এই পৃষ্ঠায় ভাষা মূল্যায়ন শব্দকোষ রয়েছে। সকল শব্দকোষের জন্য এখানে ক্লিক করুন ।
ক
মনোযোগ
একটি নিউরাল নেটওয়ার্কে ব্যবহৃত একটি প্রক্রিয়া যা একটি নির্দিষ্ট শব্দ বা শব্দের অংশের গুরুত্ব নির্দেশ করে। মনোযোগ একটি মডেলের পরবর্তী টোকেন/শব্দের পূর্বাভাস দিতে প্রয়োজনীয় তথ্যের পরিমাণ সংকুচিত করে। একটি সাধারণ মনোযোগ প্রক্রিয়া ইনপুটগুলির একটি সেটের উপর একটি ওজনযুক্ত যোগফল নিয়ে গঠিত হতে পারে, যেখানে প্রতিটি ইনপুটের ওজন নিউরাল নেটওয়ার্কের অন্য অংশ দ্বারা গণনা করা হয়।
স্ব-মনোযোগ এবং বহু-হেড স্ব-মনোযোগকেও উল্লেখ করুন, যা ট্রান্সফরমারের বিল্ডিং ব্লক।
অটোএনকোডার
একটি সিস্টেম যা ইনপুট থেকে সবচেয়ে গুরুত্বপূর্ণ তথ্য বের করতে শেখে। অটোএনকোডার হল একটি এনকোডার এবং ডিকোডারের সংমিশ্রণ। অটোএনকোডারগুলি নিম্নলিখিত দ্বি-পদক্ষেপ প্রক্রিয়ার উপর নির্ভর করে:
- এনকোডার ইনপুটকে একটি (সাধারণত) ক্ষতিকর নিম্ন-মাত্রিক (মধ্যবর্তী) বিন্যাসে ম্যাপ করে।
- ডিকোডার নিম্ন-মাত্রিক বিন্যাসটিকে মূল উচ্চ-মাত্রিক ইনপুট বিন্যাসে ম্যাপ করে মূল ইনপুটের একটি ক্ষতিকারক সংস্করণ তৈরি করে।
এনকোডারের মধ্যবর্তী বিন্যাস থেকে যতটা সম্ভব ঘনিষ্ঠভাবে মূল ইনপুট পুনর্গঠন করার জন্য ডিকোডার প্রচেষ্টার মাধ্যমে অটোএনকোডারদের এন্ড-টু-এন্ড প্রশিক্ষিত করা হয়। মধ্যবর্তী বিন্যাসটি মূল বিন্যাসের চেয়ে ছোট (নিম্ন-মাত্রিক) হওয়ায়, অটোএনকোডারকে ইনপুটে কোন তথ্য অপরিহার্য তা শিখতে বাধ্য করা হয় এবং আউটপুটটি ইনপুটের সাথে পুরোপুরি অভিন্ন হবে না।
উদাহরণ স্বরূপ:
- যদি ইনপুট ডেটা একটি গ্রাফিক হয়, অ-নির্ভুল অনুলিপিটি মূল গ্রাফিকের অনুরূপ হবে, তবে কিছুটা পরিবর্তিত হবে। সম্ভবত অ-নির্ভুল অনুলিপি মূল গ্রাফিক থেকে শব্দ সরিয়ে দেয় বা কিছু অনুপস্থিত পিক্সেল পূরণ করে।
- যদি ইনপুট ডেটা পাঠ্য হয় তবে একটি অটোএনকোডার নতুন পাঠ্য তৈরি করবে যা মূল পাঠ্যের অনুকরণ করে (কিন্তু অনুরূপ নয়)।
পরিবর্তনশীল অটোএনকোডারগুলিও দেখুন।
অটো রিগ্রেসিভ মডেল
একটি মডেল যা তার নিজের পূর্বের ভবিষ্যদ্বাণীগুলির উপর ভিত্তি করে একটি ভবিষ্যদ্বাণী অনুমান করে৷ উদাহরণস্বরূপ, অটো-রিগ্রেসিভ ল্যাঙ্গুয়েজ মডেলগুলি পূর্বে ভবিষ্যদ্বাণী করা টোকেনের উপর ভিত্তি করে পরবর্তী টোকেনের পূর্বাভাস দেয়। সমস্ত ট্রান্সফরমার -ভিত্তিক বৃহৎ ভাষার মডেলগুলি স্বয়ংক্রিয়-রিগ্রেসিভ।
বিপরীতে, GAN- ভিত্তিক ইমেজ মডেলগুলি সাধারণত অটো-রিগ্রেসিভ হয় না কারণ তারা একটি একক ফরোয়ার্ড-পাসে একটি ছবি তৈরি করে এবং ধাপে ধাপে নয়। যাইহোক, কিছু ইমেজ জেনারেশন মডেল অটো -রিগ্রেসিভ কারণ তারা ধাপে ধাপে একটি ইমেজ তৈরি করে।
খ
শব্দের ব্যাগ
ক্রম নির্বিশেষে একটি বাক্যাংশ বা প্যাসেজে শব্দের উপস্থাপনা। উদাহরণস্বরূপ, শব্দের ব্যাগ নিম্নলিখিত তিনটি বাক্যাংশকে অভিন্নভাবে উপস্থাপন করে:
- কুকুর লাফ দেয়
- কুকুর লাফিয়ে
- কুকুর লাফ দেয়
প্রতিটি শব্দ একটি স্পার্স ভেক্টরের একটি সূচকে ম্যাপ করা হয়, যেখানে ভেক্টরের শব্দভান্ডারের প্রতিটি শব্দের জন্য একটি সূচক থাকে। উদাহরণস্বরূপ, কুকুরের লাফানো শব্দগুচ্ছটি একটি বৈশিষ্ট্য ভেক্টরে ম্যাপ করা হয়েছে যা , কুকুর এবং লাফ শব্দের সাথে সম্পর্কিত তিনটি সূচকে অ-শূন্য মান সহ । অ-শূন্য মান নিম্নলিখিত যে কোনো হতে পারে:
- একটি শব্দের উপস্থিতি বোঝাতে একটি 1।
- ব্যাগে একটি শব্দ কতবার উপস্থিত হয় তার একটি গণনা। উদাহরণস্বরূপ, যদি বাক্যাংশটি মেরুন কুকুর মেরুন পশমযুক্ত একটি কুকুর হয় , তাহলে মেরুন এবং কুকুর উভয়কেই 2 হিসাবে উপস্থাপন করা হবে, অন্য শব্দগুলিকে 1 হিসাবে উপস্থাপন করা হবে।
- আরও কিছু মান, যেমন ব্যাগে একটি শব্দ কতবার উপস্থিত হয় তার সংখ্যার লগারিদম।
BERT (ট্রান্সফরমার থেকে দ্বিমুখী এনকোডার প্রতিনিধিত্ব)
পাঠ্য উপস্থাপনার জন্য একটি মডেল আর্কিটেকচার। একটি প্রশিক্ষিত BERT মডেল পাঠ্য শ্রেণিবিন্যাস বা অন্যান্য ML কাজের জন্য একটি বড় মডেলের অংশ হিসাবে কাজ করতে পারে।
BERT এর নিম্নলিখিত বৈশিষ্ট্য রয়েছে:
- ট্রান্সফরমার আর্কিটেকচার ব্যবহার করে, এবং তাই স্ব-মনোযোগের উপর নির্ভর করে।
- ট্রান্সফরমারের এনকোডার অংশ ব্যবহার করে। এনকোডারের কাজ হল শ্রেণীবিভাগের মতো একটি নির্দিষ্ট কাজ সম্পাদন করার পরিবর্তে ভাল পাঠ্য উপস্থাপনা তৈরি করা।
- দ্বিমুখী ।
- তত্ত্বাবধানহীন প্রশিক্ষণের জন্য মাস্কিং ব্যবহার করে।
BERT এর ভেরিয়েন্টগুলির মধ্যে রয়েছে:
দ্বিমুখী
এমন একটি শব্দ যা একটি সিস্টেমকে বর্ণনা করতে ব্যবহৃত হয় যা পাঠ্যের একটি লক্ষ্য বিভাগের পূর্ববর্তী এবং অনুসরণ করে এমন পাঠ্যকে মূল্যায়ন করে। বিপরীতে, একটি ইউনিডাইরেকশনাল সিস্টেম শুধুমাত্র পাঠ্যের একটি লক্ষ্য বিভাগের আগে থাকা পাঠ্যকে মূল্যায়ন করে।
উদাহরণস্বরূপ, একটি মুখোশযুক্ত ভাষা মডেল বিবেচনা করুন যা অবশ্যই নিম্নলিখিত প্রশ্নে আন্ডারলাইন প্রতিনিধিত্বকারী শব্দ বা শব্দগুলির সম্ভাব্যতা নির্ধারণ করবে:
আপনার সাথে _____ কি?
