Bu sayfa Dil Değerlendirme sözlüğü terimleri içerir. Tüm sözlük terimleri için burayı tıklayın.
CEVAP
dikkat
Nöral ağda kullanılan ve belirli bir kelimenin veya bir kelimenin bir kısmının önemini gösteren mekanizma. Dikkat, bir modelin bir sonraki jetonu/kelimeyi tahmin etmek için ihtiyaç duyduğu bilgi miktarını sıkıştırır. Tipik bir dikkat mekanizması, bir dizi giriş üzerinden alınan ağırlıklı toplamdan oluşabilir. Her bir girişin ağırlığı, nöral ağın başka bir bölümü tarafından hesaplanır.
Transformer'ın yapı taşları olan kendi kendine dikkat ve birçok kafalı kişinin kendi kendine dikkat çekmesi konularına da değinin.
otomatik kodlayıcı
Girişten en önemli bilgileri çıkarmayı öğrenen bir sistem. Otomatik kodlayıcılar, kodlayıcı ve kod çözücü kombinasyonudur. Otomatik kodlayıcılar, aşağıdaki iki adımlı süreci kullanır:
- Kodlayıcı, girişi (tipik olarak) kayıplı, düşük boyutlu (orta) bir biçime eşler.
- Kod çözücü, düşük boyutlu biçimi orijinal daha yüksek boyutlu giriş biçimiyle eşleyerek orijinal girişin kayıplı bir sürümünü oluşturur.
Otomatik kodlayıcılar, kod çözücünün orijinal girişi kodlayıcının ara biçiminden mümkün olduğunca yakından yeniden oluşturmaya çalışmasını sağlayarak uçtan uca eğitilir. Ara biçim, orijinal biçimden daha küçük (düşük boyutlu) olduğundan, otomatik kodlayıcı, girişteki hangi bilgilerin gerekli olduğunu öğrenmeye zorlanır ve çıkış, girişle tamamen aynı olmaz.
Örneğin:
- Giriş verileri bir grafikse, tam olmayan kopya orijinal grafiğe benzer, ancak bir şekilde değiştirilmiş olur. Belki de tam olmayan kopya, orijinal grafikteki gürültüyü giderir veya bazı eksik pikselleri doldurur.
- Giriş verileri metinse otomatik kodlayıcı, orijinal metni taklit eden (ancak metinle aynı olmayan) yeni metin oluşturur.
Ayrıca çeşitli otomatik kodlayıcılar konusuna da bakın.
otomatik regresif model
Kendi önceki tahminlerine dayanarak bir tahminde bulunan model. Örneğin, otomatik regresif dil modelleri, önceden tahmin edilen jetonlara dayalı olarak bir sonraki jetonu tahmin eder. Tüm Transformer tabanlı büyük dil modelleri otomatik regresiftir.
Buna karşılık GAN tabanlı görüntü modelleri, görüntüleri aşamalı olarak değil, tek bir ileriye doğru geçişte oluşturdukları için genellikle otomatik regresif değildir. Ancak bazı görüntü oluşturma modelleri, birkaç adımda görüntü oluşturdukları için otomatik regresif olur.
B
bir sürü kelime
Kelimelerin, sıralamadan bağımsız olarak bir kelime öbeği veya pasaj içinde temsili. Örneğin, bir dizi kelime öbeği, aşağıdaki üç ifadeyi aynı şekilde temsil eder:
- köpek zıplıyor
- köpeği atlar
- zıplayan köpek
Her kelime, seyrek vektör içerisindeki bir dizinle eşlenir. Bu dizinde vektör, sözlükteki her kelime için bir dizine sahiptir. Örneğin, köpek zıplar ifadesi, üç dizinde the, dog ve jumps kelimelerine karşılık gelen sıfır olmayan değerlere sahip bir özellik vektörü olarak eşlenir. Sıfır olmayan değer aşağıdakilerden herhangi biri olabilir:
- Bir kelimenin varlığını belirtmek için 1.
- Bir kelimenin çantada kaç kez göründüğünün sayısı. Örneğin, bordo köpek rengi kestane rengi kürklü bir köpek ifadesi olsaydı hem bordo hem de köpek 2 olarak temsil edilirken diğer kelimeler 1 olarak temsil edilir.
- Bir kelimenin pakette kaç kez göründüğünün logaritması gibi başka bir değer.
BERT (Transformatörlerden Çift Yönlü Kodlayıcı Temsili)
Metin temsili için model mimari. Eğitilmiş bir BERT modeli, metin sınıflandırma veya diğer makine öğrenimi görevleri için daha büyük bir modelin parçası olabilir.
BERT'in özellikleri:
- Transformer mimarisini kullandığı için kendi kendine dikkat özelliğini kullanır.
- Transformatör'ün kodlayıcı bölümünü kullanır. Kodlayıcının işi, sınıflandırma gibi belirli bir görevi gerçekleştirmek yerine iyi metin sunumları oluşturmaktır.
- İki yönlü olmalıdır.
- Gözetimsiz eğitim için maskeleme yöntemini kullanır.
BERT'in varyantları:
BERT'e genel bakış için Open Sourcing BERT: Doğal Dil İşleme için Gelişmiş Ön Eğitim sayfasına bakın.
iki yönlü
Metnin hem önüne gelen hem de takip eden metni değerlendiren bir sistemi açıklamak için kullanılan terim. Buna karşılık, tek yönlü bir sistem yalnızca metnin hedef bölümünden önce gelen metni değerlendirir.
Örneğin, aşağıdaki sorudaki alt çizgiyi temsil eden kelime veya kelimelerin olasılıklarını belirlemesi gereken bir maskeli dil modelini ele alalım:
_____ nedir?
Tek yönlü bir dil modeli, olasılıklarını yalnızca "Ne", "eşittir" ve "bir" kelimelerinin sağladığı bağlama dayandırmalıdır. Bununla birlikte, çift yönlü bir dil modeli, "birlikte" ve "siz" ifadelerinden bağlam da elde edebilir ve bu da modelin daha iyi tahminler oluşturmasına yardımcı olabilir.
iki yönlü dil modeli
Önceki ve sonraki metne göre, belirli bir jetonun belirli bir metin alıntısında bulunma olasılığını belirleyen dil modeli.
Bigram
N=2 olan bir N-gram.
