本頁包含「圖片模型」詞彙表詞彙。如要查看所有詞彙解釋,請按這裡。
A
擴增實境
這項技術會在使用者真實世界的檢視畫面中疊加電腦產生的圖片,藉此提供複合檢視。
Autoencoder
學習從輸入中擷取最重要的資訊的系統。自動編碼器是編碼器和解碼器的組合。自動編碼器需要以下兩個步驟:
- 編碼器會將輸入對應至 (通常) 有損低維度 (中繼) 格式。
- 解碼器會將較低維度的格式對應至原始的高維度輸入格式,來建構原始輸入的失真版本。
自動編碼器是經過端對端訓練,方法是讓解碼器盡可能根據編碼器的中繼格式重新建構原始輸入內容。由於中繼格式比原始格式小 (尺寸較低),因此自動編碼器必須瞭解輸入內容中的重要資訊,而輸出內容不會與輸入內容完全相同。
例如:
- 如果輸入資料是圖形,非完全副本會與原始圖形類似,但有些修改。非完全文案可能導致原始圖像中的雜訊移除,或是填滿部分缺少像素的雜訊。
- 如果輸入資料是文字,自動編碼器就會產生新文字來模仿原始文字 (但並非完全相同)。
另請參閱變分自動編碼器。
自動迴歸模型
「模型」model,可依據其之前的預測結果推斷預測。例如,自動迴歸語言模型會根據先前預測的符記預測下一個權杖。所有以 Transformer 為基礎的大型語言模型皆會自動迴歸。
相反地,以 GAN 為基礎的圖片模型通常不會自動迴歸,因為這會在單向傳遞作業中產生圖片,且不反覆疊代處理。不過,某些圖片產生模型「會」自動迴歸,因為這會在步驟中產生圖像。
B
定界框
在圖片中,矩形周圍的矩形 (x、y) 座標 (例如下圖中的狗)。

C
卷積
在數學課中,我們搭配使用兩種功能。在機器學習中,卷積會混合使用卷積篩選器和輸入矩陣,藉此訓練權重。
如果沒有捲積,機器學習演算法必須學習大型「張量」中每個儲存格的個別權重。舉例來說,系統會強制使用 2K x 2K 圖片的機器學習演算法訓練,找出 400 萬個不同的權重。藉助卷積,機器學習演算法只需要在卷積篩選器中每個細胞中找出權重,即可大幅減少訓練模型所需的記憶體。套用卷積篩選器時,系統會在儲存格間複製,讓每個儲存格都會乘以篩選器。
卷積篩選器
卷積運算中的兩位演員之一。(另一個執行者是輸入矩陣的一部分)。卷積篩選器是一種矩陣,其排名與輸入矩陣相同,但形狀較小。例如,假設使用的是 28x28 輸入矩陣,篩選器可以是小於 28x28 的任何 2D 矩陣。
在攝影操作中,卷積濾鏡中所有的儲存格通常都會設為 1 和 0 的常數模式。在機器學習中,卷積篩選器通常會以隨機數字播種,然後網路訓練是最理想的值。
卷積層
深層類神經網路層,卷積篩選器會沿著輸入矩陣傳遞。舉例來說,請考慮使用以下 3x3 卷積篩選器:
![含有下列值的 3x3 矩陣:[[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=zh-tw)
下列動畫顯示的捲積層包含包含 5x5 輸入矩陣的 9 個卷積運算。請注意,每項卷積運算在輸入矩陣的 3x3 部分上執行作業。產生的 3x3 矩陣 (右側) 包含 9 個卷積運算的結果:
![顯示兩個矩陣的動畫。第一個矩陣為 5x5 矩陣:[[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179]], [37,
28,92,195,179]], [37,
第二個矩陣為 3x3 矩陣:[[181,303,618], [115,338,605], [169,351,560]。