একটি একমুখী ভাষা মডেলকে শুধুমাত্র "কী", "is", এবং "the" শব্দ দ্বারা প্রদত্ত প্রেক্ষাপটের উপর ভিত্তি করে তার সম্ভাবনার ভিত্তি করতে হবে। বিপরীতে, একটি দ্বিমুখী ভাষা মডেল "সহ" এবং "আপনি" থেকে প্রসঙ্গ লাভ করতে পারে, যা মডেলটিকে আরও ভাল ভবিষ্যদ্বাণী তৈরি করতে সহায়তা করতে পারে।
দ্বিমুখী ভাষার মডেল
একটি ভাষা মডেল যা পূর্ববর্তী এবং পরবর্তী পাঠ্যের উপর ভিত্তি করে পাঠ্যের একটি উদ্ধৃতিতে একটি প্রদত্ত টোকেন একটি নির্দিষ্ট স্থানে উপস্থিত থাকার সম্ভাবনা নির্ধারণ করে।
বিগগ্রাম
একটি N-গ্রাম যার মধ্যে N=2।
BLEU (দ্বিভাষিক মূল্যায়ন আন্ডারস্টাডি)
0.0 এবং 1.0 এর মধ্যে একটি স্কোর, অন্তর্ভুক্ত, দুটি মানব ভাষার মধ্যে একটি অনুবাদের গুণমান নির্দেশ করে (উদাহরণস্বরূপ, ইংরেজি এবং রাশিয়ান মধ্যে)। 1.0 এর একটি BLEU স্কোর একটি নিখুঁত অনুবাদ নির্দেশ করে; একটি BLEU স্কোর 0.0 একটি ভয়ানক অনুবাদ নির্দেশ করে।
গ
কার্যকারণ ভাষা মডেল
একমুখী ভাষা মডেলের প্রতিশব্দ।
ভাষা মডেলিংয়ে বিভিন্ন দিকনির্দেশক পদ্ধতির বিপরীতে দ্বিমুখী ভাষার মডেল দেখুন।
চেইন-অফ-থট প্রম্পটিং
একটি প্রম্পট ইঞ্জিনিয়ারিং কৌশল যা একটি বৃহৎ ভাষা মডেল (LLM) কে ধাপে ধাপে তার যুক্তি ব্যাখ্যা করতে উৎসাহিত করে। উদাহরণস্বরূপ, দ্বিতীয় বাক্যে বিশেষ মনোযোগ দিয়ে নিম্নলিখিত প্রম্পটটি বিবেচনা করুন:
7 সেকেন্ডে প্রতি ঘন্টায় 0 থেকে 60 মাইল বেগে যাওয়া গাড়িতে একজন চালক কতটি জি ফোর্স অনুভব করবে? উত্তরে, সমস্ত প্রাসঙ্গিক গণনা দেখান।
এলএলএম এর প্রতিক্রিয়া সম্ভবত:
- উপযুক্ত স্থানে 0, 60, এবং 7 মান প্লাগ করে পদার্থবিজ্ঞানের সূত্রের একটি ক্রম দেখান।
- ব্যাখ্যা করুন কেন এটি সেই সূত্রগুলি বেছে নিয়েছে এবং বিভিন্ন ভেরিয়েবলের অর্থ কী।
চেইন-অফ-থট প্রম্পটিং এলএলএমকে সমস্ত গণনা সম্পাদন করতে বাধ্য করে, যা আরও সঠিক উত্তরের দিকে নিয়ে যেতে পারে। উপরন্তু, চেইন-অফ-থট প্রম্পটিং ব্যবহারকারীকে LLM-এর পদক্ষেপগুলি পরীক্ষা করতে সক্ষম করে উত্তরটি অর্থপূর্ণ কিনা তা নির্ধারণ করতে।
নির্বাচনী এলাকা পার্সিং
একটি বাক্যকে ছোট ব্যাকরণগত কাঠামোতে বিভক্ত করা ("নির্ধারক")। ML সিস্টেমের একটি পরবর্তী অংশ, যেমন একটি প্রাকৃতিক ভাষা বোঝার মডেল, মূল বাক্যের চেয়ে উপাদানগুলিকে আরও সহজে পার্স করতে পারে। উদাহরণস্বরূপ, নিম্নলিখিত বাক্যটি বিবেচনা করুন:
আমার বন্ধু দুটি বিড়াল দত্তক.
একজন নির্বাচনী পার্সার এই বাক্যটিকে নিম্নলিখিত দুটি উপাদানে ভাগ করতে পারেন:
- আমার বন্ধু একটি বিশেষ্য বাক্যাংশ।
- গৃহীত দুই বিড়াল একটি ক্রিয়া বাক্যাংশ।
এই উপাদানগুলিকে আরও ছোট উপাদানগুলিতে বিভক্ত করা যেতে পারে। উদাহরণস্বরূপ, ক্রিয়াপদ বাক্যাংশ
দুটি বিড়াল দত্তক
আরও উপবিভক্ত করা যেতে পারে:
- গৃহীত একটি ক্রিয়া।
- দুটি বিড়াল আরেকটি বিশেষ্য বাক্যাংশ।
ক্র্যাশ ব্লসম
একটি অস্পষ্ট অর্থ সহ একটি বাক্য বা বাক্যাংশ। ক্র্যাশ ফুল প্রাকৃতিক ভাষা বোঝার ক্ষেত্রে একটি উল্লেখযোগ্য সমস্যা উপস্থাপন করে। উদাহরণস্বরূপ, শিরোনাম রেড টেপ হোল্ডস আপ স্কাইস্ক্র্যাপার একটি ক্র্যাশ ব্লসম কারণ একটি NLU মডেল শিরোনামটিকে আক্ষরিক বা রূপকভাবে ব্যাখ্যা করতে পারে।
ডি
ডিকোডার
সাধারণভাবে, যে কোনো ML সিস্টেম যা একটি প্রক্রিয়াকৃত, ঘন বা অভ্যন্তরীণ উপস্থাপনা থেকে আরও কাঁচা, বিক্ষিপ্ত বা বাহ্যিক উপস্থাপনায় রূপান্তরিত হয়।
ডিকোডারগুলি প্রায়শই একটি বড় মডেলের একটি উপাদান, যেখানে তারা প্রায়শই একটি এনকোডারের সাথে যুক্ত হয়।
সিকোয়েন্স-টু-সিকোয়েন্স কাজগুলিতে , একটি ডিকোডার পরবর্তী ক্রম অনুমান করার জন্য এনকোডার দ্বারা তৈরি অভ্যন্তরীণ অবস্থা দিয়ে শুরু হয়।
ট্রান্সফরমার আর্কিটেকচারের মধ্যে একটি ডিকোডারের সংজ্ঞার জন্য ট্রান্সফরমার পড়ুন।
denoising
স্ব-তত্ত্বাবধানে শিক্ষার একটি সাধারণ পদ্ধতি যার মধ্যে:
Denoising লেবেলবিহীন উদাহরণ থেকে শেখার সক্ষম করে। মূল ডেটাসেট লক্ষ্য বা লেবেল হিসাবে কাজ করে এবং কোলাহলপূর্ণ ডেটা ইনপুট হিসাবে কাজ করে।
কিছু মুখোশযুক্ত ভাষা মডেল নিম্নরূপ denoising ব্যবহার করে:
- কিছু টোকেন মাস্ক করে লেবেলবিহীন বাক্যে কৃত্রিমভাবে নয়েজ যোগ করা হয়।
- মডেল মূল টোকেন ভবিষ্যদ্বাণী করার চেষ্টা করে।
সরাসরি প্রম্পটিং
জিরো-শট প্রম্পটিং- এর প্রতিশব্দ।
ই
দূরত্ব সম্পাদনা করুন
