หน้านี้มีคำศัพท์ในอภิธานศัพท์พื้นฐาน ML ดูคำศัพท์ทั้งหมดในอภิธานศัพท์ คลิกที่นี่
A
ความแม่นยำ
จำนวนการคาดการณ์การจัดประเภทที่ถูกต้องหารด้วยจำนวนการคาดการณ์ทั้งหมด โดยการ
ตัวอย่างเช่น โมเดลที่ทำการคาดการณ์ได้ถูกต้อง 40 รายการและการคาดการณ์ที่ไม่ถูกต้อง 10 รายการจะมีความแม่นยำดังนี้
การแยกประเภทแบบไบนารีระบุชื่อที่เจาะจงสำหรับการคาดการณ์ที่ถูกต้องและการคาดคะเนที่ไม่ถูกต้องในหมวดหมู่ต่างๆ ดังนั้นสูตรความถูกต้องแม่นยำสำหรับการแยกประเภทแบบไบนารีมีดังนี้
โดยมี
- TP คือจำนวนผลบวกจริง (การคาดคะเนที่ถูกต้อง)
- TN คือจำนวนผลลบจริง (การคาดคะเนที่ถูกต้อง)
- FP คือจํานวนผลบวกลวง (การคาดการณ์ที่ไม่ถูกต้อง)
- FN คือจำนวนผลลบลวง (การคาดการณ์ไม่ถูกต้อง)
เปรียบเทียบและเปรียบเทียบความแม่นยำกับความแม่นยำและความอ่อนไหว
ฟังก์ชันการเปิดใช้งาน
ฟังก์ชันที่ช่วยให้โครงข่ายประสาทเรียนรู้ความสัมพันธ์แบบไม่ใช่เชิงเส้น (ที่ซับซ้อน) ระหว่างฟีเจอร์และป้ายกำกับ
ฟังก์ชันการเปิดใช้งานที่นิยมใช้กัน ได้แก่
พล็อตของฟังก์ชันการเปิดใช้งานไม่ใช่เส้นตรงเดี่ยว เช่น พล็อตของฟังก์ชันการเปิดใช้งาน ReLU ประกอบด้วยเส้นตรง 2 เส้น

พล็อตของฟังก์ชันการเปิดใช้งานซิกมอยด์มีลักษณะดังต่อไปนี้

คลิกที่ไอคอนเพื่อดูตัวอย่าง
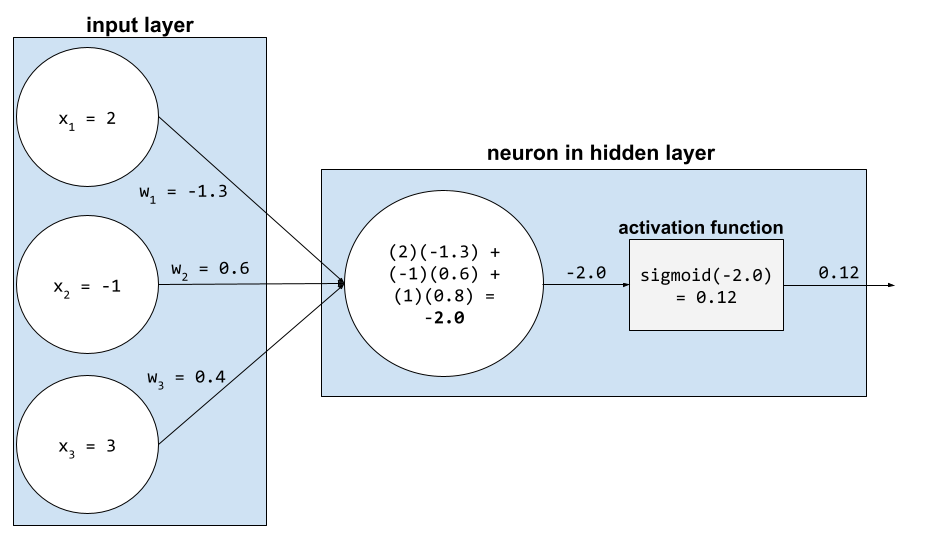
ในเครือข่ายระบบประสาท ฟังก์ชันการเปิดใช้งานจะควบคุมผลรวมถ่วงน้ำหนักของอินพุตทั้งหมดไปยังเซลล์ประสาท ในการคำนวณผลรวมแบบถ่วงน้ำหนัก เซลล์ประสาทจะรวมผลคูณของค่าและน้ำหนักที่เกี่ยวข้อง ตัวอย่างเช่น สมมติว่าอินพุตที่เกี่ยวข้องไปยังเซลล์ประสาทประกอบด้วยข้อมูลต่อไปนี้
| ค่าอินพุต | น้ำหนักอินพุต |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0สมมติว่าผู้ออกแบบโครงข่ายระบบประสาทนี้เลือกฟังก์ชันซิกมอยด์เป็นฟังก์ชันเปิดใช้งาน ในกรณีนั้น เซลล์ประสาทจะคำนวณซิกมอยด์ของ -2.0 ซึ่งเท่ากับประมาณ 0.12 ดังนั้น เซลล์ประสาทจะส่งผ่าน 0.12 (แทนที่จะเป็น -2.0) ไปยังชั้นถัดไปในโครงข่ายประสาท รูปภาพต่อไปนี้แสดงส่วนที่เกี่ยวข้องของกระบวนการ
ปัญญาประดิษฐ์ (AI)
โปรแกรมหรือmodelที่ไม่ใช่มนุษย์ซึ่งแก้ปัญหางานที่ซับซ้อนได้ เช่น โปรแกรมหรือโมเดลที่แปลข้อความหรือโปรแกรมหรือโมเดลที่ระบุโรคจากภาพรังสีวิทยาแสดงปัญญาประดิษฐ์ (AI)
อย่างเป็นทางการ แมชชีนเลิร์นนิงเป็นสาขาย่อยของปัญญาประดิษฐ์ (AI) อย่างไรก็ตาม ในช่วงไม่กี่ปีที่ผ่านมา บางองค์กรได้เริ่มใช้คำว่าปัญญาประดิษฐ์และแมชชีนเลิร์นนิงสลับกัน
AUC (พื้นที่ใต้เส้นโค้ง ROC)
ตัวเลขระหว่าง 0.0 และ 1.0 ที่แทนความสามารถของโมเดลการจัดประเภทแบบไบนารีในการแยกคลาสบวกออกจากคลาสเชิงลบ ยิ่ง AUC ใกล้เคียงกับ 1.0 มากเท่าไร โมเดลจะสามารถแยกคลาสออกจากกันได้ดีขึ้นเท่านั้น
ตัวอย่างเช่น ภาพประกอบต่อไปนี้แสดงโมเดลตัวแยกประเภทที่แยกคลาสบวก (วงรีสีเขียว) ออกจากคลาสเชิงลบ (สี่เหลี่ยมผืนผ้าสีม่วง) ได้อย่างสมบูรณ์แบบ โมเดลที่ไม่สมจริงนี้มี AUC 1.0:

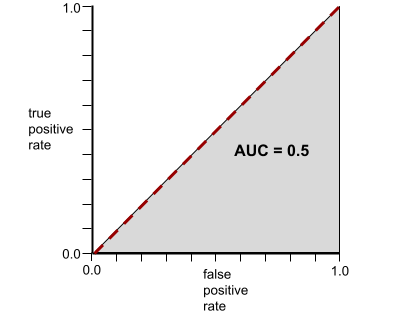
ในทางกลับกัน ภาพต่อไปนี้จะแสดงผลลัพธ์ของโมเดลตัวแยกประเภทที่สร้างผลลัพธ์แบบสุ่ม โมเดลนี้มี AUC 0.5:

ใช่ โมเดลก่อนหน้านี้มี AUC ที่ 0.5 ไม่ใช่ 0.0
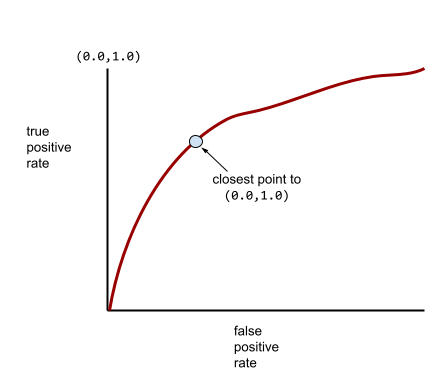
โมเดลส่วนใหญ่จะอยู่ระหว่างปลายทั้ง 2 ด้าน ตัวอย่างเช่น รูปแบบต่อไปนี้แยกผลบวกออกจากผลลบค่อนข้างมาก ดังนั้นจึงมี AUC ระหว่าง 0.5 และ 1.0

AUC จะไม่สนใจค่าที่คุณตั้งไว้สำหรับเกณฑ์การจัดประเภท แต่ AUC จะพิจารณาเกณฑ์การจัดประเภทที่เป็นไปได้ทั้งหมดแทน
คลิกที่ไอคอนเพื่อดูข้อมูลเกี่ยวกับความสัมพันธ์ระหว่างเส้นโค้ง AUC และ ROC
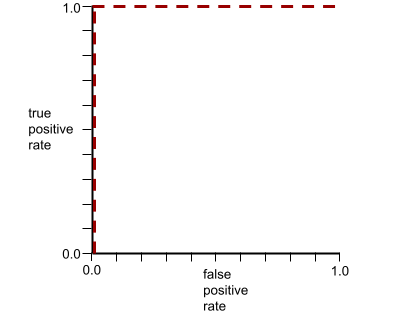
AUC แสดงพื้นที่ภายใต้เส้นโค้ง ROC ตัวอย่างเช่น เส้นโค้ง ROC สำหรับโมเดลที่แยกผลบวกออกจาก ผลลบอย่างสมบูรณ์แบบมีลักษณะดังต่อไปนี้
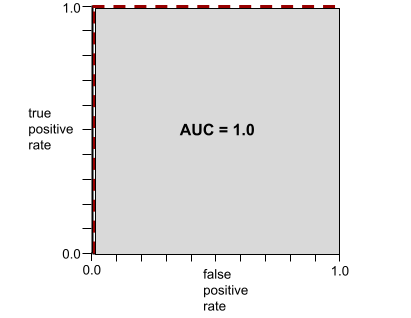
AUC คือพื้นที่ของบริเวณสีเทาในภาพประกอบก่อนหน้านี้ ในกรณีนี้ พื้นที่ดังกล่าวจะเท่ากับความยาวของพื้นที่สีเทา (1.0) คูณด้วยความกว้างของพื้นที่สีเทา (1.0) ดังนั้นผลคูณของ 1.0 และ 1.0 จะให้ AUC ที่ 1.0 พอดี ซึ่งเป็นคะแนน AUC สูงสุดที่เป็นไปได้
ในทางกลับกัน เส้นโค้ง ROC สำหรับตัวแยกประเภทที่ไม่สามารถแยกคลาสได้เลยจะมีลักษณะดังนี้ พื้นที่สีเทานี้คือ 0.5
เส้นโค้ง ROC ทั่วไปจะมีลักษณะดังนี้
การคำนวณพื้นที่ใต้เส้นโค้งนี้ด้วยตนเองเป็นเรื่องยุ่งยากมาก จึงเป็นเหตุผลที่โปรแกรมมักคำนวณค่า AUC ส่วนใหญ่
B
การแพร่พันธุ์ของด้านหลัง
อัลกอริทึมที่ใช้การลดระดับการไล่ระดับสีในโครงข่ายระบบประสาทเทียม
การฝึกโครงข่ายระบบประสาทเทียมเกี่ยวข้องกับการทำซ้ำหลายครั้งของวงจรแบบ 2-Pass ดังต่อไปนี้
- ระหว่างการส่งต่อ ระบบจะประมวลผลกลุ่มของตัวอย่างเพื่อสร้างการคาดการณ์ ระบบจะเปรียบเทียบการคาดการณ์แต่ละรายการกับค่า label แต่ละค่า ความแตกต่างระหว่างการคาดการณ์และค่าป้ายกำกับคือค่า loss ของตัวอย่างดังกล่าว ระบบจะรวมการสูญเสียของตัวอย่างทั้งหมดเพื่อคำนวณการสูญเสียทั้งหมดสำหรับแบทช์ปัจจุบัน
- ระหว่างการย้อนกลับทางเก่า (backเผยแพร่) ระบบจะลดการสูญเสียโดยการปรับน้ำหนักของเซลล์ทั้งหมดในเลเยอร์ที่ซ่อนอยู่
โครงข่ายระบบประสาทเทียมมักมีเซลล์ประสาทจำนวนมากข้ามชั้นที่ซ่อนเร้นอยู่มากมาย เซลล์ประสาทเหล่านี้แต่ละเซลล์มีส่วนทำให้เกิดการสูญเสียโดยรวมแตกต่างกันไป การแพร่พันธุ์กลับเป็นตัวกำหนดว่าจะเพิ่มหรือลดน้ำหนักที่ใช้กับเซลล์ประสาทหนึ่งๆ
อัตราการเรียนรู้คือตัวคูณที่ควบคุมระดับของการย้อนหลังแต่ละรายการเพิ่มหรือลดน้ำหนัก อัตราการเรียนรู้สูงจะเพิ่มหรือลดน้ำหนักลงมากกว่าอัตราการเรียนรู้ที่น้อยลง
ในเชิงแคลคูลัส การแพร่กระจายของกลับไปสู่การใช้งานจะใช้กฎเชนของแคลคูลัส กล่าวคือ การปรับใช้ย้อนกลับจะคำนวณอนุพันธ์บางส่วนของข้อผิดพลาดโดยคำนึงถึงพารามิเตอร์แต่ละรายการ ดูรายละเอียดเพิ่มเติมได้ที่บทแนะนำในหลักสูตรข้อขัดข้องของแมชชีนเลิร์นนิงนี้
หลายปีที่ผ่านมา ผู้ปฏิบัติงาน ML ต้องเขียนโค้ดเพื่อปรับใช้การนำไปใช้งานแบ็คเอนด์ ตอนนี้ ML API สมัยใหม่อย่าง TensorFlow ได้นำการทดแทนข้อมูลไปใช้แล้ว ในที่สุด
กลุ่ม
ชุดตัวอย่างที่ใช้ในการทำซ้ำการฝึก 1 รายการ ขนาดกลุ่มจะกำหนดจำนวนตัวอย่างในกลุ่ม
ดูคำอธิบายว่ากลุ่มเกี่ยวข้องกับ Epoch อย่างไรใน epoch
ขนาดกลุ่ม
จำนวนตัวอย่างในกลุ่ม เช่น หากขนาดกลุ่มคือ 100 โมเดลจะประมวลผลตัวอย่าง 100 รายการต่อการทำซ้ำ
กลยุทธ์แบบกลุ่มที่ได้รับความนิยมมีดังนี้
- Stochastic Gradient Descent (SGD) ซึ่งมีขนาดกลุ่มเท่ากับ 1
- ทั้งกลุ่ม โดยขนาดกลุ่มคือจำนวนตัวอย่างในชุดการฝึกทั้งชุด เช่น ถ้าชุดการฝึกมีตัวอย่างเป็นล้านตัวอย่าง ขนาดกลุ่มก็จะเป็นล้านตัวอย่าง เนื้อหาทั้งหมดมักเป็นกลยุทธ์ที่ไม่มีประสิทธิภาพ
- มินิแบทช์ ซึ่งขนาดกลุ่มมักจะอยู่ระหว่าง 10 ถึง 1,000 โดยทั่วไปแล้วการทำกลุ่มเล็กๆ จะเป็นกลยุทธ์ที่มีประสิทธิภาพมากที่สุด
อคติ (จริยธรรม/ความยุติธรรม)
1. การเหมารวม อคติ หรือความลำเอียงต่อบางสิ่ง ผู้คน หรือกลุ่มบุคคลบางกลุ่ม การให้น้ำหนักพิเศษเหล่านี้อาจส่งผลต่อการรวบรวมและการตีความข้อมูล การออกแบบระบบ และวิธีที่ผู้ใช้โต้ตอบกับระบบ รูปแบบของการให้น้ำหนักพิเศษประเภทนี้ ได้แก่
- การให้น้ำหนักอัตโนมัติ
- การให้น้ำหนักพิเศษในการยืนยัน
- ความเอนเอียงของผู้ทดสอบ
- ความเอนเอียงในการระบุแหล่งที่มาของกลุ่ม
- การให้น้ำหนักพิเศษโดยนัย
- ความเอนเอียงในกลุ่ม
- อคติเกี่ยวกับความเป็นแบบเดียวกันนอกกลุ่ม
2. ข้อผิดพลาดอย่างเป็นระบบซึ่งเกิดจากขั้นตอนการสุ่มตัวอย่างหรือการรายงาน รูปแบบของการให้น้ำหนักพิเศษประเภทนี้ ได้แก่
- การให้น้ำหนักพิเศษที่ครอบคลุม
- การให้น้ำหนักพิเศษที่ไม่ตอบกลับ
- ความเอนเอียงในการเข้าร่วม
- การให้น้ำหนักพิเศษในการรายงาน
- การให้น้ำหนักการสุ่มตัวอย่าง
- การให้น้ำหนักการเลือก
อย่าสับสนกับคำอคติในโมเดลแมชชีนเลิร์นนิงหรืออคติของการคาดการณ์
การให้น้ำหนักพิเศษ (ทางคณิตศาสตร์) หรือคำที่ให้น้ำหนักพิเศษ
จุดตัดหรือออฟเซ็ตจากต้นทาง การให้น้ำหนักพิเศษคือพารามิเตอร์ในโมเดลแมชชีนเลิร์นนิง ซึ่งระบุด้วยสัญลักษณ์อย่างใดอย่างหนึ่งต่อไปนี้
- b
- 0
ตัวอย่างเช่น การให้น้ำหนักพิเศษคือ b ในสูตรต่อไปนี้
สำหรับเส้น 2 มิติแบบง่าย การให้น้ำหนักพิเศษหมายถึง "จุดตัดแกน y" ตัวอย่างเช่น การให้น้ำหนักพิเศษของเส้นในภาพประกอบต่อไปนี้คือ 2
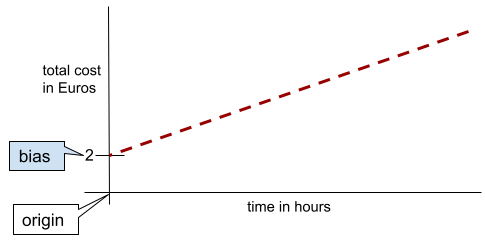
การให้น้ำหนักพิเศษมีอยู่เนื่องจากโมเดลบางส่วนไม่ได้เริ่มต้นจากต้นทาง (0,0) ตัวอย่างเช่น สมมติว่าสวนสนุกมีค่าใช้จ่าย 2 ยูโรสำหรับการเข้าสวนสนุก และอีก 0.5 ยูโรสำหรับทุกชั่วโมงที่ลูกค้าจะเข้าพัก ดังนั้นโมเดลการแมปต้นทุนทั้งหมดจึงมีการให้น้ำหนักพิเศษเป็น 2 เนื่องจากต้นทุนต่ำสุดคือ 2 ยูโร
อย่าสับสนกับอคติด้านจริยธรรมและความเป็นธรรมหรืออคติในการคาดคะเน
การจำแนกประเภทเลขฐานสอง
ประเภทของงานการแยกประเภทที่คาดการณ์ว่าหนึ่งใน 2 คลาสที่ใช้พร้อมกันไม่ได้มีดังนี้
ตัวอย่างเช่น โมเดลแมชชีนเลิร์นนิง 2 รายการต่อไปนี้แต่ละโมเดลทำการแยกประเภทแบบไบนารี
- โมเดลที่กำหนดว่าข้อความอีเมลเป็นสแปม (คลาสเชิงบวก) หรือไม่ใช่สแปม (คลาสเชิงลบ)
