Introduzione alle funzionalità Crosses
Una funzionalità può davvero consentire a un modello di adattarsi ai dati non lineari? Per scoprirlo, prova questo esercizio.
Attività: prova a creare un modello che separa i punti blu da quelli arancioni manualmente modificando i valori delle seguenti tre funzionalità di input:
- x1
- 2
- x1 x2 (croce)
Per modificare manualmente una ponderazione:
- Fai clic su una linea che collega le funzionalità a OUTPUT. Verrà visualizzato un modulo.
- Digita un valore in virgola mobile nel modulo di immissione.
- Premi Invio.
Tieni presente che l'interfaccia di questo esercizio non contiene un pulsante Step. Questo succede perché questo esercizio non addestrerà ripetutamente un modello. Dovrai invece inserire manualmente le ponderazioni "&final" per il modello.
(Le risposte vengono visualizzate appena sotto l'esercizio.)
Incroci di funzionalità più complesse
Ora vediamo alcune combinazioni avanzate di funzionalità. I dati impostati in questo esercizio di Playground sono un po' rumorosi: un gioco di freccette, con i punti blu al centro e i punti arancioni in un anello esterno.
Fai clic sull'icona Più per una spiegazione della visualizzazione del modello.
Per ogni esercizio Playground viene mostrata una visualizzazione dello stato attuale del modello. Ad esempio, ecco una visualizzazione:
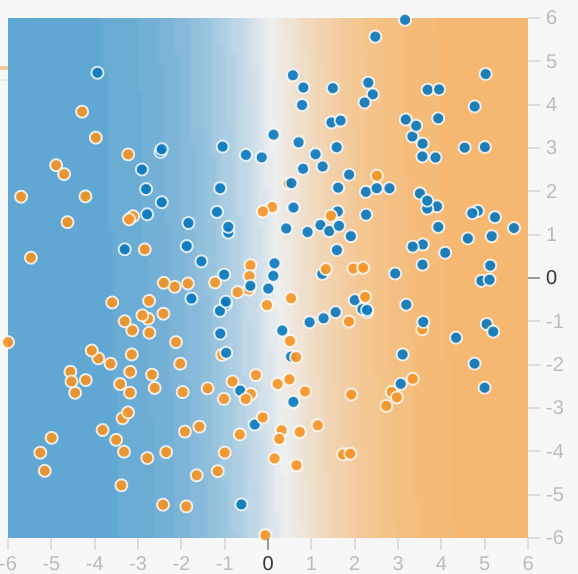
Tieni presente quanto segue in merito alla visualizzazione del modello:
- Ogni asse rappresenta una caratteristica specifica. Nel caso di spam e non di spam, le funzionalità potrebbero essere il numero di parole e il numero di destinatari dell'email.
- Ogni punto traccia i valori delle caratteristiche per un esempio di dati, ad esempio un'email.
- Il colore del punto rappresenta la classe a cui appartiene l'esempio. Ad esempio, i punti blu possono rappresentare le email non di spam, mentre i punti arancioni possono rappresentare le email di spam.
- Il colore di sfondo rappresenta la previsione del modello dei punti in cui devono essere trovati esempi di quel colore. Uno sfondo blu intorno a un punto blu indica che il modello prevede correttamente quell'esempio. Al contrario, uno sfondo arancione attorno a un punto blu indica che il modello prevede in modo errato l'esempio.
- Lo sfondo blu e arancione viene ridimensionato. Ad esempio, il lato sinistro della visualizzazione è blu fissa, ma sfuma gradualmente al bianco al centro. L'intensità del colore può indicare la sicurezza del modello nella sua ipotesi. Il colore blu fisso indica che il modello è molto sicuro della sua ipotesi, mentre il colore azzurro indica che il modello è meno sicuro. (la visualizzazione del modello mostrata nella figura sta eseguendo un lavoro di previsione scadente).
Utilizza la visualizzazione per valutare i progressi del modello. ("Eccellente: la maggior parte dei punti blu ha uno sfondo blu" o "Oh no! I puntini blu hanno uno sfondo arancione." Oltre ai colori, Playground mostra numericamente anche la perdita attuale del modello. ("Oh no! La perdita sta salendo invece di scendere."
Attività 1: esegui questo modello lineare come indicato. Dedica un minuto o due (ma non più a lungo) a provare diverse impostazioni del tasso di apprendimento per vedere se puoi migliorare. Un modello lineare può produrre risultati efficaci per questo set di dati?
Attività 2: prova ad aggiungere funzionalità cross-product, ad esempio x1 x 2, per ottimizzare il rendimento.
- Quali funzionalità sono più utili?
- Qual è il miglior rendimento che puoi ottenere?
Attività 3: quando hai un buon modello, esamina la superficie di output del modello (mostrata dal colore di sfondo).
- Assomiglia a un modello lineare?
- Come descriveresti il modello?
(Le risposte vengono visualizzate appena sotto l'esercizio.)