第二個矩陣的計算方式是透過對 5x5 矩陣的不同 3x3 子集套用卷積濾鏡 [[0, 1, 0], [1, 0, 1], [0, 1, 0]]。](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=zh-tw)
卷積類神經網路
「類神經網路」,其中至少有一個層是卷積層。典型的捲積類神經網路包含下列層的組合:
卷積類神經網路在處理圖片辨識等特定類型的問題時,可以大獲成功。
卷積運算
下列兩步驟數學運算:
- 卷積篩選器的元素層級乘法和輸入矩陣的配量。(輸入矩陣的配量與卷積篩選器具有相同的排名和大小)。
- 產生的產品矩陣所有值的總和。
例如,請思考下列的 5x5 輸入矩陣:
![5x5 矩陣:[[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195, [33,28,92,195, [37,40]],10](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=zh-tw)
現在請設想下列 2x2 卷積濾鏡:
![2x2 矩陣:[[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=zh-tw)
每個卷積運算都涉及一個 2x2 配量的輸入矩陣。例如,假設我們使用輸入矩陣左上方的 2x2 配量。因此,這個配量的捲積運算如下所示:
![將卷積濾鏡 [[1, 0], [0, 1]] 套用至輸入矩陣的左上角 2x2 區段,也就是 [[128,97], [35,22]。卷積篩選器保持 128 和 22 不變,但會使 97 和 35 保持零。因此,卷積運算會產生 150 值 (128+22)。](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=zh-tw)
卷積層包含一系列的捲積運算,每個運算都代表輸入矩陣的不同部分。
D
資料擴增
藉由轉換現有的範例來建立其他範例,以人工方式提高訓練範例的範圍和數量。例如,提供圖片是其中一個特徵,但您的資料集未包含足夠的圖片範例,無法讓模型學習實用的關聯。在理想情況下,您應將足夠的已加上標籤圖片新增至資料集,使模型能夠正確訓練。如果不可行,擴增資料可以旋轉、延展並反映每張圖片,產生許多原始圖片的變化版本,這樣或許能產生足夠的標籤資料,進而提供絕佳的訓練。
深度分隔卷積類神經網路 (sepCNN)
以程序為基礎的卷積類神經網路架構,但其中 Inception 模組會替換為深度可分離的捲積。也稱為 Xception。
深度可分離的捲積 (縮寫為可分隔卷積) 會將標準的 3D 卷積加至兩個獨立的捲積運算,以獲得有效的計算效率:第一、深度卷積、深度為 1 (n × n x 1),以及 × 1 (寬度為 1),第二點為 ×1。
詳情請參閱Xception: Deep Learning with Depthwise Separable Convolutions。
降低取樣
超載字詞可能代表下列其中一個情況:
- 減少特徵中的資訊量,以更有效率的方式訓練模型。例如在訓練圖片辨識模型之前,將高解析度圖片縮減為較低解析度的格式。
- 針對弱勢類別範例的比例過低 (不成比例) 進行訓練,以改善弱勢族群的模型訓練成效。例如,在類別-不平衡資料集中,模型往往瞭解主要類別,對於次要類別仍不夠瞭解。降低取樣有助於平衡多數和少數類別的訓練量。
F
微調
在預先訓練模型上執行第二條工作專屬的訓練傳遞,藉此修正特定用途的參數。舉例來說,部分大型語言模型的完整訓練序列如下:
- 預先訓練:針對龐大的一般資料集 (例如所有英文維基百科頁面) 訓練大型語言模型。
