Nesta página, você encontra os termos do glossário de avaliação de linguagem. Para ver todos os termos do glossário, clique aqui.
A
Attention,
Um mecanismo usado em uma rede neural que indica a importância de uma determinada palavra ou parte de uma palavra. A atenção compacta a quantidade de informações que um modelo precisa para prever o próximo token/palavra. Um mecanismo de atenção típico pode consistir em uma soma ponderada em um conjunto de entradas, em que o peso de cada entrada é calculado por outra parte da rede neural.
Consulte também autoatenção e autoatenção de várias cabeças, que são os elementos básicos dos transformadores.
codificador automático
Um sistema que aprende a extrair as informações mais importantes da entrada. Codificadores automáticos são uma combinação de codificador e decodificador. Os codificadores automáticos dependem do processo de duas etapas a seguir:
- O codificador mapeia a entrada para um formato de baixa dimensão (intermediário) com perdas.
- O decodificador cria uma versão com perda da entrada original, mapeando o formato de baixa dimensão para o original de maior dimensão.
Os codificadores automáticos são treinados de ponta a ponta, fazendo com que o decodificador tente reconstruir a entrada original do formato intermediário do codificador da melhor maneira possível. Como o formato intermediário é menor (de menor dimensão) que o formato original, o codificador automático é forçado a aprender quais informações na entrada são essenciais, e a saída não será perfeitamente idêntica à entrada.
Exemplo:
- Se os dados de entrada forem um gráfico, a cópia não exata será semelhante ao gráfico original, mas um pouco modificada. Talvez a cópia não exata remova o ruído do gráfico original ou preencha alguns pixels ausentes.
- Se os dados de entrada forem texto, um codificador automático vai gerar um novo texto que imite o texto original, mas não seja idêntico ao original.
Consulte também codificadores automáticos variáveis.
modelo autoregressivo
Um model que infere uma previsão com base nas próprias previsões anteriores. Por exemplo, os modelos de linguagem autorregressivos preveem o próximo token com base nos tokens previstos anteriormente. Todos os modelos de linguagem grandes baseados em Transformer são autorregressivos.
Por outro lado, os modelos de imagem baseados em GAN geralmente não são autorregressivos, porque geram uma imagem em uma única passagem direta e não de maneira iterativa em etapas. No entanto, alguns modelos de geração de imagens são autorregressivos porque geram uma imagem em etapas.
B
saco de palavras
Uma representação das palavras de uma frase ou passagem, independentemente da ordem. Por exemplo, o saco de palavras representa as três frases a seguir de maneira idêntica:
- o cachorro pula
- pula o cachorro
- cachorro pulando
Cada palavra é mapeada para um índice em um vetor esparso, em que o vetor tem um índice para cada palavra do vocabulário. Por exemplo, a frase o cachorro pula é mapeada em um vetor de recurso com valores diferentes de zero nos três índices correspondentes às palavras o, cachorro e pulos. O valor diferente de zero pode ser qualquer um dos seguintes:
- Um número 1 para indicar a presença de uma palavra.
- A contagem do número de vezes que uma palavra aparece no saco. Por exemplo, se a frase fosse o cão bordô é um cão com pele marrom, tanto maroon quanto cão seriam representados como 2, enquanto as outras palavras seriam representadas como 1.
- Algum outro valor, como o logaritmo da contagem do número de vezes que uma palavra aparece no saco.
Representações de codificador bidirecional dos transformadores (BERT, na sigla em inglês)
Uma arquitetura de modelo para representação de texto. Um modelo BERT treinado pode atuar como parte de um modelo maior para classificação de texto ou outras tarefas de ML.
O BERT tem as seguintes características:
- Usa a arquitetura de Transformer e, portanto, depende da autoatenção.
- Usa a parte de codificador do transformador. A função dele é produzir boas representações de texto, e não executar uma tarefa específica, como classificação.
- É bidirecional.
- Usa mascaramento para o treinamento não supervisionado.
As variantes do BERT incluem:
Consulte Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing (em inglês) para ter uma visão geral do BERT.
bidirecional
Um termo usado para descrever um sistema que avalia o texto que antecede e segue uma seção de destino. Por outro lado, um sistema unidirecional avalia apenas o texto que antecede a seção de destino.
Por exemplo, considere um modelo de linguagem mascarada que precisa determinar as probabilidades da palavra ou das palavras que representam o sublinhado na pergunta a seguir:
Qual é o/a _____?
Um modelo de linguagem unidirecional precisaria basear as probabilidades apenas no contexto fornecido pelas palavras "O quê", "é" e "o". Por outro lado, um modelo de linguagem bidirecional também pode receber contexto de "com" e "você", o que pode ajudar o modelo a gerar previsões melhores.
um modelo de linguagem bidirecional
Um modelo de idioma que determina a probabilidade de que um determinado token esteja presente em um determinado local em um trecho de texto com base no texto anterior e seguinte.
bigrama
Um N-grama em que N=2.
BLEU (subestudo de avaliação bilíngue)
Uma pontuação entre 0,0 e 1,0, indicando a qualidade de uma tradução entre dois idiomas humanos (por exemplo, entre inglês e russo). Uma pontuação BLEU de 1,0 indica uma tradução perfeita, enquanto uma pontuação BLEU de 0,0 indica uma tradução ruim.
