Viele Probleme erfordern eine Wahrscheinlichkeitsschätzung als Ausgabe. Die logistische Regression ist ein äußerst effizienter Mechanismus zum Berechnen von Wahrscheinlichkeiten. Praktisch ausgedrückt können Sie die zurückgegebene Wahrscheinlichkeit auf eine der folgenden zwei Arten verwenden:
- So wie"
- In eine Binärkategorie umgewandelt.
Überlegen wir, wie wir die Wahrscheinlichkeit verwenden können, wie sie ist. Angenommen, wir erstellen ein logistisches Regressionsmodell, um die Wahrscheinlichkeit vorherzusagen, dass ein Hund mitten in der Nacht bellt. Dies wird als Wahrscheinlichkeit bezeichnet:
\[p(bark | night)\]
Wenn das logistische Regressionsmodell \(p(bark | night) = 0.05\)vorhersagt, sollten die Inhaber des Hundes nach über einem Jahr etwa 18 Mal wach werden:
\[\begin{align} startled &= p(bark | night) \cdot nights \\ &= 0.05 \cdot 365 \\ &~= 18 \end{align} \]
In vielen Fällen ordnen Sie die Ausgabe der logistischen Regression der Lösung einem binären Klassifizierungsproblem zu, bei dem das Ziel darin besteht, eines von zwei möglichen Labels vorherzusagen (z.B. &spam;oder"kein Spam"). Ein späteres Modul konzentriert sich darauf.
Sie fragen sich vielleicht, wie ein logistisches Regressionsmodell dafür sorgen kann, dass die Ausgabe immer zwischen 0 und 1 liegt. Währenddessen erzeugt eine Sigmoidfunktion, die so definiert ist, eine Ausgabe mit denselben Eigenschaften:
Die Sigmoidfunktion liefert folgende Darstellung:
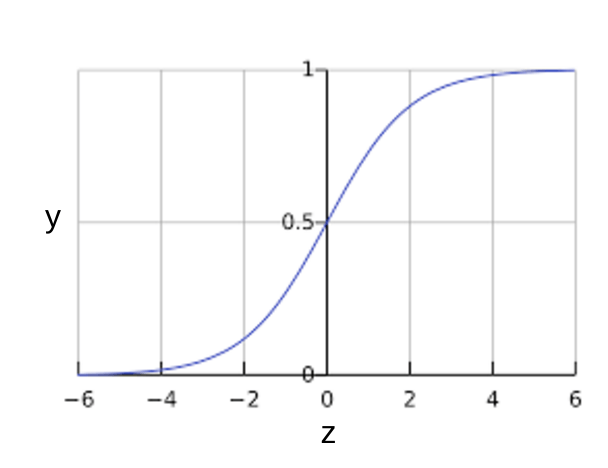
Abbildung 1: Sigmoidfunktion
Wenn \(z\) die Ausgabe der linearen Ebene eines Modells darstellt, das mit logistischer Regression trainiert wurde, \(sigmoid(z)\) ergibt einen Wert (eine Wahrscheinlichkeit) zwischen 0 und 1. In mathematischer Hinsicht:
wobei
- \(y'\) ist die Ausgabe des logistischen Regressionsmodells für ein bestimmtes Beispiel.
- \(z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\)
- Die \(w\) Werte sind die erlernten Gewichtungen des Modells und \(b\) die Verzerrungen.
- Die \(x\) -Werte sind die Featurewerte für ein bestimmtes Beispiel.
Beachten Sie, dass \(z\) auch als log-ods bezeichnet wird, da der Kehrwert der Sigmoidwerte \(z\) als Log der Wahrscheinlichkeit des Labels \(1\) definiert werden können (z.B. "Hundrinden") geteilt durch die Wahrscheinlichkeit des \(0\) Labels (z.B. &Hund bellt:
Hier sehen Sie die Sigmoidfunktion mit ML-Labels:

Abbildung 2: Ausgabe der logistischen Regression.
Klicken Sie auf das Pluszeichen, um ein Beispiel für eine Berechnung der logistischen Regression zu sehen.
Angenommen, wir haben ein logistisches Regressionsmodell mit drei Features, die die folgenden Verzerrungen und Gewichtungen gelernt haben:
$$\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} $$Nehmen wir weiter die folgenden Featurewerte für ein bestimmtes Beispiel an:
$$\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} $$Daher tritt im Protokoll auf folgende Weise auf:
ist:
$$(1) + (2)(0) + (-1)(10) + (5)(2) = 1$$Daher liegt die logistische Regressionsvorhersage für dieses Beispiel bei 0, 731:

Abbildung 3: Wahrscheinlichkeit von 73,1%