দুটি টেক্সট স্ট্রিং একে অপরের সাথে কতটা অনুরূপ তার একটি পরিমাপ। মেশিন লার্নিং-এ, দূরত্ব সম্পাদনা করা উপযোগী কারণ এটি সহজ এবং গণনা করা সহজ, এবং একটি কার্যকর উপায় যে দুটি স্ট্রিং একই রকম বলে পরিচিত অথবা একটি প্রদত্ত স্ট্রিং-এর অনুরূপ স্ট্রিং খুঁজে বের করার জন্য।
সম্পাদনা দূরত্বের বেশ কয়েকটি সংজ্ঞা রয়েছে, প্রতিটি ভিন্ন স্ট্রিং অপারেশন ব্যবহার করে। উদাহরণস্বরূপ, Levenshtein দূরত্ব সবচেয়ে কম মুছে ফেলা, সন্নিবেশ করা এবং বিকল্প ক্রিয়াকলাপ বিবেচনা করে।
উদাহরণস্বরূপ, "হার্ট" এবং "ডার্টস" শব্দের মধ্যে লেভেনশটাইনের দূরত্ব হল 3 কারণ নিম্নলিখিত 3টি সম্পাদনা হল একটি শব্দকে অন্য শব্দে পরিণত করার জন্য সবচেয়ে কম পরিবর্তন:
- হৃদয় → deart ("h" এর পরিবর্তে "d")
- deart → ডার্ট ("e" মুছুন)
- ডার্ট → ডার্টস ("s" ঢোকান)
এম্বেডিং স্তর
একটি বিশেষ লুকানো স্তর যা একটি উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণ দেয় যা ধীরে ধীরে একটি নিম্ন মাত্রার এম্বেডিং ভেক্টর শিখতে পারে। একটি এম্বেডিং স্তর একটি নিউরাল নেটওয়ার্ককে শুধুমাত্র উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণের চেয়ে অনেক বেশি দক্ষতার সাথে প্রশিক্ষণ দিতে সক্ষম করে।
উদাহরণস্বরূপ, পৃথিবী বর্তমানে প্রায় 73,000 গাছের প্রজাতিকে সমর্থন করে। ধরুন গাছের প্রজাতি আপনার মডেলের একটি বৈশিষ্ট্য , তাই আপনার মডেলের ইনপুট স্তরে একটি এক-হট ভেক্টর 73,000 উপাদান রয়েছে। উদাহরণস্বরূপ, সম্ভবত baobab এই মত কিছু প্রতিনিধিত্ব করা হবে:

একটি 73,000-এলিমেন্ট অ্যারে খুব দীর্ঘ। আপনি যদি মডেলটিতে একটি এম্বেডিং স্তর যোগ না করেন, তাহলে 72,999 শূন্য গুণ করার কারণে প্রশিক্ষণটি খুব সময়সাপেক্ষ হতে চলেছে। সম্ভবত আপনি 12টি মাত্রা সমন্বিত করার জন্য এম্বেডিং স্তরটি বেছে নিন। ফলস্বরূপ, এম্বেডিং স্তরটি ধীরে ধীরে প্রতিটি গাছের প্রজাতির জন্য একটি নতুন এমবেডিং ভেক্টর শিখবে।
কিছু পরিস্থিতিতে, হ্যাশিং একটি এম্বেডিং স্তরের একটি যুক্তিসঙ্গত বিকল্প।
এম্বেডিং স্থান
উচ্চ-মাত্রিক ভেক্টর স্থান থেকে বৈশিষ্ট্যযুক্ত ডি-ডাইমেনশনাল ভেক্টর স্পেস ম্যাপ করা হয়। আদর্শভাবে, এমবেডিং স্পেস এমন একটি কাঠামো ধারণ করে যা অর্থপূর্ণ গাণিতিক ফলাফল দেয়; উদাহরণস্বরূপ, একটি আদর্শ এম্বেডিং স্পেসে, এম্বেডিংয়ের যোগ এবং বিয়োগ শব্দের সাদৃশ্যের কাজগুলি সমাধান করতে পারে।
দুটি এমবেডিংয়ের ডট পণ্য তাদের সাদৃশ্যের একটি পরিমাপ।
এম্বেডিং ভেক্টর
বিস্তৃতভাবে বলতে গেলে, কোনো লুকানো স্তর থেকে নেওয়া ফ্লোটিং-পয়েন্ট সংখ্যার একটি অ্যারে যা সেই লুকানো স্তরের ইনপুটগুলিকে বর্ণনা করে। প্রায়শই, একটি এমবেডিং ভেক্টর হল একটি এমবেডিং স্তরে প্রশিক্ষিত ফ্লোটিং-পয়েন্ট সংখ্যার অ্যারে। উদাহরণস্বরূপ, ধরুন একটি এম্বেডিং স্তরকে অবশ্যই পৃথিবীতে 73,000টি গাছের প্রজাতির জন্য একটি এমবেডিং ভেক্টর শিখতে হবে। সম্ভবত নিম্নলিখিত অ্যারেটি একটি বাওবাব গাছের জন্য এমবেডিং ভেক্টর:

একটি এম্বেডিং ভেক্টর এলোমেলো সংখ্যার একটি গুচ্ছ নয়। একটি এমবেডিং স্তর প্রশিক্ষণের মাধ্যমে এই মানগুলি নির্ধারণ করে, যেভাবে একটি নিউরাল নেটওয়ার্ক প্রশিক্ষণের সময় অন্যান্য ওজন শেখে। অ্যারের প্রতিটি উপাদান একটি গাছের প্রজাতির কিছু বৈশিষ্ট্য বরাবর একটি রেটিং। কোন উপাদান কোন গাছের প্রজাতির বৈশিষ্ট্য উপস্থাপন করে? এটা মানুষের জন্য নির্ধারণ করা খুব কঠিন।
একটি এমবেডিং ভেক্টরের গাণিতিকভাবে উল্লেখযোগ্য অংশ হল যে অনুরূপ আইটেমগুলিতে ভাসমান-বিন্দু সংখ্যার অনুরূপ সেট রয়েছে। উদাহরণ স্বরূপ, অনুরূপ গাছের প্রজাতির ভিন্ন ভিন্ন বৃক্ষের প্রজাতির তুলনায় ভাসমান-বিন্দু সংখ্যার আরও অনুরূপ সেট রয়েছে। রেডউডস এবং সিকোইয়াস গাছের প্রজাতি সম্পর্কিত, তাই তাদের রেডউডস এবং নারকেল পামের তুলনায় ভাসমান-পয়েন্টিং সংখ্যার আরও অনুরূপ সেট থাকবে। এমবেডিং ভেক্টরের সংখ্যাগুলি আপনি প্রতিবার মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়ার সময় পরিবর্তিত হবে, এমনকি যদি আপনি অভিন্ন ইনপুট দিয়ে মডেলটিকে পুনরায় প্রশিক্ষণ দেন।
এনকোডার
সাধারণভাবে, যে কোনো ML সিস্টেম যা একটি কাঁচা, বিক্ষিপ্ত, বা বাহ্যিক উপস্থাপনা থেকে আরও প্রক্রিয়াকৃত, ঘন বা আরও অভ্যন্তরীণ উপস্থাপনায় রূপান্তরিত হয়।
এনকোডারগুলি প্রায়শই একটি বড় মডেলের একটি উপাদান, যেখানে তারা প্রায়শই একটি ডিকোডারের সাথে যুক্ত হয়। কিছু ট্রান্সফরমার ডিকোডারের সাথে এনকোডার যুক্ত করে, যদিও অন্যান্য ট্রান্সফরমার শুধুমাত্র এনকোডার বা শুধুমাত্র ডিকোডার ব্যবহার করে।