BLEU (İki Dilli Değerlendirme Ek Çalışması)
İki insan dili arasındaki (örneğin, İngilizce ve Rusça arasında) bir çevirinin kalitesini gösteren 0, 0 ile 1, 0 arasında (bu değerler dahil) puan. 1,0 olan BLEU puanı mükemmel çeviriyi, 0,0 olan BLEU puanı ise çok kötü bir çeviriyi belirtir.
C
nedensel dil modeli
Tek yönlü dil modeli'nin eş anlamlısı.
Dil modellemedeki farklı yönlü yaklaşımları karşılaştırmak için iki yönlü dil modeli bölümüne bakın.
düşünce zinciri yoluyla yönlendirme
Nedenini adım adım açıklamak için geniş bir dil modelini (LLM) teşvik eden bir istem mühendisliği tekniğidir. Örneğin, ikinci cümleye özellikle dikkat ederek aşağıdaki istemi ele alalım:
7 saniyede 0'dan 90 km'ye giden bir arabada sürücü kaç g kuvveti duyar? Yanıtta tüm alakalı hesaplamaları gösterin.
LLM'nin yanıtı muhtemelen:
- Uygun yerlere 0, 60 ve 7 değerlerini ekleyerek bir fizik formülleri dizisini gösterin.
- Formülleri neden seçtiğini ve çeşitli değişkenlerin ne anlama geldiğini açıklayın.
Düşünce zincirinin teşvik edilmesi, LLM'yi tüm hesaplamaları yapmaya zorlar. Bu da daha doğru bir yanıt sağlayabilir. Buna ek olarak, düşünme zinciriyle yapılan istemler, kullanıcının cevabın mantıklı olup olmadığını belirlemek için LLM'nin adımlarını incelemesini sağlar.
seçim bölgesi ayrıştırma
Cümlenin daha küçük dil bilgisi yapılarına ("bileşenler") bölünmesi. ML sisteminin doğal dil anlama modeli gibi sonraki bir kısmı, bileşenleri orijinal cümleden daha kolay ayrıştırabilir. Örneğin, şu cümleyi ele alalım:
Arkadaşım iki kedi sahiplendi.
Seçim bölgesi ayrıştırıcı, bu cümleyi aşağıdaki iki bileşene ayırabilir:
- Arkadaşım bir isim ifadesidir.
- evlat edelim fiili bir kelime öbeğidir.
Bu bileşenler, daha küçük bileşenlere ayrılabilir. Örneğin,
iki kedi sahiplendim
başka alt bölümler de olabilir:
- benimseme bir fiildir.
- iki kedi de bir diğer isim öbeğidir.
kilitlenme çiçeği
Anlamı belirsiz bir cümle veya kelime öbeği. Çökme çiçekleri doğal dil anlama açısından önemli bir sorun teşkil eder. Örneğin, Kırmızı Bant Dikey Sizi Tutuyor başlığı, bir NLU modeli başlığı olduğu gibi veya mecazi olarak yorumlayabileceği için bir kilitlenme çiçeğidir.
D
kod çözücü
Genel olarak, işlenmiş, yoğun veya dahili bir temsilden daha işlenmemiş, seyrek veya harici bir temsile dönüşen tüm ML sistemleri.
Kod çözücüler, genellikle daha büyük bir modelin bileşenleridir ve çoğunlukla bir kodlayıcı ile eşlenirler.
Adım sırası görevlerinde bir sonraki adım sırasını tahmin etmek için kod çözücü, kodlayıcı tarafından oluşturulan dahili durumla başlar.
Dönüştürücü mimarisindeki bir kod çözücünün tanımı için Transformer bölümüne bakın.
gürültü giderme
Kendi kendine gözetimli öğrenime yönelik yaygın bir yaklaşımdır.
Parazit giderme, etiketlenmemiş örneklerden öğrenmeye olanak tanır. Orijinal veri kümesi hedef veya etiket olarak, gürültülü veri ise giriş olarak kullanılır.
Bazı maskelenmiş dil modelleri gürültü gidermeyi aşağıdaki şekilde kullanır:
- Bazı jetonlar maskelenerek, etiketlenmemiş cümleye yapay olarak gürültü eklenir.
- Model, orijinal jetonları tahmin etmeye çalışır.
doğrudan isteme
Sıfır çekim istemi ile eş anlamlı kelime.
E
mesafeyi düzenle
İki metin dizesinin birbirine ne kadar benzer olduğunun ölçümü. Makine öğreniminde, düzenleme mesafesi yararlıdır. Bunun nedeni, basit ve hesaplanmasının yanı sıra benzer olduğu bilinen iki dizeyi karşılaştırmanın veya belirli bir dizeye benzeyen dizeleri bulmanın etkili bir yoludur.
Her biri farklı dize işlemleri kullanan birkaç düzenleme mesafesi tanımı vardır. Örneğin, Levenshtein mesafesi en az silme, ekleme ve değiştirme işlemini dikkate alır.
Örneğin, Levenshtein'da "kalp" ve "dart" kelimeleri arasındaki mesafe 3'tür, çünkü aşağıdaki 3 düzenleme bir kelimeyi diğerine dönüştürmek için gereken en az değişikliktir:
- kalp → deart ("h" yerine "d")
- deart → dart işareti ("e"yi sil)
- dart → dart ("s")
yerleştirme katmanı
Daha düşük boyutlu bir yerleştirme vektörünü kademeli olarak öğrenmek için yüksek boyutlu kategorik özellik üzerinde eğitilen özel bir gizli katman. Yerleştirme katmanı, bir nöral ağın yalnızca yüksek boyutlu kategorik özellik üzerinde eğitimden çok daha verimli bir şekilde eğitilmesini sağlar.
Örneğin, Earth şu anda yaklaşık 73.000 ağaç türünü desteklemektedir. Ağaç türünün, modelinizde bir özellik olduğunu ve modelinizin giriş katmanının 73.000 öğe uzunluğunda bir tek sıcak vektör içerdiğini varsayalım.
Örneğin, baobab şu şekilde temsil edilebilir:

73.000 öğeli bir dizi çok uzun. Modele yerleştirme katmanı eklemezseniz 72.999 sıfırın çarpımından dolayı eğitim çok zaman alır. Belki de yerleştirme katmanını 12 boyuttan oluşacak şekilde seçersiniz. Bunun sonucunda, yerleştirme katmanı her bir ağaç türü için kademeli olarak yeni bir yerleştirme vektörü öğrenecektir.