- โมเดลที่ประเมินอาการทางการแพทย์เพื่อระบุว่าบุคคลหนึ่งเป็นโรคอย่างใดอย่างหนึ่ง (คลาสที่เป็นบวก) หรือไม่เป็นโรคนั้น (คลาสเชิงลบ)
คอนทราสต์กับการจัดประเภทแบบหลายคลาส
ดูข้อมูลเพิ่มเติมได้ในการถดถอยแบบโลจิสติกและเกณฑ์การจัดประเภท
การฝากข้อมูล
การแปลงฟีเจอร์เดียวเป็นฟีเจอร์ไบนารีหลายรายการที่เรียกว่าที่เก็บข้อมูลหรือ bins โดยทั่วไปจะขึ้นอยู่กับช่วงค่า ฟีเจอร์ที่ตัดแล้วมักเป็นฟีเจอร์แบบต่อเนื่อง
เช่น แทนที่จะแสดงอุณหภูมิเป็นฟีเจอร์จุดลอยตัวต่อเนื่องจุดเดียว คุณอาจตัดช่วงของอุณหภูมิลงในที่เก็บข้อมูลที่แยกจากกันได้ เช่น
- <= 10 องศาเซลเซียสคือถังเก็บความเย็น
- 11-24 องศาเซลเซียสคืออุณหภูมิที่ "อากาศอบอุ่น"
- >= 25 องศาเซลเซียส เท่ากับถัง "อุ่น"
โมเดลนี้จะดำเนินการกับทุกค่าในที่เก็บข้อมูลเดียวกันเหมือนกัน ตัวอย่างเช่น ค่า 13 และ 22 ทั้งคู่อยู่ในที่เก็บข้อมูลชั่วคราว ดังนั้นโมเดลจะถือว่าทั้ง 2 ค่าเหมือนกัน
C
ข้อมูลเชิงหมวดหมู่
ฟีเจอร์ที่มีชุดค่าที่เป็นไปได้ที่เฉพาะเจาะจง ตัวอย่างเช่น ลองพิจารณาฟีเจอร์เชิงหมวดหมู่ชื่อ traffic-light-state ซึ่งมีค่าที่เป็นไปได้ 1 ใน 3 ค่าต่อไปนี้
redyellowgreen
การนําเสนอ traffic-light-state เป็นฟีเจอร์เชิงหมวดหมู่ช่วยให้โมเดลเรียนรู้ผลกระทบที่ red, green และ yellow มีต่อพฤติกรรมของผู้ขับขี่ได้
บางครั้งฟีเจอร์ตามหมวดหมู่เรียกว่าฟีเจอร์ที่ไม่ต่อเนื่อง
คอนทราสต์กับข้อมูลตัวเลข
คลาส
หมวดหมู่ที่มีป้ายกำกับอยู่ได้ เช่น
- ในรูปแบบการจัดประเภทไบนารีที่ตรวจหาสแปม คลาส 2 คลาสอาจเป็นสแปมและไม่ใช่สแปม
- ในรูปแบบการจัดประเภทแบบหลายคลาสที่ระบุสายพันธุ์สุนัข คลาสอาจเป็นพุดเดิ้ล บีเกิล ปั๊ก และอื่นๆ
โมเดลการจัดประเภทจะคาดการณ์คลาส ในทางตรงกันข้าม โมเดลการถดถอยจะคาดการณ์ตัวเลขไม่ใช่คลาส
โมเดลการจัดประเภท
model ที่มีการคาดการณ์เป็นคลาส ตัวอย่างต่อไปนี้คือโมเดลการจัดประเภททั้งหมด
- โมเดลที่คาดคะเนภาษาของประโยคอินพุต (ภาษาฝรั่งเศส ภาษาสเปน ภาษาอิตาลี)
- โมเดลที่คาดการณ์ชนิดของต้นไม้ (Maple? Oak? เบาบับ)
- โมเดลที่คาดการณ์คลาสเชิงบวกหรือเชิงลบสำหรับภาวะทางการแพทย์หนึ่งๆ
ในทางตรงกันข้าม โมเดลการถดถอยจะคาดการณ์ตัวเลขแทนคลาส
รูปแบบการจัดประเภทที่ใช้กันทั่วไปมี 2 ประเภท ได้แก่
เกณฑ์การจัดประเภท
ในการจัดประเภทแบบไบนารี จำนวนระหว่าง 0 ถึง 1 ที่แปลงเอาต์พุตดิบของโมเดลการถดถอยแบบโลจิสติกเป็นการคาดการณ์คลาสบวกหรือคลาสเชิงลบ โปรดทราบว่าเกณฑ์การจัดประเภทเป็นค่าที่มนุษย์เลือก ไม่ใช่ค่าที่การฝึกโมเดลเลือก
โมเดลการถดถอยแบบโลจิสติกจะแสดงค่าข้อมูลดิบระหว่าง 0 ถึง 1 จากนั้นให้ทำดังนี้
- หากค่าดิบนี้มากกว่าเกณฑ์การจัดประเภท ระบบจะคาดการณ์คลาสที่เป็นบวก
- หากค่าดิบนี้น้อยกว่าเกณฑ์การจัดประเภท ระบบจะคาดการณ์คลาสที่เป็นลบ
เช่น สมมติว่าเกณฑ์การจัดประเภทคือ 0.8 หากค่าดิบคือ 0.9 โมเดลจะคาดการณ์คลาสที่เป็นบวก หากค่าดิบคือ 0.7 โมเดลจะคาดการณ์คลาสที่เป็นลบ
ตัวเลือกเกณฑ์การจัดประเภทจะส่งผลต่อจำนวนผลบวกลวงและผลลบลวงอย่างมาก
ชุดข้อมูลที่ไม่สมดุลระดับ
ชุดข้อมูลสำหรับปัญหาการแยกประเภทซึ่งจำนวนป้ายกำกับทั้งหมดของแต่ละคลาสแตกต่างกันอย่างมีนัยสำคัญ เช่น ลองพิจารณาชุดข้อมูลการจัดประเภทแบบไบนารีซึ่งมีป้ายกำกับ 2 ป้ายที่แบ่งได้ดังนี้
- ป้ายกำกับเชิงลบ 1,000,000 รายการ
- ป้ายกำกับเชิงบวก 10 รายการ
อัตราส่วนของป้ายกำกับเชิงลบต่อป้ายกำกับบวกคือ 100,000 ต่อ 1 ชุดข้อมูลนี้จึงไม่สมดุล
ในทางตรงกันข้าม ชุดข้อมูลต่อไปนี้ไม่ไม่สมดุลกันเนื่องจากอัตราส่วนของป้ายกำกับเชิงลบต่อป้ายกำกับเชิงบวกค่อนข้างใกล้เคียงกับ 1
- ป้ายกำกับเชิงลบ 517 รายการ
- ป้ายกำกับเชิงบวก 483 รายการ
นอกจากนี้ ชุดข้อมูลแบบหลายคลาสอาจทำให้คลาสไม่สมดุลด้วย เช่น ชุดข้อมูลการจัดประเภทแบบหลายคลาสต่อไปนี้ไม่สมดุลด้วย เนื่องจากป้ายกำกับหนึ่งมีตัวอย่างมากกว่าอีก 2 ป้าย
- ป้ายกำกับ 1,000,000 ป้ายที่มีคลาส "สีเขียว"
- ป้ายกำกับ 200 ป้ายที่มีคลาส "สีม่วง"
- ป้ายกำกับ 350 รายการที่มีคลาส "สีส้ม"
โปรดดูเอนโทรปี คลาสส่วนใหญ่ และคลาสของชนกลุ่มน้อย
การคลิป
เทคนิคในการจัดการค่าที่ผิดปกติโดยทำอย่างใดอย่างหนึ่งหรือทั้ง 2 อย่างต่อไปนี้
- ลดค่า feature ที่มากกว่าเกณฑ์สูงสุดลงไปจนถึงเกณฑ์สูงสุดนั้น
- การเพิ่มค่าฟีเจอร์ที่น้อยกว่าเกณฑ์ขั้นต่ำจนถึงเกณฑ์ขั้นต่ำนั้น
ตัวอย่างเช่น สมมติว่าค่า <0.5% สำหรับคุณลักษณะหนึ่งอยู่นอกช่วง 40–60 ในกรณีนี้ คุณสามารถดำเนินการต่อไปนี้
- ตัดค่าทั้งหมดที่เกิน 60 (เกณฑ์ขั้นต่ำ) ให้เป็น 60 พอดี
- ตัดทุกค่าที่ต่ำกว่า 40 (เกณฑ์ขั้นต่ำ) ให้เป็น 40 พอดี
ค่าที่ผิดปกติอาจทำให้โมเดลเสียหาย ซึ่งบางครั้งอาจทำให้มีน้ำหนักล้นระหว่างการฝึก ค่าที่ผิดปกติบางอย่างอาจทำให้เมตริกต่างๆ เสียไปอย่างมาก เช่น ความแม่นยำ การตัดคลิปเป็นเทคนิคทั่วไปในการจำกัดความเสียหาย
การไล่ระดับสีจะบังคับค่าการไล่ระดับสีภายในช่วงที่กำหนดในระหว่างการฝึก
เมทริกซ์ความสับสน
ตาราง NxN ที่สรุปจำนวนการคาดการณ์ที่ถูกต้องและไม่ถูกต้องซึ่งโมเดลการจัดประเภททำขึ้น ลองพิจารณาเมทริกซ์ความสับสนต่อไปนี้สำหรับโมเดลการจัดประเภทแบบไบนารี
| เนื้องอก (ที่คาดการณ์) | ไม่ใช่เนื้องอก (คาดการณ์) | |
|---|---|---|
| เนื้องอก (ข้อมูลจากการสังเกตการณ์โดยตรง) | 18 (TP) | 1 (FN) |
| ไม่ใช่เนื้องอก (ข้อมูลจากการสังเกตการณ์โดยตรง) | 6 (FP) | 452 (เทนเนสซี) |
เมทริกซ์ความสับสนก่อนหน้าจะแสดงข้อมูลต่อไปนี้
- จากการคาดการณ์ 19 รายการที่ข้อมูลจากการสังเกตการณ์โดยตรงคือเนื้องอก โมเดลมีการจัดประเภทอย่างถูกต้อง 18 รายการและจัดประเภทเป็น 1 อย่างไม่ถูกต้อง
- จากการคาดการณ์ 458 รายการ ที่ความจริงเสมือนเป็นไม่ใช่เนื้องอก โมเดลได้รับการจัดประเภทอย่างถูกต้อง 452 รายการและจัดประเภทอย่างไม่ถูกต้อง 6 รายการ
เมทริกซ์ความสับสนของปัญหาการจัดประเภทแบบหลายคลาสช่วยให้คุณระบุรูปแบบของข้อผิดพลาดได้ เช่น ลองพิจารณาเมทริกซ์ความสับสนต่อไปนี้สำหรับโมเดลการจัดประเภทแบบหลายคลาส 3 คลาสที่จัดหมวดหมู่ไอริส 3 ประเภทที่แตกต่างกัน (Virginica, Versicolor และ Setosa) เมื่อข้อเท็จจริงบนพื้นดินคือ Virginica เมทริกซ์ความสับสนแสดงให้เห็นว่าโมเดลมีแนวโน้มที่จะคาดการณ์ Versicolor ผิดพลาดมากกว่า Setosa:
| Setosa (ตามการคาดการณ์) | Versicolor (ตามการคาดการณ์) | เวอร์จิเนีย (ตามการคาดการณ์) | |
|---|---|---|---|
| เซโตซา (ข้อมูลจากการสังเกตการณ์โดยตรง) | 88 | 12 | 0 |
| Versicolor (ข้อมูลจากการสังเกตการณ์โดยตรง) | 6 | 141 | 7 |
| เวอร์จิกา (ข้อมูลจากการสังเกตการณ์โดยตรง) | 2 | 27 | 109 |
อีกตัวอย่างหนึ่งคือ เมทริกซ์ความสับสนอาจเปิดเผยว่าโมเดลที่ฝึกให้จดจำตัวเลขที่เขียนด้วยลายมือมีแนวโน้มที่จะคาดการณ์ผิดพลาดเป็น 9 ไม่ใช่ 4 หรืออาจคาดคะเน 1 แทนที่จะเป็น 7 ผิดพลาด
เมทริกซ์ความสับสนมีข้อมูลที่เพียงพอสำหรับการคำนวณเมตริกประสิทธิภาพแบบต่างๆ ซึ่งรวมถึงความแม่นยำและการจดจำ
ฟีเจอร์ต่อเนื่อง
ฟีเจอร์จุดลอยตัวที่มีช่วงของค่าที่เป็นไปได้อย่างไม่จำกัด เช่น อุณหภูมิหรือน้ำหนัก
คอนทราสต์กับฟีเจอร์ไม่ต่อเนื่อง
ผสานรวม
สถานะที่มาถึงเมื่อค่า loss เปลี่ยนแปลงน้อยมากหรือไม่เปลี่ยนเลยในแต่ละการทำซ้ำ ตัวอย่างเช่น เส้นโค้งการสูญเสียต่อไปนี้แสดงถึงการบรรจบกันที่การทำซ้ำประมาณ 700 ครั้ง
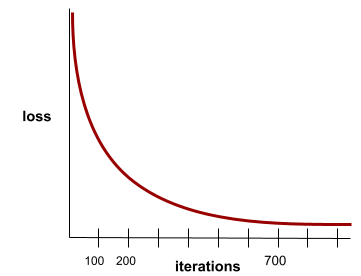
โมเดลจะสื่อสารเมื่อการฝึกเพิ่มเติมไม่ช่วยพัฒนาโมเดล
ในการเรียนรู้เชิงลึก บางครั้งค่าการสูญเสียอาจคงที่หรือเกือบตลอดเวลาในการทำซ้ำหลายครั้งก่อนที่จะจากมากไปน้อย ในช่วงเวลาที่ค่าสูญเสียคงที่เป็นระยะเวลานาน อาจทำให้คุณรู้สึกว่ามีการมาบรรจบกันที่ผิดพลาดชั่วคราว
โปรดดูการหยุดก่อนกำหนด
D
DataFrame
ประเภทข้อมูล pandas ยอดนิยมสำหรับการแสดงชุดข้อมูลในหน่วยความจำ
DataFrame คล้ายกับตารางหรือสเปรดชีต แต่ละคอลัมน์ของ DataFrame จะมีชื่อ (ส่วนหัว) และแต่ละแถวจะระบุด้วยหมายเลขที่ไม่ซ้ำกัน
แต่ละคอลัมน์ใน DataFrame มีโครงสร้างเหมือนอาร์เรย์ 2D เว้นแต่ว่าคอลัมน์แต่ละคอลัมน์จะกำหนดประเภทข้อมูลของตัวเองได้
โปรดดูหน้าข้อมูลอ้างอิงของ pandas.DataFrame อย่างเป็นทางการ
ชุดข้อมูลหรือชุดข้อมูล
การเก็บรวบรวมข้อมูลดิบ ซึ่งโดยปกติ (แต่ไม่เกิดขึ้นเพียงอย่างเดียว) จะจัดระเบียบในรูปแบบใดรูปแบบหนึ่งต่อไปนี้
- สเปรดชีต
- ไฟล์ในรูปแบบ CSV (ค่าที่คั่นด้วยคอมมา)
โมเดลเชิงลึก
โครงข่ายระบบประสาทเทียมที่มีเลเยอร์ที่ซ่อนอยู่มากกว่า 1 รายการ
โมเดลเชิงลึกเรียกอีกอย่างว่าโครงข่ายประสาทแบบลึก
คอนทราสต์กับโมเดลแบบกว้าง
จุดสนใจที่หนาแน่น
ฟีเจอร์ที่ค่าส่วนใหญ่หรือทั้งหมดไม่ใช่ 0 ซึ่งมักจะเป็น Tensor ของค่าจุดลอยตัว ตัวอย่างเช่น Tensor 10 องค์ประกอบต่อไปนี้มีความหนาแน่นเนื่องจากค่า 9 ค่าขององค์ประกอบไม่ใช่ 0
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
คอนทราสต์กับฟีเจอร์แบบกระจัดกระจาย
ความลึก
ผลรวมของสิ่งต่อไปนี้ในโครงข่ายระบบประสาทเทียม:
- จำนวนเลเยอร์ที่ซ่อนอยู่
- จํานวนเลเยอร์เอาต์พุต ซึ่งปกติคือ 1
- จำนวนเลเยอร์การฝังใดๆ
ตัวอย่างเช่น โครงข่ายระบบประสาทเทียมที่มีเลเยอร์ซ่อนอยู่ 5 เลเยอร์ และเลเยอร์เอาต์พุตหนึ่งมีความลึก 6 ชั้น
โปรดสังเกตว่าเลเยอร์อินพุตไม่มีอิทธิพลต่อความลึก
ฟีเจอร์แยกกัน