C
modelo de linguagem causal
Sinônimo de modelo de linguagem unidirecional.
Consulte o modelo de linguagem bidirecional para contrastar diferentes abordagens direcionais na modelagem de linguagem.
comandos de cadeia de pensamento
Uma técnica de engenharia de comando que incentiva um modelo de linguagem grande (LLM) para explicar o raciocínio passo a passo. Por exemplo, considere o comando a seguir, prestando atenção especial à segunda frase:
Quantas forças g um motorista experimentaria em um carro que vai de 0 a 90 milhas por hora em 7 segundos? Na resposta, mostre todos os cálculos relevantes.
A resposta do LLM provavelmente:
- Mostre uma sequência de fórmulas físicas, inserindo os valores 0, 60 e 7 nos locais adequados.
- Explique por que escolheu essas fórmulas e o que as diversas variáveis significam.
A solicitação de cadeia de pensamento força o LLM a realizar todos os cálculos, o que pode levar a uma resposta mais correta. Além disso, a solicitação de cadeia de pensamento permite que o usuário examine as etapas do LLM para determinar se a resposta faz sentido ou não.
análise do eleitorado
Dividir uma frase em estruturas gramaticais menores ("constituentes"). Uma parte posterior do sistema de ML, como um modelo de compreensão de linguagem natural, pode analisar os constituintes com mais facilidade do que a frase original. Por exemplo, considere a seguinte frase:
Meu amigo adotou dois gatos.
Um analisador de eleitores pode dividir essa frase nos dois constituintes a seguir:
- Meu amigo é um frase substantivo.
- adopted two cats é um verbo.
Esses constituintes podem ser subdivididos em constituintes menores. Por exemplo, o verbo
adotaram dois gatos
poderia ser subdividido em:
- adopted é um verbo.
- dois gatos é outro sintagma substantivo.
flor da falha
Uma sentença ou frase com um significado ambíguo. As flores de falhas apresentam um problema significativo na compreensão da linguagem natural. Por exemplo, o título Arranha-céu da fita vermelha é uma flor de falhas porque um modelo de PLN pode interpretar o título de maneira literal ou figura.
D
decodificador
Em geral, qualquer sistema de ML que converta uma representação processada, densa ou interna em uma representação mais bruta, esparsa ou externa.
Os decodificadores geralmente são um componente de um modelo maior, em que são frequentemente pareados a um codificador.
Nas tarefas sequência para sequência, um decodificador começa com o estado interno gerado pelo codificador para prever a próxima sequência.
Consulte Transformador para ver a definição de um decodificador na arquitetura do transformador.
removendo ruídos
Uma abordagem comum para o aprendizado autossupervisionado, em que:
A remoção de ruídos permite aprender com exemplos sem rótulos. O conjunto de dados original serve como destino ou rótulo e os dados com ruído como entrada.
Alguns modelos de linguagem mascarados usam a remoção de ruído da seguinte maneira:
- O ruído é adicionado artificialmente a uma frase sem rótulo mascarando alguns dos tokens.
- O modelo tenta prever os tokens originais.
solicitações diretas
Sinônimo de zero-shot prompting.
E
editar distância
Uma medida de como duas strings de texto são parecidas. Em machine learning, a edição de distância é útil porque é simples e fácil de calcular, além de ser uma maneira eficaz de comparar duas strings conhecidas por serem semelhantes ou encontrar strings semelhantes a uma determinada string.
Há várias definições de distância de edição, cada uma usando operações de string diferentes. Por exemplo, a distância de Levenshtein considera o menor número de operações de exclusão, inserção e substituição.
Por exemplo, a distância de Levenshtein entre as palavras "coração" e "dardos" é 3 porque as três edições a seguir são as menores mudanças para transformar uma palavra em outra:
- coração → deart (substitua "h" por "d")
- deart → dart (excluir "e")
- dart → darts (inserir "s")
camada de embedding
Uma camada escondida especial que é treinada em um recurso categórico de alta dimensão para aprender gradualmente um vetor de embedding de dimensão mais baixa. Uma camada de incorporação permite que uma rede neural treine com muito mais eficiência do que o treinamento apenas no atributo categórico de alta dimensão.
Por exemplo, a Terra atualmente aceita cerca de 73.000 espécies de árvores. Suponha
que espécies de árvores sejam um recurso no seu modelo, de modo que a camada de entrada
do modelo inclua um vetor one-hot de 73.000 elementos.
Por exemplo, talvez baobab fosse representado assim:

Uma matriz de 73 mil elementos é muito longa. Se você não adicionar uma camada de embedding ao modelo, o treinamento vai consumir muito tempo devido à multiplicação de 72.999 zeros. Talvez você escolha a camada de incorporação com 12 dimensões. Consequentemente, a camada de embedding vai aprender gradualmente um novo vetor de embedding para cada espécie de árvore.
Em determinadas situações, o hash é uma alternativa razoável a uma camada de embedding.
espaço de embedding
O espaço vetorial d-dimensional com o qual elementos de um espaço vetorial de dimensão superior é mapeado. O ideal é que o espaço de embedding contenha uma estrutura que produza resultados matemáticos significativos. Por exemplo, em um espaço de embedding ideal, a adição e subtração de embeddings pode resolver tarefas de analogia de palavras.
