クラスタリングは教師なしであるため、結果の検証に「トゥルース」は使用できません。事実が欠如していると品質の評価が複雑になります。また、実際のデータセットは通常、図 1 に示すようなデータセットのサンプルにはあたりません。
残念ながら、実際のデータは図 2 のような形式で表示されるため、クラスタリングの品質を視覚的に評価することは困難です。
以下のフローチャートは、クラスタリングの品質を確認する方法をまとめたものです。次のセクションでは、この概要について詳しく説明します。

ステップ 1: クラスタリングの品質
クラスタリングは「事実」に基づいていないため、クラスタリングの品質チェックは厳密なプロセスではありません。以下は、クラスタリングの品質を改善するために繰り返し適用できるガイドラインです。
まず、クラスタが期待どおりに表示され、類似していると思われるサンプルが同じクラスタに表示されることを確認します。その後、次のセクションで説明するように、一般的に使用される指標を確認します。
- クラスタのカーディナリティ
- クラスタの強度
- ダウンストリーム システムのパフォーマンス
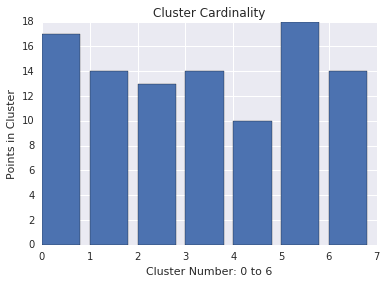
クラスタのカーディナリティ
クラスタのカーディナリティは、クラスタあたりのサンプル数です。すべてのクラスタのクラスタ カーディナリティをプロットし、主要な外れ値であるクラスタを調べます。たとえば、図 2 でクラスタ番号 5 を調査します。
クラスタの強度
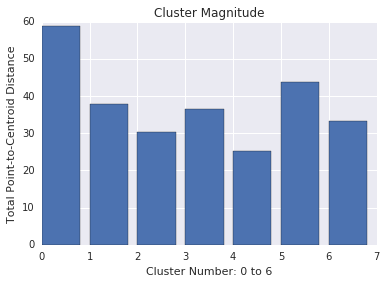
クラスタの強度は、すべてのサンプルからクラスタのセントロイドまでの距離の合計です。カーディナリティと同様に、クラスタ全体で強度がどのように変動するかを確認し、異常を調査します。たとえば、図 3 でクラスタ番号 0 を調査します。
マグニチュードとカーディナリティ
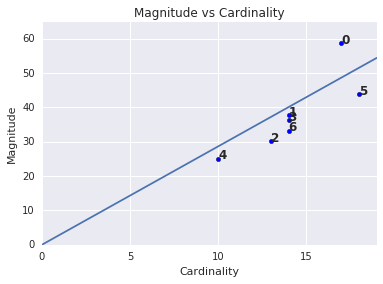
クラスタのカーディナリティが高いほど、クラスタの強度が高くなる傾向があり、直感的に理解できます。カーディナリティが他のクラスタと相対的でない場合、クラスタは異常です。カーディナリティに対して規模をプロットすることにより、異常なクラスタを見つけます。たとえば、図 4 では、クラスタ指標に 1 つの線を引くと、クラスタ番号 0 が異常であることを示しています。
ダウンストリーム システムのパフォーマンス
クラスタリング出力はダウンストリーム ML システムでよく使用されるため、クラスタリング プロセスの変更時にダウンストリーム システムのパフォーマンスが改善されるかどうかを確認してください。ダウンストリームのパフォーマンスへの影響は、クラスタリングの品質の実際のテストを提供します。デメリットは、このチェックの実行が複雑であることです。
問題が見つかった場合に調査する質問
問題が見つかった場合は、データの準備と類似性の尺度を確認して、次の質問を自分に問いかけます。
- データはスケーリングされますか?
- 類似性の測定結果は正しいですか?
- アルゴリズムはデータに対して意味的に有意な演算を行っていますか?
- アルゴリズムの前提条件はデータと一致していますか?
ステップ 2: 類似性メジャーのパフォーマンス
クラスタリング アルゴリズムは、類似度の測定と同程度の質です。類似度メジャーで実用的な結果が返されることを確認します。最も単純なチェックは、他のペアとほぼ類似している、または類似していないことが判明しているサンプルのペアを特定することです。次に、サンプルのペアごとに類似性の測定値を計算します。類似度の高いサンプルの類似度の測定値が、類似度の低いサンプルの類似度の測定値よりも高いことを確認します。
類似性メジャーをスポット チェックに使用する例は、データセットを代表するものである必要があります。すべての例で、類似性のメジャーが適用されることを確認します。慎重な検証により、手動または管理対象にかかわらず、類似性の測定値がデータセット全体で一貫するようにします。類似性の測定値が一部の例で一致しない場合、それらの例は類似例とクラスタ化されません。
類似度が低いサンプルが見つかった場合、類似性の測定では、それらのサンプルを区別する特徴データが取得されない可能性があります。類似度メジャーを試して、より正確な類似性が得られるかどうかを判断します。
ステップ 3: 最適なクラスタ数
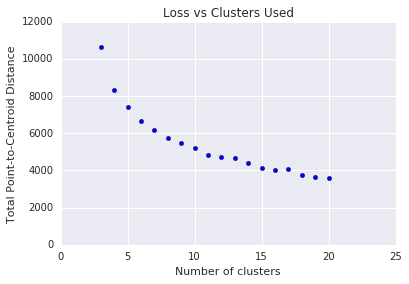
k 平均法では、クラスタの数を事前に決定する必要があります。 \(k\) \(k\)の最適な値はどのようにして決定されますか。アルゴリズムを実行し、 \(k\) の値を増やし、クラスタの強度の合計を確認します。 \(k\)が大きくなるとクラスタは小さくなり、合計距離は短くなります。この距離をクラスタ数に対してプロットします。
図 4 に示すように、特定の \(k\)で \(k\)が増加すると、損失の減少はわずかになります。数学的には、これは通常 \(k\)勾配が -1(\(\theta > 135^{\circ}\))を超える交差になります。このガイドラインでは、最適値に正確な値ではなく、 \(k\) 正確な値を正確に特定しています。示されているプロットでは、最適値は約 11 です。 \(k\) より詳細なクラスタが必要な場合は、このプロットをガイダンスとして \(k\) 高いクラスタを選択できます。