ฟีเจอร์ที่มีชุดค่าที่เป็นไปได้อย่างจำกัด ตัวอย่างเช่น ฟีเจอร์ที่มีค่าต้องเป็นสัตว์ ผัก หรือแร่ธาตุเท่านั้น เป็นฟีเจอร์ที่มีการแยกส่วน (หรือตามหมวดหมู่)
คอนทราสต์กับฟีเจอร์ต่อเนื่อง
ไดนามิก
บางสิ่งที่ทำบ่อยหรือต่อเนื่อง คำว่าไดนามิกและออนไลน์เป็นคำที่มีความหมายเหมือนกันในแมชชีนเลิร์นนิง การใช้งานแบบไดนามิกและออนไลน์โดยทั่วไปในแมชชีนเลิร์นนิงมีดังนี้
- โมเดลแบบไดนามิก (หรือโมเดลออนไลน์) คือโมเดลที่มีการฝึกซ้ำบ่อยๆ หรือต่อเนื่อง
- การฝึกอบรมแบบไดนามิก (หรือการฝึกอบรมออนไลน์) เป็นกระบวนการฝึกบ่อยๆ หรืออย่างต่อเนื่อง
- การอนุมานแบบไดนามิก (หรือการอนุมานออนไลน์) เป็นกระบวนการสร้างการคาดการณ์ตามคำขอ
โมเดลแบบไดนามิก
modelที่ฝึกซ้ำบ่อย (หรืออย่างต่อเนื่อง) โมเดลแบบไดนามิกคือ "ผู้เรียนรู้ตลอดชีวิต" ซึ่งปรับตัวเข้ากับข้อมูลที่มีการเปลี่ยนแปลงอยู่ตลอดเวลา โมเดลแบบไดนามิกเรียกอีกอย่างว่าโมเดลออนไลน์
คอนทราสต์กับโมเดลภาพนิ่ง
E
การหยุดก่อนกำหนด
เมธอดสำหรับ regularization ที่เกี่ยวข้องกับการสิ้นสุดการฝึก ก่อนที่การสูญเสียการฝึกจะเสร็จสิ้นลดลง ในการหยุดก่อนกำหนด จะเป็นการหยุดฝึกโมเดลโดยตั้งใจเมื่อการสูญเสียชุดข้อมูลการตรวจสอบเริ่มเพิ่มขึ้น กล่าวคือเมื่อประสิทธิภาพของการทำให้เป็นทั่วไปแย่ลง
เลเยอร์ที่ฝัง
เลเยอร์ที่ซ่อนอยู่พิเศษที่ฝึกบนฟีเจอร์เชิงหมวดหมู่มิติสูงเพื่อค่อยๆ เรียนรู้เวกเตอร์ที่ฝังอยู่ที่มีขนาดต่ำกว่า เลเยอร์ที่ฝังอยู่ทำให้โครงข่ายประสาทฝึกได้อย่างมีประสิทธิภาพมากกว่าการฝึกเฉพาะฟีเจอร์เชิงหมวดหมู่ในมิติระดับสูง
ตัวอย่างเช่น ปัจจุบัน Earth รองรับต้นไม้ประมาณ 73,000 ชนิด สมมติว่าสปีชีส์ของต้นไม้เป็นฟีเจอร์ในโมเดลของคุณ เลเยอร์อินพุตของโมเดลจึงมีเวกเตอร์ครั้งเดียว องค์ประกอบยาว 73,000 รายการ
ตัวอย่างเช่น baobab อาจแสดงขึ้นประมาณนี้

อาร์เรย์ 73,000 องค์ประกอบยาวมาก หากไม่เพิ่มเลเยอร์ที่ฝังลงในโมเดล การฝึกจะใช้เวลานานมากเนื่องจากมีการคูณ 0 ถึง 72,999 ตัว คุณอาจเลือกเลเยอร์การฝังให้ประกอบด้วย ขนาด 12 ขนาด เลเยอร์ที่ฝังจะค่อยๆ เรียนรู้ เวกเตอร์การฝังใหม่สำหรับต้นไม้แต่ละชนิด
ในบางสถานการณ์ การแฮชเป็นทางเลือกที่สมเหตุสมผลแทนการฝังเลเยอร์
Epoch
การฝึกอบรมเต็มรูปแบบผ่านชุดการฝึกทั้งหมดเพื่อให้ตัวอย่างแต่ละรายการได้รับการประมวลผลเพียงครั้งเดียว
Epoch แสดง N/ขนาดกลุ่ม
การทำซ้ำ โดย N คือจำนวนตัวอย่างทั้งหมด
ตัวอย่างเช่น สมมติว่า
- ชุดข้อมูลประกอบด้วยตัวอย่าง 1,000 รายการ
- ขนาดกลุ่มคือ 50 ตัวอย่าง
ดังนั้น Epoch 1 รายการต้องมีการทำซ้ำ 20 ครั้ง ดังนี้
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
example (ตัวอย่าง)
ค่าของฟีเจอร์ 1 แถวและอาจจะเป็นป้ายกำกับ ตัวอย่างการเรียนรู้ที่มีการควบคุมดูแลจะแบ่งออกเป็น 2 หมวดหมู่ทั่วไปดังนี้
- ตัวอย่างที่ติดป้ายกำกับประกอบด้วยฟีเจอร์อย่างน้อย 1 รายการและป้ายกำกับ ตัวอย่างที่ติดป้ายกำกับจะใช้ในระหว่างการฝึก
- ตัวอย่างที่ไม่มีป้ายกำกับประกอบด้วยฟีเจอร์อย่างน้อย 1 รายการ แต่ไม่มีป้ายกำกับ ตัวอย่างที่ไม่มีป้ายกำกับจะใช้ในระหว่างการอนุมาน
ตัวอย่างเช่น สมมติว่าคุณกำลังฝึกโมเดลเพื่อกำหนดอิทธิพลของสภาพอากาศที่มีต่อคะแนนสอบของนักเรียน ต่อไปนี้เป็นตัวอย่างที่มีป้ายกำกับ 3 รายการ
| ฟีเจอร์ | ป้ายกำกับ | ||
|---|---|---|---|
| อุณหภูมิ | ความชื้น | ความกดอากาศ | คะแนนสอบ |
| 15 | 47 | 998 | เร็ว |
| 19 | 34 | 1020 | ดีมาก |
| 18 | 92 | 1012 | แย่ |
ต่อไปนี้เป็นตัวอย่างที่ไม่มีป้ายกำกับ 3 ตัวอย่าง
| อุณหภูมิ | ความชื้น | ความกดอากาศ | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
แถวของชุดข้อมูลมักจะเป็นแหล่งข้อมูลดิบสำหรับตัวอย่าง กล่าวคือ ตัวอย่างโดยทั่วไปจะประกอบด้วยชุดย่อยของคอลัมน์ในชุดข้อมูล นอกจากนี้ ฟีเจอร์ต่างๆ ในตัวอย่างอาจรวมถึงฟีเจอร์สังเคราะห์ เช่น ฟีเจอร์ครอสของฟีเจอร์
F
ผลลบลวง (FN)
ตัวอย่างที่โมเดลคาดการณ์คลาสเชิงลบอย่างไม่ถูกต้อง ตัวอย่างเช่น โมเดลคาดการณ์ว่าข้อความอีเมลหนึ่งๆ ไม่ใช่สแปม (คลาสเชิงลบ) แต่ข้อความอีเมลนั้นที่จริงแล้วเป็นสแปม
ผลบวกลวง (FP)
ตัวอย่างที่โมเดลคาดการณ์คลาสเชิงบวกอย่างไม่ถูกต้อง ตัวอย่างเช่น โมเดลคาดการณ์ว่าข้อความอีเมลหนึ่งๆ คือสแปม (คลาสเชิงบวก) แต่ข้อความอีเมลนั้นที่จริงแล้วไม่ใช่สแปม
อัตราผลบวกลวง (FPR)
สัดส่วนของตัวอย่างเชิงลบจริงที่โมเดลคาดการณ์คลาสเชิงบวกโดยไม่ตั้งใจ สูตรต่อไปนี้จะคำนวณอัตราผลบวกลวง
อัตราผลบวกลวงคือแกน x ในเส้นโค้ง ROC
ฟีเจอร์
ตัวแปรอินพุตให้กับโมเดลแมชชีนเลิร์นนิง ตัวอย่าง ประกอบด้วยฟีเจอร์อย่างน้อย 1 รายการ ตัวอย่างเช่น สมมติว่าคุณกำลังฝึกโมเดลเพื่อกำหนดอิทธิพลของสภาพอากาศที่มีต่อคะแนนสอบของนักเรียน ตารางต่อไปนี้แสดงตัวอย่าง 3 ตัวอย่าง แต่ละรายการประกอบด้วย 3 ฟีเจอร์ และ 1 ป้ายกำกับ ดังนี้
| ฟีเจอร์ | ป้ายกำกับ | ||
|---|---|---|---|
| อุณหภูมิ | ความชื้น | ความกดอากาศ | คะแนนสอบ |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
คอนทราสต์กับป้ายกำกับ
กากบาทฟีเจอร์
ฟีเจอร์สังเคราะห์ที่เกิดจากฟีเจอร์ "การข้าม" เชิงหมวดหมู่หรือที่เก็บข้อมูล
ตัวอย่างเช่น ลองใช้โมเดล "การคาดการณ์อารมณ์" ที่แสดงถึงอุณหภูมิใน 1 ใน 4 ด้านต่อไปนี้
freezingchillytemperatewarm
และแสดงความเร็วลมในที่เก็บข้อมูล 3 รายการต่อไปนี้
stilllightwindy
เมื่อไม่มีข้ามฟีเจอร์ โมเดลเชิงเส้นจะฝึกแยกกันในที่เก็บข้อมูลต่างๆ 7 ที่เก็บข้อมูลที่อยู่ก่อนหน้า ดังนั้นโมเดลจะฝึกใน
freezing โดยไม่ขึ้นอยู่กับการฝึก เช่น
windy
หรือจะสร้างความแตกต่างระหว่างอุณหภูมิและความเร็วลม ฟีเจอร์สังเคราะห์นี้จะมีค่าที่เป็นไปได้ 12 ค่าดังต่อไปนี้
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
ฟีเจอร์กากบาทฟีเจอร์ทำให้โมเดลเรียนรู้ความแตกต่างของอารมณ์ได้ในช่วง freezing-windy วันถึง freezing-still วัน
หากคุณสร้างฟีเจอร์สังเคราะห์จาก 2 ฟีเจอร์โดยที่แต่ละฟีเจอร์มีที่เก็บข้อมูลจำนวนมาก ค่าที่ได้ของฟีเจอร์ข้ามจะมีชุดค่าผสมที่เป็นไปได้จำนวนมากมาย ตัวอย่างเช่น หากฟีเจอร์หนึ่งมีที่เก็บข้อมูล 1,000 รายการ และอีกฟีเจอร์หนึ่งมีที่เก็บข้อมูล 2,000 รายการ ฟีเจอร์ข้ามได้จะมีที่เก็บข้อมูล 2,000,000 รายการ
รูปกากบาทอย่างเป็นทางการคือ ผลคูณของคาร์ทีเซียน
เครื่องหมายกากบาทฟีเจอร์ส่วนใหญ่ใช้กับโมเดลเชิงเส้นและไม่ค่อยใช้กับโครงข่ายระบบประสาทเทียม
Feature Engineering
กระบวนการที่มีขั้นตอนดังต่อไปนี้
- การกำหนดฟีเจอร์ที่อาจมีประโยชน์ในการฝึกโมเดล
- การแปลงข้อมูลดิบจากชุดข้อมูลให้เป็นเวอร์ชันที่มีประสิทธิภาพของฟีเจอร์เหล่านี้
ตัวอย่างเช่น คุณอาจพิจารณาได้ว่า temperature อาจเป็นฟีเจอร์ที่มีประโยชน์ จากนั้นคุณอาจทดสอบที่เก็บข้อมูลเพื่อเพิ่มประสิทธิภาพสิ่งที่โมเดลสามารถเรียนรู้จากช่วง temperature ต่างๆ
บางครั้งเราเรียกวิศวกรรมฟีเจอร์ว่าการดึงข้อมูลฟีเจอร์
ชุดฟีเจอร์
กลุ่มฟีเจอร์ของโมเดลแมชชีนเลิร์นนิงที่ฝึกใช้งาน ตัวอย่างเช่น รหัสไปรษณีย์ ขนาดอสังหาริมทรัพย์ และสภาพอสังหาริมทรัพย์อาจประกอบด้วยชุดฟีเจอร์แบบง่ายๆ สำหรับโมเดลที่คาดการณ์ราคาที่พักอาศัย
เวกเตอร์จุดสนใจ
อาร์เรย์ของค่า feature ที่ประกอบด้วยตัวอย่าง เวกเตอร์ของฟีเจอร์คืออินพุตระหว่างการฝึกและระหว่างการอนุมาน ตัวอย่างเช่น เวกเตอร์จุดสนใจสำหรับโมเดลที่มีจุดสนใจที่แยกกันสองอย่างอาจเป็นดังนี้
[0.92, 0.56]
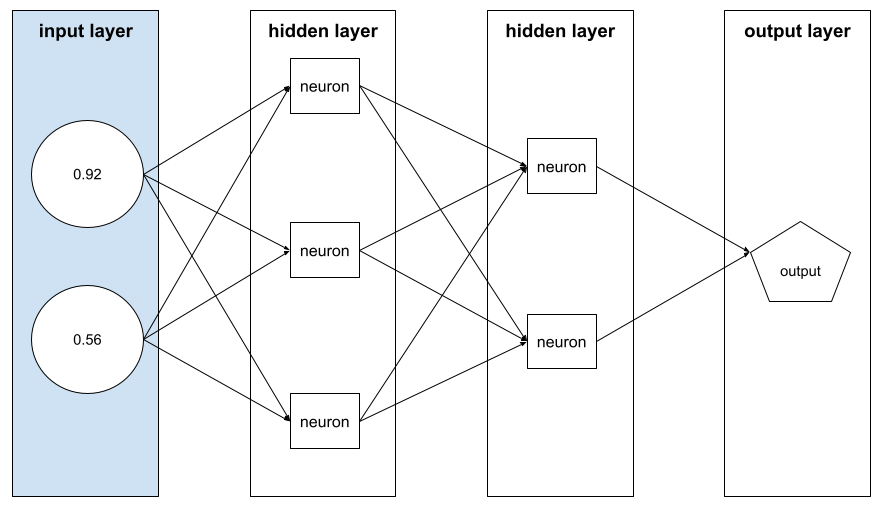
แต่ละตัวอย่างให้ค่าที่ต่างกันสำหรับเวกเตอร์ของจุดสนใจ ดังนั้นเวกเตอร์ของจุดสนใจสำหรับตัวอย่างถัดไปอาจมีลักษณะดังนี้
[0.73, 0.49]
วิศวกรรมคุณลักษณะกำหนดวิธีแสดงจุดสนใจในเวกเตอร์จุดสนใจ เช่น ฟีเจอร์เชิงหมวดหมู่ไบนารีที่มีค่าที่เป็นไปได้ 5 ค่าอาจแสดงด้วยการเข้ารหัสแบบ One-Hot ในกรณีนี้ ส่วนของเวกเตอร์จุดสนใจของตัวอย่างหนึ่งๆ จะประกอบด้วยเลขศูนย์ 4 ตัว และเลข 1.0 ตัวเดียวในตำแหน่งที่ 3 ดังนี้
[0.0, 0.0, 1.0, 0.0, 0.0]
อีกตัวอย่างหนึ่ง สมมติว่าโมเดลของคุณประกอบด้วยคุณลักษณะสามอย่าง:
- ฟีเจอร์เชิงหมวดหมู่ไบนารีที่มีค่าที่เป็นไปได้ 5 ค่าซึ่งแสดงด้วยการเข้ารหัสแบบ 1-Hot เช่น
[0.0, 1.0, 0.0, 0.0, 0.0] - อีกฟีเจอร์หมวดหมู่ไบนารีที่มีค่าที่เป็นไปได้ 3 ค่าซึ่งแสดงด้วยการเข้ารหัสแบบ 1-Hot เช่น
[0.0, 0.0, 1.0] - ฟีเจอร์จุดลอยตัว เช่น
8.3
ในกรณีนี้ เวกเตอร์ของฟีเจอร์สำหรับแต่ละตัวอย่างจะแสดงด้วยค่า 9 ค่า จากค่าตัวอย่างในรายการก่อนหน้า เวกเตอร์ของจุดสนใจจะเป็นดังนี้
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
ลูปความคิดเห็น
ในแมชชีนเลิร์นนิง สถานการณ์ที่การคาดการณ์ของโมเดลมีอิทธิพลต่อข้อมูลการฝึกสำหรับโมเดลเดียวกันหรือโมเดลอื่น เช่น โมเดลที่แนะนำภาพยนตร์จะมีอิทธิพลต่อภาพยนตร์ที่ผู้ใช้ดู ซึ่งจะมีผลต่อโมเดลการแนะนำภาพยนตร์ต่อๆ ไป
G
ข้อมูลทั่วไป
ความสามารถของโมเดลในการคาดการณ์ที่ถูกต้องเกี่ยวกับข้อมูลใหม่ที่ไม่เคยเห็นมาก่อน โมเดลที่สร้างข้อมูลทั่วไปได้คือรูปแบบตรงกันข้ามกับโมเดลที่นำมาใส่ไว้มากเกินไป
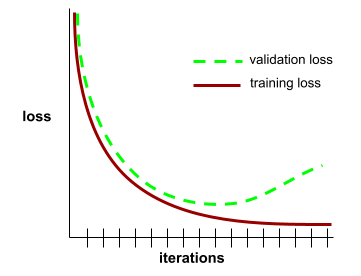
เส้นโค้งภาพรวม
แผนผังของทั้ง การสูญเสียการฝึกและการสูญเสียการตรวจสอบ เป็นฟังก์ชันของจำนวนการทำซ้ำ