কিছু সিস্টেম শ্রেণীবিভাগ বা রিগ্রেশন নেটওয়ার্কে ইনপুট হিসাবে এনকোডারের আউটপুট ব্যবহার করে।
সিকোয়েন্স-টু-সিকোয়েন্স কাজগুলিতে , একটি এনকোডার একটি ইনপুট সিকোয়েন্স নেয় এবং একটি অভ্যন্তরীণ অবস্থা (একটি ভেক্টর) প্রদান করে। তারপর, ডিকোডার পরবর্তী ক্রম অনুমান করতে সেই অভ্যন্তরীণ অবস্থা ব্যবহার করে।
ট্রান্সফরমার আর্কিটেকচারে একটি এনকোডারের সংজ্ঞার জন্য ট্রান্সফরমার পড়ুন।
চ
কয়েক শট প্রম্পটিং
একটি প্রম্পট যাতে একাধিক (একটি "কয়েক") উদাহরণ রয়েছে যা প্রদর্শন করে যে কীভাবে বড় ভাষা মডেলের প্রতিক্রিয়া জানানো উচিত। উদাহরণস্বরূপ, নিম্নলিখিত দীর্ঘ প্রম্পটে দুটি উদাহরণ রয়েছে যা একটি বৃহৎ ভাষার মডেল দেখাচ্ছে কিভাবে একটি প্রশ্নের উত্তর দিতে হয়।
| এক প্রম্পটের অংশ | মন্তব্য |
|---|---|
| নির্দিষ্ট দেশের সরকারী মুদ্রা কি? | যে প্রশ্নটির উত্তর আপনি LLM করতে চান। |
| ফ্রান্স: EUR | একটি উদাহরণ. |
| যুক্তরাজ্য: জিবিপি | আরেকটি উদাহরণ. |
| ভারত: | প্রকৃত প্রশ্ন. |
কিছু-শট প্রম্পটিং সাধারণত জিরো-শট প্রম্পটিং এবং ওয়ান-শট প্রম্পটিংয়ের চেয়ে বেশি পছন্দসই ফলাফল দেয়। যাইহোক, অল্প-শট প্রম্পটিংয়ের জন্য একটি দীর্ঘ প্রম্পট প্রয়োজন।
ফিউ-শট প্রম্পটিং হল প্রম্পট-ভিত্তিক শিক্ষার জন্য প্রয়োগ করা কয়েক-শট লার্নিংয়ের একটি রূপ।
বেহালা
একটি পাইথন-প্রথম কনফিগারেশন লাইব্রেরি যা আক্রমণাত্মক কোড বা অবকাঠামো ছাড়াই ফাংশন এবং ক্লাসের মান সেট করে। প্যাক্স —এবং অন্যান্য ML কোডবেসের ক্ষেত্রে — এই ফাংশন এবং ক্লাসগুলি মডেল এবং প্রশিক্ষণ হাইপারপ্যারামিটারগুলিকে উপস্থাপন করে।
ফিডল অনুমান করে যে মেশিন লার্নিং কোডবেসগুলি সাধারণত বিভক্ত হয়:
- লাইব্রেরি কোড, যা স্তর এবং অপ্টিমাইজার সংজ্ঞায়িত করে।
- ডেটাসেট "আঠালো" কোড, যা লাইব্রেরিগুলিকে কল করে এবং সবকিছুকে একত্রিত করে।
ফিডল একটি অমূল্যায়িত এবং পরিবর্তনযোগ্য আকারে আঠালো কোডের কল কাঠামো ক্যাপচার করে।
ফাইন টিউনিং
একটি নির্দিষ্ট ব্যবহারের ক্ষেত্রে এর পরামিতিগুলিকে পরিমার্জিত করার জন্য একটি প্রাক-প্রশিক্ষিত মডেলে একটি দ্বিতীয়, টাস্ক-নির্দিষ্ট প্রশিক্ষণ পাস। উদাহরণস্বরূপ, কিছু বড় ভাষা মডেলের জন্য সম্পূর্ণ প্রশিক্ষণের ক্রম নিম্নরূপ:
- প্রাক-প্রশিক্ষণ: একটি বিশাল সাধারণ ডেটাসেটে একটি বৃহৎ ভাষার মডেলকে প্রশিক্ষণ দিন, যেমন সমস্ত ইংরেজি ভাষার উইকিপিডিয়া পৃষ্ঠা।
- ফাইন-টিউনিং: একটি নির্দিষ্ট কাজ করার জন্য প্রাক-প্রশিক্ষিত মডেলকে প্রশিক্ষণ দিন, যেমন মেডিকেল প্রশ্নের উত্তর দেওয়া। ফাইন-টিউনিংয়ে সাধারণত নির্দিষ্ট কাজের উপর দৃষ্টি নিবদ্ধ করে শত শত বা হাজার হাজার উদাহরণ জড়িত থাকে।
আরেকটি উদাহরণ হিসাবে, একটি বড় ইমেজ মডেলের জন্য সম্পূর্ণ প্রশিক্ষণের ক্রম নিম্নরূপ:
- প্রাক-প্রশিক্ষণ: একটি বিশাল সাধারণ ইমেজ ডেটাসেটে একটি বড় ইমেজ মডেলকে প্রশিক্ষণ দিন, যেমন উইকিমিডিয়া কমন্সের সমস্ত ছবি।
- ফাইন-টিউনিং: একটি নির্দিষ্ট কাজ সম্পাদন করার জন্য পূর্ব-প্রশিক্ষিত মডেলকে প্রশিক্ষণ দিন, যেমন অর্কাসের ছবি তৈরি করা।
ফাইন-টিউনিং নিম্নলিখিত কৌশলগুলির যেকোন সংমিশ্রণকে অন্তর্ভুক্ত করতে পারে:
- প্রাক-প্রশিক্ষিত মডেলের বিদ্যমান পরামিতিগুলির সমস্ত পরিবর্তন করা। একে কখনও কখনও ফুল ফাইন-টিউনিং বলা হয়।
- অন্যান্য বিদ্যমান পরামিতিগুলি অপরিবর্তিত রেখে (সাধারণত, ইনপুট স্তরের সবচেয়ে কাছের স্তরগুলি) রেখে শুধুমাত্র প্রাক-প্রশিক্ষিত মডেলের বিদ্যমান প্যারামিটারগুলির কিছু পরিবর্তন করা (সাধারণত, আউটপুট স্তরের নিকটতম স্তরগুলি)। প্যারামিটার-দক্ষ টিউনিং দেখুন।
- আরও স্তর যুক্ত করা হচ্ছে, সাধারণত আউটপুট স্তরের নিকটতম বিদ্যমান স্তরগুলির উপরে।
ফাইন-টিউনিং হল ট্রান্সফার লার্নিং এর একটি ফর্ম। যেমন, ফাইন-টিউনিং একটি ভিন্ন লস ফাংশন ব্যবহার করতে পারে বা প্রাক-প্রশিক্ষিত মডেলকে প্রশিক্ষিত করতে ব্যবহৃত মডেলের তুলনায় ভিন্ন মডেলের ধরন ব্যবহার করতে পারে। উদাহরণস্বরূপ, আপনি একটি রিগ্রেশন মডেল তৈরি করতে একটি প্রাক-প্রশিক্ষিত বড় ইমেজ মডেলকে সূক্ষ্ম-টিউন করতে পারেন যা একটি ইনপুট চিত্রে পাখির সংখ্যা ফেরত দেয়।
নিম্নলিখিত পদগুলির সাথে ফাইন-টিউনিং তুলনা করুন এবং বৈসাদৃশ্য করুন:
শণ