O produto ponto de dois embeddings é uma medida da semelhança.
vetor de embedding
De modo geral, uma matriz de números de ponto flutuante retirados de qualquer camada escondida que descrevem as entradas para essa camada escondida. Muitas vezes, um vetor de embedding é a matriz de números de ponto flutuante treinados em uma camada de embedding. Por exemplo, suponha que uma camada de embedding precise aprender um vetor de incorporação para cada uma das 73 mil espécies de árvores da Terra. Talvez a matriz a seguir seja o vetor de embedding de uma árvore de baobab:

Um vetor de embedding não é composto por vários números aleatórios. Uma camada de embedding determina esses valores por treinamento, de maneira semelhante à maneira como uma rede neural aprende outros pesos durante o treinamento. Cada elemento da matriz é uma classificação ao longo de algumas características de uma espécie de árvore. Qual elemento representa a característica de quais espécies de árvores? Isso é muito difícil para os humanos determinar.
A parte matematicamente notável de um vetor de embedding é que itens semelhantes têm conjuntos semelhantes de números de ponto flutuante. Por exemplo, espécies de árvores semelhantes têm um conjunto mais semelhante de números de ponto flutuante do que espécies de árvores diferentes. As sequoias e as sequoias são espécies de árvores relacionadas, portanto, elas apresentam um conjunto de números flutuantes mais semelhantes do que as sequoias e os coqueiros. Os números no vetor de embedding mudam sempre que você treina o modelo novamente, mesmo que com uma entrada idêntica.
codificador
Em geral, qualquer sistema de ML que converta de uma representação bruta, esparsa ou externa em uma representação mais processada, mais densa ou mais interna.
Os codificadores geralmente são um componente de um modelo maior, em que são frequentemente pareados a um decodificador. Alguns Transformers paream codificadores com decodificadores, mas outros transformadores usam apenas o codificador ou apenas o decodificador.
Alguns sistemas usam a saída do codificador como entrada para uma rede de classificação ou regressão.
Em tarefas sequência para sequência, um codificador usa uma sequência de entrada e retorna um estado interno (um vetor). Em seguida, o decodificador usa esse estado interno para prever a próxima sequência.
Consulte Transformador para ver a definição de um codificador na arquitetura do transformador.
F)
comando few shot
Uma solicitação que contém mais de um (alguns) exemplo que demonstram como o modelo de linguagem grande precisa responder. O prompt longo a seguir contém dois exemplos que mostram um modelo de linguagem grande como responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Reino Unido: GBP | Outro exemplo. |
| Índia: | A consulta real. |
A solicitação de poucas fotos geralmente produz resultados mais desejáveis do que a solicitação zero-shot e a solicitação única. No entanto, os prompts de few shot requerem um prompt mais longo.
A criação de prompts de few shot é uma forma de aprendizado de poucas imagens aplicada ao aprendizado baseado em comandos.
Violino
Uma biblioteca de configuração com foco em Python que define os valores de funções e classes sem código ou infraestrutura invasivos. No caso do Pax (e de outras bases de código de ML), essas funções e classes representam modelos e hiperparâmetros de treinamento.
O Fiddle supõe que as bases de código de machine learning normalmente são divididas em:
- O código da biblioteca, que define as camadas e os otimizadores.
- O código "cola" do conjunto de dados, que chama as bibliotecas e conecta tudo.
O Fiddle captura a estrutura de chamada do código agrupador de forma não avaliada e mutável.
ajuste
Um segundo passe de treinamento específico para a tarefa realizado em um modelo pré-treinado para refinar os parâmetros dele para um caso de uso específico. Por exemplo, a sequência de treinamento completa para alguns modelos de linguagem grandes é a seguinte:
- Pré-treinamento:treine um modelo de linguagem grande em um conjunto de dados geral vasto, como todas as páginas da Wikipédia em inglês.
- Ajuste:treine o modelo pré-treinado para executar uma tarefa específica, como responder a consultas médicas. Normalmente, o ajuste envolve centenas ou milhares de exemplos focados na tarefa específica.
Como outro exemplo, a sequência de treinamento completa para um modelo de imagem grande é a seguinte:
- Pré-treinamento:treine um modelo de imagem grande em um conjunto de dados geral vasto, como todas as imagens no Wikimedia commons.
- Ajuste:treine o modelo pré-treinado para executar uma tarefa específica, como gerar imagens de orcas.
O ajuste pode envolver qualquer combinação das seguintes estratégias:
- Modificar todos os parâmetros existentes do modelo pré-treinado. Às vezes, isso é chamado de ajuste completo.
- Modificar apenas alguns dos parâmetros atuais do modelo pré-treinado (geralmente as camadas mais próximas da camada de saída), mantendo outros parâmetros inalterados (normalmente, as camadas mais próximas à camada de entrada). Consulte ajuste da eficiência de parâmetros.
- Adição de mais camadas, normalmente sobre as camadas existentes mais próximas da camada de saída.