Belirli durumlarda, yerleştirme katmanına makul bir alternatif olarak karma oluşturma kullanılabilir.
yerleştirme alanı
Daha yüksek boyutlu bir vektör uzayından özellikler içeren d boyutlu vektör uzayı eşlenir. İdeal olarak, yerleştirme alanı anlamlı matematiksel sonuçlar veren bir yapı içerir. Örneğin, ideal bir yerleştirme alanında, yerleştirmelerin toplanması ve çıkarılması, kelime analojisi görevlerini çözebilir.
İki yerleştirmenin nokta çarpımı, benzerliklerinin ölçüsüdür.
gömme vektör
Genel olarak, söz konusu gizli katmandaki girişleri açıklayan herhangi bir gizli katmandan alınan kayan nokta sayıları dizisi. Genellikle yerleştirme vektörü, bir yerleştirme katmanında eğitilen kayan nokta sayıları dizisidir. Örneğin, bir yerleştirme katmanının Dünya'daki 73.000 ağaç türünün her biri için bir gömme vektörü öğrenmesi gerektiğini varsayalım. Aşağıdaki dizi, bir baobab ağacının gömme vektörü olabilir:

Katıştırma vektörü, bir dizi rastgele sayı değildir. Yerleştirme katmanı, bu değerleri, bir nöral ağın eğitim sırasında diğer ağırlıkları öğrenmesine benzer şekilde eğitim aracılığıyla belirler. Dizinin her öğesi, bir ağaç türünün bazı özelliklerine göre bir derecelendirmedir. Hangi öğe, hangi ağaç türünün özelliğini temsil eder? İnsanların bunu belirlemesi çok zordur.
Yerleştirme vektörünün matematiksel olarak en dikkat çekici yanı, benzer öğelerin benzer kayan nokta sayılarına sahip olmasıdır. Örneğin, benzer ağaç türleri, farklı olmayan ağaç türlerine göre daha benzer kayan nokta sayıları kümesine sahiptir. Sekoyalar ve sekoyalar birbiriyle alakalı ağaç türleridir. Bu nedenle, sekoya ve Hindistan cevizi ağaçlarına göre daha benzer bir kayan nokta sayılarına sahiptir. Yerleştirme vektöründeki sayılar, modeli aynı girdiyle yeniden eğitseniz bile modeli her yeniden eğittiğinizde değişir.
kodlayıcı
Genel olarak, ham, seyrek veya harici bir temsilden daha işlenmiş, daha yoğun veya daha çok dahili bir temsile dönüşen tüm ML sistemleri.
Kodlayıcılar, genellikle daha büyük bir modelin bileşenleridir ve çoğunlukla bir kod çözücü ile eşlenirler. Bazı Transformatörler, kodlayıcıları kod çözücülerle eşler. Diğer Transformatörler ise yalnızca kodlayıcıyı veya yalnızca kod çözücüyü kullanır.
Bazı sistemler, sınıflandırma veya regresyon ağına giriş olarak kodlayıcının çıkışını kullanır.
Diziden adım sırası görevlerinde, kodlayıcı bir giriş sırası alır ve bir dahili durum (vektör) döndürür. Ardından kod çözücü, bir sonraki adım sırasını tahmin etmek için bu dahili durumu kullanır.
Dönüştürücü mimarisindeki kodlayıcının tanımı için Transformer bölümüne bakın.
F
birkaç kez yönlendirme
Büyük dil modelinin nasıl yanıt vermesi gerektiğini gösteren birden fazla ("birkaç tane") örnek içeren bir istem. Örneğin, aşağıdaki uzun istem, büyük bir dil modeline bir sorgunun nasıl yanıtlanacağını gösteren iki örnek içermektedir.
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | Geniş kapsamlı dil modellerinin yanıtlamasını istediğiniz soru. |
| Fransa: avro | Bir örnek. |
| Birleşik Krallık: GBP | Başka bir örnek. |
| Hindistan: | Gerçek sorgu. |
Az sayıda çekim istemi, genellikle sıfır çekim isteme ve tek seferlik istem işlemlerinden daha istenen sonuçlar verir. Ancak, birkaç çekimlik istem için daha uzun bir istem gerekir.
Az çekimli istemler, isteme dayalı öğrenim için uygulanan bir birkaç çekimle öğrenme biçimidir.
Keman
İstismarcı kod veya altyapı olmadan işlev ve sınıfların değerlerini ayarlayan Python öncelikli bir yapılandırma kitaplığı. Pax ve diğer makine öğrenimi kod tabanları söz konusu olduğunda bu işlevler ve sınıflar, modelleri ve eğitim hiper parametrelerini temsil eder.
Fiddle, makine öğrenimi kod tabanlarının genellikle şu bölümlere ayrıldığını varsayar:
- Katmanları ve optimize edicileri tanımlayan kitaplık kodu.
- Kitaplıkları çağıran ve her şeyi bir arada bağlayan veri kümesi "yapışkan" kodu.
Fiddle, yapıştırıcı kodunun çağrı yapısını değerlendirilmemiş ve değişken bir biçimde yakalar.
ince ayar
Önceden eğitilmiş bir modelde gerçekleştirilen göreve özel ikinci bir eğitim geçişi, modelin parametrelerini belirli bir kullanım alanına göre hassaslaştırıyor. Örneğin, bazı büyük dil modelleri için tam eğitim sırası aşağıdaki gibidir:
- Ön eğitim: Tüm İngilizce Wikipedia sayfaları gibi geniş bir genel veri kümesiyle büyük bir dil modelini eğitin.
- Hassas ayarlama: Önceden eğitilmiş modeli, tıbbi sorgulara yanıt verme gibi belirli bir görevi gerçekleştirecek şekilde eğitin. İnce ayarlar genellikle belirli bir göreve odaklanan yüz veya binlerce örnek içerir.
Başka bir örnek olarak, büyük bir resim modeli için tam eğitim sırası aşağıdaki gibidir:
- Ön eğitim: Wikimedia Commons'taki tüm resimler gibi büyük bir genel resim veri kümesinde büyük bir resim modelini eğitin.
- Hassas ayarlama: Önceden eğitilmiş modeli, orkaların görüntülerini oluşturma gibi belirli bir görevi gerçekleştirecek şekilde eğitin.
Hassas ayarlamalar yapmak için aşağıdaki stratejilerin herhangi bir kombinasyonu gerekebilir:
- Önceden eğitilmiş modelin mevcut parametrelerinin tümünü değiştirme. Buna bazen tam ince ayar denir.