เส้นโค้งทั่วไปช่วยให้คุณตรวจหาการซ้อนทับที่เป็นไปได้ ตัวอย่างเช่น เส้นโค้งทั่วไปต่อไปนี้แนะนำให้ติดแท็กมากเกินไปเนื่องจากการสูญเสียการตรวจสอบจะสูงกว่าการสูญเสียการฝึกมากในท้ายที่สุด
การไล่ระดับสีลง
เทคนิคทางคณิตศาสตร์ที่จะช่วยลดการสูญเสีย การไล่ระดับสีแบบค่อยเป็นค่อยไปจะปรับน้ำหนักและอคติซ้ำๆ โดยจะค่อยๆ หาชุดค่าผสมที่ดีที่สุดเพื่อลดการสูญเสีย
การไล่ระดับสี (ไล่ระดับสี) เก่ากว่าแมชชีนเลิร์นนิงมาก
ข้อมูลจากการสังเกตการณ์โดยตรง
เรียลลิตี้
สิ่งที่เกิดขึ้นจริง
ตัวอย่างเช่น ลองใช้โมเดลการแยกประเภทแบบไบนารีที่คาดการณ์ว่านักศึกษาปีแรกในมหาวิทยาลัยจะสำเร็จการศึกษาภายใน 6 ปีหรือไม่ ข้อมูลจากการสังเกตการณ์โดยตรงสำหรับโมเดลนี้คือ นักเรียนคนนั้นจบการศึกษาภายใน 6 ปีหรือไม่
ฮิต
เลเยอร์ที่ซ่อนอยู่
เลเยอร์ในโครงข่ายระบบประสาทเทียมระหว่างเลเยอร์อินพุต (ฟีเจอร์ต่างๆ) และเลเยอร์เอาต์พุต (การคาดการณ์) เลเยอร์ที่ซ่อนอยู่แต่ละเลเยอร์ประกอบด้วยเซลล์ประสาทอย่างน้อย 1 เซลล์ ตัวอย่างเช่น โครงข่ายระบบประสาทเทียมต่อไปนี้มีเลเยอร์ซ่อนอยู่ 2 ชั้น ชั้นแรกมีเซลล์ประสาท 3 เซลล์ ชั้นแรกมีเซลล์ประสาท 2 ชั้น
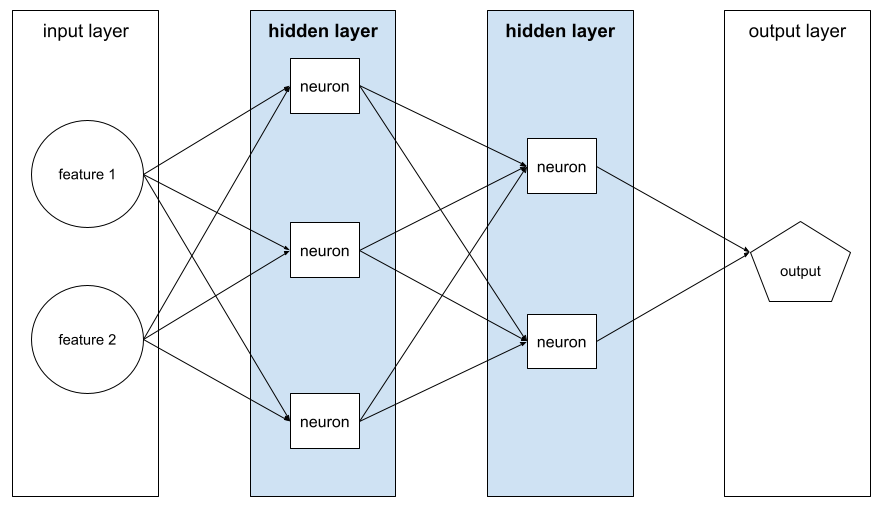
โครงข่ายประสาทแบบลึกมีเลเยอร์ที่ซ่อนอยู่มากกว่า 1 ชั้น ตัวอย่างเช่น ภาพก่อนหน้าคือโครงข่ายประสาทแบบลึกเนื่องจากโมเดลมีเลเยอร์ที่ซ่อนอยู่ 2 ชั้น
ไฮเปอร์พารามิเตอร์
ตัวแปรที่คุณหรือบริการปรับแต่งไฮเปอร์พารามิเตอร์ จะปรับระหว่างการฝึกโมเดลอย่างต่อเนื่อง ตัวอย่างเช่น อัตราการเรียนรู้คือไฮเปอร์พารามิเตอร์ คุณสามารถตั้งค่าอัตราการเรียนรู้เป็น 0.01 ก่อนเซสชันการฝึกอบรม 1 เซสชัน หากคุณเห็นว่า 0.01 สูงเกินไป คุณอาจกำหนดอัตราการเรียนรู้เป็น 0.003 สำหรับเซสชันการฝึกอบรมครั้งถัดไป
ในทางตรงกันข้าม พารามิเตอร์คือน้ำหนักและอคติต่างๆ ที่โมเดลเรียนรู้ระหว่างการฝึก
I
เผยแพร่อย่างอิสระและเหมือนกัน (เช่น)
ข้อมูลที่ถูกดึงมาจากการแจกแจงที่ไม่มีการเปลี่ยนแปลง และที่ที่แต่ละค่าดึงมาไม่ได้ขึ้นอยู่กับค่าที่ดึงออกมาก่อนหน้านี้ ไอดี คือก๊าซในอุดมคติของแมชชีนเลิร์นนิง โครงสร้างทางคณิตศาสตร์ที่มีประโยชน์แต่แทบจะไม่เคยพบเลยในชีวิตจริง ตัวอย่างเช่น การกระจายของผู้เข้าชมหน้าเว็บอาจเป็น i.i.d. ในช่วงเวลาสั้นๆ กล่าวคือ การกระจายจะไม่เปลี่ยนแปลง ในช่วงเวลาสั้นๆ นั้น และโดยทั่วกันโดยทั่วไป การเข้าชมของบุคคลหนึ่งขึ้นอยู่กับการเข้าชมของอีกคนหนึ่ง อย่างไรก็ตาม หากคุณขยายกรอบเวลานั้น ความแตกต่างตามฤดูกาลในผู้เข้าชมหน้าเว็บอาจปรากฏ
ดูข้อมูลเพิ่มเติมที่ไม่คงที่
การอนุมาน
ในแมชชีนเลิร์นนิง กระบวนการสร้างการคาดการณ์โดยใช้โมเดลที่ฝึกแล้วกับตัวอย่างที่ไม่มีป้ายกำกับ
การอนุมานจะมีความหมายแตกต่างกันไปในสถิติ ดูรายละเอียดได้ที่ บทความ Wikipedia เกี่ยวกับการอนุมานทางสถิติ
เลเยอร์อินพุต
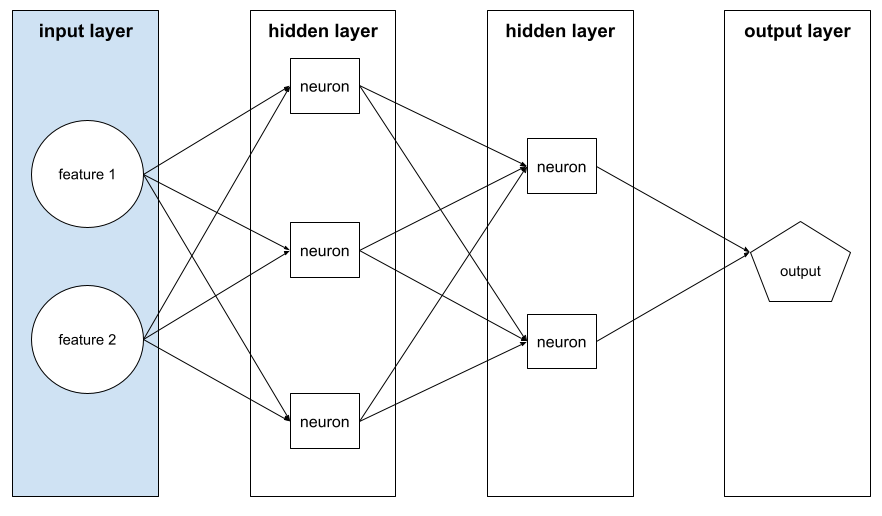
เลเยอร์ของโครงข่ายระบบประสาทเทียมที่มีเวกเตอร์ฟีเจอร์ กล่าวคือ เลเยอร์อินพุตจะแสดงตัวอย่างสำหรับการฝึกหรือการอนุมาน ตัวอย่างเช่น เลเยอร์อินพุตในโครงข่ายประสาทต่อไปนี้ประกอบด้วย 2 ฟีเจอร์
ความสามารถในการตีความ
ความสามารถในการอธิบายหรือนำเสนอโมเดลของ ML ให้มนุษย์เข้าใจได้
ตัวอย่างเช่น โมเดลการถดถอยเชิงเส้นส่วนใหญ่จะตีความได้สูง (คุณเพียงต้องดูน้ำหนักที่ฝึกของแต่ละฟีเจอร์เท่านั้น) ป่าตัดสินใจมีการตีความอย่างสูงด้วย อย่างไรก็ตาม บางโมเดลต้องใช้การแสดงผลที่ซับซ้อนเพื่อให้ตีความได้
คุณสามารถใช้เครื่องมือตีความการเรียนรู้ (LIT) เพื่อตีความโมเดล ML
การทำซ้ำ
การอัปเดตพารามิเตอร์ของโมเดล 1 ครั้ง ซึ่งก็คือน้ำหนักและอคติของโมเดล ระหว่างการฝึก ขนาดกลุ่มจะกำหนดจำนวนตัวอย่างที่โมเดลประมวลผลในการทำซ้ำแต่ละครั้ง เช่น ถ้าขนาดกลุ่มคือ 20 โมเดลจะประมวลผลตัวอย่าง 20 รายการก่อนปรับเปลี่ยนพารามิเตอร์
เมื่อฝึกโครงข่ายระบบประสาทเทียม การทำซ้ำ 1 ครั้งจะอาศัย 2 เส้นทางต่อไปนี้
- การส่งต่อเพื่อประเมินการสูญเสียในชุดเดียว
- การส่งแบบย้อนหลัง (backprofagation) เพื่อปรับพารามิเตอร์ของโมเดลตามการสูญเสียและอัตราการเรียนรู้
L
การกำหนดกฎ L0
ประเภทของรูปแบบการจัดสรรที่หักจำนวนรวมของน้ำหนักที่ไม่ใช่ 0 ในโมเดล เช่น โมเดลที่มีน้ำหนักมากกว่า 0 จำนวน 11 รายการ จะได้รับการลงโทษมากกว่าโมเดลที่คล้ายกันที่มีน้ำหนักมากกว่า 00 จำนวน 10
การกำหนดกฎ L0 บางครั้งเรียกว่าการกำหนด L0-norm
แพ้ L1
ฟังก์ชัน Los ที่คำนวณค่าสัมบูรณ์ของความแตกต่างระหว่างค่า label จริงกับค่าที่โมเดลคาดการณ์ไว้ เช่น การคำนวณการสูญเสีย L1 สำหรับกลุ่ม 5 ตัวอย่าง
| มูลค่าจริงของตัวอย่าง | ค่าที่คาดการณ์ไว้ของโมเดล | ค่าสัมบูรณ์ของเดลต้า |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = แพ้ L1 | ||
การสูญเสีย 1 มีความไวต่อค่าที่ผิดปกติน้อยกว่าการสูญเสีย L2
ค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์คือการสูญเสีย L1 โดยเฉลี่ยต่อตัวอย่าง
การกำหนดกฎ L1
ประเภทรูปแบบการจัดสรรที่หักค่าน้ำหนักเป็นสัดส่วนกับผลรวมของค่าสัมบูรณ์ของน้ำหนัก การกำหนดกฎ L1 ช่วยให้น้ำหนักของฟีเจอร์ที่ไม่เกี่ยวข้องหรือแทบจะไม่เกี่ยวข้องเป็น 0 เลย ระบบนำฟีเจอร์ที่มีน้ำหนักเป็น 0 ออกจากโมเดลอย่างเหมาะสม
คอนทราสต์กับการกำหนดกฎ L2
แพ้ L2
ฟังก์ชัน Los ที่คำนวณค่ากำลังสองของความแตกต่างระหว่างค่า label จริงกับค่าที่โมเดลคาดการณ์ เช่น การคำนวณการสูญเสีย L2 สำหรับกลุ่ม 5 ตัวอย่าง
| มูลค่าจริงของตัวอย่าง | ค่าที่คาดการณ์ไว้ของโมเดล | กำลังสองของเดลต้า |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 แพ้ | ||
เนื่องจากการยกกำลังสอง L2 จะขยายอิทธิพลของค่าที่ผิดปกติ กล่าวคือ การสูญเสีย L2 ตอบสนองอย่างมากต่อการคาดการณ์ที่ผิดพลาดมากกว่าการสูญเสีย L1 เช่น การสูญเสีย L1 สำหรับกลุ่มก่อนหน้าจะเป็น 8 ไม่ใช่ 16 โปรดสังเกตว่าค่าที่ผิดปกติ แต่ละรายการมีค่าเป็น 9 ใน 16
โมเดลการถดถอยมักจะใช้การสูญเสีย L2 เป็นฟังก์ชันการสูญเสีย
ค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง คือการสูญเสีย L2 โดยเฉลี่ยต่อตัวอย่าง Squared Los เป็นอีกชื่อหนึ่งของการสูญเสีย L2
การกำหนดกฎ L2
ประเภทของรูปแบบการจัดสรรที่หักลบน้ำหนักตามสัดส่วนของผลรวมของกำลังสองของน้ำหนัก การกำหนดกฎ L2 ช่วยให้น้ำหนักค่าผิดปกติ (ที่มีค่าบวกสูงหรือค่าลบต่ำ) มีค่าใกล้เคียงกับ 0 แต่ไม่เชิงถึง 0 ฟีเจอร์ที่มีค่าใกล้ 0 มากจะยังคงอยู่ในโมเดล แต่จะไม่ส่งผลต่อการคาดการณ์ของโมเดลมากนัก
การกำหนดรูปแบบ L2 จะปรับปรุงการสรุปเนื้อหาในโมเดลเชิงเส้นเสมอ
คอนทราสต์กับการกำหนดกฎ L1
ป้ายกำกับ
ในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล ส่วน "คำตอบ" หรือ "ผลลัพธ์" ของตัวอย่าง
ตัวอย่างที่ติดป้ายกำกับแต่ละรายการประกอบด้วยฟีเจอร์อย่างน้อย 1 รายการและป้ายกำกับ เช่น ในชุดข้อมูลการตรวจจับสแปม ป้ายกำกับอาจเป็น "สแปม" หรือ "ไม่ใช่สแปม" ในชุดข้อมูลปริมาณฝน ป้ายกำกับอาจหมายถึงปริมาณน้ำฝนที่ตกลงในช่วงเวลาหนึ่งๆ
ตัวอย่างที่มีป้ายกำกับ
ตัวอย่างที่มีฟีเจอร์อย่างน้อย 1 รายการและป้ายกำกับ ตัวอย่างเช่น ตารางต่อไปนี้แสดงตัวอย่าง 3 แบบที่มีป้ายกำกับจากรูปแบบการประเมินราคาบ้าน โดยแต่ละรายการมีฟีเจอร์ 3 รายการและป้ายกำกับ 1 ป้าย
| จำนวนห้องนอน | จำนวนห้องน้ำ | อายุบ้าน | ราคาบ้าน (ป้ายกำกับ) |
|---|---|---|---|
| 3 | 2 | 15 | 10,350,000 บาท |
| 2 | 1 | 72 | 5,280,000 บาท |
| 4 | 2 | 34 | 392,000 ดอลลาร์ |
ในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล โมเดลจะฝึกตามตัวอย่างที่มีป้ายกำกับและคาดการณ์ตัวอย่างที่ไม่มีป้ายกำกับ
ตัดกันกับตัวอย่างที่มีป้ายกำกับกับตัวอย่างที่ไม่มีป้ายกำกับ
แลมบ์ดา
คำพ้องของอัตราปกติ
คำว่า Lambda เป็นคำศัพท์ที่มากเกินไป เราจะเน้นไปที่คำจำกัดความของคำศัพท์ในการกำหนดรูปแบบที่สอดคล้องกัน
ชั้น
ชุดของเซลล์ประสาทในโครงข่ายประสาท เลเยอร์ทั่วไปมี 3 ประเภท ดังต่อไปนี้
- เลเยอร์อินพุต ซึ่งระบุค่าสำหรับฟีเจอร์ทั้งหมด
- มีเลเยอร์ที่ซ่อนไว้อย่างน้อย 1 เลเยอร์ ซึ่งจะพบความสัมพันธ์ที่ไม่ใช่แบบเชิงเส้นระหว่างจุดสนใจและป้ายกำกับ
- เลเยอร์เอาต์พุต ซึ่งจะมอบการคาดการณ์
ตัวอย่างเช่น ภาพต่อไปนี้แสดงโครงข่ายประสาทที่มีเลเยอร์อินพุต 1 เลเยอร์ เลเยอร์ซ่อน 2 เลเยอร์ และเลเยอร์เอาต์พุต 1 ชั้น
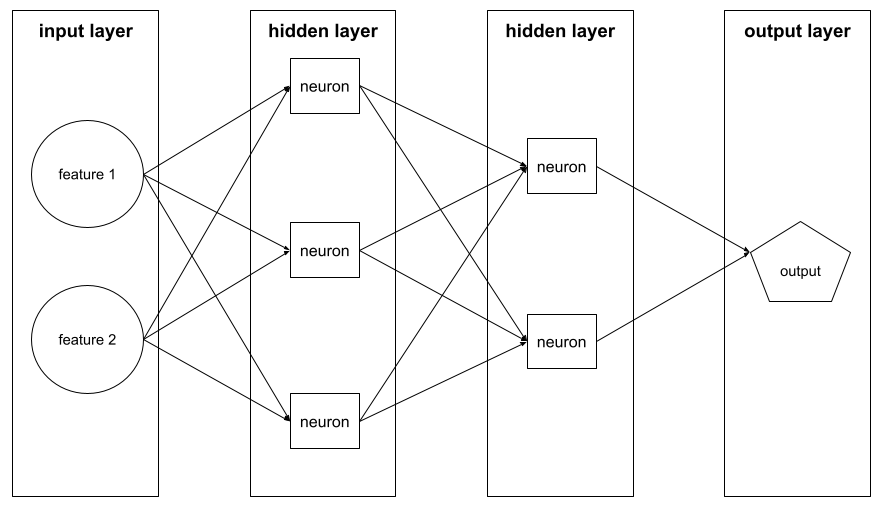
ใน TensorFlow เลเยอร์ยังเป็นฟังก์ชัน Python ที่ใช้ Tensor และตัวเลือกการกำหนดค่าเป็นอินพุตและสร้าง Tensor อื่นๆ เป็นเอาต์พุต
อัตราการเรียนรู้
ตัวเลขลอยตัวที่บอกอัลกอริทึมการไล่ระดับสีว่าจะปรับน้ำหนักและการให้น้ำหนักพิเศษในการทำซ้ำแต่ละรายการมากเพียงใด เช่น อัตราการเรียนรู้ที่ 0.3 จะปรับน้ำหนักและความให้น้ำหนักพิเศษได้มากกว่าอัตราการเรียนรู้ที่ 0.1 ถึง 3 เท่า
อัตราการเรียนรู้คือไฮเปอร์พารามิเตอร์ที่สำคัญ หากคุณกำหนดอัตราการเรียนรู้ต่ำเกินไป การฝึกจะใช้เวลานานเกินไป หากคุณตั้งอัตราการเรียนรู้สูงเกินไป การไล่ระดับสีต่ำลงมักจะมีปัญหาในการเข้าถึงการสนทนา
เชิงเส้น
ความสัมพันธ์ระหว่างตัวแปรตั้งแต่ 2 ตัวขึ้นไปที่สามารถแสดงผ่านการเพิ่มและการคูณเพียงอย่างเดียว
พล็อตของความสัมพันธ์เชิงเส้นคือเส้น
คอนทราสต์กับเนื้อหาที่ไม่ใช่เชิงเส้น
รูปแบบเชิงเส้น