O ajuste é uma forma de aprendizado por transferência. Assim, o ajuste pode usar uma função de perda ou um tipo de modelo diferentes dos usados para treinar o modelo pré-treinado. Por exemplo, é possível ajustar um modelo de imagem grande pré-treinado para produzir um modelo de regressão que retorne o número de pássaros em uma imagem de entrada.
Compare e contraste o ajuste com os seguintes termos:
Linho
Uma biblioteca de código aberto e alto desempenho para aprendizado profundo baseada no JAX. O Flax fornece funções para treinamento de redes neurais, bem como métodos para avaliar o desempenho delas.
Flaxformador
Uma biblioteca de código aberto Transformer, criada no Flax, projetada principalmente para processamento de linguagem natural e pesquisa multimodal.
G
a IA generativa
Um campo transformador emergente sem definição formal. Dito isso, a maioria dos especialistas concorda que os modelos de IA generativa podem criar ("gerar") conteúdo que seja:
- complexo
- coerentes
- original
Por exemplo, um modelo de IA generativa pode criar ensaios ou imagens sofisticadas.
Algumas tecnologias anteriores, incluindo LSTMs e RNNs, também podem gerar conteúdo original e coerente. Alguns especialistas veem essas tecnologias anteriores como IA generativa, enquanto outros acreditam que a verdadeira IA generativa exige um resultado mais complexo do que as tecnologias anteriores podem produzir.
Contraste com o ML preditivo.
GPT (transformador pré-treinado generativo)
Uma família de modelos de linguagem grandes baseados em Transformer (em inglês) desenvolvidos pela OpenAI.
As variantes da GPT podem ser aplicadas a várias modalidades, incluindo:
- geração de imagens (por exemplo, ImageGPT)
- de texto para imagem (por exemplo, DALL-E).
H
alucinação
A produção de resultados que parecem plausíveis, mas na verdade, incorretos, por um modelo de IA generativa que alega fazer uma declaração sobre o mundo real. Por exemplo, um modelo de IA generativa que alega que Barack Obama morreu em 1865 está alucinante.
I
aprendizado em contexto
Sinônimo de few-shot prompting.
L
LaMDA (modelo de linguagem para aplicativos de diálogo)
Um modelo de linguagem grande baseado em Transformer, desenvolvido pelo Google e treinado em um grande conjunto de dados de diálogos que pode gerar respostas de conversação realistas.
No artigo LaMDA: nossa tecnologia de conversação inovadora, você tem uma visão geral.
de linguagem grande
Um model que estima a probabilidade de um model ou sequência de tokens que ocorrem em uma sequência mais longa.
modelo de linguagem grande
Um termo informal sem definição estrita que geralmente significa um modelo de linguagem com um alto número de parâmetros. Alguns modelos de linguagem grandes contêm mais de 100 bilhões de parâmetros.
M
modelo de linguagem mascarada
Um modelo de linguagem que prevê a probabilidade de tokens candidatos preencherem espaços em branco em uma sequência. Por exemplo, um modelo de linguagem mascarado pode calcular as probabilidades de que a(s) palavra(s) candidata(s) substitua(m) o sublinhado na seguinte frase:
O(a) ____ no chapéu voltou.
Normalmente, a literatura usa a string "MASK" em vez de um sublinhado. Exemplo:
A "MÁSCARA" no chapéu voltou.
A maioria dos modelos modernos de linguagem mascarada é bidirecional.
metaaprendizado
Um subconjunto de machine learning que descobre ou melhora um algoritmo de aprendizado. Um sistema de metaaprendizado também pode ter como objetivo treinar um modelo para aprender rapidamente uma nova tarefa com uma pequena quantidade de dados ou com a experiência adquirida em tarefas anteriores. Os algoritmos de metaaprendizado geralmente tentam:
- Melhore/aprenda recursos criados manualmente (como um inicializador ou um otimizador).
- ser mais eficiente em termos de dados e computação;
- Melhorar a generalização.
O metaaprendizado está relacionado ao few-shot learning.
modality
Uma categoria de dados de alto nível. Por exemplo, números, texto, imagens, vídeo e áudio são cinco modalidades diferentes.
paralelismo de modelos
Uma maneira de escalonar o treinamento ou a inferência que coloca partes diferentes de um model em diferentes model. O paralelismo de modelos permite modelos grandes demais para caber em um único dispositivo.
Para implementar o paralelismo de modelos, um sistema normalmente faz o seguinte:
- Fragmenta (divide) o modelo em partes menores.
- Distribui o treinamento dessas partes menores em vários processadores. Cada processador treina a própria parte do modelo.
- Combina os resultados para criar um único modelo.
O paralelismo de modelos atrasa o treinamento.
Veja também paralelismo de dados.
autoatenção com várias cabeças
Uma extensão de autoatenção que aplica o mecanismo de autoatenção várias vezes para cada posição na sequência de entrada.
A Transformers introduziu a autoatenção de várias cabeças.
modelo multimodal
Um modelo com entradas e/ou saídas que incluem mais de uma modalidade. Por exemplo, considere um modelo que usa uma imagem e uma legenda de texto (duas modalidades) como recursos e gera uma pontuação indicando o grau de adequação da legenda de texto para a imagem. Portanto, as entradas desse modelo são multimodais, e a saída é unimodal.