- Önceden eğitilmiş modelin mevcut parametrelerinin yalnızca bazılarını (genellikle çıkış katmanına en yakın katmanlar) değiştirirken diğer mevcut parametreleri değiştirmeden (tipik olarak, katmanlar giriş katmanına en yakın olan katmanlar) değiştirilir. Parametre etkili ayarlama bölümünü inceleyin.
- Genellikle çıkış katmanına en yakın mevcut katmanların üzerine daha fazla katman ekleme.
İnce ayar, bir öğrenme aktarma biçimidir. Bu nedenle, ince ayarda, önceden eğitilmiş modeli eğitmek için kullanılanlardan farklı bir kayıp işlevi veya farklı bir model türü kullanılabilir. Örneğin, giriş görüntüsündeki kuş sayısını döndüren bir regresyon modeli oluşturmak için, önceden eğitilmiş bir büyük görüntü modelinde ince ayar yapabilirsiniz.
İnce ayarları aşağıdaki terimlerle karşılaştırın:
Keten
JAX üzerine inşa edilmiş, derin öğrenme için yüksek performanslı, açık kaynaklı bir kitaplık. Flax, performanslarını değerlendirme yöntemlerinin yanı sıra eğitim nöral ağları için de işlevler sunar.
Keçeli Kalem
Flax üzerinde oluşturulmuş, açık kaynaklı Transformer kitaplığı, özellikle doğal dil işleme ve çok modlu araştırmalar için tasarlanmıştır.
G
üretken yapay zeka
Resmi tanımı olmayan, dönüştürücü bir alan. Bununla birlikte, çoğu uzman, üretici yapay zeka modellerinin aşağıdakilerin tümüne sahip içerikler oluşturabileceği ("üretim") konusunda hemfikirdir:
- karmaşık
- tutarlı
- orijinal
Örneğin, üretken yapay zeka modeli karmaşık makaleler ve görüntüler oluşturabilir.
LSTM ve RNN'ler gibi önceki bazı teknolojiler de orijinal ve tutarlı içerikler oluşturabilir. Bazı uzmanlar bu eski teknolojileri üretken yapay zeka olarak görürken diğerleri gerçek üretici yapay zekanın, önceki teknolojilerin üretebileceğinden daha karmaşık çıkışlar gerektirdiğini düşünüyor.
Tahmine dayalı makine öğrenimi ile kontrast oluşturun.
GPT (Üretken Önceden Eğitilmiş Dönüştürücü)
OpenAI tarafından geliştirilen, Transformer tabanlı bir büyük dil modelleri ailesi.
GPT varyantları, aşağıdakiler dahil birden fazla moda uygulanabilir:
- resim oluşturma (örneğin, ResimGPT)
- metinden görüntü oluşturma (örneğin, DALL-E).
VR
halüsinasyon
Gerçek dünya hakkında iddiada bulunuyormuş gibi görünen üretken yapay zeka modeli tarafından makul görünen ancak gerçekler açısından yanlış sonuçlar üretilmesi. Örneğin, Barack Obama'nın 1865'te öldüğünü iddia eden üretken yapay zeka modeli halüsinasyona neden olur.
İ
bağlam içi öğrenme
Az çekim istem kelimesinin eş anlamlısı.
L
LaMDA (Diyalog Uygulamaları için Dil Modeli)
Google tarafından geliştirilen, Dönüştürücü tabanlı bir büyük dil modeli. Bu model, diyaloglarda gerçekçi yanıtlar oluşturabilen büyük bir diyalog veri kümesiyle eğitilmiş.
LaMDA: Çığır açan sohbet teknolojimiz genel bakış sağlıyor.
dil modeli
Bir jeton veya jeton dizisinin daha uzun bir jeton dizisinde gerçekleşme olasılığını tahmin eden bir model.
büyük dil modeli
Genellikle çok sayıda parametre olan bir dil modelini ifade eden, kesin bir tanımı olmayan gayriresmi bir terim. Bazı büyük dil modelleri 100 milyardan fazla parametre içerir.
M
maskelenmiş dil modeli
Aday jetonlarının bir dizideki boşlukları doldurma olasılığını tahmin eden bir dil modeli. Örneğin, maskeli bir dil modeli, aday kelimelerin aşağıdaki cümledeki alt çizginin yerine geçme olasılığını hesaplayabilir:
Şapkadaki ____ geri geldi.
Literatürde genellikle alt çizgi yerine "MASK" dizesi kullanılmıştır. Örneğin:
Şapkadaki "MASKİ" tekrar görünüyor.
Modern maskeli dil modelleri iki yönlüdür.
meta öğrenme
Bir öğrenme algoritmasını keşfeden veya geliştiren makine öğrenimi alt kümesi. Bir meta öğrenme sistemi, bir modeli az miktarda veriden veya önceki görevlerde edinilen deneyimlerden yeni bir görevi hızlı bir şekilde öğrenecek şekilde eğitmeyi de hedefleyebilir. Meta öğrenme algoritmaları genellikle şunları gerçekleştirmeye çalışır:
- Elle tasarlanmış özellikleri (başlatıcı veya optimize edici gibi) iyileştirin/öğrenin.
- Veri ve işlem açısından daha verimli olun.
- Genellemeyi iyileştirin.
Meta öğrenme, birkaç adımda öğrenme ile ilgilidir.
yöntem
Üst düzey veri kategorisi. Örneğin sayılar, metin, resimler, video ve ses beş farklı moddur.
model paralelliği
Bir model farklı parçalarını farklı model yerleştiren bir eğitim veya çıkarım ölçeklendirme yöntemidir. Model paralelliği, tek bir cihaza sığmayacak kadar büyük modelleri mümkün kılar.
Model paralelliğini uygulamak için bir sistem genellikle aşağıdakileri yapar:
- Modeli parçalara ayırır (bölün).
- Bu küçük parçaların eğitimini birden çok işlemciye dağıtır. Her işlemci, modelin kendi bölümünü eğitir.
- Sonuçları birleştirerek tek bir model oluşturur.
Model paralelliği, eğitimi yavaşlatır.
Ayrıca Veri paralelliği konusuna da bakın.
birden fazla kişinin kendi kendine dikkat etmesi
Giriş sırasındaki her pozisyon için kendi kendine dikkat mekanizmasını birden fazla kez uygulayan bir kendi kendine dikkat uzantısı.
Transformers, birden fazla kişinin kendi kendine dikkat çekmesini sağladı.