- 微調:訓練預先訓練模型來執行特定工作,例如回應醫療查詢。微調通常會涉及數百或數千個以特定工作為主的範例。
再舉一個例子,大型圖片模型的完整訓練序列如下:
- 預先訓練:根據龐大的「一般」圖片資料集訓練大型圖片模型,例如 Wikimedia 常見問題中的所有圖片。
- 微調:訓練預先訓練模型來執行特定工作,例如產生虎鯨的圖片。
微調可涵蓋下列任何策略的組合:
- 修改「所有」預先訓練模型的現有參數。這種做法有時稱為「完整微調」。
- 只修改「部分」預先訓練模型的現有參數 (通常是最靠近輸出層的圖層),同時保留其他現有的參數 (通常是最靠近輸入層的圖層)。請參閱「具參數運用效率的調整」一節。
- 新增更多圖層,通常位於最靠近輸出層的現有圖層上方。
微調是一種遷移學習形式。因此,微調可能會使用不同的損失函式,或與用來訓練預先訓練模型的模型類型不同。例如,您可以微調預先訓練的大型圖片模型,產生迴歸模型,藉此傳回輸入圖片中的鳥類數量。
比較及對照下列字詞的微調設定:
G
生成式 AI
沒有正式定義的新興變革領域。話雖如此,多數專家也認為生成式 AI 模型能夠建立 (「產生」) 內容具有以下特質:
- 複雜
- Coherent
- 原始圖片
舉例來說,生成式 AI 模型可以建立複雜論文或圖片,
部分早期技術 (包括 LSTM 和 RNN) 也可能會產生原創且一致的內容。有些專家認為這些早期技術是生成式 AI,有些專家則認為,真正的生成式 AI 的輸出結果會比早期技術產生的複雜性更高。
與預測式機器學習相反。
I
圖片辨識
將圖片中的物件、模式或概念分類的程序。圖片辨識也稱為「圖片分類」。
詳情請參閱機器學習實務:圖片分類一文。
交叉路口 (IoU)
兩組的交集除以其聯集。在機器學習圖片偵測工作中,IoU 可用來評估模型預測定界框與真值定界框的準確率。在這種情況下,兩個方塊的 IoU 是指重疊區域與總面積之間的比率,其值範圍從 0 (預測定界框與真值定界框沒有重疊) 到 1 (預測定界框與真值定界框具有相同的座標)。
例如,在下圖中:
- 預測的定界框 (也就是模型預測繪畫中夜間資料表位置的座標) 以紫色標出。
- 真值定界框 (代表畫作中夜間資料表實際位置的座標) 的外框以綠色外框表示。
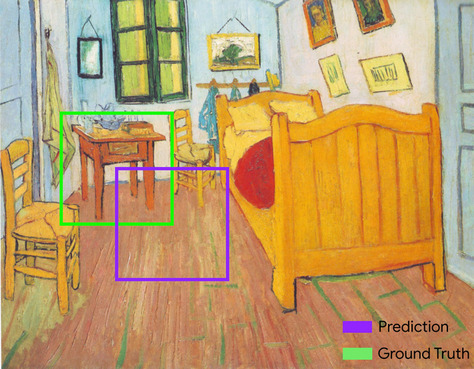
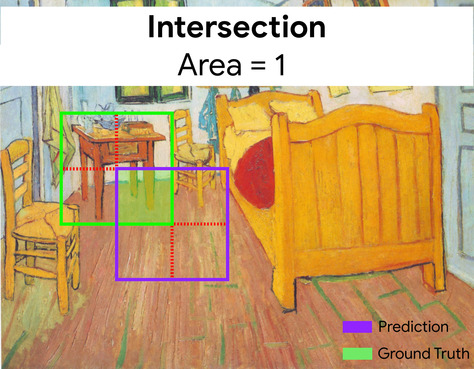
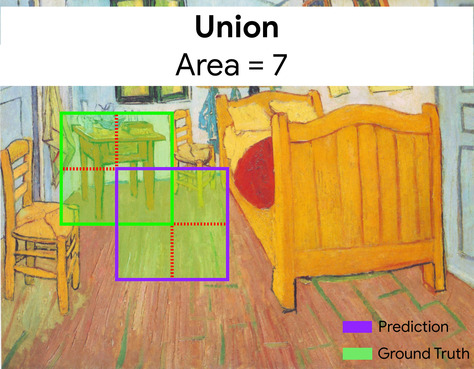
在這裡,預測和真值定界框的交界點 (左下方) 為 1,預測和真值定界框的聯集 (右下方) 為 7,因此 IoU 為 \(\frac{1}{7}\)。
K
關鍵點
圖片中特定地圖項目的座標。舉例來說,如果是用來區分花卉物種的圖片辨識模型,關鍵點可能是每隻花瓣的中心點、詞幹、 Stem 等。
L
地標
鍵控點的同義詞。
M
MNIST
公開網域資料集由 LeCun、Cortes 和 Burges 彙整,內含 60,000 張圖片,每張圖片顯示人類如何手動撰寫特定數字 (0 至 9)。每張圖片都會以 28x28 的整數陣列儲存,其中每個整數都是介於 0 至 255 (含) 之間的灰階值。
MNIST 是機器學習的標準資料集,通常用於測試新的機器學習做法。詳情請參閱 手寫數字的 MNIST 資料庫。
P
游泳池
將先前的卷積層建立的矩陣 (或矩陣) 縮減為較小的矩陣。集區通常需要取集區區域內的最大值或平均值。例如,假設有下列 3x3 矩陣:
