An embedding is a relatively low-dimensional space into which you can translate high-dimensional vectors. Embeddings make it easier to do machine learning on large inputs like sparse vectors representing words. Ideally, an embedding captures some of the semantics of the input by placing semantically similar inputs close together in the embedding space. An embedding can be learned and reused across models.
Embeddings
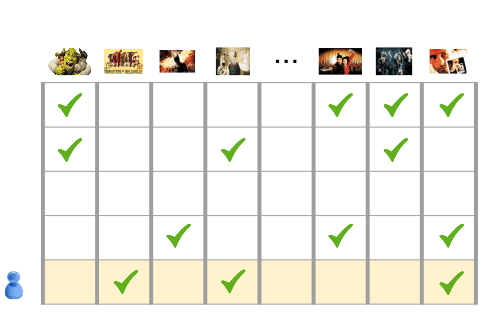
Motivation From Collaborative Filtering
- Input: 1,000,000 movies that 500,000 users have chosen to watch
- Task: Recommend movies to users
To solve this problem some method is needed to determine which movies are similar to each other.
Organizing Movies by Similarity (1d)

Organizing Movies by Similarity (2d)

Two-Dimensional Embedding

Two-Dimensional Embedding

d-Dimensional Embeddings
- Assumes user interest in movies can be roughly explained by d aspects
- Each movie becomes a d-dimensional point where the value in dimension d represents how much the movie fits that aspect
- Embeddings can be learned from data
Learning Embeddings in a Deep Network
- No separate training process needed -- the embedding layer is just a hidden layer with one unit per dimension
- Supervised information (e.g. users watched the same two movies) tailors the learned embeddings for the desired task
- Intuitively the hidden units discover how to organize the items in the d-dimensional space in a way to best optimize the final objective
Input Representation
- Each example (a row in this matrix) is a sparse vector of features (movies) that have been watched by the user
- Dense representation of this example as: (0, 1, 0, 1, 0, 0, 0, 1)
Is not efficient in terms of space and time.
Input Representation
- Build a dictionary mapping each feature to an integer from 0, ..., # movies - 1
- Efficiently represent the sparse vector as just the movies the user watched. This might be represented as:


An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Regression problem to predict home sales prices:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Multiclass Classification to predict a handwritten digit:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

An Embedding Layer in a Deep Network
Collaborative Filtering to predict movies to recommend:

Correspondence to Geometric View
Deep Network
- Each of hidden units corresponds to a dimension (latent feature)
- Edge weights between a movie and hidden layer are coordinate values

Geometric view of a single movie embedding

Selecting How Many Embeddings Dims
- Higher-dimensional embeddings can more accurately represent the relationships between input values
- But more dimensions increases the chance of overfitting and leads to slower training
- Empirical rule-of-thumb (a good starting point but should be tuned using the validation data): $$ dimensions \approx \sqrt[4]{possible\;values} $$
Embeddings as a Tool
- Embeddings map items (e.g. movies, text,...) to low-dimensional real vectors in a way that similar items are close to each other
- Embeddings can also be applied to dense data (e.g. audio) to create a meaningful similarity metric
- Jointly embedding diverse data types (e.g. text, images, audio, ...) define a similarity between them