çok modlu model
Giriş ve/veya çıkışları birden fazla modalite içeren bir model. Örneğin, hem bir resmi hem de bir metin başlığını (iki yöntem) özellikler olarak alan ve metin başlığının resim için ne kadar uygun olduğunu belirten bir puan veren bir modeli ele alalım. Dolayısıyla, bu modelin girişleri çok modlu ve çıkış tek modludur.
N
doğal dil anlama
Bir kullanıcının yazdıklarına veya söylediklerine dayalı olarak niyetini belirleme. Örneğin, bir arama motoru, kullanıcının yazdığı veya söylediklerine göre ne aradığını belirlemek için doğal dil anlamayı kullanır.
N-gram
N kelimeden oluşan sıralı bir dizi. Örneğin, truly madly 2 gramdır. Düzen alakalı olduğu için, acaba doğrusu ile çok çılgınca farklı bir 2 gramdır.
| N | Bu N-gram türünün adları | Örnekler |
|---|---|---|
| 2 | Bigram veya 2 gram | gidip gitme, öğle yemeği yemek, akşam yemeği yemek |
| 3 | trigram veya 3 gram | çok yemişti, üç kör fare, zil sesi |
| 4 | 4 gram | parkta yürümek, rüzgarda toz yemiş, çocuk mercimek yedi |
Birçok doğal dil anlama modeli, kullanıcının yazacağı veya söyleyeceğiniz bir sonraki kelimeyi tahmin etmek için N-gram'ları kullanır. Örneğin, bir kullanıcının üç görme engelli yazdığını varsayalım. Trigramlara dayalı bir NLU modeli muhtemelen kullanıcının bir sonraki mikrofon türünü tahmin edeceğini tahmin eder.
N-gramları, sıralanmamış kelime kümeleri olan kelime paketi ile karşılaştırın.
NLU
Doğal dil anlama ifadesinin kısaltmasıdır.
O
tek seferlik istem
Büyük dil modelinin nasıl yanıt vermesi gerektiğini gösteren bir örnek içeren bir istem. Örneğin, aşağıdaki istemde, büyük bir dil modelinin bir sorguyu nasıl yanıtlaması gerektiğini gösteren bir örnek bulunmaktadır.
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | Geniş kapsamlı dil modellerinin yanıtlamasını istediğiniz soru. |
| Fransa: avro | Bir örnek. |
| Hindistan: | Gerçek sorgu. |
Tek seferlik istemleri aşağıdaki terimlerle karşılaştırın:
P
parametre açısından verimli ayarlama
Büyük bir önceden eğitilmiş dil modeli (PLM), tamamen ince ayarlamalardan daha verimli bir şekilde ince ayar yapmak için bir dizi teknik. Parametre etkili ayarlamalar, genellikle tam ince ayarlamalardan çok daha az parametrede ince ayar yapar. Ancak genellikle tamamen hassas ayarlamalarla oluşturulan büyük bir dil modeli kadar iyi (veya neredeyse aynı düzeyde) performans gösteren büyük bir dil modeli üretir.
Parametre açısından verimli ayarları aşağıdakilerle karşılaştırın:
Parametreyi verimli şekilde ayarlama, parametre açısından verimli ince ayar olarak da bilinir.
ardışık düzen
Bir modelin işlemesinin ardışık aşamalara ayrıldığı ve her aşamanın farklı bir cihazda yürütüldüğü bir model paralelliği biçimi. Bir aşama bir grubu işlerken önceki aşama sonraki toplu işlem üzerinde çalışabilir.
Ayrıca aşamalı eğitim konusuna bakın.
PLM
Önceden eğitilmiş dil modeli'nin kısaltmasıdır.
konumsal kodlama
Bir jetonun yerleştirmesine bir dizideki konumu hakkında bilgi eklemek için kullanılan teknik. Dönüştürücü modelleri, dizinin farklı bölümleri arasındaki ilişkiyi daha iyi anlamak için konumsal kodlamadan yararlanır.
Konumsal kodlamanın yaygın bir uygulaması, sinüsoid fonksiyon kullanır. (Özellikle sinüzoit işlevin sıklığı ve genliği, jetonun dizideki konumuna göre belirlenir.) Bu teknik, bir transformatör modelinin, konumlarına göre dizinin farklı bölümlerine bakmayı öğrenmesini sağlar.
önceden eğitilmiş model
Eğitilmiş modeller veya model bileşenleri (yerleştirme vektör gibi). Bazen, önceden eğitilmiş yerleştirilmiş vektörleri bir nöral ağa feedlersiniz. Diğer durumlarda, modeliniz önceden eğitilmiş yerleştirmelere bağlı kalmak yerine yerleştirme vektörlerini eğitir.
Önceden eğitilmiş dil modeli terimi, eğitim öncesi süreçlerden geçmiş büyük bir dil modelini ifade eder.
ön eğitim
Büyük bir veri kümesi üzerinde bir modelin ilk eğitimi. Bazı önceden eğitilmiş modeller sakar devlerdir ve genellikle ek eğitimlerle iyileştirilmesi gerekir. Örneğin, makine öğrenimi uzmanları Wikipedia'daki tüm İngilizce sayfalar gibi geniş bir metin veri kümesi üzerinde büyük bir dil modelini önceden eğitebilir. Ön eğitimin ardından ortaya çıkan model, aşağıdaki tekniklerden herhangi biri kullanılarak daha da hassaslaştırılabilir:
istem
Modelin belirli bir şekilde davranmasını sağlamak için büyük bir dil modeline girdi olarak girilen herhangi bir metin. İstemler bir cümle kadar kısa veya rastgele uzun olabilir (örneğin, bir roman metninin tamamı). İstemler, aşağıdaki tabloda gösterilenler de dahil olmak üzere birden fazla kategoriye ayrılır:
| İstem kategorisi | Örnek | Notlar |
|---|---|---|
| Soru | Bir güvercin ne kadar hızlı uçabilir? | |
| Talimat | Arbitraj hakkında komik bir şiir yazın. | Büyük dil modelinden bir şey yapmasını isteyen bir istem. |
| Örnek | Markdown kodunu HTML'ye çevirin. Örneğin:
Markdown: * liste öğesi HTML: <ul> <li>liste öğesi</li> </ul> |
Bu örnek istemdeki ilk cümle bir talimattır. İstemin geri kalanı örnektir. |
| Rol | Fizik alanında doktora yapmak için makine öğrenimi eğitiminde gradyan inişin neden kullanıldığını açıklayın. | Cümlenin ilk bölümü bir talimattır. "Fizik doktorasına" ifadesi ise rol kısmıdır. |
| Modelin tamamlanması için kısmi giriş | Birleşik Krallık Başbakanı'nın yaşadığı yer: | Kısmi giriş istemi aniden (bu örnekte olduğu gibi) veya alt çizgiyle sona erebilir. |
Üretken yapay zeka modeli, isteklere metin, kod, resimler, yerleştirmeler, videolar gibi neredeyse her şeyle yanıt verebilir.
istem temelli öğrenim
Davranışlarını rastgele metin girişine (istemler) göre uyarlamalarını sağlayan belirli modeller özelliği. Tipik bir isteme dayalı öğrenme paradigmasında, büyük bir dil modeli bir isteğe metin oluşturarak yanıt verir. Örneğin, bir kullanıcının aşağıdaki istemi girdiğini varsayalım:
Newton'un Üçüncü Hareket Yasası'nı özetleyin.