modelที่กำหนดmodel 1 รายการต่อmodelเพื่อสร้างmodel (รูปแบบเชิงเส้นยังมีอคติรวมอยู่ด้วย) ในทางตรงกันข้าม ความสัมพันธ์ของฟีเจอร์กับการคาดการณ์ในโมเดลเชิงลึกโดยทั่วไปจะไม่เป็นเชิงเส้น
รูปแบบเชิงเส้นมักฝึกได้ง่ายกว่าและตีความได้มากกว่าโมเดลเชิงลึก อย่างไรก็ตาม โมเดลเชิงลึกจะเรียนรู้ความสัมพันธ์ที่ซับซ้อนระหว่างฟีเจอร์ต่างๆ ได้
การถดถอยเชิงเส้นและการถดถอยแบบโลจิสติกเป็นรูปแบบเชิงเส้น 2 ประเภท
การถดถอยเชิงเส้น
โมเดลแมชชีนเลิร์นนิงประเภทหนึ่งที่มีลักษณะดังนี้
- โมเดลนี้เป็นรูปแบบเชิงเส้น
- การคาดคะเนจะเป็นค่าทศนิยม (นี่คือส่วนการถดถอยของการถดถอยเชิงเส้น)
คอนทราสต์การถดถอยเชิงเส้นกับการถดถอยแบบโลจิสติก รวมถึงการถดถอยคอนทราสต์กับการแยกประเภท
การถดถอยแบบโลจิสติก
โมเดลการถดถอยประเภทหนึ่งที่คาดการณ์ความน่าจะเป็น โมเดลการถดถอยแบบโลจิสติกมีลักษณะดังต่อไปนี้
- ป้ายกำกับเป็นหมวดหมู่ คำว่า "โลจิสติกส์" มักจะหมายถึงการถดถอยแบบโลจิสติกส์แบบไบนารี ซึ่งก็คือโมเดลที่คำนวณความน่าจะเป็นของป้ายกำกับที่มีค่าที่เป็นไปได้ 2 ค่า ตัวแปรการถดถอยแบบลอจิสติกส์แบบพหุนามตัวแปรที่พบน้อยกว่า จะคำนวณความน่าจะเป็นสำหรับป้ายกำกับที่มีค่าที่เป็นไปได้มากกว่า 2 ค่า
- ฟังก์ชันการสูญเสียในระหว่างการฝึกคือ บันทึกสูญหาย (คุณสามารถวางหน่วยการสูญเสียบันทึกหลายหน่วยพร้อมกันสำหรับป้ายกำกับที่มีค่าที่เป็นไปได้มากกว่า 2 ค่า)
- โมเดลมีสถาปัตยกรรมแบบเส้นตรง ไม่ใช่โครงข่ายประสาทแบบลึก อย่างไรก็ตาม ส่วนที่เหลือของคําจํากัดความนี้ยังใช้กับโมเดลเชิงลึกที่คาดการณ์ความน่าจะเป็นสำหรับป้ายกํากับตามหมวดหมู่ได้ด้วย
เช่น ลองพิจารณาโมเดลการถดถอยแบบโลจิสติกซึ่งคำนวณความเป็นไปได้ที่อีเมลอินพุตจะเป็นสแปมหรือไม่เป็นจดหมายขยะ ในระหว่างการอนุมาน สมมติว่าโมเดลคาดการณ์ 0.72 ดังนั้น โมเดลนี้ จึงประมาณข้อมูลต่อไปนี้
- โอกาส 72% ที่อีเมลจะเป็นสแปม
- มีโอกาส 28% ที่อีเมลจะไม่เป็นจดหมายขยะ
โมเดลการถดถอยแบบโลจิสติกใช้สถาปัตยกรรม 2 ขั้นตอนต่อไปนี้
- โมเดลจะสร้างการคาดการณ์ดิบ (y") โดยใช้ฟังก์ชันเชิงเส้นของฟีเจอร์อินพุต
- โมเดลนี้ใช้การคาดการณ์แบบข้อมูลดิบดังกล่าวเป็นอินพุตไปยังฟังก์ชันซิกมอยด์ ซึ่งจะแปลงการคาดการณ์ดิบเป็นค่าระหว่าง 0 ถึง 1 (ที่ไม่ซ้ำกัน)
โมเดลการถดถอยแบบโลจิสติกจะคาดการณ์จำนวนได้เช่นเดียวกับโมเดลการถดถอย แต่โดยปกติแล้วตัวเลขนี้จะกลายเป็นส่วนหนึ่งของโมเดลการจัดประเภทแบบไบนารี ดังนี้
- หากจำนวนที่คาดการณ์มากกว่าเกณฑ์การจัดประเภท โมเดลการจัดประเภทแบบไบนารีจะคาดการณ์คลาสที่เป็นบวก
- หากจำนวนที่คาดการณ์น้อยกว่าเกณฑ์การจัดประเภท โมเดลการจัดประเภทแบบไบนารีจะคาดการณ์คลาสที่เป็นลบ
บันทึกหายไป
ฟังก์ชันการสูญเสียที่ใช้ในการถดถอยแบบโลจิสติกแบบไบนารี
โอกาสในการบันทึก
ลอการิทึมของความน่าจะเป็นของเหตุการณ์บางอย่าง
แพ้
ในระหว่างการฝึกของโมเดลที่มีการควบคุมดูแล ระบบจะวัดว่าการคาดคะเนของโมเดลอยู่ห่างจากป้ายกำกับเท่าใด
ฟังก์ชันการสูญเสียจะคำนวณการสูญเสีย
เส้นโค้งการสูญเสีย
พล็อต loss ในรูปฟังก์ชันของจำนวนการทำซ้ำการฝึก พล็อตต่อไปนี้จะแสดงเส้นโค้งของการสูญเสียโดยทั่วไป
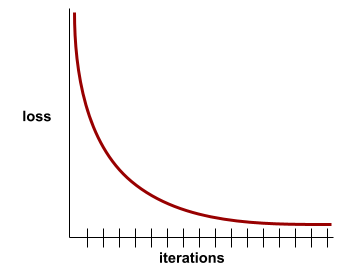
เส้นโค้งการสูญเสียช่วยให้คุณระบุเวลาที่โมเดลกำลังสนทนาหรือซ้อนทับได้
เส้นโค้งการสูญเสียสามารถพล็อตการสูญเสียทุกประเภทต่อไปนี้
ดูเส้นโค้งภาพรวมด้วย
ฟังก์ชันการสูญเสีย
ในระหว่างการฝึกหรือการทดสอบ ฟังก์ชันทางคณิตศาสตร์ที่ใช้คำนวณความสูญเสียในกลุ่มของตัวอย่าง ฟังก์ชันการสูญเสียจะส่งคืนความสูญเสียต่ำกว่าสำหรับโมเดลที่ให้การคาดการณ์ที่ดีเมื่อเทียบกับโมเดลที่ทำการคาดการณ์ได้ไม่ดี
โดยทั่วไป เป้าหมายของการฝึกคือเพื่อลดการสูญเสียที่ฟังก์ชัน Loss กลับมา
มีฟังก์ชันการสูญเสียหลายรูปแบบ เลือกฟังก์ชันการสูญเสียที่เหมาะกับชนิดของโมเดลที่คุณกำลังสร้าง เช่น
- L2 Loss (หรือ Mean Squared Error) คือฟังก์ชันการสูญเสียสำหรับการถดถอยเชิงเส้น
- Log Loss คือฟังก์ชันการสูญเสียสำหรับการถดถอยแบบโลจิสติกส์
M
แมชชีนเลิร์นนิง
โปรแกรมหรือระบบที่ฝึกโมเดลจากข้อมูลอินพุต โมเดลที่ผ่านการฝึกจะสร้างการคาดการณ์ที่เป็นประโยชน์จากข้อมูลใหม่ (ไม่เคยเห็นมาก่อน) ที่มาจากการกระจายข้อมูลเดียวกันกับที่ใช้ฝึกโมเดล
แมชชีนเลิร์นนิงยังหมายถึงสาขาวิชาที่เกี่ยวข้องกับโปรแกรมหรือระบบเหล่านี้ด้วย
คลาสส่วนใหญ่
ป้ายกำกับที่พบได้บ่อยในชุดข้อมูลที่ไม่สมดุลระดับคลาส ตัวอย่างเช่น หากชุดข้อมูลที่มีป้ายกำกับเชิงลบ 99% และป้ายกำกับเชิงบวก 1% ป้ายกำกับดังกล่าวคือคลาสส่วนใหญ่
ตรงข้ามกับชนกลุ่มน้อย
กลุ่มขนาดเล็ก
ชุดย่อยขนาดเล็กที่สุ่มเลือกของกลุ่มซึ่งประมวลผลในการทำซ้ำ 1 รายการ ขนาดกลุ่มของกลุ่มเล็กๆ มักจะอยู่ระหว่าง 10 ถึง 1,000 ตัวอย่าง
เช่น สมมติว่าชุดการฝึกทั้งชุด (กลุ่มทั้งหมด) ประกอบด้วยตัวอย่าง 1,000 รายการ นอกจากนี้ สมมติว่าคุณตั้งค่าขนาดกลุ่มของแต่ละกลุ่มขนาดเล็กเป็น 20 ดังนั้น การทำซ้ำแต่ละรายการจะระบุความสูญเสียของตัวอย่าง 20 รายการจากทั้งหมด 1,000 รายการแบบสุ่ม จากนั้นจะปรับน้ำหนักและอคติตามนั้น
การคํานวณการสูญเสียในชุดย่อยจะมีประสิทธิภาพมากกว่าการขาดทุนในตัวอย่างทั้งหมดในกลุ่มที่สมบูรณ์
ชนชั้นน้อย
ป้ายกำกับที่พบไม่บ่อยในชุดข้อมูลที่ไม่สมดุลระดับคลาส ตัวอย่างเช่น หากชุดข้อมูลที่มีป้ายกำกับลบ 99% และป้ายกำกับเชิงบวก 1% ป้ายกำกับเชิงบวกคือกลุ่มชนกลุ่มน้อย
ตรงข้ามกับกลุ่มใหญ่
model
โดยทั่วไป โครงสร้างทางคณิตศาสตร์ใดๆ ที่ประมวลผลข้อมูลอินพุตและเอาต์พุตกลับ พูดง่ายๆ ก็คือ โมเดลคือชุดของพารามิเตอร์และโครงสร้างที่จำเป็นสำหรับระบบเพื่อทำการคาดการณ์ ในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล โมเดลจะใช้ตัวอย่างเป็นอินพุตและอนุมานการคาดคะเนเป็นเอาต์พุต ภายในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล โมเดลจะแตกต่างไปบ้าง เช่น
- โมเดลการถดถอยเชิงเส้นประกอบด้วยชุดน้ำหนักและอคติ
- โมเดลโครงข่ายระบบประสาทเทียมประกอบด้วย
- ชุดของเลเยอร์ที่ซ่อนอยู่ แต่ละชั้นมีเซลล์ประสาทอย่างน้อย 1 ชั้น
- น้ำหนักและการให้น้ำหนักที่สัมพันธ์กับเซลล์ประสาทแต่ละเซลล์
- โมเดลแผนผังการตัดสินใจประกอบด้วย
- รูปร่างของต้นไม้ ซึ่งก็คือรูปแบบที่มีการเชื่อมโยงเงื่อนไขและใบไม้เข้าด้วยกัน
- เงื่อนไขและออกจากสถานที่
คุณจะบันทึก กู้คืน หรือทำสำเนาของโมเดลได้
แมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแลยังสร้างโมเดล ซึ่งโดยทั่วไปจะเป็นฟังก์ชันที่แมปตัวอย่างอินพุตกับคลัสเตอร์ที่เหมาะสมที่สุดได้
การจัดประเภทแบบหลายคลาส
ในการเรียนรู้ภายใต้การควบคุมดูแล ปัญหาการแยกประเภทซึ่งชุดข้อมูลมีป้ายกำกับมากกว่า 2 คลาส ตัวอย่างเช่น ป้ายกำกับในชุดข้อมูล Iris ต้องเป็น 1 ใน 3 คลาสต่อไปนี้
- ไอริสเซโตซา
- ไอริสเวอร์จิเนีย
- สีม่านตา
โมเดลที่ฝึกจากชุดข้อมูล Iris ที่คาดการณ์ประเภท Iris ในตัวอย่างใหม่กำลังทำการจัดประเภทแบบหลายคลาส
ในทางตรงกันข้าม ปัญหาการจัดประเภทที่แยกความแตกต่างระหว่างคลาส 2 คลาสจริงๆ คือโมเดลการจัดประเภทแบบไบนารี เช่น โมเดลอีเมลที่คาดคะเนสแปมหรือไม่ใช่สแปมคือโมเดลการจัดประเภทแบบไบนารี
ในปัญหาการจัดกลุ่ม การจัดประเภทแบบหลายคลาสหมายถึงคลัสเตอร์มากกว่า 2 คลัสเตอร์
N
คลาสเชิงลบ
ในการจัดประเภทไบนารี คลาสหนึ่งเรียกว่าเชิงบวก และอีกคลาสเรียกว่าเชิงลบ คลาสเชิงบวกคือสิ่งที่โมเดลหรือเหตุการณ์ที่โมเดลกำลังทดสอบ ส่วนคลาสเชิงลบก็เป็นความเป็นไปได้อื่น เช่น
- ชนิดที่ติดลบในการทดสอบทางการแพทย์อาจเป็น "ไม่ใช่เนื้องอก"
- คลาสเชิงลบในตัวแยกประเภทอีเมลอาจเป็น "ไม่ใช่สแปม"
คอนทราสต์กับคลาสเชิงบวก
โครงข่ายระบบประสาทเทียม
modelที่มีmodelอย่างน้อย 1 รายการ โครงข่ายประสาทแบบลึก คือโครงข่ายประสาทประเภทหนึ่งที่มีเลเยอร์ซ่อนอยู่มากกว่า 1 ชั้น ตัวอย่างเช่น แผนภาพต่อไปนี้ แสดงโครงข่ายประสาทแบบลึกที่มีเลเยอร์ซ่อนอยู่ 2 ชั้น
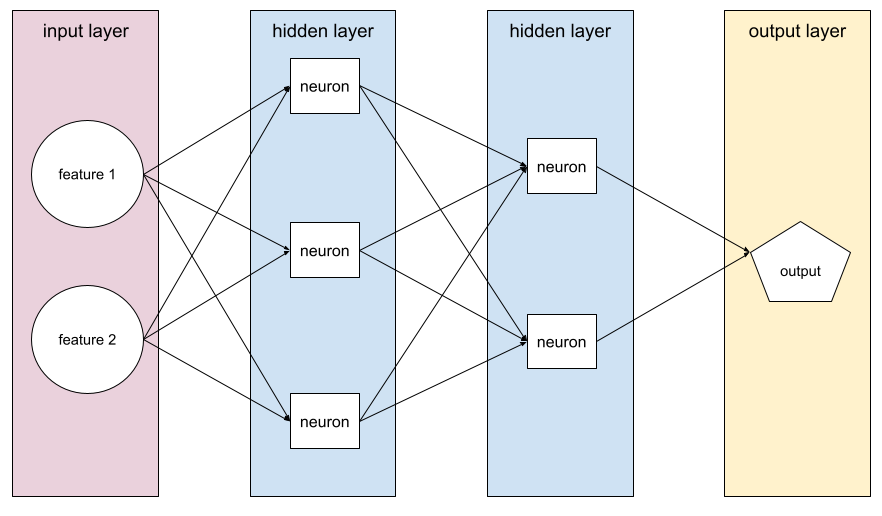
เซลล์ประสาทแต่ละเซลล์ในโครงข่ายประสาทจะเชื่อมต่อกับโหนดทั้งหมดในเลเยอร์ถัดไป ตัวอย่างเช่น ในแผนภาพก่อนหน้า ให้สังเกตว่าเซลล์ประสาทแต่ละเซลล์ในเลเยอร์ที่ซ่อนแรกจะเชื่อมต่อกับเซลล์ประสาททั้ง 2 เซลล์ของเซลล์ประสาททั้ง 2 เซลล์ในชั้นที่ 2 ที่ซ่อนอยู่แยกจากกัน
บางครั้งก็เรียกว่าโครงข่ายประสาทเทียม ซึ่งจะแยกออกจากโครงข่ายประสาทที่พบในสมองและระบบประสาทอื่นๆ
โครงข่ายประสาทบางเครือข่ายอาจเลียนแบบความสัมพันธ์แบบไม่ใช่เชิงเส้นที่ซับซ้อนมากระหว่างฟีเจอร์ต่างๆ และป้ายกำกับ
โปรดดูโครงข่ายระบบประสาทเทียมและโครงข่ายประสาทแบบเกิดซ้ำ
เซลล์ประสาท
ในแมชชีนเลิร์นนิง หน่วยที่แตกต่างกันภายในเลเยอร์ที่ซ่อนอยู่ของโครงข่ายระบบประสาทเทียม เซลล์ประสาทแต่ละเซลล์จะทำงาน ใน 2 ขั้นตอนดังต่อไปนี้
- จะคำนวณผลรวมถ่วงน้ำหนักของค่าที่ป้อนคูณด้วยน้ำหนักที่สัมพันธ์กัน
- ส่งต่อผลรวมน้ำหนักเป็นอินพุตไปยังฟังก์ชันการเปิดใช้งาน
เซลล์ประสาทในเลเยอร์แรกที่ซ่อนอยู่จะยอมรับอินพุตจากค่าฟีเจอร์ในเลเยอร์อินพุต เซลล์ประสาทในเลเยอร์ที่ซ่อนอยู่นอกเหนือจากชั้นแรกจะรับอินพุตจากเซลล์ประสาทในชั้นที่ซ่อนอยู่ที่อยู่ก่อนหน้า เช่น เซลล์ประสาทในชั้นที่ 2 ที่ซ่อนอยู่จะยอมรับอินพุตจากเซลล์ประสาทในชั้นแรกที่ซ่อนอยู่