JAX- এর উপরে তৈরি গভীর শিক্ষার জন্য একটি উচ্চ-কর্মক্ষমতাসম্পন্ন ওপেন-সোর্স লাইব্রেরি । ফ্ল্যাক্স নিউরাল নেটওয়ার্কের প্রশিক্ষণের জন্য ফাংশন প্রদান করে, সেইসাথে তাদের কার্যকারিতা মূল্যায়নের পদ্ধতি।
ফ্ল্যাক্সফর্মার
একটি ওপেন সোর্স ট্রান্সফরমার লাইব্রেরি , ফ্ল্যাক্সের উপর নির্মিত, যা প্রাথমিকভাবে প্রাকৃতিক ভাষা প্রক্রিয়াকরণ এবং মাল্টিমোডাল গবেষণার জন্য ডিজাইন করা হয়েছে।
জি
জেনারেটিভ এআই
কোনো আনুষ্ঠানিক সংজ্ঞা ছাড়াই একটি উদীয়মান রূপান্তরমূলক ক্ষেত্র। এটি বলেছে, বেশিরভাগ বিশেষজ্ঞরা সম্মত হন যে জেনারেটিভ এআই মডেলগুলি নিম্নলিখিত সমস্ত সামগ্রী তৈরি করতে পারে ("উত্পন্ন"):
- জটিল
- সুসঙ্গত
- মূল
উদাহরণস্বরূপ, একটি জেনারেটিভ এআই মডেল পরিশীলিত প্রবন্ধ বা চিত্র তৈরি করতে পারে।
LSTMs এবং RNN সহ কিছু আগের প্রযুক্তিও আসল এবং সুসংগত বিষয়বস্তু তৈরি করতে পারে। কিছু বিশেষজ্ঞ এই আগের প্রযুক্তিগুলিকে জেনারেটিভ AI হিসাবে দেখেন, অন্যরা মনে করেন যে সত্যিকারের জেনারেটিভ AI-এর জন্য আগের প্রযুক্তিগুলি তৈরি করতে পারে তার চেয়ে আরও জটিল আউটপুট প্রয়োজন।
ভবিষ্যদ্বাণীমূলক ML এর সাথে বৈসাদৃশ্য।
জিপিটি (জেনারেটিভ প্রাক-প্রশিক্ষিত ট্রান্সফরমার)
OpenAI দ্বারা বিকশিত ট্রান্সফরমার -ভিত্তিক বড় ভাষা মডেলের একটি পরিবার।
GPT ভেরিয়েন্টগুলি একাধিক পদ্ধতিতে প্রয়োগ করতে পারে, যার মধ্যে রয়েছে:
- ইমেজ জেনারেশন (উদাহরণস্বরূপ, ImageGPT)
- টেক্সট-টু-ইমেজ জেনারেশন (উদাহরণস্বরূপ, DALL-E )।
এইচ
হ্যালুসিনেশন
একটি জেনারেটিভ এআই মডেল দ্বারা প্রশংসনীয়-আপাত কিন্তু বাস্তবে ভুল আউটপুট উৎপাদন যা বাস্তব জগৎ সম্পর্কে একটি দাবী করে। উদাহরণস্বরূপ, একটি জেনারেটিভ এআই মডেল যা দাবি করে যে বারাক ওবামা 1865 সালে মারা গিয়েছিলেন তা হ্যালুসিনেটিং ।
আমি
প্রেক্ষাপটে শিক্ষা
কয়েক শট প্রম্পটিং এর সমার্থক।
এল
LaMDA (সংলাপ অ্যাপ্লিকেশনের জন্য ভাষা মডেল)
একটি ট্রান্সফরমার -ভিত্তিক বৃহৎ ভাষা মডেল যা Google দ্বারা তৈরি করা হয়েছে একটি বৃহৎ ডায়ালগ ডেটাসেটে প্রশিক্ষণ দেওয়া হয়েছে যা বাস্তবসম্মত কথোপকথনমূলক প্রতিক্রিয়া তৈরি করতে পারে।
LaMDA: আমাদের যুগান্তকারী কথোপকথন প্রযুক্তি একটি ওভারভিউ প্রদান করে।
ভাষার মডেল
একটি মডেল যা একটি টোকেন বা টোকেনের ক্রম টোকেনগুলির একটি দীর্ঘ ক্রমানুসারে ঘটানোর সম্ভাবনা অনুমান করে৷
বড় ভাষা মডেল
একটি অনানুষ্ঠানিক শব্দ যার কোন কঠোর সংজ্ঞা নেই যার অর্থ সাধারণত একটি ভাষা মডেল যার উচ্চ সংখ্যক পরামিতি রয়েছে। কিছু বড় ভাষার মডেলে 100 বিলিয়নের বেশি প্যারামিটার থাকে।
এম
মুখোশযুক্ত ভাষা মডেল
একটি ভাষা মডেল যা প্রার্থীর টোকেনগুলির একটি ক্রমানুসারে শূন্যস্থান পূরণ করার সম্ভাবনার পূর্বাভাস দেয়৷ উদাহরণস্বরূপ, একটি মুখোশযুক্ত ভাষা মডেল নিম্নলিখিত বাক্যে আন্ডারলাইন প্রতিস্থাপন করতে প্রার্থী শব্দ(গুলি) এর সম্ভাব্যতা গণনা করতে পারে:
টুপির ____ ফিরে এল।
সাহিত্য সাধারণত আন্ডারলাইনের পরিবর্তে স্ট্রিং "MASK" ব্যবহার করে। উদাহরণ স্বরূপ:
টুপিতে "মাস্ক" ফিরে এসেছে।
বেশিরভাগ আধুনিক মুখোশযুক্ত ভাষার মডেলগুলি দ্বিমুখী ।
মেটা-লার্নিং
মেশিন লার্নিংয়ের একটি উপসেট যা একটি শেখার অ্যালগরিদম আবিষ্কার করে বা উন্নত করে। একটি মেটা-লার্নিং সিস্টেমের লক্ষ্য হতে পারে একটি মডেলকে দ্রুত একটি নতুন কাজ শিখতে শেখার জন্য অল্প পরিমাণ ডেটা বা পূর্ববর্তী কাজগুলিতে অর্জিত অভিজ্ঞতা থেকে। মেটা-লার্নিং অ্যালগরিদমগুলি সাধারণত নিম্নলিখিতগুলি অর্জন করার চেষ্টা করে:
- হ্যান্ড-ইঞ্জিনিয়ারড বৈশিষ্ট্যগুলি উন্নত/শিখুন (যেমন একটি ইনিশিয়ালাইজার বা একটি অপ্টিমাইজার)।
- আরও ডেটা-দক্ষ এবং গণনা-দক্ষ হন।
- সাধারণীকরণ উন্নত করুন।
মেটা-লার্নিং অল্প-শট শেখার সাথে সম্পর্কিত।
পদ্ধতি
একটি উচ্চ-স্তরের ডেটা বিভাগ। উদাহরণস্বরূপ, সংখ্যা, পাঠ্য, চিত্র, ভিডিও এবং অডিও পাঁচটি ভিন্ন পদ্ধতি।
মডেল সমান্তরালতা
প্রশিক্ষণ বা অনুমান স্কেলিং করার একটি উপায় যা একটি মডেলের বিভিন্ন অংশকে বিভিন্ন ডিভাইসে রাখে। মডেল সমান্তরাল মডেলগুলিকে সক্ষম করে যেগুলি একটি একক ডিভাইসে ফিট করার জন্য খুব বড়।
মডেল সমান্তরালতা বাস্তবায়ন করতে, একটি সিস্টেম সাধারণত নিম্নলিখিতগুলি করে:
- মডেলটিকে ছোট ছোট অংশে ভাগ করে।
- একাধিক প্রসেসর জুড়ে সেই ছোট অংশগুলির প্রশিক্ষণ বিতরণ করে। প্রতিটি প্রসেসর মডেলের নিজস্ব অংশকে প্রশিক্ষণ দেয়।
- একটি একক মডেল তৈরি করতে ফলাফলগুলিকে একত্রিত করে৷
মডেল সমান্তরালতা প্রশিক্ষণ ধীর.