İstem tabanlı öğrenme yapabilen bir model, önceki istemi yanıtlamak için özel olarak eğitilmemiştir. Bu model daha çok fizik ve genel dil kuralları hakkında pek çok olguyu ve genel olarak faydalı yanıtları oluşturan şeyler hakkında pek çok bilgiyi "bilgilendirir". Bu bilgi (umarım) faydalı bir cevap vermek için yeterlidir. İnsanlardan gelen ek geri bildirimler ("Bu cevap çok karmaşıktı" veya "Tepki nedir?") bazı istem temelli öğrenim sistemlerinin, yanıtlarının yararlılığını kademeli olarak iyileştirmesini sağlar.
istem tasarımı
istem mühendisliği ile eş anlamlı kelime.
istem mühendisliği
Büyük bir dil modelinden istenen yanıtları almak için istemler oluşturma sanatı. İnsanlar hızlı mühendislik işlemi yapar. İyi yapılandırılmış istemler yazmak, büyük bir dil modelinden faydalı yanıtlar almanın önemli bir parçasıdır. Hızlı mühendislik, aşağıdakiler de dahil birçok faktöre bağlıdır:
- Büyük dil modelini önceden eğitmek ve muhtemelen ince ayar yapmak için kullanılan veri kümesidir.
- Modelin yanıt oluşturmak için kullandığı sıcaklık ve diğer kod çözme parametreleri.
Faydalı istemler yazma hakkında daha fazla bilgi edinmek için İstem tasarımına giriş bölümüne bakın.
İstem tasarımı, istem mühendisliği ile eş anlamlıdır.
istem ayarlama
Sistemin gerçek isteme eklediği bir "ön eki" öğrenen bir parametre verimli ayarlama mekanizması.
Bazen önek ayarlama olarak da adlandırılan istem ayarlamanın bir varyasyonu, ön eki her katmana eklemektir. Buna karşılık, çoğu istem ayarı giriş katmanına yalnızca bir ön ek ekler.
R
rol isteme
Üretken yapay zeka modelinin yanıtı için hedef kitleyi tanımlayan istemin isteğe bağlı bölümü. Rol istemi olmadığında büyük bir dil modeli, soruları soran kişi için yararlı olabilecek veya olmayabilecek bir cevap sağlar. Büyük bir dil modeli, rol istemi ile belirli bir hedef kitle için daha uygun ve daha faydalı bir şekilde yanıt verebilir. Örneğin, aşağıdaki istemlerin rol istemi bölümü kalın harflerle gösterilmiştir:
- Ekonomik doktora için bu makaleyi özetleyin.
- On yaşındaki bir çocuğun dalgaların nasıl işlediğini açıklayın.
- 2008 ekonomik krizini açıklama. Küçük bir çocuğa veya bir Golden Retriever'a gibi konuşun.
S
kendine dikkat etme (kendine dikkat katmanı olarak da adlandırılır)
Bir yerleştirme dizisini (örneğin, jeton yerleştirmeleri) başka bir yerleştirme dizisine dönüştüren bir nöral ağ katmanı. Çıkış dizisindeki her yerleştirme, bir dikkat mekanizması aracılığıyla giriş dizisi öğelerindeki bilgilerin entegre edilmesiyle oluşturulur.
Kendine dikkat çekmenin kendine bölümü, başka bir bağlamdan ziyade kendine katılan sırayı ifade eder. Kendine dikkat etme, Transformers'ın ana yapı taşlarından biridir ve "sorgu", "anahtar" ve "değer" gibi sözlük arama terminolojisini kullanır.
Kendine dikkat katmanı, her kelime için bir giriş temsilleri dizisiyle başlar. Bir kelimenin giriş gösterimi, basit bir yerleştirme olabilir. Ağ, bir giriş sırasındaki her kelime için, kelimenin tüm kelime dizisindeki her öğeyle alaka düzeyini puanlar. Alaka düzeyi puanları, bir kelimenin nihai temsilinin diğer kelimelerin temsillerini ne kadar içerdiğini belirler.
Örneğin, aşağıdaki cümleyi ele alalım:
Hayvan çok yorgun olduğu için sokağın karşıya geçmedi.
Aşağıdaki çizimde (Transformer: A Novel Neural Network Architecture for Language Anlama (Dil Anlama): Yeni Bir Nöral Ağ Mimarisi ’nden), it zamiri için kendine dikkat katmanının dikkat kalıbı gösterilmektedir. Her satırın koyuluğu, her kelimenin temsile ne kadar katkıda bulunduğunu belirtir:
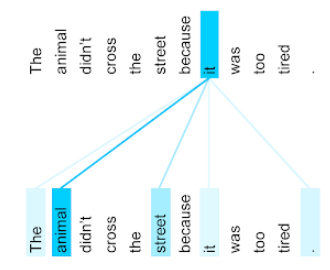
Kendine dikkat katmanı, "kendine" ile alakalı kelimeleri vurgular. Bu durumda dikkat katmanı, anim ile alakalı kelimeleri vurgulayarak en yüksek ağırlığı hayvan türüne atamıştır.
Bir n jeton dizisi için kendine dikkat etme, bir dizi yerleştirmeyi n kez olacak şekilde, dizideki her konumda bir kez olacak şekilde dönüştürür.