N
processamento de linguagem natural
Determinar as intenções de um usuário com base no que ele digitou ou disse. Por exemplo, um mecanismo de pesquisa usa processamento de linguagem natural para determinar o que o usuário está pesquisando com base no que digitou ou disse.
N-grama
Uma sequência ordenada de N palavras. Por exemplo, truly madly é um bloco de dois gramas. Como a ordem é relevante, loucamente, é um grama diferente do que realmente loucamente.
| N | Nomes desse tipo de grama N | Exemplos |
|---|---|---|
| 2 | bigrama ou 2-gramas | ir, ir para, almoçar, comer |
| 3 | trigrama ou 3-gramas | comeu demais, três ratinhos cegos, o sino toca |
| 4 | 4 gramas | andar no parque, poeira ao vento, o menino comeu lentilhas |
Muitos modelos de compreensão de linguagem natural dependem de N-gramas para prever a próxima palavra que o usuário vai digitar ou dizer. Por exemplo, suponha que um usuário tenha digitado três cegas. Um modelo de PLN baseado em trigramas provavelmente preveria que o usuário digitaria ratos em seguida.
Contraste N-gramas com saco de palavras, que são conjuntos não ordenados de palavras.
PLN
Abreviação de compreensão de linguagem natural.
O
criação de comando one-shot
Um prompt com um exemplo que demonstra como o modelo de linguagem grande deve responder. Na solicitação a seguir, há um exemplo que mostra um modelo de linguagem grande para responder a uma consulta.
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| França: EUR | Um exemplo. |
| Índia: | A consulta real. |
Compare e contraste a solicitação de comando único com os seguintes termos:
P
ajuste de eficiência de parâmetros
Um conjunto de técnicas para ajustar um grande modelo de linguagem pré-treinado com mais eficiência do que o ajuste completo. O ajuste da eficiência de parâmetros normalmente ajusta muito menos parâmetros do que o ajuste completo. No entanto, geralmente produz um modelo de linguagem grande que tem um desempenho tão bom (ou quase tão bom) quanto um modelo de linguagem grande criado com base em um ajuste completo.
Compare e contraste o ajuste da eficiência de parâmetros com:
O ajuste da eficiência de parâmetros também é conhecido como ajuste da eficiência de parâmetros.
tubulação
Uma forma de paralelismo de modelos em que o processamento de um modelo é dividido em estágios consecutivos, e cada um deles é executado em um dispositivo diferente. Enquanto uma etapa está processando um lote, a anterior pode trabalhar no próximo.
Consulte também o treinamento gradual.
PLM
Abreviação de modelo de idioma pré-treinado (em inglês).
codificação posicional
Uma técnica para adicionar informações sobre a posição de um token em sequência ao incorporação dele. Os modelos de transformador usam a codificação de posicionamento para entender melhor a relação entre diferentes partes da sequência.
Uma implementação comum de codificação posicional usa uma função senoidal. Especificamente, a frequência e a amplitude da função senoidal são determinadas pela posição do token na sequência. Essa técnica permite que um modelo de transformador aprenda a atender a diferentes partes da sequência com base na posição delas.
pré-treinado
Modelos ou componentes do modelo (como um vetor de incorporação) que já foram treinados. Às vezes, você alimentará vetores de embedding pré-treinados em uma rede neural (link em inglês). Outras vezes, o modelo treinará os próprios vetores de embedding, em vez de depender de embeddings pré-treinados.
O termo modelo de linguagem pré-treinado se refere a um modelo de linguagem grande que passou por pré-treinamento.
pré-treinamento
Treinamento inicial de um modelo em um grande conjunto de dados. Alguns modelos pré-treinados são gigantes desajeitados e normalmente precisam ser refinados com outros treinamentos. Por exemplo, os especialistas em ML podem pré-treinar um modelo de linguagem grande em um vasto conjunto de dados de texto, como todas as páginas em inglês na Wikipédia. Após o pré-treinamento, o modelo resultante pode ser refinado ainda mais com qualquer uma destas técnicas:
prompt
Qualquer texto inserido como entrada em um modelo de linguagem grande para condicionar o modelo a se comportar de uma determinada maneira. As instruções podem ser curtas, como uma frase, ou arbitrariamente longas (por exemplo, o texto inteiro de um romance). As solicitações se enquadram em várias categorias, incluindo as mostradas na tabela abaixo:
| Categoria da solicitação | Exemplo | Observações |
|---|---|---|
| Pergunta | Qual é a velocidade de um pombo? | |
| Instrução | Escreva um poema engraçado sobre arbitragem. | Um prompt que pede ao modelo de linguagem grande para fazer algo. |
| Exemplo | Traduza o código Markdown para HTML. Por exemplo:
Markdown: * item de lista HTML: <ul> <li>item de lista</li> </ul> |
A primeira frase do prompt de exemplo é uma instrução. O restante do comando é o exemplo. |
| Papel | Explicar por que o gradiente descendente é usado no treinamento de machine learning até um PhD em física. | A primeira parte da frase é uma instrução. A frase "a um PhD em física" é a parte do papel. |
| Entrada parcial para o modelo concluir | O primeiro-ministro do Reino Unido mora em | Um prompt de entrada parcial pode terminar abruptamente (como no exemplo) ou com um sublinhado. |
Um modelo de IA generativa pode responder a um prompt com texto, código, imagens, embeddings, vídeos... quase qualquer coisa.
aprendizado baseado em comandos
Um recurso de determinados modelos que permite adaptar o comportamento em resposta a entradas arbitrárias de texto (solicitações). Em um paradigma típico de aprendizado baseado em prompt, um modelo de linguagem grande responde a um comando gerando texto. Por exemplo, suponha que um usuário insira o seguinte comando:
Resumir a terceira lei do movimento de Newton.
