) มักจะทํางานได้ดีกว่าตัวเลือกอื่นๆ MLP นั้นง่ายต่อการทําความเข้าใจและเข้าใจง่าย ให้ความแม่นยําที่ดี และต้องใช้การคํานวณค่อนข้างน้อย
โค้ดต่อไปนี้กําหนดโมเดล MLP แบบ 2 ชั้นใน tf.keras โดยเพิ่มเมนูแบบเลื่อนลงของ 2 เลเยอร์สําหรับการปรับให้สอดคล้องตามมาตรฐาน (เพื่อป้องกันไม่ให้กําหนดค่ามากเกินไปสําหรับการฝึกตัวอย่าง)
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
โมเดลลําดับการสร้าง [ตัวเลือก B]
เราเรียกโมเดลที่สามารถเรียนรู้จากความใกล้เคียงของโทเค็นเป็นโมเดลลําดับ ซึ่งรวมถึงคลาสของ CNN และ RNN ระบบจะประมวลผลข้อมูลล่วงหน้าเป็นเวกเตอร์ของค่าสําหรับโมเดลเหล่านี้
โดยทั่วไป โมเดลลําดับจะมีพารามิเตอร์จํานวนมากให้เรียนรู้ เลเยอร์แรกในโมเดลเหล่านี้คือเลเยอร์แบบฝัง ซึ่งจะเรียนรู้ความสัมพันธ์ระหว่างคําในพื้นที่เวกเตอร์ที่หนาแน่น การเรียนรู้ความสัมพันธ์ของคํา ได้ผลดีที่สุดกับตัวอย่างมากมาย
คําในชุดข้อมูลหนึ่งๆ มักจะไม่ซ้ํากันในชุดข้อมูลนั้น เราจึงเรียนรู้ความสัมพันธ์ระหว่างคําในชุดข้อมูลโดยใช้ชุดข้อมูลอื่นๆ เราสามารถโอนการฝังที่เรียนรู้จากชุดข้อมูลอื่นลงในเลเยอร์การฝังได้ การฝังเหล่านี้เรียกว่าการฝังล่วงหน้า การใช้การฝังก่อนการฝึกจะทําให้โมเดลเริ่มต้นในกระบวนการเรียนรู้ได้ล่วงหน้า
มีการฝังแบบฝึกล่วงหน้าที่ได้รับการฝึกโดยใช้คลังข้อมูลขนาดใหญ่ เช่น GloVe GloVe ได้รับการฝึกอบรม ในหลายคอร์ส (วิกิพีเดีย) เราได้ทดสอบการฝึกโมเดลลําดับโดยใช้การฝัง GloVe เวอร์ชันหนึ่งและสังเกตได้ว่า หากเราถ่วงน้ําหนักน้ําหนักของการฝังก่อนการฝึกและฝึกเพียงส่วนที่เหลือในเครือข่าย โมเดลนั้นจะทํางานได้ไม่ดีนัก ซึ่งอาจเป็นเพราะบริบท ซึ่งเลเยอร์การรักษาได้รับการฝึกอบรมอาจต่างจากบริบทที่เราใช้อยู่
การฝัง GloVe ที่ผ่านการฝึกอบรมเกี่ยวกับข้อมูล Wikipedia อาจไม่สอดคล้องกับรูปแบบภาษาในชุดข้อมูล IMDb ของเรา อาจต้องสรุปความสัมพันธ์ที่สรุปได้ เช่น น้ําหนักแบบฝังอาจต้องปรับตามบริบท โดยมี 2 ขั้นดังนี้
ในการเรียกใช้งานครั้งแรก ที่น้ําหนักตัวชั้นแบบฝังหยุดนิ่ง เราก็อนุญาตให้เครือข่ายที่เหลือเรียนรู้ได้ ในตอนท้ายของน้ําหนักนี้ น้ําหนักของรูปแบบจะได้ไปยังสถานะที่ดีกว่าค่าที่ไม่ได้ระบุไว้ สําหรับการเรียกใช้ครั้งที่สอง เราอนุญาตให้เลเยอร์แบบฝังเรียนรู้ด้วย โดยปรับแต่งน้ําหนักทั้งหมดให้ละเอียดในเครือข่าย กระบวนการนี้เรียกว่าการฝังแบบฝังที่ได้รับการปรับแต่ง
การฝังที่มีการปรับแต่งอย่างละเอียดจะมีความแม่นยํามากกว่า แต่ต้องอาศัยพลังการประมวลผลที่เพิ่มขึ้นในการฝึกเครือข่าย เนื่องจากเรามีตัวอย่างจํานวนหนึ่งเพียงพอ ทําให้เราเรียนรู้การฝังตัวได้เป็นอย่างดี เราสังเกตเห็นว่าสําหรับ
S/W > 15Kนั้น การเริ่มใหม่ตั้งแต่ต้นจะให้ผลลัพธ์ที่แม่นยําเช่นเดียวกับการใช้การฝังที่ปรับแต่ง
เราเปรียบเทียบรูปแบบลําดับต่างๆ เช่น CNN, sepCNN, RNN (LSTM & GRU), CNN-RNN และ RNN แบบซ้อนที่แตกต่างกัน เราพบว่า sepCNNs ซึ่งเป็นตัวแปรเครือข่ายที่มีการปฏิวัติมักมีประสิทธิภาพข้อมูลและการประมวลผลมากกว่า และทํางานได้ดีกว่ารูปแบบอื่นๆ
โค้ดต่อไปนี้จะสร้างโมเดล sepCNN แบบ 4 ชั้น
from tensorflow.python.keras import models
from tensorflow.python.keras import initializers
from tensorflow.python.keras import regularizers
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.layers import Embedding
from tensorflow.python.keras.layers import SeparableConv1D
from tensorflow.python.keras.layers import MaxPooling1D
from tensorflow.python.keras.layers import GlobalAveragePooling1D
def sepcnn_model(blocks,
filters,
kernel_size,
embedding_dim,
dropout_rate,
pool_size,
input_shape,
num_classes,
num_features,
use_pretrained_embedding=False,
is_embedding_trainable=False,
embedding_matrix=None):
"""Creates an instance of a separable CNN model.