ডেটা সমান্তরালতাও দেখুন।
বহু-মাথা স্ব-মনোযোগ
স্ব-মনোযোগের একটি এক্সটেনশন যা ইনপুট অনুক্রমের প্রতিটি অবস্থানের জন্য স্ব-মনোযোগ প্রক্রিয়া একাধিকবার প্রয়োগ করে।
ট্রান্সফরমার মাল্টি-হেড স্ব-মনোযোগ চালু করেছে।
মাল্টিমোডাল মডেল
একটি মডেল যার ইনপুট এবং/অথবা আউটপুট একাধিক মোডালিটি অন্তর্ভুক্ত করে। উদাহরণ স্বরূপ, এমন একটি মডেল বিবেচনা করুন যা একটি চিত্র এবং একটি পাঠ্য ক্যাপশন (দুটি রূপ) উভয়কেই বৈশিষ্ট্য হিসাবে গ্রহণ করে এবং একটি স্কোর আউটপুট করে যা নির্দেশ করে যে পাঠ্য ক্যাপশনটি চিত্রের জন্য কতটা উপযুক্ত। সুতরাং, এই মডেলের ইনপুট মাল্টিমোডাল এবং আউটপুট ইউনিমডাল।
এন
প্রাকৃতিক ভাষা বোঝা
ব্যবহারকারী যা টাইপ করেছেন বা বলেছেন তার উপর ভিত্তি করে ব্যবহারকারীর উদ্দেশ্য নির্ধারণ করা। উদাহরণস্বরূপ, ব্যবহারকারী যা টাইপ করেছেন বা বলেছেন তার উপর ভিত্তি করে ব্যবহারকারী কী অনুসন্ধান করছেন তা নির্ধারণ করতে একটি সার্চ ইঞ্জিন প্রাকৃতিক ভাষা বোঝার ব্যবহার করে।
এন-গ্রাম
N শব্দের একটি আদেশকৃত ক্রম। উদাহরণস্বরূপ, সত্যিকারের পাগল হল একটি 2-গ্রাম। কারণ অর্ডার প্রাসঙ্গিক, madly সত্যি সত্যি পাগলের চেয়ে আলাদা 2-গ্রাম।
| এন | এই ধরনের N-গ্রামের জন্য নাম(গুলি) | উদাহরণ |
|---|---|---|
| 2 | বিগগ্রাম বা 2-গ্রাম | যেতে, যেতে, দুপুরের খাবার খেতে, রাতের খাবার খেতে |
| 3 | ট্রিগ্রাম বা 3-গ্রাম | খুব বেশি খেয়েছে, তিনটি অন্ধ ইঁদুর, ঘণ্টা বাজছে |
| 4 | 4-গ্রাম | পার্কে হাঁটা, বাতাসে ধুলো, ছেলেটা মসুর ডাল খেয়েছে |
অনেক প্রাকৃতিক ভাষা বোঝার মডেল এন-গ্রামের উপর নির্ভর করে পরবর্তী শব্দ যা ব্যবহারকারী টাইপ করবে বা বলবে তা ভবিষ্যদ্বাণী করতে। উদাহরণস্বরূপ, ধরুন একজন ব্যবহারকারী তিনটি অন্ধ টাইপ করেছেন। ট্রিগ্রামের উপর ভিত্তি করে একটি NLU মডেল সম্ভবত ভবিষ্যদ্বাণী করবে যে ব্যবহারকারী পরবর্তীতে ইঁদুর টাইপ করবে।
শব্দের ব্যাগের সাথে এন-গ্রামের বৈসাদৃশ্য করুন, যা শব্দের বিন্যাসহীন সেট।
এনএলইউ
প্রাকৃতিক ভাষা বোঝার জন্য সংক্ষিপ্ত রূপ।
ও
এক শট প্রম্পটিং
একটি প্রম্পট যাতে একটি উদাহরণ রয়েছে যা প্রদর্শন করে যে কীভাবে বড় ভাষা মডেলের প্রতিক্রিয়া জানানো উচিত। উদাহরণ স্বরূপ, নিচের প্রম্পটে একটি উদাহরণ রয়েছে যেটি একটি বৃহৎ ভাষার মডেল দেখায় কিভাবে এটি একটি প্রশ্নের উত্তর দিতে হবে।
| এক প্রম্পটের অংশ | মন্তব্য |
|---|---|
| নির্দিষ্ট দেশের সরকারী মুদ্রা কি? | যে প্রশ্নটির উত্তর আপনি LLM করতে চান। |
| ফ্রান্স: EUR | একটি উদাহরণ. |
| ভারত: | প্রকৃত প্রশ্ন. |
নিম্নলিখিত পদগুলির সাথে এক-শট প্রম্পটিং তুলনা করুন এবং বৈসাদৃশ্য করুন:
পৃ
প্যারামিটার-দক্ষ টিউনিং
একটি বৃহৎ প্রাক-প্রশিক্ষিত ভাষা মডেল (PLM) সম্পূর্ণ ফাইন-টিউনিংয়ের চেয়ে আরও দক্ষতার সাথে সূক্ষ্ম-টিউন করার কৌশলগুলির একটি সেট। প্যারামিটার-দক্ষ টিউনিং সাধারণত পূর্ণ সূক্ষ্ম-টিউনিংয়ের চেয়ে অনেক কম পরামিতিকে সূক্ষ্ম-টিউন করে, তবুও সাধারণত একটি বৃহৎ ভাষার মডেল তৈরি করে যা সম্পূর্ণ সূক্ষ্ম-টিউনিং থেকে নির্মিত একটি বৃহৎ ভাষার মডেল হিসাবে (বা প্রায় পাশাপাশি) কাজ করে।
এর সাথে পরামিতি-দক্ষ টিউনিং তুলনা করুন এবং বৈসাদৃশ্য করুন:
প্যারামিটার-দক্ষ টিউনিং প্যারামিটার-দক্ষ ফাইন-টিউনিং নামেও পরিচিত।
পাইপলাইন
মডেলের সমান্তরালতার একটি ফর্ম যেখানে একটি মডেলের প্রক্রিয়াকরণ ধারাবাহিক পর্যায়ে বিভক্ত এবং প্রতিটি পর্যায় একটি ভিন্ন ডিভাইসে কার্যকর করা হয়। একটি পর্যায় যখন একটি ব্যাচ প্রক্রিয়া করছে, পূর্ববর্তী পর্যায়টি পরবর্তী ব্যাচে কাজ করতে পারে।
এছাড়াও মঞ্চস্থ প্রশিক্ষণ দেখুন.