Um modelo capaz de aprendizado baseado em comandos não é treinado especificamente para responder à instrução anterior. Em vez disso, o modelo "sabe" muitos fatos sobre física, muitos sobre regras gerais de linguagem e muito sobre o que constitui respostas geralmente úteis. Esse conhecimento é suficiente para fornecer uma resposta (esperamos) útil. O feedback humano extra ("Essa resposta foi muito complicada" ou "O que é uma reação?") permite que alguns sistemas de aprendizado baseados em comandos melhorem gradualmente a utilidade das respostas.
design de comandos
Sinônimo de prompt Engineering (engenharia de comando).
engenharia de prompts
A arte de criar solicitações que recebem as respostas desejadas de um modelo de linguagem grande. Os humanos realizam a engenharia de prompts. Escrever prompts bem estruturados é uma parte essencial para garantir respostas úteis de um modelo de linguagem grande. A engenharia de prompts depende de muitos fatores, incluindo:
- O conjunto de dados usado para pré-treinar e possivelmente ajustar o modelo de linguagem grande.
- A temperatura e outros parâmetros de decodificação que o modelo usa para gerar respostas.
Consulte Introdução ao design de comandos para saber mais sobre como criar comandos úteis.
Design de prompts é um sinônimo de engenharia de prompts.
ajuste de prompts
Um mecanismo de ajuste de parâmetro eficiente que aprende um "prefixo" anexado pelo sistema ao prompt real.
Uma variação do ajuste de prompts, às vezes chamado de ajuste de prefixo, é inserir o prefixo em todas as camadas. Por outro lado, a maioria do ajuste de prompts só adiciona um prefixo à camada de entrada.
R
solicitação de papéis
Uma parte opcional de uma solicitação que identifica um público-alvo para a resposta de um modelo de IA generativa. Sem um prompt de papel, um modelo de linguagem grande fornece uma resposta que pode ou não ser útil para a pessoa que faz as perguntas. Com um prompt de papel, um modelo de linguagem grande pode responder de uma maneira mais adequada e mais útil para um público-alvo específico. Por exemplo, a parte do prompt de papel das seguintes solicitações está em negrito:
- Resuma este artigo sobre um PhD em economia.
- Descreva como as marés funcionam para uma criança de 10 anos.
- Explicar a crise financeira de 2008. Fale como você fala com uma criança ou um golden retriever.
S
autoatenção (também chamada de camada de autoatenção)
Uma camada de rede neural que transforma uma sequência de embeddings, por exemplo, token em outra sequência de embeddings. Cada embedding na sequência de saída é construído integrando informações dos elementos da sequência de entrada por meio de um mecanismo de atenção.
A parte próprio da autoatenção se refere à sequência que responde a si em vez de algum outro contexto. A autoatenção é um dos principais elementos básicos dos Transformers e usa a terminologia de pesquisa de dicionário, como "consulta", "chave" e "valor".
Uma camada de autoatenção começa com uma sequência de representações de entrada, uma para cada palavra. A representação de entrada de uma palavra pode ser uma incorporação simples. Para cada palavra em uma sequência de entrada, a rede pontua a relevância da palavra para todos os elementos na sequência inteira de palavras. As pontuações de relevância determinam o quanto a representação final da palavra incorpora as representações de outras palavras.
Por exemplo, considere a seguinte frase:
O animal não atravessou a rua porque estava muito cansado.
A ilustração a seguir (de Transformer: A Novel Neural Network Architecture for Language Understanding, em inglês) mostra o padrão de atenção de uma camada de autoatenção para o pronome it, com a escuridão de cada linha indicando quanto cada palavra contribui para a representação:
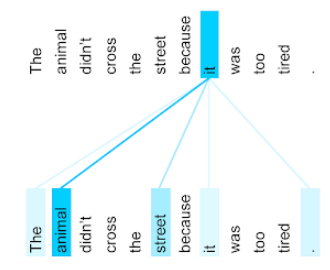
A camada de autoatenção destaca as palavras que são relevantes para "ele". Nesse caso, a camada de atenção aprendeu a destacar as palavras que ela pode se referir, atribuindo o peso mais alto a animal.
Para uma sequência de n tokens, a autoatenção transforma uma sequência de embeddings n vezes diferentes, uma vez em cada posição na sequência.
Consulte também atenção e autoatenção de várias cabeças.
análise de sentimento
Usar algoritmos estatísticos ou de aprendizado de máquina para determinar a atitude geral de um grupo (positiva ou negativa) em relação a um serviço, produto, organização ou tópico. Por exemplo, usando conhecimento de linguagem natural, um algoritmo pode realizar uma análise de sentimento no feedback textual de um curso universitário para determinar o grau de aceitação dos alunos que geralmente gostaram ou não do curso.
tarefa sequência para sequência
Uma tarefa que converte uma sequência de entrada de tokens em uma sequência de saída de tokens. Por exemplo, dois tipos conhecidos de tarefas sequência para sequência são:
- Tradutores:
- Exemplo de sequência de entrada: "Eu te amo".