Ayrıca dikkat yapma ve birçok kişinin kendi kendine dikkat çekmesini ifade edin.
yaklaşım analizi
Bir grubun bir hizmete, ürüne, kuruluşa veya konuya karşı genel yaklaşımını (olumlu ya da olumsuz) belirlemek için istatistiksel veya makine öğrenimi algoritmalarını kullanma. Örneğin, doğal dil anlama özelliğini kullanan bir algoritma, öğrencilerin kursu genel olarak ne kadar beğendiğini veya beğenmediğini belirlemek için üniversite dersinden alınan metinsel geri bildirimlerde duygu analizi gerçekleştirebilir.
sıralı görevi
Jeton giriş dizisini jeton çıkış sırasına dönüştüren bir görev. Örneğin, popüler iki tür sıralı görev şunlardır:
- Çevirmenler:
- Örnek giriş dizisi: "Seni seviyorum."
- Örnek çıkış sırası: "Je t'aime".
- Soru yanıtlama:
- Örnek giriş dizisi: "İstanbul'da arabama ihtiyacım var mı?"
- Örnek çıkış sırası: "Hayır. Lütfen arabanızı evde tutun."
seyrek özellik
Değerleri çoğunlukla sıfır veya boş olan bir özellik. Örneğin, tek bir 1 değeri ve bir milyon 0 değeri içeren bir özellik seyrek sayılır. Buna karşılık, yoğun bir özellik çoğunlukla sıfır veya boş olmayan değerlere sahiptir.
Makine öğreniminde şaşırtıcı sayıda özellik, seyrek özelliklerdir. Kategorik özellikler genellikle seyrek özelliklerdir. Örneğin, bir ormandaki 300 olası ağaç türü arasından tek bir örnekte yalnızca bir akçaağaç tanımlanabilir. Ya da bir video kitaplığındaki milyonlarca olası video arasından tek bir örnek sadece "Kazablanka"yı tanımlamak olabilir.
Bir modelde genellikle tek sıcak kodlama ile seyrek özellikleri temsil edersiniz. Tek seferlik kodlama büyükse daha yüksek verimlilik için tek sıcak kodlamanın üzerine bir yerleştirme katmanı yerleştirebilirsiniz.
seyrek gösterim
Seyrek bir özellikte yalnızca sıfır olmayan öğelerin konumlarını depolama.
Örneğin, species adlı kategorik bir özelliğin belirli bir ormandaki 36 ağaç türünü tanımladığını varsayalım. Ayrıca her örneğin yalnızca tek bir türü tanımladığını varsayalım.
Her örnekte ağaç türlerini temsil etmek için tek sıcak vektör kullanabilirsiniz.
Tek sıcak vektör tek bir 1 (bu örnekteki belirli ağaç türünü temsil etmek için) ve 35 0 (bu örnekte değil) 35 ağaç türünü temsil eder. Dolayısıyla, maple teriminin tek sıcak temsili aşağıdaki gibi görünebilir:

Alternatif olarak, seyrek gösterim kullanılarak belirli bir türün konumu
belirlenebilir. maple 24. konumdaysa maple için seyrek temsili şöyle olur:
24
Seyrek temsilin, tek seferlik gösterimden çok daha kompakt olduğuna dikkat edin.
Biraz daha karmaşık bir örnek için simgeyi tıklayın.
Modelinizdeki her bir örneğin, İngilizce cümledeki kelimeleri (bu kelimelerin sırasını değil) temsil etmesi gerektiğini varsayalım. İngilizce yaklaşık 170.000 kelimeden oluştuğu için, İngilizce yaklaşık 170.000 öğe içeren kategorik bir özelliktir. Çoğu İngilizce cümle bu 170.000 kelimenin çok küçük bir kısmını kullanır. Bu nedenle tek bir örnekteki kelime kümesi neredeyse kesinlikle seyrek veri oluşturur.
Şu cümleyi ele alalım:
My dog is a great dog
Bu cümledeki kelimeleri temsil etmek için tek sıcak vektör varyantını kullanabilirsiniz. Bu varyantta, vektördeki birden fazla hücre sıfır dışında bir değer içerebilir. Ayrıca, bu varyantta bir hücre, bir tam sayı dışında bir tam sayı içerebilir. "Benim", "bir", "bir" ve "harika" kelimeleri cümle içinde sadece bir kez geçse de, "köpek" kelimesi iki kez geçmektedir. Bu cümledeki kelimeleri temsil etmek için bir sıcak vektörlerin bu varyantını kullanmak,aşağıdaki 170.000 öğeli vektörü verir:

Aynı cümlenin seyrek temsili şöyle olmalıdır:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
aşamalı eğitim
Bir modeli ayrı aşamalarda eğitme taktiği. Amaç eğitim sürecini hızlandırmak veya model kalitesini artırmak olabilir.
Aşağıda progresif yığma yaklaşımının bir çizimi gösterilmiştir:
- 1. Aşama 3 gizli katman, 2. aşama 6 gizli katman, 3. aşama ise 12 gizli katman içerir.
- 2. Aşama, 1. Aşama'nın 3 gizli katmanında öğrenilen ağırlıklarla eğitime başlar. 3. Aşama, 2. Aşama'nın 6 gizli katmanında öğrenilen ağırlıklarla eğitime başlar.
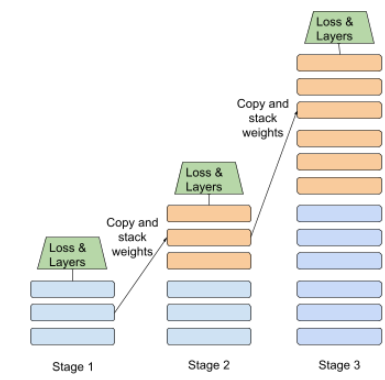
Ayrıca ardışık düzen bölümünü de inceleyin.
T
T5
Google AI tarafından 2020'de kullanıma sunulan metin okuma öğrenim aktarma modeli. T5, Transformer mimarisine dayalı, son derece büyük bir veri kümesinde eğitilmiş bir kodlayıcı-kod çözücü modelidir. Metin oluşturma, dilleri çevirme ve soruları diyalog çerçevesinde yanıtlama gibi çeşitli doğal dil işleme görevlerinde etkilidir.
T5, adını "Metin-Metin Aktarım Dönüştürücüsü "ndeki beş T'den alır.
T5X
Büyük ölçekli doğal dil işleme (NLP) modelleri oluşturup eğitmek için tasarlanmış açık kaynaklı bir makine öğrenimi çerçevesidir. T5, T5X kod tabanında uygulanır (JAX ve Flax üzerinde oluşturulur).
sıcaklık
Bir model çıkışının rastgelelik derecesini kontrol eden bir hiperparametre. Yüksek sıcaklıklar daha fazla rastgele çıkışla, düşük sıcaklıklar ise daha az rastgele çıkışla sonuçlanır.