![3x3 矩陣 [[5,3,1], [8,2,5], [9,4,3]。](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?hl=zh-tw)
池化運算和卷積運算一樣,會將矩陣分割為配量,然後滑出卷積運算三角。舉例來說,假設集區運算將卷積矩陣分割為 1x1 步距的 2x2 區塊。如下圖所示,系統會進行四個集區作業。假設每個集區運算只挑選該區塊中四值的最大值:
![輸入矩陣為 3x3,其值為 [[5,3,1], [8,2,5], [9,4,3]。輸入矩陣的左上角 2x2 子矩陣為 [[5,3], [8,2]],因此左上方集區運算會產生 8 值 (上限為 5、3、8 和 2)。輸入矩陣的右上角 2x2 子矩陣為 [[3,1], [2,5]],因此右上方集區運算會產生值 5。輸入矩陣的左下 2x2 子矩陣為 [[8,2], [9,4]],因此左下方的集區運算會產生值 9。輸入矩陣的右下方 2x2 子矩陣為 [[2,5], [4,3]],因此右下角集區運算會產生值 5。總而言之,集區運算會產生 2x2 矩陣 [[8,5], [9,5]]。](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=zh-tw)
集區有助於在輸入矩陣中強制執行翻譯變異數。
視覺應用程式集區稱為「空間集區」。時間序列應用程式通常稱為「臨時集區」。格式較不正式,資料集區通常稱為「向下取樣」或「降低取樣」。
預先訓練模型
已經過訓練的模型或模型元件 (例如嵌入向量)。 有時候,您必須將預先訓練的嵌入向量饋送到類神經網路中。有時候,模型會自行訓練嵌入向量,而不是依賴預先訓練的嵌入。
「預先訓練的語言模型」一詞是指已完成預先訓練的大型語言模型。
預先訓練
大型資料集上的模型初始訓練。部分預先訓練模型是笨拙的巨人,通常必須透過額外訓練進行修正。舉例來說,機器學習專家可能會針對大型文字資料集 (例如維基百科中的所有英文頁面) 預先訓練大型語言模型。預先訓練之後,您可以透過下列任一技巧進一步修正產生的模型:
R
旋轉不變
在圖片分類問題中,即使圖片方向改變,演算法仍能成功分類圖片。舉例來說,演算法仍可識別網球拍,可以是向上、左右或向下。請注意,旋轉變數不一定是想要的;例如,上下 9 不應歸類為 9。
六
大小差異
在圖片分類問題中,即使圖片大小改變,演算法仍能成功分類圖片。舉例來說,演算法仍可辨別使用 200 萬像素或 20 萬像素的貓。請注意,即使是最好的圖片分類演算法,在大小變數方面仍有實際的限制。舉例來說,演算法 (或人工) 可能無法將僅耗用 20 像素的貓咪圖片正確分類。
空間集區
請參閱「集區」。
跨步
在卷積運算或集區中,下一個輸入片段中每個維度的差異。舉例來說,下列動畫展示卷積運算期間的 (1,1) 步距。因此,下一個輸入片段會從前一個輸入片段的右側開始一個位置。當運算到達右邊緣時,下一個片段會一直到左側,但往下一個位置。
上述範例為二維步線。如果輸入矩陣為 3D 範圍,則步距也為 3D。
向下取樣
請參閱「集區」。
T
溫度
控制模型輸出隨機度量的「超參數」。溫度越高,隨機輸出的次數就越多,而隨機性越低則產生較少隨機輸出。
要選擇最佳溫度,取決於特定應用程式及模型輸出內容的所需屬性。舉例來說,您可能在建立用於產生廣告素材輸出內容的應用程式時調高溫度。相反地,在建構可將圖片或文字分類的模型時,建議您降低溫度,以改善模型的準確率與一致性。
溫度經常與 softmax 搭配使用。
差異化翻譯
在圖片分類問題中,即使圖片中的物件位置有所變更,演算法仍能成功分類圖片。舉例來說,演算法仍可識別犬隻,無論它位於影格中心或末端。