ภาพต่อไปนี้จะไฮไลต์เซลล์ประสาทสองเซลล์และข้อมูลของเซลล์เหล่านั้น
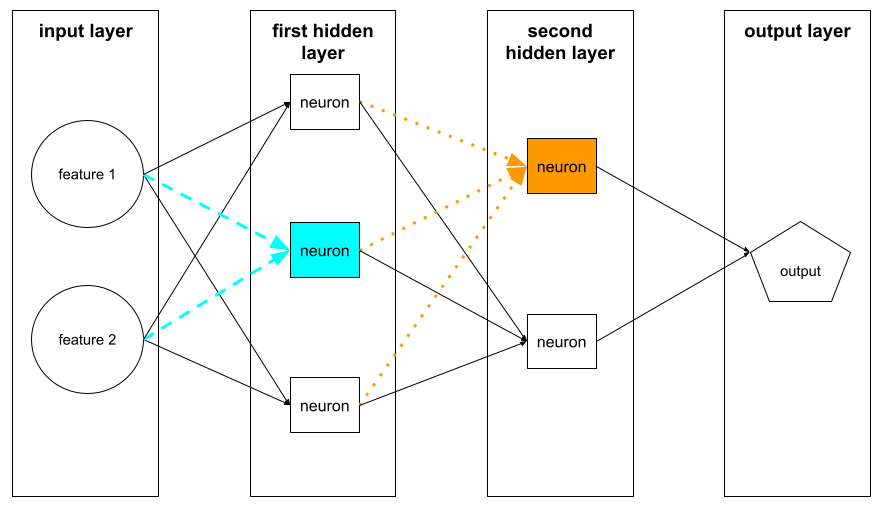
เซลล์ประสาทในโครงข่ายประสาทจะเลียนแบบพฤติกรรมของเซลล์ประสาทในสมองและส่วนอื่นๆ ของระบบประสาท
โหนด (โครงข่ายระบบประสาทเทียม)
เซลล์ประสาทในเลเยอร์ที่ซ่อนอยู่
ไม่เป็นเชิงเส้น
ความสัมพันธ์ระหว่างตัวแปรตั้งแต่ 2 ตัวขึ้นไปที่ไม่สามารถนำเสนอผ่านการเพิ่มและการคูณเพียงอย่างเดียวได้ ความสัมพันธ์แบบเชิงเส้นอาจแสดงเป็นเส้น ความสัมพันธ์แบบไม่ใช่เชิงเส้นจะแสดงแบบเส้นไม่ได้ เช่น ลองพิจารณาโมเดล 2 รูปแบบที่แต่ละโมเดล เชื่อมโยงฟีเจอร์เดียวกับป้ายกำกับป้ายเดียว โมเดลด้านซ้ายเป็นเชิงเส้น และโมเดลด้านขวาไม่ใช่แบบเชิงเส้น

ความไม่คงที่
ฟีเจอร์ที่มีค่าเปลี่ยนแปลงในมิติข้อมูลอย่างน้อย 1 รายการ ซึ่งโดยปกติจะเป็นเวลา ตัวอย่างเช่น ลองพิจารณาตัวแสดงค่าที่ไม่คงที่ดังต่อไปนี้
- จํานวนชุดว่ายน้ำที่ขายในร้านค้าหนึ่งๆ จะแตกต่างกันไปตามฤดูกาล
- ผลไม้ชนิดหนึ่งที่เก็บในภูมิภาคหนึ่งๆ จะมีปริมาณเป็น 0 ในช่วงเวลาส่วนใหญ่ของปี แต่จะสูงเป็นระยะเวลาสั้นๆ
- เนื่องจากการเปลี่ยนแปลงสภาพภูมิอากาศ ทำให้อุณหภูมิเฉลี่ยต่อปีมีการเปลี่ยนแปลง
คอนทราสต์กับความคงที่
การปรับให้เป็นมาตรฐาน
กล่าวกว้างๆ ก็คือขั้นตอนการแปลงช่วงค่าจริงของตัวแปรให้อยู่ในช่วงค่ามาตรฐาน เช่น
- -1 ถึง +1
- 0 ถึง 1
- การกระจายปกติ
ตัวอย่างเช่น สมมติว่าช่วงจริงของค่าฟีเจอร์หนึ่งคือ 800 ถึง 2,400 ในวิศวกรรมฟีเจอร์ คุณสามารถปรับค่าจริงให้อยู่ในระดับมาตรฐานได้ เช่น -1 ถึง +1
การปรับให้สอดคล้องตามมาตรฐานเป็นงานทั่วไปในวิศวกรรมฟีเจอร์ โมเดลมักจะฝึกได้เร็วขึ้น (และคาดการณ์ได้ดีกว่า) เมื่อฟีเจอร์ตัวเลขทั้งหมดใน เวกเตอร์ฟีเจอร์ มีช่วงใกล้เคียงกัน
ข้อมูลตัวเลข
ฟีเจอร์ซึ่งแสดงเป็นจำนวนเต็มหรือจำนวนจริง เช่น รูปแบบการตีราคาบ้านอาจแสดงขนาดบ้าน (เป็นตารางฟุตหรือตารางเมตร) เป็นข้อมูลตัวเลข การนำเสนอฟีเจอร์เป็นข้อมูลตัวเลขซึ่งบ่งบอกว่าค่าของฟีเจอร์มีความสัมพันธ์ทางคณิตศาสตร์กับป้ายกำกับ กล่าวคือ จำนวนตารางเมตรในบ้านน่าจะมีความสัมพันธ์ทางคณิตศาสตร์บางอย่างกับมูลค่าของบ้าน
ข้อมูลจำนวนเต็มบางรายการไม่ควรแสดงเป็นข้อมูลตัวเลข ตัวอย่างเช่น รหัสไปรษณีย์ในบางพื้นที่ของโลกเป็นจำนวนเต็ม อย่างไรก็ตาม รหัสไปรษณีย์ไม่ควรแสดงเป็นข้อมูลตัวเลขในโมเดล เนื่องจากรหัสไปรษณีย์ของ 20000 ไม่ใช่ 2 (หรือครึ่งหนึ่ง) ที่เทียบเท่ากับรหัสไปรษณีย์ 10000 นอกจากนี้ แม้ว่ารหัสไปรษณีย์ต่างๆ จะมีความเกี่ยวข้องกับมูลค่าอสังหาริมทรัพย์ที่ต่างกัน แต่เราก็ไม่สามารถสรุปได้ว่ามูลค่าอสังหาริมทรัพย์ตามรหัสไปรษณีย์ 20000 มีมูลค่าเป็น 2 เท่าของมูลค่าอสังหาริมทรัพย์ที่รหัสไปรษณีย์ 10000
รหัสไปรษณีย์ควรแสดงเป็นข้อมูลตามหมวดหมู่แทน
บางครั้งเราเรียกฟีเจอร์ที่เป็นตัวเลขว่าฟีเจอร์แบบต่อเนื่อง
O
ออฟไลน์
คำพ้องของ static
การอนุมานแบบออฟไลน์
กระบวนการของโมเดลที่สร้างการคาดการณ์ชุดหนึ่ง แล้วแคช (บันทึก) การคาดการณ์เหล่านั้น จากนั้นแอปจะเข้าถึงการคาดการณ์ที่ต้องการจากแคชแทนการเรียกใช้โมเดลอีกครั้ง
ตัวอย่างเช่น ลองพิจารณาโมเดลที่สร้างการพยากรณ์อากาศในท้องถิ่น (การพยากรณ์อากาศ) 1 ครั้งในทุกๆ 4 ชั่วโมง หลังจากแต่ละโมเดลทำงานแล้ว ระบบจะแคชข้อมูลการพยากรณ์อากาศท้องถิ่นทั้งหมด แอปสภาพอากาศจะเรียกพยากรณ์อากาศ จากแคช
การอนุมานแบบออฟไลน์เรียกอีกอย่างว่าการอนุมานแบบคงที่
คอนทราสต์กับการอนุมานออนไลน์
การเข้ารหัสแบบ One-hot
แสดงข้อมูลเชิงหมวดหมู่เป็นเวกเตอร์ที่
- องค์ประกอบ 1 รายการได้รับการตั้งค่าเป็น 1
- องค์ประกอบอื่นๆ ทั้งหมดจะกำหนดไว้เป็น 0
การเข้ารหัสแบบ One-Hot นั้นมักใช้กันเพื่อแสดงถึงสตริงหรือตัวระบุที่มีชุดค่าที่เป็นไปได้ที่แน่นอน
ตัวอย่างเช่น สมมติว่าฟีเจอร์เชิงหมวดหมู่ชื่อ Scandinavia มีค่าที่เป็นไปได้ 5 ค่า ดังนี้
- "เดนมาร์ก"
- "สวีเดน"
- "นอร์เวย์"
- "ฟินแลนด์"
- "ไอซ์แลนด์"
การเข้ารหัสแบบ Hot-Hot สามารถแสดงแต่ละค่าในห้าค่าดังต่อไปนี้:
| country | เวกเตอร์ | ||||
|---|---|---|---|---|---|
| "เดนมาร์ก" | 1 | 0 | 0 | 0 | 0 |
| "สวีเดน" | 0 | 1 | 0 | 0 | 0 |
| "นอร์เวย์" | 0 | 0 | 1 | 0 | 0 |
| "ฟินแลนด์" | 0 | 0 | 0 | 1 | 0 |
| "ไอซ์แลนด์" | 0 | 0 | 0 | 0 | 1 |
การเข้ารหัสแบบ Hot-Hot ช่วยให้โมเดลเรียนรู้การเชื่อมต่อที่แตกต่างกันตามแต่ละประเทศ 5 ประเทศได้
การแสดงฟีเจอร์เป็น ข้อมูลตัวเลข เป็นอีกทางเลือกหนึ่งของการเข้ารหัสแบบ 1-Hot แต่การแทนประเทศสแกนดิเนเวียด้วยตัวเลขไม่ใช่ตัวเลือกที่ดี ตัวอย่างเช่น ลองพิจารณาการนำเสนอด้วยตัวเลขต่อไปนี้
- "เดนมาร์ก" คือ 0
- "สวีเดน" คือ 1
- "นอร์เวย์" คือ 2
- "ฟินแลนด์" คือ 3
- "ไอซ์แลนด์" คือ 4
ด้วยการเข้ารหัสตัวเลข โมเดลจะตีความตัวเลขดิบทางคณิตศาสตร์ และจะพยายามฝึกกับตัวเลขเหล่านั้น แต่ประเทศไอซ์แลนด์ไม่ได้มากกว่านอร์เวย์ 2 เท่า (หรือครึ่งหนึ่ง) เลยทำให้ได้ข้อสรุปที่แปลกๆ
หนึ่งต่อทั้งหมด
จากปัญหาการจัดประเภทของคลาส N คำตอบจะประกอบด้วยตัวแยกประเภทแบบไบนารีแยกกัน N รายการ ซึ่งเป็นตัวแยกประเภทไบนารีสำหรับผลลัพธ์ที่เป็นไปได้แต่ละรายการ ตัวอย่างเช่น สำหรับโมเดลที่จำแนกตัวอย่างเป็นสัตว์ ผัก หรือแร่ โซลูชันแบบหนึ่งเทียบกับทั้งหมดจะให้ตัวแยกประเภทแบบไบนารีที่แยกกัน 3 รายการต่อไปนี้
- สัตว์กับไม่ใช่สัตว์
- ผักกับไม่ใช่ผัก
- Mineral เทียบกับ ไม่ใช่แร่
ออนไลน์
คำพ้องความหมายสำหรับ dynamic
การอนุมานออนไลน์
สร้างการคาดการณ์ตามคำขอ ตัวอย่างเช่น สมมติว่าแอปส่งอินพุตไปยังโมเดลและออกคำขอสำหรับการคาดการณ์ ระบบที่ใช้การอนุมานออนไลน์จะตอบสนองต่อคำขอโดยเรียกใช้โมเดล (และแสดงผลการคาดการณ์ไปยังแอป)
คอนทราสต์กับการอนุมานแบบออฟไลน์
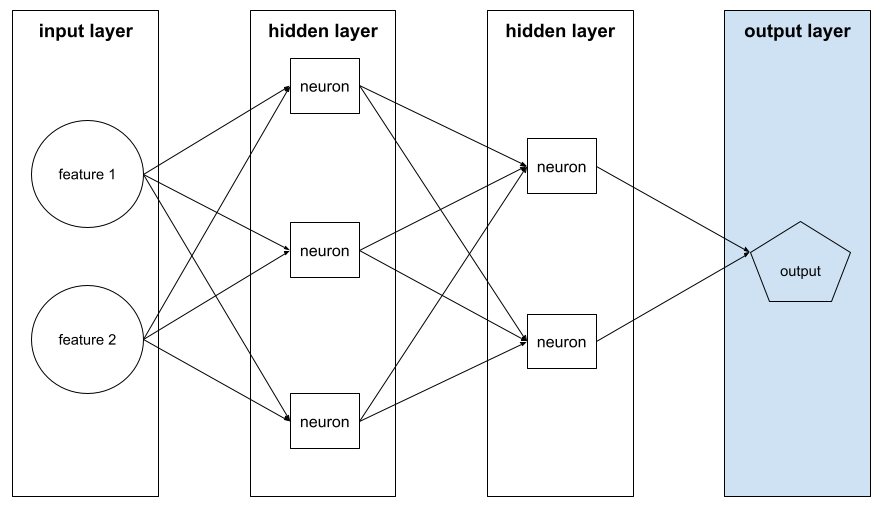
เลเยอร์เอาต์พุต
ชั้น "สุดท้าย" ของโครงข่ายประสาท เลเยอร์เอาต์พุตมีการคาดการณ์
ภาพต่อไปนี้แสดงโครงข่ายประสาทแบบลึกขนาดเล็กที่มีเลเยอร์อินพุต เลเยอร์ที่ซ่อนอยู่ 2 เลเยอร์ และเลเยอร์เอาต์พุต
Overfitting
การสร้างmodelที่ตรงกับmodelให้ใกล้เคียงมากจนทำให้โมเดลคาดการณ์ข้อมูลใหม่ไม่ถูกต้อง
การปรับให้สม่ำเสมอช่วยลดการปรับให้มากเกินไปได้ การฝึกอบรมในชุดการฝึกอบรมที่มีขนาดใหญ่และหลากหลายยังสามารถลดการออกกำลังกายมากเกินไปได้
คะแนน
แพนด้า
API การวิเคราะห์ข้อมูลแบบคอลัมน์ซึ่งสร้างขึ้นจาก numpy เฟรมเวิร์กแมชชีนเลิร์นนิงจำนวนมาก รวมถึง TensorFlow รองรับโครงสร้างข้อมูลแพนด้าเป็นอินพุต ดูรายละเอียดได้ที่ เอกสารประกอบเกี่ยวกับ Pandas
พารามิเตอร์
น้ำหนักและอคติที่โมเดลเรียนรู้ระหว่างการฝึก ตัวอย่างเช่น ในรูปแบบการถดถอยเชิงเส้น พารามิเตอร์ประกอบด้วยการให้น้ำหนักพิเศษ (b) และน้ำหนักทั้งหมด (w1, w2 และอื่นๆ) ในสูตรต่อไปนี้
ในทางตรงกันข้าม hyperparameter คือค่าที่ คุณ (หรือบริการเปลี่ยนไฮเปอร์พารามิเตอร์) จัดหาให้กับโมเดล เช่น อัตราการเรียนรู้คือไฮเปอร์พารามิเตอร์
คลาสเชิงบวก
ชั้นเรียนที่คุณจะทดสอบ
ตัวอย่างเช่น คลาสเชิงบวกในโมเดลมะเร็งอาจเป็น "เนื้องอก" คลาสเชิงบวกในตัวแยกประเภทอีเมลอาจเป็น "สแปม"
คอนทราสต์กับคลาสเชิงลบ
หลังการประมวลผล
การปรับเอาต์พุตของโมเดลหลังจากที่เรียกใช้โมเดลแล้ว คุณอาจใช้กระบวนการหลังการประมวลผลในการบังคับใช้ข้อจำกัดเกี่ยวกับความเป็นธรรมโดยไม่ต้องปรับเปลี่ยนโมเดลด้วยตนเอง
เช่น รายการหนึ่งอาจใช้หลังการประมวลผลกับตัวแยกประเภทแบบไบนารีโดยการตั้งค่าเกณฑ์การจัดประเภทเพื่อให้แอตทริบิวต์บางรายการคงความเท่ากันของโอกาสไว้ โดยตรวจสอบว่าอัตราผลบวกจริงเหมือนกันสำหรับค่าทั้งหมดของแอตทริบิวต์นั้น
การคาดการณ์
เอาต์พุตของโมเดล เช่น
- การคาดการณ์ของโมเดลการจัดประเภทแบบไบนารีอาจเป็นคลาสบวกหรือคลาสเชิงลบ
- การคาดการณ์ของโมเดลการจัดประเภทแบบหลายคลาสเป็น 1 คลาส
- การคาดการณ์ของโมเดลการถดถอยเชิงเส้นเป็นตัวเลข
ป้ายกำกับพร็อกซี
ข้อมูลที่ใช้ประมาณป้ายกำกับที่ไม่มีอยู่ในชุดข้อมูลโดยตรง
เช่น สมมติว่าคุณต้องฝึกโมเดลให้คาดการณ์ระดับความเครียดของพนักงาน ชุดข้อมูลมีฟีเจอร์การคาดการณ์จำนวนมาก แต่ไม่มีป้ายกำกับชื่อระดับความเครียด ไม่ต้องกังวล คุณจึงเลือก "อุบัติเหตุในที่ทำงาน" เป็นป้ายกำกับพร็อกซีสำหรับระดับความเครียด เพราะสุดท้ายแล้ว พนักงานที่อยู่ในช่วงที่มีความเครียดสูง ประสบกับอุบัติเหตุมากกว่าพนักงานที่สงบสุข หรือว่า อุบัติเหตุในที่ทำงาน อาจขึ้นๆ ลงๆ ได้จากหลายสาเหตุ
ตัวอย่างเช่น สมมติว่าคุณต้องการให้ฝนตกไหมเป็นป้ายกำกับบูลีนสำหรับชุดข้อมูล แต่ชุดข้อมูลไม่มีข้อมูลฝน กรณีที่มีถ่ายภาพได้ คุณอาจสร้างภาพคน ถือร่มเป็นป้ายชื่อพร็อกซีว่า ฝนตกไหม เป็นป้ายกำกับพร็อกซีที่ดีไหม หรืออาจจะ แต่ผู้คนในบางวัฒนธรรม มีแนวโน้มที่จะพกร่มเพื่อป้องกันแสงแดดมากกว่าฝน
ป้ายกำกับพร็อกซีมักจะไม่สมบูรณ์ เมื่อเป็นไปได้ ให้เลือกป้ายกำกับจริง แทนป้ายกำกับพร็อกซี อย่างไรก็ตาม เมื่อไม่มีป้ายกำกับจริง ให้เลือกป้ายกำกับพร็อกซีอย่างระมัดระวัง โดยเลือกใช้ป้ายกำกับพร็อกซีที่ไม่เหมาะสมน้อยที่สุด
R
ผู้ตรวจสอบ
บุคคลที่ให้ป้ายกำกับสำหรับตัวอย่าง "ผู้กำกับเนื้อหา" เป็นอีกชื่อหนึ่งของผู้ประเมิน
หน่วยเชิงเส้นตรง (ReLU)
ฟังก์ชันการเปิดใช้งานที่มีลักษณะการทำงานต่อไปนี้