# Arguments
blocks: int, number of pairs of sepCNN and pooling blocks in the model.
filters: int, output dimension of the layers.
kernel_size: int, length of the convolution window.
embedding_dim: int, dimension of the embedding vectors.
dropout_rate: float, percentage of input to drop at Dropout layers.
pool_size: int, factor by which to downscale input at MaxPooling layer.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
num_features: int, number of words (embedding input dimension).
use_pretrained_embedding: bool, true if pre-trained embedding is on.
is_embedding_trainable: bool, true if embedding layer is trainable.
embedding_matrix: dict, dictionary with embedding coefficients.
# Returns
A sepCNN model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
# Add embedding layer. If pre-trained embedding is used add weights to the
# embeddings layer and set trainable to input is_embedding_trainable flag.
if use_pretrained_embedding:
model.add(Embedding(input_dim=num_features,
output_dim=embedding_dim,
input_length=input_shape[0],
weights=[embedding_matrix],
trainable=is_embedding_trainable))
else:
model.add(Embedding(input_dim=num_features,
output_dim=embedding_dim,
input_length=input_shape[0]))
for _ in range(blocks-1):
model.add(Dropout(rate=dropout_rate))
model.add(SeparableConv1D(filters=filters,
kernel_size=kernel_size,
activation='relu',
bias_initializer='random_uniform',
depthwise_initializer='random_uniform',
padding='same'))
model.add(SeparableConv1D(filters=filters,
kernel_size=kernel_size,
activation='relu',
bias_initializer='random_uniform',
depthwise_initializer='random_uniform',
padding='same'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(SeparableConv1D(filters=filters * 2,
kernel_size=kernel_size,
activation='relu',
bias_initializer='random_uniform',
depthwise_initializer='random_uniform',
padding='same'))
model.add(SeparableConv1D(filters=filters * 2,
kernel_size=kernel_size,
activation='relu',
bias_initializer='random_uniform',
depthwise_initializer='random_uniform',
padding='same'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(rate=dropout_rate))
model.add(Dense(op_units, activation=op_activation))
return model
ฝึกโมเดลของคุณ
เมื่อเราสร้างสถาปัตยกรรมโมเดลแล้ว เราจําเป็นต้องฝึกโมเดล การฝึกเกี่ยวข้องกับการสร้างการคาดการณ์ตามสถานะปัจจุบันของโมเดล การคํานวณความไม่ถูกต้องของการคาดการณ์ การอัปเดตน้ําหนักหรือพารามิเตอร์ของเครือข่ายเพื่อลดข้อผิดพลาดนี้ และทําให้โมเดลคาดการณ์ได้ดีขึ้น เราดําเนินการซ้ําตามขั้นตอนนี้จนกว่าโมเดลของเราจะมีสถานะ Conversion และไม่สามารถเรียนรู้ได้อีก พารามิเตอร์หลักที่เลือกสําหรับกระบวนการนี้มีอยู่ 3 รายการ (ดูตารางที่ 2
- เมตริก: วิธีวัดประสิทธิภาพของโมเดลโดยใช้เมตริก เราใช้ความถูกต้องเป็นเมตริกในการทดสอบ
- ฟังก์ชันการสูญเสีย: ฟังก์ชันที่ใช้ในการคํานวณค่าการสูญเสียที่กระบวนการฝึก จากนั้นจะพยายามลดให้เหลือน้อยที่สุดโดยการปรับแต่งน้ําหนักเครือข่าย สําหรับปัญหาเกี่ยวกับการแยกประเภท การสูญเสียครอสเอนโทรปี
- Optimizer: ฟังก์ชันที่กําหนดวิธีการอัปเดตน้ําหนักเครือข่ายตามเอาต์พุตของฟังก์ชันการสูญเสีย เราใช้เครื่องมือเพิ่มประสิทธิภาพ Adam ยอดนิยมในการทดสอบของเรา
ใน Keras เราส่งผ่านพารามิเตอร์การเรียนรู้เหล่านี้ไปยังโมเดลได้โดยใช้เมธอด คอมไพล์
| พารามิเตอร์การเรียนรู้ | ค่า |
|---|---|
| เมตริก | ความแม่นยำ |
| ฟังก์ชันการสูญเสีย - การแยกประเภทไบนารี | ไบนารีครอสโทรปี |
| ฟังก์ชันการสูญเสีย - การแยกประเภทแบบหลายคลาส | Sparse_categorical_crossentropy |
| เครื่องมือเพิ่มประสิทธิภาพ | Adam |
ตารางที่ 2: พารามิเตอร์การเรียนรู้
การฝึกจริงจะเกิดขึ้นโดยใช้เมธอดพอดี
ระบบจะใช้รอบการประมวลผลส่วนใหญ่ ทั้งนี้ขึ้นอยู่กับขนาดของชุดข้อมูล ในการทําซ้ําการฝึกแต่ละครั้ง ระบบจะใช้ตัวอย่างจํานวน batch_size รายการจากข้อมูลการฝึกของคุณเพื่อคํานวณการสูญเสีย และจะอัปเดตน้ําหนัก 1 ครั้งโดยอิงตามค่านี้
กระบวนการฝึกจะเสร็จสมบูรณ์ภายใน epoch เมื่อโมเดลดูชุดข้อมูลการฝึกทั้งหมด ที่ตอนท้ายของแต่ละ Epoch เราใช้ชุดข้อมูลการตรวจสอบเพื่อประเมินว่าโมเดลกําลังเรียนรู้ได้ดีเพียงใด เราต้องฝึกซ้ําโดยใช้ชุดข้อมูลตามจํานวน Epoch ที่กําหนดไว้ล่วงหน้า เราอาจเพิ่มประสิทธิภาพด้วยการหยุดให้เร็วเมื่อความถูกต้องการตรวจสอบความถูกต้องคงที่ระหว่าง Epoch ที่ต่อเนื่องกัน ซึ่งแสดงให้เห็นว่าโมเดลไม่ได้ฝึกแล้ว
| ไฮเปอร์พารามิเตอร์การฝึก | ค่า |
|---|---|
| อัตราการเรียนรู้ | 1e-3 |
| ช่วงเวลาสําคัญในอดีต | 1000 |
| ขนาดกลุ่ม | 512 |
| การหยุดก่อนกำหนด | พารามิเตอร์: val_loss, ความอดทน: 1 |
ตารางที่ 3: ไฮเปอร์พารามิเตอร์การฝึก
โค้ด Keras ต่อไปนี้ใช้ขั้นตอนการฝึกอบรมโดยใช้พารามิเตอร์ที่เลือกในตารางที่ 2 และ 3 ข้างต้น
def train_ngram_model(data,
learning_rate=1e-3,
epochs=1000,
batch_size=128,
layers=2,
units=64,
dropout_rate=0.2):
"""Trains n-gram model on the given dataset.
# Arguments
data: tuples of training and test texts and labels.
learning_rate: float, learning rate for training model.
epochs: int, number of epochs.
batch_size: int, number of samples per batch.
layers: int, number of `Dense` layers in the model.
units: int, output dimension of Dense layers in the model.
dropout_rate: float: percentage of input to drop at Dropout layers.
# Raises
ValueError: If validation data has label values which were not seen
in the training data.
"""
# Get the data.
(train_texts, train_labels), (val_texts, val_labels) = data
# Verify that validation labels are in the same range as training labels.
num_classes = explore_data.get_num_classes(train_labels)
unexpected_labels = [v for v in val_labels if v not in range(num_classes)]
if len(unexpected_labels):
raise ValueError('Unexpected label values found in the validation set:'
' {unexpected_labels}. Please make sure that the '
'labels in the validation set are in the same range '
'as training labels.'.format(
unexpected_labels=unexpected_labels))
# Vectorize texts.
x_train, x_val = vectorize_data.ngram_vectorize(
train_texts, train_labels, val_texts)
# Create model instance.
model = build_model.mlp_model(layers=layers,
units=units,
dropout_rate=dropout_rate,
input_shape=x_train.shape[1:],
num_classes=num_classes)
# Compile model with learning parameters.
if num_classes == 2:
loss = 'binary_crossentropy'
else:
loss = 'sparse_categorical_crossentropy'
optimizer = tf.keras.optimizers.Adam(lr=learning_rate)
model.compile(optimizer=optimizer, loss=loss, metrics=['acc'])
# Create callback for early stopping on validation loss. If the loss does
# not decrease in two consecutive tries, stop training.
callbacks = [tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=2)]
# Train and validate model.
history = model.fit(
x_train,
train_labels,
epochs=epochs,
callbacks=callbacks,
validation_data=(x_val, val_labels),
verbose=2, # Logs once per epoch.
batch_size=batch_size)
# Print results.
history = history.history
print('Validation accuracy: {acc}, loss: {loss}'.format(
acc=history['val_acc'][-1], loss=history['val_loss'][-1]))
# Save model.
model.save('IMDb_mlp_model.h5')
return history['val_acc'][-1], history['val_loss'][-1]
ดูตัวอย่างโค้ดสําหรับการฝึกโมเดลลําดับได้ที่นี่