Une représentation vectorielle continue est un espace de relativement faible dimension dans lequel vous pouvez traduire des vecteurs de grande dimension. Les représentations vectorielles continues facilitent le machine learning sur des entrées volumineuses, telles que des vecteurs creux représentant des mots. Idéalement, une représentation vectorielle continue capture une partie de la sémantique de l'entrée en rapprochant les entrées sémantiquement similaires les unes des autres dans l'espace de représentation vectorielle. Une représentation vectorielle continue peut être apprise et réutilisée sur plusieurs modèles.
Représentations vectorielles continues
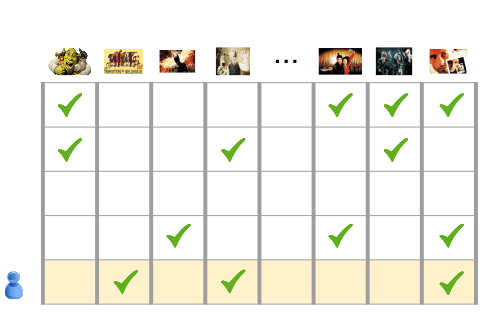
Motivation issue du filtrage collaboratif
- Entrée:1 000 000 de films que 500 000 utilisateurs ont choisi de regarder
- Tâche : recommander des films aux utilisateurs
Pour ce faire, nous avons besoin d'une méthode qui nous permette de déterminer les similitudes entre les films.
Organisation des films par similarité (1 j)

Organisation de films par similarité (2d)

Représentation vectorielle continue à deux dimensions

Représentation vectorielle continue à deux dimensions

Représentations vectorielles continues à d dimensions
- Partons du principe que l'intérêt des utilisateurs pour les films peut être globalement expliqué
- Chaque film devient un point à d dimensions, où la valeur de la dimension d représente l'adéquation de la vidéo.
- Les représentations vectorielles continues peuvent être apprises des données
Apprentissage des représentations vectorielles continues dans un réseau profond
- Aucun processus d'entraînement distinct n'est nécessaire : la couche de représentations vectorielles continues n'est qu'une couche cachée avec une unité par dimension.
- Les informations supervisées (par exemple, les utilisateurs ont regardé les deux mêmes films) adaptent les représentations vectorielles continues apprises pour la tâche souhaitée.
- Intuitivement, les unités cachées découvrent comment organiser les éléments dans l'espace à d dimensions afin d'optimiser au mieux l'objectif final.
Représentation de l'entrée
- Chaque exemple (une ligne de cette matrice) est un vecteur creux de caractéristiques (films) visionnées par l'utilisateur.
- Représentation dense de cet exemple comme suit : (0, 1, 0, 1, 0, 0, 0, 1)
N'est pas efficace en termes d'espace et de temps.
Représentation de l'entrée
- Créez un dictionnaire mappant chaque caractéristique à un entier compris entre 0, ..., # films - 1
- Représentez efficacement le vecteur creux pour décrire les films que l'utilisateur a regardés. Cela peut être représenté par :


Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Problème de régression pour prédire le prix d'une vente immobilière:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Classification à classes multiples pour prédire un chiffre manuscrit:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Une couche de représentations vectorielles continues dans un réseau profond
Filtrage collaboratif pour prédire les films à recommander:

Correspondance avec la vue géométrique
Réseau profond
- Chacune des unités masquées correspond à une dimension (caractéristique latente).
- Les pondérations des bords entre une vidéo et une couche cachée sont des valeurs de coordonnées

Vue géométrique d'une représentation vectorielle continue d'un film

Sélection du nombre de représentations vectorielles continues
- Les représentations vectorielles continues de plus grande dimension peuvent représenter plus précisément les relations entre les valeurs d'entrée
- Mais plus de dimensions augmentent les chances de surapprentissage et ralentissent l'entraînement
- Règle empirique (un bon point de départ, mais qui doit être ajusté à l'aide des données de validation): $$ dimensions \approx \sqrt[4]{possible\;values} $$
Les représentations vectorielles continues en tant qu'outil
- Les représentations vectorielles continues permettent de mapper des éléments (films, texte, etc.) sur des vecteurs réels de faible dimension, de sorte que les éléments similaires soient proches les uns des autres.
- Les représentations vectorielles continues peuvent également être appliquées à des données denses (par exemple, des contenus audio) pour créer une métrique de similarité pertinente
- L'intégration conjointe de divers types de données (par exemple, texte, images, audio, etc.) définit une similitude