- หากอินพุตเป็นลบหรือ 0 เอาต์พุตจะเป็น 0
- หากอินพุตเป็นบวก เอาต์พุตจะเท่ากับอินพุต
เช่น
- หากอินพุตเป็น -3 เอาต์พุตจะเป็น 0
- หากอินพุตเป็น +3 เอาต์พุตจะเป็น 3.0
พล็อตเรื่อง ReLU มีดังนี้
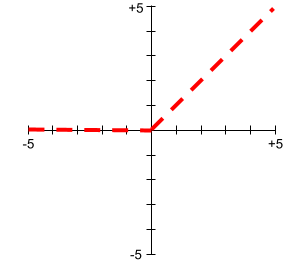
ReLU เป็นฟังก์ชันเปิดใช้งานที่ได้รับความนิยมอย่างมาก แม้จะมีลักษณะการทำงานที่ไม่ซับซ้อน แต่ ReLU ก็ยังคงช่วยให้โครงข่ายประสาทเรียนรู้ความสัมพันธ์ที่ไม่ใช่เชิงเส้นระหว่างฟีเจอร์และป้ายกำกับได้
โมเดลการถดถอย
แบบไม่เป็นทางการ เป็นโมเดลที่สร้างการคาดการณ์เชิงตัวเลข (ในทางตรงกันข้าม โมเดลการจัดประเภทจะสร้างการคาดการณ์คลาส) ตัวอย่างต่อไปนี้คือโมเดลการถดถอยทั้งหมด
- โมเดลที่คาดการณ์มูลค่าของบ้านบางหลัง เช่น 423,000 ยูโร
- โมเดลที่คาดการณ์อายุการใช้งานของต้นไม้ต้นหนึ่ง เช่น 23.2 ปี
- โมเดลที่คาดการณ์ปริมาณฝนที่จะตกในบางเมืองในช่วง 6 ชั่วโมงข้างหน้า เช่น 0.18 นิ้ว
รูปแบบการถดถอยที่พบบ่อยมี 2 ประเภท ได้แก่
- การถดถอยเชิงเส้น ซึ่งจะค้นหาบรรทัดที่เหมาะกับค่าของป้ายกำกับกับฟีเจอร์ต่างๆ มากที่สุด
- การถดถอยแบบโลจิสติกส์ ซึ่งสร้างความน่าจะเป็นระหว่าง 0.0 ถึง 1.0 ที่ระบบมักจะแมปกับการคาดคะเนคลาส
ไม่ใช่ทุกโมเดลที่แสดงการคาดการณ์เชิงตัวเลขที่เป็นรูปแบบการถดถอย ในบางกรณี การคาดการณ์แบบตัวเลขเป็นเพียงโมเดลการจัดประเภทที่มีชื่อคลาสเป็นตัวเลข เช่น โมเดลที่คาดการณ์รหัสไปรษณีย์ที่เป็นตัวเลขคือโมเดลการจัดประเภท ไม่ใช่โมเดลการถดถอย
Regularization
กลไกที่ลดการปรับให้พอดี ประเภทรูปแบบที่นิยมใช้กัน ได้แก่
- การกำหนดกฎ L1
- การกำหนดกฎ L2
- การกำหนดรูปแบบดรอปเอาต์
- การหยุดก่อนกำหนด (นี่ไม่ใช่วิธีการกำหนดรูปแบบเป็นทางการ แต่สามารถจำกัดการปรับมากเกินไปได้อย่างมีประสิทธิภาพ)
การปรับให้เป็นปกติอาจเป็นบทลงโทษสำหรับความซับซ้อนของโมเดล
อัตราการปรับให้เป็นมาตรฐาน
ตัวเลขที่ระบุความสำคัญเชิงสัมพัทธ์ของรูปแบบการจัดสรรในระหว่างการฝึก การเพิ่มอัตราการปรับรูปแบบสม่ำเสมอจะลดการปรับให้เหมาะสมแต่อาจลดประสิทธิภาพการคาดการณ์ของโมเดล ในทางกลับกัน การลดหรือละเว้นอัตราการปรับเป็นประจำจะเพิ่มมากเกินไป
ReLU
ตัวย่อของหน่วยเชิงเส้นแบบปรับเป็นหน่วย
รุ่น Augmented Reality สำหรับการดึงข้อมูล
สถาปัตยกรรมซอฟต์แวร์ที่ใช้กันโดยทั่วไปในแอปพลิเคชันโมเดลภาษาขนาดใหญ่ (LLM) แรงจูงใจทั่วไปในการใช้การสร้างการดึงข้อมูลเพิ่มเติม ได้แก่
- การเพิ่มความถูกต้องของข้อเท็จจริงของคำตอบที่สร้างขึ้นของโมเดล
- การให้สิทธิ์เข้าถึงความรู้ที่โมเดลไม่ได้รับการฝึกอบรม
- เปลี่ยนความรู้ที่โมเดลใช้
- ทำให้โมเดลสามารถอ้างอิงแหล่งที่มาได้
เช่น สมมติว่าแอปวิชาเคมีใช้ PaLM API เพื่อสร้างสรุปเกี่ยวกับ ข้อความค้นหาของผู้ใช้ เมื่อแบ็กเอนด์ของแอปได้รับคำค้นหา ระบบแบ็กเอนด์จะค้นหาข้อมูล ("การดึงข้อมูล") ที่เกี่ยวข้องกับคำค้นหาของผู้ใช้ก่อน จากนั้นจึงเติม ("เสริม") ข้อมูลเคมีที่เกี่ยวข้องไปกับคำค้นหาของผู้ใช้ และสั่งให้ LLM สร้างสรุปตามข้อมูลต่อท้าย
เส้นโค้ง ROC (องค์ประกอบการทำงานในฝั่งผู้รับ)
กราฟของอัตราผลบวกจริงกับอัตราผลบวกลวงสำหรับเกณฑ์การจัดประเภทที่แตกต่างกันในการจัดประเภทไบนารี
รูปร่างของเส้นโค้ง ROC แสดงถึงความสามารถของโมเดลการจัดประเภทแบบไบนารีในการแยกคลาสบวกออกจากคลาสเชิงลบ ตัวอย่างเช่น สมมติว่าโมเดลการจัดประเภทแบบไบนารีแยกคลาสเชิงลบทั้งหมดออกจากคลาสเชิงบวกทั้งหมดอย่างลงตัว
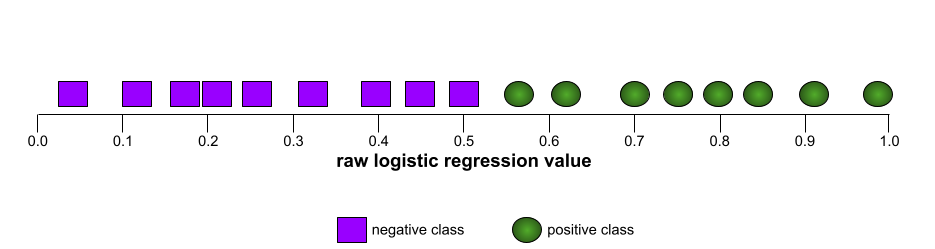
เส้นโค้ง ROC สำหรับรูปแบบก่อนหน้าจะมีลักษณะดังนี้
ในทางตรงกันข้าม ภาพประกอบต่อไปนี้จะแสดงกราฟค่าการถดถอยแบบโลจิสติกที่เป็นข้อมูลดิบสำหรับโมเดลที่แย่มากซึ่งไม่สามารถแยกคลาสเชิงลบออกจากคลาสเชิงบวกได้เลย
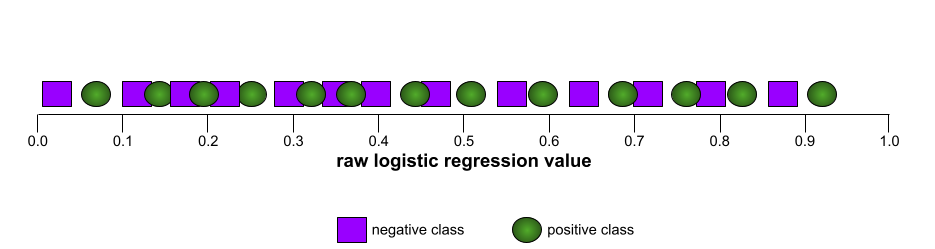
เส้นโค้ง ROC สำหรับโมเดลนี้มีลักษณะดังนี้
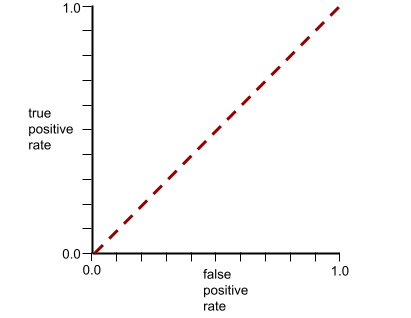
ในขณะเดียวกัน ในโลกแห่งความเป็นจริง โมเดลการจัดประเภทแบบไบนารีส่วนใหญ่จะแยกคลาสบวกและเชิงลบในระดับหนึ่ง แต่ก็มักจะไม่ได้สมบูรณ์แบบ ดังนั้น เส้นโค้ง ROC โดยทั่วไปจะอยู่ระหว่างด้านสุดโต่ง 2 ด้าน ดังนี้
ตามหลักแล้ว จุดบนเส้นโค้ง ROC ที่ใกล้เคียงที่สุด (0.0,1.0) จะระบุเกณฑ์การจัดประเภทที่เหมาะสม อย่างไรก็ตาม ปัญหาอื่นๆ มากมายในโลกนี้ มีอิทธิพลต่อการเลือกเกณฑ์การจัดประเภทที่เหมาะสม เช่น ผลลบลวง อาจทำให้รู้สึกเจ็บปวดมากกว่าผลบวกลวง
เมตริกตัวเลขที่ชื่อ AUC จะสรุปเส้นโค้ง ROC เป็นค่าจุดลอยตัวค่าเดียว
ค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง (RMSE)
รากที่สองของ ค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง
S
ฟังก์ชันซิกมอยด์
ฟังก์ชันทางคณิตศาสตร์ที่ "บีบ" ค่าอินพุตให้อยู่ในช่วงที่มีการจำกัด ซึ่งโดยทั่วไปคือ 0 ถึง 1 หรือ -1 ถึง +1 นั่นคือ คุณสามารถส่งจำนวนใดก็ได้ (2,1,000,000,000,000 หรืออะไรก็ได้) ไปยัง sigmoid และเอาต์พุตจะยังคงอยู่ในช่วงที่จำกัด พล็อตของฟังก์ชันการเปิดใช้งานซิกมอยด์มีลักษณะดังต่อไปนี้
ฟังก์ชัน Sigmoid มีประโยชน์หลายอย่างในแมชชีนเลิร์นนิง ซึ่งรวมถึง
- การแปลงเอาต์พุตข้อมูลดิบของโมเดลการถดถอยแบบโลจิสติกหรือโมเดลการถดถอยพหุนามเป็นความน่าจะเป็น
- ทำหน้าที่เป็นฟังก์ชันเปิดใช้งานในโครงข่ายระบบประสาทเทียมบางเครือข่าย
Softmax
ฟังก์ชันที่กำหนดความน่าจะเป็นสำหรับคลาสที่เป็นไปได้แต่ละคลาสในโมเดลการจัดประเภทแบบหลายคลาส ความน่าจะเป็นรวมกัน เป็น 1.0 พอดี ตัวอย่างเช่น ตารางต่อไปนี้แสดงให้เห็นว่า Softmax กระจายความน่าจะเป็นต่างๆ อย่างไร
| รูปภาพคือ... | ความน่าจะเป็น |
|---|---|
| สุนัข | .85 |
| cat | .13 |
| ม้า | 0.02 |
Softmax เรียกอีกอย่างว่า Full softmax
ตรงข้ามกับการนำข้อความตัวอย่างไปใช้
ฟีเจอร์แบบกระจัดกระจาย
ฟีเจอร์ที่มีค่าเป็น 0 หรือว่างเปล่าเป็นหลัก เช่น ฟีเจอร์ที่มีค่า 1 ค่าเดียวแต่มีค่าเป็น 0 ล้านค่าจะมีจำนวนน้อย แต่ในทางตรงกันข้าม ฟีเจอร์แบบหนาแน่นจะมีค่าที่โดยส่วนใหญ่แล้วไม่เท่ากับ 0 หรือว่างเปล่า
ในแมชชีนเลิร์นนิง จำนวนฟีเจอร์ที่ไม่น่าประหลาดใจคือฟีเจอร์ที่มีน้อย ฟีเจอร์ตามหมวดหมู่มักเป็นฟีเจอร์ที่มีน้อย เช่น จากต้นไม้ 300 ชนิดที่เป็นไปได้ในป่า ตัวอย่างหนึ่งอาจระบุเพียงต้นเมเปิลก็ได้ หรือวิดีโอที่เป็นไปได้นับล้านในคลังวิดีโอ ตัวอย่างเดียวอาจหมายถึง "คาซาบลังกา"
ในโมเดล โดยปกติแล้วคุณจะแสดงฟีเจอร์แบบเบาบางโดยใช้การเข้ารหัสแบบ One-Hot หากการเข้ารหัสแบบคลิกเดียวมีขนาดใหญ่ คุณอาจวางเลเยอร์การฝังไว้ที่ด้านบนของการเข้ารหัสแบบ One-Hot เพื่อเพิ่มประสิทธิภาพ
การเป็นตัวแทนบางส่วน
การจัดเก็บเฉพาะตำแหน่งขององค์ประกอบที่ไม่ใช่ 0 ในฟีเจอร์แบบกระจัดกระจาย
ตัวอย่างเช่น สมมติว่าฟีเจอร์เชิงหมวดหมู่ชื่อ species ระบุพันธุ์ไม้ 36 ชนิดในป่าแห่งใดแห่งหนึ่ง สมมติต่อไปว่าตัวอย่างแต่ละรายการระบุสายพันธุ์เพียงสายพันธุ์เดียว
คุณสามารถใช้เวกเตอร์หนึ่งที่น่าสนใจเพื่อแสดงถึงสปีชีส์ของต้นไม้ในแต่ละตัวอย่าง
เวกเตอร์ 1 รายการจะมี 1 เดี่ยว (เพื่อแทนต้นไม้สายพันธุ์ที่เฉพาะเจาะจงในตัวอย่างนั้น) และ 35 0 (เพื่อแสดงถึงประเภทต้นไม้ 35 ชนิดที่ไม่ใช่ในตัวอย่างนั้น) ดังนั้น การแสดงค่าเดี่ยวของ maple อาจมีลักษณะดังนี้

หรือการแสดงข้อมูลแบบกระจัดกระจายอาจเพียงแค่ระบุตำแหน่งของสิ่งมีชีวิตชนิดใดชนิดหนึ่ง หาก maple อยู่ที่ตำแหน่ง 24 การแสดงที่เบาบางของ maple จะเป็นเพียง
24
โปรดสังเกตว่าการแสดงแบบกระทัดรัดจะกะทัดรัดมากกว่าการนำเสนอแบบแสดงครั้งเดียวมาก
คลิกไอคอนสำหรับตัวอย่างที่ซับซ้อนขึ้นเล็กน้อย
สมมติว่าแต่ละตัวอย่างในรูปแบบของคุณต้องแสดงแทนคำในประโยคภาษาอังกฤษ ไม่ใช่ลำดับของคำเหล่านั้น ภาษาอังกฤษประกอบด้วยคำประมาณ 170,000 คำ ดังนั้นภาษาอังกฤษจึงเป็นฟีเจอร์เชิงหมวดหมู่ที่มีองค์ประกอบประมาณ 170,000 องค์ประกอบ ประโยคภาษาอังกฤษส่วนใหญ่ใช้เพียงเศษส่วนน้อยมากจาก 170,000 คำนั้น ดังนั้นชุดของคำในตัวอย่างเดียวจึงแทบจะเป็นข้อมูลที่กระจัดกระจายไปเลย
ลองพิจารณาประโยคต่อไปนี้
My dog is a great dog
คุณสามารถใช้รูปแบบของเวกเตอร์ที่นิยมครั้งเดียวเพื่อแสดงคำในประโยคนี้ได้ ในตัวแปรนี้ หลายเซลล์ในเวกเตอร์อาจมีค่าที่ไม่ใช่ 0 นอกจากนี้ ในตัวแปรนี้ เซลล์อาจมีจำนวนเต็มมากกว่าหนึ่งรายการ แม้ว่าคำว่า "ของฉัน", "คือ", "a" และ "ดีเลิศ" จะปรากฏเพียงหนึ่งครั้งในประโยคนี้ แต่คำว่า "สุนัข" จะปรากฏ 2 ครั้ง การใช้ตัวแปรของเวกเตอร์ที่นิยมหนึ่งครั้งนี้เพื่อแทนคำในประโยคนี้จะได้เวกเตอร์องค์ประกอบ 170,000 องค์ประกอบดังต่อไปนี้

บางส่วนของประโยคเดียวกันที่แสดงเพียงสั้นๆ
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
เวกเตอร์กระจัดกระจาย
เวกเตอร์ที่ค่าส่วนใหญ่เป็น 0 โปรดดูฟีเจอร์แบบย่อและความตรงกันของข้อมูลด้วย
ความสูญเสียยกกำลังสอง
คำพ้องความหมายของ L2 Los
คงที่
เป็นการดำเนินการที่ทำเพียงครั้งเดียว แทนที่จะเป็นอย่างต่อเนื่อง คำว่าคงที่และออฟไลน์เป็นคำพ้องความหมาย การใช้งานแบบคงที่และออฟไลน์โดยทั่วไปในแมชชีนเลิร์นนิงมีดังนี้
- โมเดลแบบคงที่ (หรือโมเดลออฟไลน์) เป็นโมเดลที่ได้รับการฝึกเพียงครั้งเดียวแล้วใช้ไประยะหนึ่ง
- การฝึกแบบคงที่ (หรือการฝึกออฟไลน์) คือกระบวนการฝึกโมเดลแบบคงที่
- การอนุมานแบบคงที่ (หรือการอนุมานแบบออฟไลน์) คือขั้นตอนที่โมเดลสร้างการคาดการณ์แบบกลุ่มขึ้นมาทีละชุด
คอนทราสต์แบบไดนามิก
การอนุมานแบบคงที่
คำพ้องความหมายของการอนุมานแบบออฟไลน์
สถานีเพลง
ฟีเจอร์ที่มีค่าไม่เปลี่ยนแปลงในมิติข้อมูลอย่างน้อย 1 รายการ ซึ่งมักจะเป็นเวลา ตัวอย่างเช่น คุณลักษณะที่มีค่าพอๆ กันในปี 2021 และ 2023 จะแสดงภาพนิ่ง
ในโลกแห่งความเป็นจริง มีน้อยมากที่จะจัดนิทรรศการภาพนิ่งต่างๆ แม้แต่คุณลักษณะที่ไม่มีความหมายเหมือนกันกับความเสถียร (เช่น ระดับน้ำทะเล) ก็มีการเปลี่ยนแปลงเมื่อเวลาผ่านไป
คอนทราสต์กับความไม่คงที่
การไล่ระดับสีแบบสตอคฮัสติก (SGD)
อัลกอริทึมการลดระดับลงของการไล่ระดับสีซึ่งมีขนาดกลุ่มเท่ากับ กล่าวคือ SGD ฝึกกับตัวอย่างเดียวที่ได้รับเลือกอย่างเท่าเทียมกันจากชุดการฝึก
แมชชีนเลิร์นนิงที่มีการควบคุมดูแล
การฝึกmodelจากmodelและmodelที่เกี่ยวข้อง แมชชีนเลิร์นนิงที่มีการควบคุมดูแลเทียบเคียงกันได้ กับการเรียนรู้เรื่องใดเรื่องหนึ่งโดยการศึกษาชุดคำถามและคำตอบที่ตรงกัน หลังจากจับคู่คำถามและคำตอบอย่างเชี่ยวชาญแล้ว นักเรียนจะสามารถตอบคำถามใหม่ๆ (ไม่เคยเห็นมาก่อน) ในหัวข้อเดียวกันได้
เปรียบเทียบกับแมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแล
ฟีเจอร์สังเคราะห์
ฟีเจอร์ที่ไม่ปรากฏในฟีเจอร์อินพุต แต่ประกอบขึ้นจากฟีเจอร์อย่างน้อย 1 รายการ วิธีสร้างฟีเจอร์สังเคราะห์มีดังนี้
- การเก็บข้อมูลฟีเจอร์แบบต่อเนื่องไว้ในกลุ่มช่วง
- การสร้างกากบาทฟีเจอร์
- การคูณ (หรือหาร) ค่าสถานที่หนึ่งด้วยค่าอื่นๆ ของจุดสนใจหรือค่าเดียว ตัวอย่างเช่น หาก
aและbเป็นฟีเจอร์อินพุต ต่อไปนี้จะเป็นตัวอย่างของฟีเจอร์สังเคราะห์- ab
- a2
- การใช้ฟังก์ชันเชิงซ้อนกับค่าฟีเจอร์ ตัวอย่างเช่น หาก
cเป็นฟีเจอร์อินพุต ตัวอย่างของฟีเจอร์สังเคราะห์มีดังนี้- sin(c)
- ln(c)
ฟีเจอร์ที่สร้างโดยการปรับให้สอดคล้องตามมาตรฐานหรือการปรับขนาดเพียงอย่างเดียวไม่ถือว่าเป็นฟีเจอร์สังเคราะห์
T
ทดสอบการสูญหาย
เมตริกที่แสดงถึงความสูญเสียของโมเดลเมื่อเทียบกับชุดทดสอบ เมื่อสร้างmodel คุณมักพยายามลดการสูญเสียการทดสอบ นั่นเป็นเพราะว่าการสูญเสียการทดสอบต่ำจะเป็นสัญญาณที่มีคุณภาพดีกว่าการสูญเสียการฝึกต่ำ หรือการสูญเสียการตรวจสอบต่ำ
บางครั้งความแตกต่างอย่างมากระหว่างการสูญเสียการทดสอบกับการสูญเสียการฝึกหรือการตรวจสอบความถูกต้องอาจทำให้คุณต้องเพิ่มอัตราการทำให้เป็นมาตรฐาน
การฝึก
ขั้นตอนการกำหนดพารามิเตอร์ที่เหมาะสม (น้ำหนักและอคติ) ซึ่งประกอบด้วยโมเดล ในระหว่างการฝึก ระบบจะอ่านตัวอย่างและค่อยๆ ปรับพารามิเตอร์ การฝึกจะใช้ตัวอย่างแต่ละรายการตั้งแต่ 2-3 ครั้งไปจนถึงหลายพันล้านครั้ง
การสูญเสียจากการฝึก
เมตริกที่แสดงถึงการสูญเสียของโมเดลระหว่างการฝึกซ้ำๆ ตัวอย่างเช่น สมมติว่าฟังก์ชันการสูญเสียเป็น Mean Squared Error บางทีการสูญเสียการฝึก (ข้อผิดพลาด Squared เฉลี่ย) สำหรับการทำซ้ำครั้งที่ 10 อาจเป็น 2.2 และการสูญเสียการฝึกสำหรับการทำซ้ำครั้งที่ 100 คือ 1.9
เส้นโค้งการสูญเสียแสดงการสูญเสียการฝึกเทียบกับจำนวนการทำซ้ำ เส้นโค้งการสูญเสียให้คำใบ้เกี่ยวกับการฝึกดังต่อไปนี้
- ความลาดลงด้านล่างหมายความว่าโมเดลมีการปรับปรุง
- ความลาดชันขึ้นหมายความว่าโมเดลกำลังแย่ลง
- ความลาดชันแบบแบนราบหมายความว่าโมเดลมาถึงการสนทนาแล้ว
ตัวอย่างเช่น เส้นโค้งการสูญเสียซึ่งค่อนข้างสมบูรณ์ในอุดมคติต่อไปนี้
- กราฟที่ลาดชันลงระหว่างการทำซ้ำครั้งแรก ซึ่งแสดงถึงการปรับปรุงโมเดลอย่างรวดเร็ว
- ทางลาดที่ค่อยๆ ราบเรียบ (แต่ยังคงเป็นขาลง) จนกระทั่งใกล้สิ้นสุดการฝึก ซึ่งบ่งบอกว่ามีการปรับปรุงโมเดลอย่างต่อเนื่องด้วยความเร็วที่ค่อนข้างช้ากว่าในระหว่างการทำซ้ำครั้งแรก
- ทางลาดที่ราบเรียบไปจนถึงช่วงท้ายของการฝึก ซึ่งแสดงถึงการบรรจบกัน
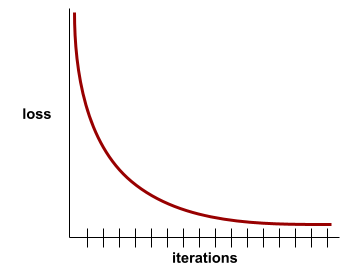
แม้ว่าการสูญเสียการฝึกอบรมจะมีความสำคัญ โปรดดูการทำให้เป็นแบบทั่วไปด้วย
ความคลาดเคลื่อนระหว่างการฝึกและการให้บริการ
ความแตกต่างระหว่างประสิทธิภาพของโมเดลในระหว่างการฝึกกับประสิทธิภาพของโมเดลเดียวกันในระหว่างการแสดงผล
ชุดการฝึก
ชุดย่อยของชุดข้อมูลที่ใช้เพื่อฝึกโมเดล
เดิมที ตัวอย่างในชุดข้อมูลจะแบ่งออกเป็น 3 ชุดย่อยที่แตกต่างกันดังนี้
- ชุดการฝึก
- ชุดการตรวจสอบ
- ชุดการทดสอบ
ตามหลักการแล้ว ตัวอย่างแต่ละรายการในชุดข้อมูลควรเป็นของชุดย่อยที่อยู่ก่อนหน้าเพียงชุดเดียวเท่านั้น เช่น ตัวอย่างเดียวไม่ควรอยู่ในทั้งชุดการฝึกและชุดการตรวจสอบ
ผลลบจริง (TN)
ตัวอย่างที่โมเดลคาดการณ์คลาสเชิงลบได้อย่างถูกต้อง ตัวอย่างเช่น โมเดลจะอนุมานได้ว่าข้อความอีเมลหนึ่งๆ ไม่ใช่สแปม และข้อความอีเมลนั้นไม่ใช่สแปมจริงๆ
ผลบวกจริง (TP)
ตัวอย่างที่โมเดลคาดการณ์คลาสเชิงบวกได้อย่างถูกต้อง ตัวอย่างเช่น โมเดลอนุมานได้ว่าข้อความอีเมลหนึ่งๆ เป็นสแปม และข้อความอีเมลนั้นเป็นสแปมจริงๆ
อัตราผลบวกจริง (TPR)
คำพ้องความหมายของ recall โดยการ
อัตราผลบวกจริงคือแกน Y ในเส้นโค้ง ROC
U
การใส่ชุดชั้นใน
สร้างmodelที่มีความสามารถในการคาดการณ์ต่ำเนื่องจากโมเดลไม่ได้บันทึกความซับซ้อนของข้อมูลการฝึกอย่างสมบูรณ์ หลายๆ ปัญหา ที่อาจทำให้เกิดความไม่สมควรนี้ ได้แก่
- การฝึกใช้ฟีเจอร์ผิดชุด
- การฝึกสำหรับ Epoch น้อยเกินไปหรือมีอัตราการเรียนรู้ต่ำเกินไป
- การฝึกที่มีอัตราการจัดเป็นมาตรฐานสูงเกินไป
- การมีเลเยอร์ที่ซ่อนอยู่น้อยเกินไปในโครงข่ายประสาทแบบลึก
ตัวอย่างที่ไม่มีป้ายกำกับ
ตัวอย่างที่มีฟีเจอร์ แต่ไม่มีป้ายกำกับ ตัวอย่างเช่น ตารางต่อไปนี้แสดงตัวอย่าง 3 ตัวอย่างที่ไม่มีป้ายกำกับจากรูปแบบการประเมินมูลค่าบ้าน โดยแต่ละรายการมีฟีเจอร์ 3 รายการแต่ไม่มีมูลค่าบ้าน
| จำนวนห้องนอน | จำนวนห้องน้ำ | อายุบ้าน |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
ในแมชชีนเลิร์นนิงที่มีการควบคุมดูแล โมเดลจะฝึกตามตัวอย่างที่มีป้ายกำกับและคาดการณ์ตัวอย่างที่ไม่มีป้ายกำกับ
ในการเรียนรู้แบบมีการควบคุมดูแลและไม่มีการควบคุมดูแล จะมีการใช้ตัวอย่างที่ไม่มีป้ายกำกับในระหว่างการฝึก
ตัวอย่างคอนทราสต์ที่ไม่มีป้ายกำกับกับตัวอย่างที่ติดป้ายกำกับ
แมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแล
การฝึกmodelเพื่อค้นหารูปแบบในชุดข้อมูล ซึ่งโดยปกติแล้วจะเป็นชุดข้อมูลที่ไม่มีป้ายกำกับ
การใช้แมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแลที่พบมากที่สุดคือการจัดกลุ่มข้อมูลเป็นกลุ่มตัวอย่างที่คล้ายกัน เช่น อัลกอริทึมแมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแลสามารถจัดกลุ่มเพลงตามคุณสมบัติต่างๆ ของเพลง คลัสเตอร์ที่ได้อาจกลายเป็นอินพุตของอัลกอริทึมแมชชีนเลิร์นนิงอื่นๆ (เช่น บริการแนะนำเพลง) การจัดกลุ่มมีประโยชน์หากไม่มีหรือขาดป้ายกำกับที่เป็นประโยชน์ ตัวอย่างเช่น ในโดเมนต่างๆ อย่างการป้องกันการละเมิดและการประพฤติมิชอบ คลัสเตอร์จะช่วยให้ผู้ใช้เข้าใจข้อมูลได้ดีขึ้น
ตรงข้ามกับแมชชีนเลิร์นนิงที่มีการควบคุมดูแล
V
การตรวจสอบความถูกต้อง
การประเมินคุณภาพของโมเดลเบื้องต้น การตรวจสอบความถูกต้องจะตรวจสอบคุณภาพของการคาดการณ์ของโมเดลโดยเทียบกับชุดการตรวจสอบ
เนื่องจากชุดการตรวจสอบจะแตกต่างจากชุดการฝึก การตรวจสอบจึงช่วยป้องกันการซ้อนทับ
คุณอาจลองประเมินโมเดลเทียบกับชุดการตรวจสอบในฐานะการทดสอบรอบแรก และประเมินโมเดลเทียบกับชุดทดสอบซึ่งเป็นการทดสอบรอบที่ 2
การสูญเสียการตรวจสอบ
เมตริกที่แสดงถึงการสูญเสียของโมเดลในชุดการตรวจสอบในระหว่างการทำซ้ำการฝึกที่เฉพาะเจาะจง
ดูเส้นโค้งภาพรวมด้วย
ชุดการตรวจสอบ
ชุดย่อยของชุดข้อมูลที่ทำการประเมินเบื้องต้นกับโมเดลที่ผ่านการฝึกแล้ว โดยปกติแล้ว คุณจะประเมินโมเดลที่ฝึกกับชุดการตรวจสอบหลายครั้งก่อนที่จะประเมินโมเดลกับชุดการทดสอบ
เดิมที คุณจะแบ่งตัวอย่างในชุดข้อมูลออกเป็น 3 ชุดย่อยที่แตกต่างกันดังนี้
- ชุดการฝึก
- ชุดการตรวจสอบ
- ชุดการทดสอบ
ตามหลักการแล้ว ตัวอย่างแต่ละรายการในชุดข้อมูลควรเป็นของชุดย่อยที่อยู่ก่อนหน้าเพียงชุดเดียวเท่านั้น เช่น ตัวอย่างเดียวไม่ควรอยู่ในทั้งชุดการฝึกและชุดการตรวจสอบ
W
น้ำหนัก
ค่าที่โมเดลคูณด้วยค่าอื่น การฝึกเป็นกระบวนการกำหนดน้ำหนักที่เหมาะสมของโมเดล การอนุมานเป็นกระบวนการของการใช้น้ำหนักที่เรียนรู้มานี้ในการคาดการณ์
ผลรวมถ่วงน้ำหนัก
ผลรวมของค่าที่ป้อนที่เกี่ยวข้องทั้งหมดคูณด้วยน้ำหนักที่สัมพันธ์กัน ตัวอย่างเช่น สมมติว่าอินพุตที่เกี่ยวข้องประกอบด้วยข้อมูลต่อไปนี้
| ค่าอินพุต | น้ำหนักอินพุต |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
ดังนั้น ผลรวมถ่วงน้ำหนักจะเป็นดังนี้
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
ผลรวมถ่วงน้ำหนักคืออาร์กิวเมนต์อินพุตของฟังก์ชันการเปิดใช้งาน
Z
การปรับค่ามาตรฐาน Z
เทคนิคการปรับขนาดที่แทนที่ค่า feature ดิบด้วยค่าจุดลอยตัวซึ่งแสดงจำนวนค่าเบี่ยงเบนมาตรฐานจากค่าเฉลี่ยของจุดสนใจนั้น ตัวอย่างเช่น ลองพิจารณาสถานที่ที่มีค่าเฉลี่ยคือ 800 และมีค่าเบี่ยงเบนมาตรฐานคือ 100 ตารางต่อไปนี้แสดงวิธีที่การปรับมาตรฐานคะแนน Z จับคู่ค่าดิบกับค่ามาตรฐาน Z
| ค่าดิบ | คะแนน Z |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
จากนั้นโมเดลแมชชีนเลิร์นนิงจะฝึกตามค่าคะแนน Z สำหรับฟีเจอร์นั้นแทนค่าดิบ