- Exemplo de sequência de saída: "Je t'aime".
- Resposta a perguntas:
- Exemplo de sequência de entrada: "Preciso do meu carro em Nova York?"
- Exemplo de sequência de saída: "Não. Mantenha o carro em casa".
atributo esparso
Um elemento com valores predominantemente zero ou vazios. Por exemplo, um recurso que contém um único valor 1 e um milhão de valores 0 é esparso. Por outro lado, um recurso denso tem valores predominantemente não zero ou vazios.
Em machine learning, um número surpreendente de atributos é esparso. Geralmente, os atributos categóricos são esparsos. Por exemplo, das 300 espécies de árvores possíveis em uma floresta, um único exemplo pode identificar apenas uma árvore de bordo. Ou, dos milhões de vídeos possíveis em uma biblioteca, um único exemplo poderia identificar apenas "Casablanca".
Em um modelo, você normalmente representa recursos esparsos com codificação one-hot. Se a codificação one-hot for grande, coloque uma camada de incorporação sobre a codificação one-hot para maior eficiência.
representação esparsa
Armazenar apenas as posições de elementos diferentes de zero em um atributo esparso.
Por exemplo, suponha que um recurso categórico chamado species identifique as 36 espécies de árvores em uma floresta específica. Considere também que cada
exemplo identifica apenas uma espécie.
Você pode usar um vetor one-hot para representar as espécies de árvores em cada exemplo.
Um vetor one-hot contém uma única 1 (para representar
a espécie de árvore específica neste exemplo) e 35 0s (para representar as
35 espécies de árvores não nesse exemplo). Portanto, a representação one-hot
de maple pode ser parecida com esta:

Como alternativa, a representação esparsa simplesmente identificaria a posição de uma determinada espécie. Se maple estiver na posição 24, a representação esparsa
de maple será simplesmente:
24
Observe que a representação esparsa é muito mais compacta do que a representação one-hot.
Clique no ícone para conferir um exemplo um pouco mais complexo.
Suponha que cada exemplo no seu modelo represente as palavras, mas não a ordem delas, em uma frase em inglês. O inglês consiste em cerca de 170.000 palavras. Portanto, o inglês é um atributo categórico com cerca de 170.000 elementos. A maioria das sentenças em inglês usa uma fração extremamente pequena dessas 170.000 palavras, de modo que o conjunto de palavras em um único exemplo é quase certamente dados esparsos.
Considere a seguinte frase:
My dog is a great dog
Você pode usar uma variante do vetor one-hot para representar as palavras desta frase. Nessa variante, várias células no vetor podem conter um valor diferente de zero. Além disso, nessa variante, uma célula pode conter um número inteiro diferente de um. Embora as palavras "meu", "é", "um" e "ótimo" apareçam apenas uma vez na frase, a palavra "cachorro" aparece duas vezes. O uso dessa variante de vetores one-hot para representar as palavras dessa frase resulta no seguinte vetor de 170.000 elementos:

Uma representação esparsa da mesma frase seria:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
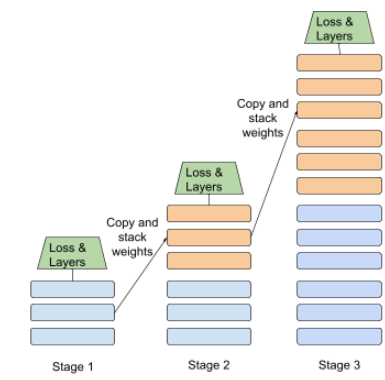
treinamento em etapas
Tática de treinar um modelo em uma sequência de etapas distintas. O objetivo pode ser acelerar o processo de treinamento ou melhorar a qualidade do modelo.
Uma ilustração da abordagem de empilhamento progressivo é mostrada abaixo:
- O estágio 1 contém três camadas escondidas, a 2 contém 6 camadas escondidas e a fase 3 contém 12 camadas ocultas.
- No estágio 2, o treinamento começa com os pesos aprendidos nas três camadas ocultas do estágio 1. O estágio 3 começa o treinamento com os pesos aprendidos nas seis camadas ocultas do estágio 2.
Consulte também pipelining.
T
T5
Um modelo de aprendizado por transferência de texto para texto lançado pela IA do Google em 2020. T5 é um modelo de codificador-decodificador baseado na arquitetura Transformer, treinado em um conjunto de dados extremamente grande. Ele é eficaz em uma variedade de tarefas de processamento de linguagem natural, como gerar texto, traduzir idiomas e responder perguntas de maneira conversacional.
O nome T5 vem dos cinco "Ts" do "Transformer de transferência de texto para texto".
Conexão T5X
Um framework de aprendizado de máquina de código aberto projetado para criar e treinar modelos de processamento de linguagem natural (PLN) em grande escala. A T5 é implementada na base de código do T5X, criada com base no JAX e no Flax (links em inglês).
temperatura
Um hiperparâmetro que controla o grau de aleatoriedade da saída de um modelo. Temperaturas mais altas resultam em uma saída mais aleatória, enquanto temperaturas mais baixas resultam em menos saídas aleatórias.