En iyi sıcaklığın seçilmesi uygulamaya ve model çıktısının istenen özelliklerine bağlıdır. Örneğin, reklam öğesi çıktısı üreten bir uygulama oluştururken muhtemelen sıcaklığı yükseltirsiniz. Buna karşılık, modelin doğruluğunu ve tutarlılığını iyileştirmek için resimleri veya metni sınıflandıran bir model oluştururken muhtemelen sıcaklığı düşürürsünüz.
Sıcaklık genellikle softmax ile kullanılır.
metin aralığı
Bir metin dizesinin belirli bir alt bölümüyle ilişkilendirilmiş dizi dizini aralığı.
Örneğin s="Be good now" Python dizesindeki good kelimesi, 3 ile 6 arasındaki metin aralığını kaplar.
token
Bir dil modelinde, modelin eğitim aldığı ve üzerinde tahminde bulunduğu atom birimi. Jeton genellikle şunlardan biridir:
- Örneğin, "kedi gibi köpekler" ifadesi üç kelimeden oluşur: "köpekler", "beğen" ve "kediler".
- bir karakter; örneğin, "bisiklet balığı" ifadesi dokuz karakterli jetondan oluşur. (Boş alanın jetonlardan biri olarak sayıldığını unutmayın.)
- alt kelimeler; tek bir kelime tek bir jeton veya birden fazla jeton olabilir. Alt kelime, bir kök kelime, ön ek veya bir son ekten oluşur. Örneğin, alt kelimeleri jeton olarak kullanan bir dil modeli, "köpekler" kelimesini iki simge (kök kelimesi "köpek" ve çoğul son ek "s") olarak görebilir. Aynı dil modelinde, tek "daha uzun" kelimesi iki alt kelime (kök "tall" kelimesi ve "er" son eki) olarak görülebilir.
Jetonlar, dil modellerinin dışındaki alanlarda diğer atom birimi türlerini temsil edebilir. Örneğin, bilgisayar görüşünde jeton, bir görüntünün alt kümesi olabilir.
Transformatör
Google'da geliştirilen ve dönüşümlere veya yinelenen nöral ağlara dayanmadan, bir dizi giriş yerleştirmesini bir dizi çıktı yerleştirmesine dönüştürmek için kendi kendine dikkat mekanizmalarına dayanan bir nöral ağ mimarisidir. Bir transformatör, kendi kendine dikkat katmanlarından oluşan bir yığın olarak görülebilir.
Transformatör aşağıdakilerden herhangi birini içerebilir:
- Kodlayıcı
- kod çözücü
- hem kodlayıcı hem de kod çözücü
Kodlayıcı, bir yerleştirme dizisini aynı uzunluktaki yeni bir diziye dönüştürür. Bir kodlayıcı, her biri iki alt katman içeren N tane özdeş katman içerir. Bu iki alt katman, giriş yerleştirme sırasının her bir konumuna uygulanır ve dizinin her bir öğesi yeni bir yerleştirmeye dönüştürülür. İlk kodlayıcı alt katmanı, giriş sırasından bilgileri toplar. İkinci kodlayıcı alt katmanı, birleştirilmiş bilgileri bir çıkış yerleştirmeye dönüştürür.
Kod çözücü, bir giriş yerleştirme sırasını muhtemelen farklı uzunluktaki bir çıkış yerleştirme dizisine dönüştürür. Kod çözücü ayrıca, ikisi kodlayıcı alt katmanlarına benzeyen üç alt katmanı olan N tane özdeş katman içerir. Üçüncü kod çözücü alt katmanı, kodlayıcının çıktısını alır ve buradan bilgi toplamak için kendi kendine dikkat mekanizmasını uygular.
Transformer: A Novel Nural Network Architecture for Language Understanding (Dönüştürücü: Dil Anlamaya Yönelik Yeni Bir Nöral Ağ Mimarisi) blog yayını Transformers ile ilgili iyi bir giriş niteliğindedir.
trigram
N=3 olan bir N-gram.
U
tek yönlü
Yalnızca metnin hedef bölümünün önünden önce gelen metni değerlendiren bir sistem. Buna karşılık, çift yönlü bir sistem, metnin hem öncesinde bulunan hem de takip eden metni değerlendirir. Daha fazla ayrıntı için iki yönlü belgeye bakın.
tek yönlü dil modeli
Olasılıklarını yalnızca hedef jetonlardan sonra değil, öncesinde görünen jetonlara dayandıran bir dil modeli. İki yönlü dil modeliyle kontrast.
V
varyasyon otomatik kodlayıcı (VAE)
Girişlerin değiştirilmiş versiyonlarını oluşturmak için giriş ve çıkışlar arasındaki tutarsızlıktan yararlanan bir otomatik kodlayıcı türü. Varyant otomatik kodlayıcılar üretici yapay zeka için yararlıdır.
VAE'ler, varyasyon çıkarımına dayanır. Bu, bir olasılık modelinin parametrelerinin tahminini hesaplamak için kullanılan bir tekniktir.
W
kelime yerleştirme
Bir yerleştirme vektör içinde bulunan kelime kümesindeki her bir kelimeyi temsil etme; diğer bir deyişle, her kelimeyi 0,0 ile 1,0 arasındaki kayan nokta değerlerinin vektörü olarak temsil eder. Benzer anlamları olan kelimeler, farklı anlamlara sahip kelimelere kıyasla daha çok benzer temsillere sahiptir. Örneğin, havuç, kereviz ve salatalık nispeten benzer temsillere sahiptir. Bu, uçak, güneş gözlüğü ve diş macununun temsillerinden çok farklıdır.
Z
sıfır atış istemi
Büyük dil modelinin nasıl yanıt vermesini istediğinizle ilgili bir örnek sağlamayan istem. Örneğin:
| Bir istemin bölümleri | Notlar |
|---|---|
| Belirtilen ülkenin resmi para birimi nedir? | Geniş kapsamlı dil modellerinin yanıtlamasını istediğiniz soru. |
| Hindistan: | Gerçek sorgu. |
Büyük dil modeli, aşağıdakilerden herhangi biriyle yanıt verebilir:
- Rupi
- INR
- ₹
- Hint rupisi
- Rupi
- Hint rupisi
Belirli bir biçimi tercih edebilirsiniz ancak tüm yanıtlar doğrudur.
Sıfır çekim istemini aşağıdaki terimlerle karşılaştırın: