En este punto, recopilamos nuestro conjunto de datos y obtuvimos estadísticas sobre sus características clave. Luego, según las métricas que reunimos en el Paso 2, debemos pensar qué modelo de clasificación deberíamos usar. Esto significa hacer preguntas como “¿Cómo presentamos los datos de texto a un algoritmo que espera una entrada numérica?” (esto se llama procesamiento previo y vectorización de datos), “¿Qué tipo de modelo deberíamos usar?”, “¿Qué parámetros de configuración deberíamos usar para nuestro modelo?”, etcétera.
Gracias a décadas de investigación, tenemos acceso a una gran variedad de opciones de procesamiento previo y configuración de modelos. Sin embargo, la disponibilidad de una gran variedad de opciones viables para elegir aumenta considerablemente la complejidad y el alcance del problema en cuestión. Dado que las mejores opciones podrían no ser obvias, una solución simple sería probar todas las opciones posibles de forma exhaustiva y reducir algunas opciones a través de la intuición. Sin embargo, sería muy costoso.
En esta guía, intentamos simplificar significativamente el proceso de selección de un modelo de clasificación de texto. Para un conjunto de datos determinado, nuestro objetivo es encontrar el algoritmo que logre una exactitud casi exacta y, al mismo tiempo, minimizar el tiempo de procesamiento necesario para el entrenamiento. Ejecutamos una gran cantidad (alrededor de 450,000) de experimentos en problemas de diferentes tipos (especialmente análisis de opiniones y problemas de clasificación de temas) mediante 12 conjuntos de datos que alternaban cada conjunto de datos entre diferentes técnicas de procesamiento previo de datos y arquitecturas de modelos diferentes. Esto nos ayudó a identificar los parámetros del conjunto de datos que influyen en las opciones óptimas.
El algoritmo de selección del modelo y el diagrama de flujo a continuación son un resumen de nuestra experimentación. No te preocupes si aún no entiendes todos los términos que se usan en ellos. Las siguientes secciones de esta guía los explican en profundidad.
Algoritmo para la preparación de datos y la creación de modelos
1. Calculate the number of samples/number of words per sample ratio. 2. If this ratio is less than 1500, tokenize the text as n-grams and use a simple multi-layer perceptron (MLP) model to classify them (left branch in the flowchart below): a. Split the samples into word n-grams; convert the n-grams into vectors. b. Score the importance of the vectors and then select the top 20K using the scores. c. Build an MLP model. 3. If the ratio is greater than 1500, tokenize the text as sequences and use a sepCNN model to classify them (right branch in the flowchart below): a. Split the samples into words; select the top 20K words based on their frequency. b. Convert the samples into word sequence vectors. c. If the original number of samples/number of words per sample ratio is less than 15K, using a fine-tuned pre-trained embedding with the sepCNN model will likely provide the best results. 4. Measure the model performance with different hyperparameter values to find the best model configuration for the dataset.
En el siguiente diagrama de flujo, los cuadros amarillos indican los procesos de preparación de datos y modelos. Los cuadros grises y verdes indican las opciones que consideramos para cada proceso. Los cuadros verdes indican nuestra opción recomendada para cada proceso.
Puedes usar este diagrama de flujo como punto de partida para construir tu primer experimento, ya que te brindará una buena precisión con costos de procesamiento bajos. Luego, puedes continuar mejorando tu modelo inicial en las iteraciones posteriores.
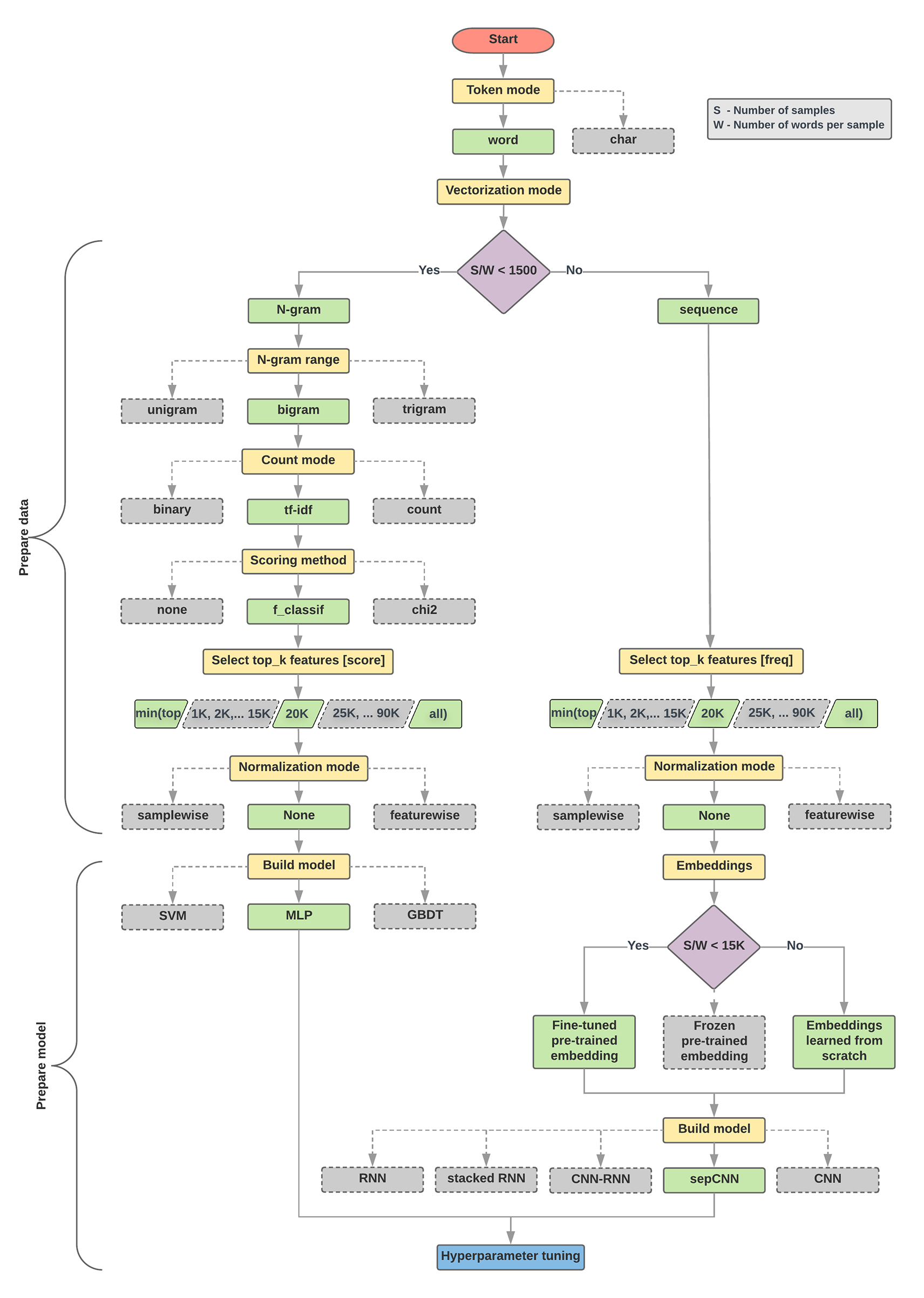
Figura 5: Diagrama de flujo de clasificación de texto
En este diagrama de flujo, se responden dos preguntas clave:
¿Qué algoritmo o modelo de aprendizaje deberíamos usar?
¿Cómo deberíamos preparar los datos para aprender de manera eficiente la relación entre el texto y la etiqueta?
La respuesta a la segunda pregunta depende de la respuesta de la primera pregunta. La forma en que procesamos los datos para ingresar en un modelo dependerá del modelo que elijamos. A grandes rasgos, los modelos se pueden clasificar en dos categorías: aquellos que utilizan información de orden de las palabras (modelos de secuencia) y los que solo ven texto como “bolsas” (conjuntos) de palabras (modelos de n-grama). Los tipos de modelos de secuencia incluyen redes neuronales convolucionales (CNN), redes neuronales recurrentes (RNN) y sus variaciones. Los tipos de modelos de n-grama incluyen regresión logística, perceptrones multicapa simples (MLP o redes neuronales completamente conectadas), árboles potenciados por gradientes y máquinas vectoriales.
Desde nuestros experimentos, observamos que la relación entre la “cantidad de muestras” (S) y la “cantidad de palabras por muestra” (W) se correlaciona con el modelo que tiene un buen rendimiento.
Cuando el valor de esta proporción es pequeño (<1500), los perceptrones pequeños de varias capas que toman n-gramas como entrada (que llamaremos Opción A) tienen un mejor o menos rendimiento, así como modelos de secuencia. Los MLP son fáciles de definir y comprender, y requieren mucho menos tiempo de procesamiento que los modelos de secuencia. Cuando el valor de esta proporción es grande (>= 1500), usa un modelo de secuencia (Opción B). En los siguientes pasos, puedes omitir las subsecciones relevantes (etiquetadas A o B) para el tipo de modelo que elegiste en función de la proporción de muestras/palabras por muestra.
En el caso de nuestro conjunto de datos de revisión de IMDb, la proporción de muestras/palabras por muestra es de aproximadamente 144. Esto significa que crearemos un modelo de MLP.