A escolha da melhor temperatura depende do aplicativo específico e das propriedades desejadas da saída do modelo. Por exemplo, você provavelmente aumentaria a temperatura ao criar um aplicativo que gera resultados criativos. Por outro lado, você provavelmente diminuiria a temperatura ao criar um modelo que classifica imagens ou texto para melhorar a precisão e consistência do modelo.
A temperatura geralmente é usada com o softmax (em inglês).
extensão do texto
O período do índice da matriz associado a uma subseção específica de uma string de texto.
Por exemplo, a palavra good na string do Python s="Be good now" ocupa
o período de texto de 3 a 6.
token
Em um modelo de linguagem, a unidade atômica em que o modelo está treinando e fazendo previsões. Um token geralmente é um destes:
- Uma palavra. Por exemplo, a frase "cães como gatos" consiste em três tokens de palavras: "cães", "gosto" e "gatos".
- um caractere. Por exemplo, a frase "peixe de bicicleta" consiste em nove tokens. O espaço em branco conta como um dos tokens.
- subpalavras, nas quais uma única palavra pode ser um único token ou vários. Uma subpalavra consiste em uma palavra raiz, um prefixo ou um sufixo. Por exemplo, um modelo de linguagem que usa subpalavras como tokens pode ver a palavra "cachorros" como dois tokens (a palavra raiz "cachorro" e o sufixo "s" no plural). Nesse mesmo modelo de idioma, a única palavra "mais alto" pode ser interpretada como duas subpalavras (a raiz "alto" e o sufixo "er").
Em domínios fora dos modelos de linguagem, os tokens podem representar outros tipos de unidades atômicas. Por exemplo, na visão computacional, um token pode ser um subconjunto de uma imagem.
Transformer
Uma arquitetura de rede neural desenvolvida no Google que depende de mecanismos de autoatenção para transformar uma sequência de embeddings de entrada em uma sequência de embeddings de saída sem depender de convoluções ou de redes neurais recorrentes. Um transformador pode ser visualizado como uma pilha de camadas de autoatenção.
Um transformador pode incluir qualquer uma das seguintes opções:
- Um codificador
- Um decodificador
- um codificador e um decodificador
Um codificador transforma uma sequência de embeddings em uma nova sequência do mesmo tamanho. Um codificador inclui N camadas idênticas, cada uma contendo duas subcamadas. Essas duas subcamadas são aplicadas em cada posição da sequência de embedding de entrada, transformando cada elemento da sequência em um novo embedding. A primeira subcamada de codificador agrega informações de toda a sequência de entrada. A segunda subcamada de codificador transforma as informações agregadas em um embedding de saída.
Um decodificador transforma uma sequência de embeddings de entrada em uma sequência de embeddings de saída, possivelmente com um comprimento diferente. Um decodificador também inclui N camadas idênticas com três subcamadas, duas das quais são semelhantes às subcamadas do codificador. A terceira subcamada de codificador recebe a saída do codificador e aplica o mecanismo de autoatenção para coletar informações dele.
A postagem do blog Transformer: uma nova arquitetura de rede neural para compreensão de linguagem (em inglês) apresenta uma boa introdução aos transformadores.
trigrama
Um N-grama em que N=3.
U
unidirecional
Um sistema que avalia somente o texto que antecede uma seção de destino. Por outro lado, um sistema bidirecional avalia o texto que antecede e segue uma seção de destino do texto. Consulte bidirecional para mais detalhes.
modelo de linguagem unidirecional
Um modelo de idioma que baseia as probabilidades apenas nos tokens que aparecem antes, e não depois dos tokens de destino. Contraste com o modelo de linguagem bidirecional.
V
codificador automático variacional (VAE, na sigla em inglês)
Um tipo de codificador automático que aproveita a discrepância entre entradas e saídas para gerar versões modificadas das entradas. Os codificadores automáticos variacionais são úteis para a IA generativa.
Os VAEs são baseados na inferência variacional: uma técnica para estimar os parâmetros de um modelo de probabilidade.
W
embedding de palavras
Representar cada palavra de um conjunto dentro de um vetor de incorporação, ou seja, representar cada palavra como um vetor de valores de ponto flutuante entre 0,0 e 1,0. Palavras com significados semelhantes têm representações mais semelhantes do que palavras com significados diferentes. Por exemplo, cenoura, acelery e pepino têm representações relativamente semelhantes, que são muito diferentes das representações de avião, óculos de sol e pasta de dentes.
Z
comando "zero-shot"
Uma solicitação que não forneça um exemplo de como você quer que o modelo de linguagem grande responda. Exemplo:
| Partes de um comando | Observações |
|---|---|
| Qual é a moeda oficial do país especificado? | A pergunta que você quer que o LLM responda. |
| Índia: | A consulta real. |
O modelo de linguagem grande pode responder com qualquer uma das seguintes opções:
- Rúpia
- INR
- ₹
- Rúpias indianas
- A rúpia
- A rúpia indiana
Todas as respostas estão corretas, embora você possa preferir um formato específico.
Compare e contraste a solicitação "zero-shot" com os seguintes termos: