Poiché il clustering non è supervisionato, non è disponibile "attendibilità" per verificare i risultati. L'assenza di dati complica la valutazione della qualità. Inoltre, i set di dati reali in genere non rientrano in ovvi cluster di esempi, come il set di dati mostrato nella Figura 1.
Purtroppo, i dati del mondo reale sono più simili a quelli della Figura 2, il che rende difficile valutare visivamente la qualità del clustering.
Il diagramma di flusso riportata di seguito riassume come verificare la qualità del tuo clustering. Il riepilogo verrà ampliato nelle sezioni seguenti.

Passaggio 1: qualità del clustering
Il controllo della qualità del clustering non è un processo rigoroso perché il clustering è "privato". Ecco le linee guida che puoi applicare ripetutamente per migliorare la qualità del tuo clustering.
Prima di tutto, esegui un controllo visivo per vedere che i cluster abbiano l'aspetto previsto e che gli esempi che consideri simili appaiano nello stesso cluster. Poi controlla le metriche di uso comune descritte nelle sezioni seguenti:
- Cardinalità dei cluster
- Magnitudo cluster
- Prestazioni del sistema di downstream
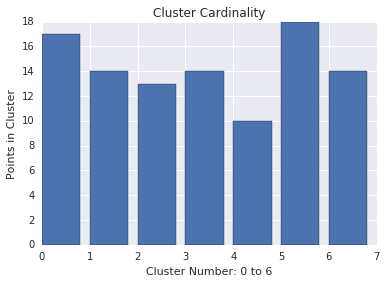
Cardinalità del cluster
La cardinalità del cluster è il numero di esempi per cluster. Traccia la cardinalità del cluster per tutti i cluster ed esaminare i cluster che sono importanti. Ad esempio, nella Figura 2, esaminare il cluster numero 5.
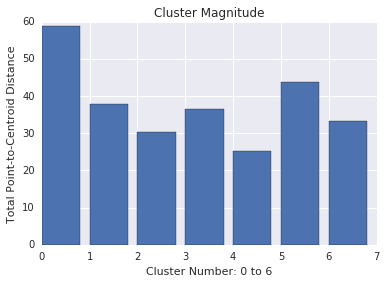
Magnitudo del cluster
L'entità del cluster è la somma delle distanze da tutti gli esempi al centroide del cluster. Come per la cardinalità, controlla la variazione della grandezza nei cluster e analizza le anomalie. Ad esempio, nella Figura 3, esaminare il numero di cluster 0.
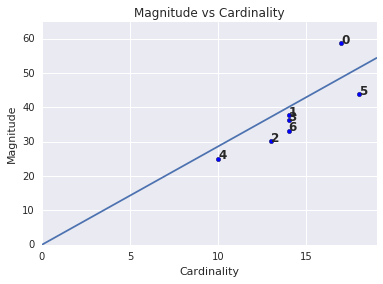
Magnitudo e cardinalità
Nota che una cardinalità del cluster più elevata tende a ottenere un cluster di dimensioni più grandi, il che ha senso in modo intuitivo. I cluster sono anomali quando la cardinalità non è correlata alla grandezza degli altri cluster. Trova cluster anomale tracciando la portata in base alla cardinalità. Ad esempio, nella figura 4, l'adattamento di una linea alle metriche del cluster mostra che il numero di cluster 0 è anomalo.
Prestazioni del sistema di downstream
Poiché l'output del clustering è spesso utilizzato nei sistemi di ML downstream, controlla se le prestazioni del sistema di downstream migliorano quando il processo di clustering cambia. L'impatto sulle tue prestazioni downstream fornisce un test reale sulla qualità del tuo clustering. Lo svantaggio è che questo controllo è complesso da eseguire.
Domande per verificare se vengono rilevati problemi
Se riscontri problemi, controlla la preparazione dei dati e la misura di somiglianza, ponendoti le seguenti domande:
- I tuoi dati vengono scalati?
- La misura di similitudine è corretta?
- Il tuo algoritmo esegue operazioni sui dati a livello semantico?
- Le ipotesi dell'algoritmo corrispondono ai dati?
Passaggio 2. Rendimento della misurazione di similitudine
L'algoritmo di clustering dipende dalla misurazione della somiglianza. Assicurati che la misura di similitudine restituisca risultati ragionevoli. Il controllo più semplice consiste nell'identificare coppie di esempi che sono note in modo più o meno simile ad altre coppie. Successivamente, calcola la misura di somiglianza per ogni coppia di esempi. Assicurati che la misura di similitudine per esempi più simili sia superiore a quella per gli esempi meno simili.
Gli esempi utilizzati per individuare la misura di similitudine devono essere rappresentativi del set di dati. Assicurati che la misura di similitudine sia valida per tutti gli esempi. Un'attenta verifica garantisce che la misurazione della somiglianza, manuale o supervisionato, sia coerente in tutto il set di dati. Se la tua misura di similitudine non è coerente per alcuni esempi, questi non verranno raggruppati con esempi simili.
Se trovi esempi con analogie imprecise, è probabile che la misura della similitudine non acquisisca i dati delle caratteristiche che li distinguono. Fai esperimenti con la tua misura di somiglianza e stabilisci se le somiglianze sono più precise.
Passaggio 3: numero ottimale di cluster
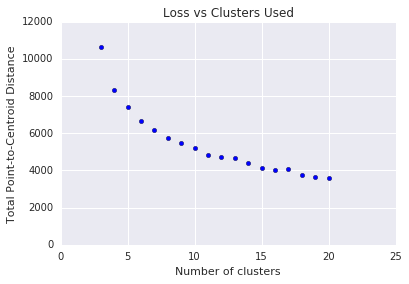
k-means richiede che tu decida il numero \(k\) di cluster in anticipo. Come puoi determinare il valore ottimale di \(k\)? Prova a eseguire l'algoritmo per aumentare \(k\) e notare la somma delle grandezze dei cluster. Man mano che \(k\) aumenta, i cluster diventano più piccoli e la distanza totale diminuisce. Confronta questa distanza con il numero di cluster.
Come mostrato nella Figura 4, con una certa \(k\), la riduzione della perdita diventa marginale con l'aumento di \(k\). In teoria, questo è approssimativamente \(k\)il punto in cui la pendenza supera -1 (\(\theta > 135^{\circ}\)). Questa linea guida non indica un valore esatto per l'ottimismo, \(k\) ma solo un valore approssimativo. Per il grafico mostrato, l'ottimizzazione \(k\) è pari a circa 11. Se preferisci cluster più granulari, puoi scegliere un \(k\) più alto utilizzando questo grafico come guida.