পিএলএম
প্রাক-প্রশিক্ষিত ভাষা মডেলের সংক্ষিপ্ত রূপ।
অবস্থানগত এনকোডিং
টোকেনের এম্বেডিং-এ একটি ক্রমানুসারে একটি টোকেনের অবস্থান সম্পর্কে তথ্য যোগ করার একটি কৌশল। ট্রান্সফরমার মডেলগুলি সিকোয়েন্সের বিভিন্ন অংশের মধ্যে সম্পর্ক আরও ভালভাবে বোঝার জন্য অবস্থানগত এনকোডিং ব্যবহার করে।
অবস্থানগত এনকোডিংয়ের একটি সাধারণ বাস্তবায়ন একটি সাইনোসয়েডাল ফাংশন ব্যবহার করে। (বিশেষত, সাইনোসয়েডাল ফাংশনের ফ্রিকোয়েন্সি এবং প্রশস্ততা ক্রমানুসারে টোকেনের অবস্থান দ্বারা নির্ধারিত হয়।) এই কৌশলটি একটি ট্রান্সফরমার মডেলকে তাদের অবস্থানের উপর ভিত্তি করে ক্রমটির বিভিন্ন অংশে উপস্থিত থাকতে শিখতে সক্ষম করে।
প্রাক-প্রশিক্ষিত মডেল
মডেল বা মডেল উপাদান (যেমন একটি এমবেডিং ভেক্টর ) যা ইতিমধ্যেই প্রশিক্ষিত হয়েছে। কখনও কখনও, আপনি একটি নিউরাল নেটওয়ার্কে প্রাক-প্রশিক্ষিত এমবেডিং ভেক্টর খাওয়াবেন। অন্য সময়ে, আপনার মডেল প্রাক-প্রশিক্ষিত এম্বেডিংয়ের উপর নির্ভর না করে নিজেরাই এম্বেডিং ভেক্টরকে প্রশিক্ষণ দেবে।
প্রাক-প্রশিক্ষিত ভাষা মডেল শব্দটি একটি বড় ভাষা মডেলকে বোঝায় যা প্রাক-প্রশিক্ষণের মধ্য দিয়ে গেছে।
প্রাক-প্রশিক্ষণ
একটি বড় ডেটাসেটে একটি মডেলের প্রাথমিক প্রশিক্ষণ৷ কিছু প্রাক-প্রশিক্ষিত মডেল হল আনাড়ি জায়ান্ট এবং সাধারণত অতিরিক্ত প্রশিক্ষণের মাধ্যমে পরিমার্জিত হতে হবে। উদাহরণস্বরূপ, এমএল বিশেষজ্ঞরা একটি বিশাল টেক্সট ডেটাসেটে, যেমন উইকিপিডিয়ার সমস্ত ইংরেজি পৃষ্ঠাগুলিতে একটি বড় ভাষার মডেলকে প্রাক-প্রশিক্ষণ দিতে পারে। প্রাক-প্রশিক্ষণের পরে, ফলস্বরূপ মডেলটি নিম্নলিখিত কৌশলগুলির মাধ্যমে আরও পরিমার্জিত হতে পারে:
শীঘ্র
একটি বৃহৎ ভাষার মডেলে ইনপুট হিসাবে প্রবেশ করা যেকোন পাঠ্য মডেলটিকে একটি নির্দিষ্ট উপায়ে আচরণ করার শর্ত দেয়। প্রম্পটগুলি একটি বাক্যাংশের মতো ছোট বা ইচ্ছাকৃতভাবে দীর্ঘ হতে পারে (উদাহরণস্বরূপ, একটি উপন্যাসের সম্পূর্ণ পাঠ্য)। প্রম্পটগুলি নিম্নলিখিত সারণীতে দেখানো সহ একাধিক বিভাগে পড়ে:
| প্রম্পট বিভাগ | উদাহরণ | মন্তব্য |
|---|---|---|
| প্রশ্ন | একটি কবুতর কত দ্রুত উড়তে পারে? | |
| নির্দেশ | স্বেচ্ছাচারিতা সম্পর্কে একটি মজার কবিতা লিখুন। | একটি প্রম্পট যা বড় ভাষা মডেলকে কিছু করতে বলে। |
| উদাহরণ | HTML-এ মার্কডাউন কোড অনুবাদ করুন। উদাহরণ স্বরূপ: মার্কডাউন: * তালিকা আইটেম HTML: <ul> <li>তালিকা আইটেম</li> </ul> | এই উদাহরণের প্রম্পটে প্রথম বাক্যটি একটি নির্দেশ। প্রম্পটের অবশিষ্টাংশটি উদাহরণ। |
| ভূমিকা | পদার্থবিদ্যায় পিএইচডি করার জন্য মেশিন লার্নিং প্রশিক্ষণে গ্রেডিয়েন্ট ডিসেন্ট কেন ব্যবহার করা হয় তা ব্যাখ্যা করুন। | বাক্যের প্রথম অংশটি একটি নির্দেশ; "পদার্থবিজ্ঞানে পিএইচডি করতে" বাক্যাংশটি ভূমিকা অংশ। |
| মডেল সম্পূর্ণ করার জন্য আংশিক ইনপুট | যুক্তরাজ্যের প্রধানমন্ত্রী এখানে থাকেন | একটি আংশিক ইনপুট প্রম্পট হয় আকস্মিকভাবে শেষ হতে পারে (যেমন এই উদাহরণটি করে) অথবা একটি আন্ডারস্কোর দিয়ে শেষ হতে পারে। |
একটি জেনারেটিভ এআই মডেল টেক্সট, কোড, ইমেজ, এমবেডিং , ভিডিও...প্রায় যেকোন কিছুর সাথে প্রম্পটে সাড়া দিতে পারে।
প্রম্পট-ভিত্তিক শিক্ষা
নির্দিষ্ট মডেলের একটি ক্ষমতা যা তাদের স্বেচ্ছাচারী পাঠ্য ইনপুট ( প্রম্পট ) এর প্রতিক্রিয়ায় তাদের আচরণকে মানিয়ে নিতে সক্ষম করে। একটি সাধারণ প্রম্পট-ভিত্তিক শেখার দৃষ্টান্তে, একটি বৃহৎ ভাষা মডেল পাঠ্য তৈরি করে একটি প্রম্পটে সাড়া দেয়। উদাহরণস্বরূপ, ধরুন একজন ব্যবহারকারী নিম্নলিখিত প্রম্পটে প্রবেশ করে:
নিউটনের গতির তৃতীয় সূত্র সংক্ষিপ্ত কর।
প্রম্পট-ভিত্তিক শিক্ষার জন্য সক্ষম একটি মডেল পূর্ববর্তী প্রম্পটের উত্তর দেওয়ার জন্য বিশেষভাবে প্রশিক্ষিত নয়। বরং, মডেলটি পদার্থবিজ্ঞান সম্পর্কে অনেক তথ্য, সাধারণ ভাষার নিয়ম সম্পর্কে অনেক কিছু এবং সাধারণত দরকারী উত্তরগুলি কী গঠন করে সে সম্পর্কে অনেক কিছু "জানে"৷ সেই জ্ঞান একটি (আশা করি) দরকারী উত্তর প্রদানের জন্য যথেষ্ট। অতিরিক্ত মানুষের প্রতিক্রিয়া ("উত্তরটি খুব জটিল ছিল।" বা "একটি প্রতিক্রিয়া কী?") কিছু প্রম্পট-ভিত্তিক শিক্ষা ব্যবস্থাকে ধীরে ধীরে তাদের উত্তরগুলির উপযোগিতা উন্নত করতে সক্ষম করে।
প্রম্পট নকশা
প্রম্পট ইঞ্জিনিয়ারিং এর প্রতিশব্দ।
প্রম্পট ইঞ্জিনিয়ারিং
প্রম্পট তৈরি করার শিল্প যা একটি বৃহৎ ভাষার মডেল থেকে পছন্দসই প্রতিক্রিয়াগুলি প্রকাশ করে। মানুষ প্রম্পট ইঞ্জিনিয়ারিং সঞ্চালন. সুগঠিত প্রম্পট লেখা একটি বড় ভাষা মডেল থেকে কার্যকর প্রতিক্রিয়া নিশ্চিত করার একটি অপরিহার্য অংশ। প্রম্পট ইঞ্জিনিয়ারিং অনেক কারণের উপর নির্ভর করে, যার মধ্যে রয়েছে:
- ডেটাসেটটি প্রাক-প্রশিক্ষণ এবং সম্ভবত বৃহৎ ভাষার মডেলটিকে সূক্ষ্ম-টিউন করতে ব্যবহৃত হয়।
- তাপমাত্রা এবং অন্যান্য ডিকোডিং পরামিতি যা মডেল প্রতিক্রিয়া তৈরি করতে ব্যবহার করে।
সহায়ক প্রম্পট লেখার বিষয়ে আরও বিস্তারিত জানার জন্য প্রম্পট ডিজাইনের ভূমিকা দেখুন।
প্রম্পট ডিজাইন প্রম্পট ইঞ্জিনিয়ারিং এর প্রতিশব্দ।
প্রম্পট টিউনিং
একটি পরামিতি দক্ষ টিউনিং প্রক্রিয়া যা একটি "প্রিফিক্স" শিখে যা সিস্টেমটি প্রকৃত প্রম্পটে প্রিপেন্ড করে।
প্রম্পট টিউনিং-এর একটি বৈচিত্র—কখনও কখনও প্রিফিক্স টিউনিং বলা হয়— প্রতিটি স্তরে উপসর্গটি প্রিপেন্ড করা। বিপরীতে, বেশিরভাগ প্রম্পট টিউনিং শুধুমাত্র ইনপুট স্তরে একটি উপসর্গ যোগ করে।
আর
ভূমিকা প্রম্পটিং
একটি প্রম্পটের একটি ঐচ্ছিক অংশ যা একটি জেনারেটিভ এআই মডেলের প্রতিক্রিয়ার জন্য লক্ষ্য দর্শকদের সনাক্ত করে। রোল প্রম্পট ছাড়াই , একটি বৃহৎ ভাষা মডেল একটি উত্তর প্রদান করে যা প্রশ্ন জিজ্ঞাসাকারী ব্যক্তির পক্ষে কার্যকর হতে পারে বা নাও হতে পারে। একটি ভূমিকা প্রম্পট সহ , একটি বড় ভাষা মডেল এমনভাবে উত্তর দিতে পারে যা একটি নির্দিষ্ট লক্ষ্য দর্শকদের জন্য আরও উপযুক্ত এবং আরও সহায়ক। উদাহরণস্বরূপ, নিম্নলিখিত প্রম্পটগুলির ভূমিকা প্রম্পট অংশটি বোল্ডফেসে রয়েছে:
- Summarize this article for a PhD in economics .
- Describe how tides work for a ten-year old .
- Explain the 2008 financial crisis. Speak as you might to a young child, or a golden retriever.
এস
self-attention (also called self-attention layer)
A neural network layer that transforms a sequence of embeddings (for instance, token embeddings) into another sequence of embeddings. Each embedding in the output sequence is constructed by integrating information from the elements of the input sequence through an attention mechanism.
The self part of self-attention refers to the sequence attending to itself rather than to some other context. Self-attention is one of the main building blocks for Transformers and uses dictionary lookup terminology, such as “query”, “key”, and “value”.
A self-attention layer starts with a sequence of input representations, one for each word. The input representation for a word can be a simple embedding. For each word in an input sequence, the network scores the relevance of the word to every element in the whole sequence of words. The relevance scores determine how much the word's final representation incorporates the representations of other words.
For example, consider the following sentence:
The animal didn't cross the street because it was too tired.
The following illustration (from Transformer: A Novel Neural Network Architecture for Language Understanding ) shows a self-attention layer's attention pattern for the pronoun it , with the darkness of each line indicating how much each word contributes to the representation:
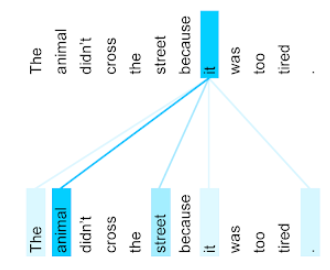
The self-attention layer highlights words that are relevant to "it". In this case, the attention layer has learned to highlight words that it might refer to, assigning the highest weight to animal .
For a sequence of n tokens , self-attention transforms a sequence of embeddings n separate times, once at each position in the sequence.
Refer also to attention and multi-head self-attention .
অনুভূতির বিশ্লেষণ
Using statistical or machine learning algorithms to determine a group's overall attitude—positive or negative—toward a service, product, organization, or topic. For example, using natural language understanding , an algorithm could perform sentiment analysis on the textual feedback from a university course to determine the degree to which students generally liked or disliked the course.
sequence-to-sequence task
A task that converts an input sequence of tokens to an output sequence of tokens. For example, two popular kinds of sequence-to-sequence tasks are:
- Translators:
- Sample input sequence: "I love you."
- Sample output sequence: "Je t'aime."
- Question answering:
- Sample input sequence: "Do I need my car in New York City?"
- Sample output sequence: "No. Please keep your car at home."
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree . Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding . If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36 tree species in a particular forest. Further assume that each example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example. A one-hot vector would contain a single 1 (to represent the particular tree species in that example) and 35 0 s (to represent the 35 tree species not in that example). So, the one-hot representation of maple might look something like the following:

Alternatively, sparse representation would simply identify the position of the particular species. If maple is at position 24, then the sparse representation of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
নিম্নলিখিত বাক্য বিবেচনা করুন:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:

A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
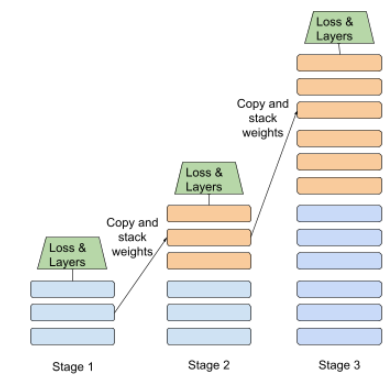
staged training
A tactic of training a model in a sequence of discrete stages. The goal can be either to speed up the training process, or to achieve better model quality.
An illustration of the progressive stacking approach is shown below:
- Stage 1 contains 3 hidden layers, stage 2 contains 6 hidden layers, and stage 3 contains 12 hidden layers.
- Stage 2 begins training with the weights learned in the 3 hidden layers of Stage 1. Stage 3 begins training with the weights learned in the 6 hidden layers of Stage 2.
See also pipelining .
টি
T5
A text-to-text transfer learning model introduced by Google AI in 2020 . T5 is an encoder - decoder model, based on the Transformer architecture, trained on an extremely large dataset. It is effective at a variety of natural language processing tasks, such as generating text, translating languages, and answering questions in a conversational manner.
T5 gets its name from the five T's in "Text-to-Text Transfer Transformer."
T5X
An open-source, machine learning framework designed to build and train large-scale natural language processing (NLP) models. T5 is implemented on the T5X codebase (which is built on JAX and Flax ).
তাপমাত্রা
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and the desired properties of the model's output. For example, you would probably raise the temperature when creating an application that generates creative output. Conversely, you would probably lower the temperature when building a model that classifies images or text in order to improve the model's accuracy and consistency.
Temperature is often used with softmax .
text span
The array index span associated with a specific subsection of a text string. For example, the word good in the Python string s="Be good now" occupies the text span from 3 to 6.
টোকেন
In a language model , the atomic unit that the model is training on and making predictions on. A token is typically one of the following:
- a word—for example, the phrase "dogs like cats" consists of three word tokens: "dogs", "like", and "cats".
- a character—for example, the phrase "bike fish" consists of nine character tokens. (Note that the blank space counts as one of the tokens.)
- subwords—in which a single word can be a single token or multiple tokens. A subword consists of a root word, a prefix, or a suffix. For example, a language model that uses subwords as tokens might view the word "dogs" as two tokens (the root word "dog" and the plural suffix "s"). That same language model might view the single word "taller" as two subwords (the root word "tall" and the suffix "er").
In domains outside of language models, tokens can represent other kinds of atomic units. For example, in computer vision, a token might be a subset of an image.
ট্রান্সফরমার
A neural network architecture developed at Google that relies on self-attention mechanisms to transform a sequence of input embeddings into a sequence of output embeddings without relying on convolutions or recurrent neural networks . A Transformer can be viewed as a stack of self-attention layers.
A Transformer can include any of the following:
An encoder transforms a sequence of embeddings into a new sequence of the same length. An encoder includes N identical layers, each of which contains two sub-layers. These two sub-layers are applied at each position of the input embedding sequence, transforming each element of the sequence into a new embedding. The first encoder sub-layer aggregates information from across the input sequence. The second encoder sub-layer transforms the aggregated information into an output embedding.
A decoder transforms a sequence of input embeddings into a sequence of output embeddings, possibly with a different length. A decoder also includes N identical layers with three sub-layers, two of which are similar to the encoder sub-layers. The third decoder sub-layer takes the output of the encoder and applies the self-attention mechanism to gather information from it.
The blog post Transformer: A Novel Neural Network Architecture for Language Understanding provides a good introduction to Transformers.
trigram
An N-gram in which N=3.
উ
একমুখী
A system that only evaluates the text that precedes a target section of text. In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before , not after , the target token(s). Contrast with bidirectional language model .
ভি
ভেরিয়েশনাল অটোএনকোডার (VAE)
A type of autoencoder that leverages the discrepancy between inputs and outputs to generate modified versions of the inputs. Variational autoencoders are useful for generative AI .
VAEs are based on variational inference: a technique for estimating the parameters of a probability model.
ডব্লিউ
শব্দ এমবেডিং
Representing each word in a word set within an embedding vector ; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots , celery , and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane , sunglasses , and toothpaste .
জেড
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. উদাহরণ স্বরূপ:
| Parts of one prompt | মন্তব্য |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| ভারত: | The actual query. |
The large language model might respond with any of the following:
- রুপি
- INR
- ₹
- ভারতীয় রুপি
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: