A maneira mais fácil de classificar é com a função sort(list), que usa uma lista e retorna uma nova lista com esses elementos em ordem de classificação. A lista original não é alterada.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
É mais comum passar uma lista para a função sort(), mas, na verdade, ela pode usar qualquer tipo de coleção iterável como entrada. O método list.sort() mais antigo é uma alternativa detalhada abaixo. A função Sort() parece mais fácil de usar em comparação com sort(), por isso recomendamos o uso de sort().
A função sort() pode ser personalizada com argumentos opcionais. O argumento opcional sort() invertido=True, por exemplo, Classificado(list, downgrade=True), faz com que a classificação seja inversa.
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
Classificação personalizada com key=
Para uma classificação personalizada mais complexa, sort() usa um "key=" opcional especificando uma "chave" que transforma cada elemento antes da comparação. A função principal recebe um valor e retorna um valor, e o "proxy" retornado value é usado para as comparações dentro da classificação.
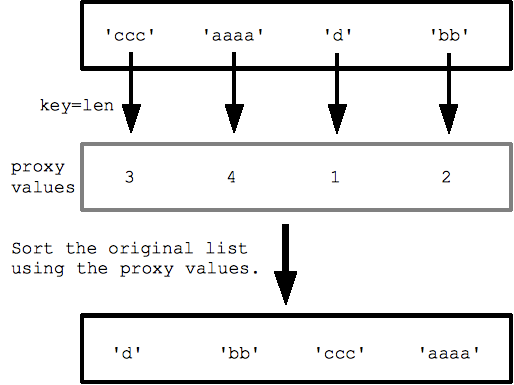
Por exemplo, com uma lista de strings, especificar key=len (a função len() integrada) classifica as strings por comprimento, da menor para a maior. A classificação chama len() para cada string para obter a lista de valores de comprimento de proxy e, em seguida, classifica com esses valores de proxy.
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
Como outro exemplo, especificar "str.lower" como a função-chave é uma forma de forçar a classificação a tratar maiúsculas e minúsculas da mesma forma:
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
Você também pode transmitir seu próprio MyFn como a função-chave, desta forma:
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
Para uma classificação mais complexa, como classificar por sobrenome e depois por nome, Você pode usar as funções itemgetter ou attrgetter como:
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
método sort()
Como alternativa para classificar(), o método sort() em uma lista classifica essa lista em ordem crescente, por exemplo, list.sort()). O método sort() muda a lista subjacente e retorna None, então use-o assim:
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
O que foi mencionado acima é um mal-entendido muito comum com sort(): ele *não retorna* a lista classificada. O método sort() deve ser chamado em uma lista; isso não funciona em nenhuma coleção enumerável (mas a função Sort() acima funciona em qualquer coisa). Como o método sort() antecede a função sort(), você provavelmente a verá em códigos mais antigos. O método sort() não precisa criar uma nova lista, então pode ser um pouco mais rápido caso os elementos a serem classificados já estejam em uma lista.
Tuplas
Uma tupla é um agrupamento de elementos de tamanho fixo, como uma coordenação (x, y). As tuplas são como listas, mas são imutáveis e não mudam de tamanho. Elas não são estritamente imutáveis, já que um dos elementos contidos pode ser mutável. As tuplas desempenham um tipo de "struct" em Python: uma maneira conveniente de transmitir um pequeno pacote lógico e de tamanho fixo de valores. Uma função que precisa retornar vários valores pode retornar uma tupla dos valores. Por exemplo, se eu quiser uma lista de coordenadas 3-d, a representação natural do Python seria uma lista de tuplas, em que cada tupla tem o tamanho 3 e contém um grupo (x, y, z).
Para criar uma tupla, basta listar os valores entre parênteses, separados por vírgulas. O “empty” tupla é apenas um par vazio de parênteses. O acesso aos elementos de uma tupla é como uma lista: len(), [ ], for, in etc. Funcionam da mesma forma.
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
Para criar uma tupla size-1, o elemento solitário deve ser seguido por uma vírgula.
tuple = ('hi',) ## size-1 tuple
Esse é um caso engraçado na sintaxe, mas a vírgula é necessária para distinguir a tupla do caso comum de colocar uma expressão entre parênteses. Em alguns casos, é possível omitir os parênteses e, nas vírgulas, o Python verá que você pretende criar uma tupla.
Ao atribuir uma tupla a outra de tamanho idêntico, a tupla de nomes de variáveis atribui todos os valores correspondentes. Se as tuplas não forem do mesmo tamanho, um erro será gerado. Esse recurso também funciona com listas.
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
Interpretações de lista (opcional)
A compreensão de listas é um recurso mais avançado que é bom para alguns casos, mas não é necessário para os exercícios e não é algo que você precisa aprender no início (ou seja, você pode pular esta seção). A compreensão de lista é uma maneira compacta de escrever uma expressão que se expande em uma lista inteira. Suponha que temos uma lista de números [1, 2, 3, 4]. Aqui está a compreensão da lista para calcular uma lista dos quadrados [1, 4, 9, 16]:
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
A sintaxe é [ expr for var in list ]. O for var in list parece uma repetição for normal, mas sem os dois-pontos (:). A expr à esquerda é avaliada uma vez para cada elemento a fim de fornecer os valores para a nova lista. Aqui está um exemplo com strings, em que cada string é alterada para maiúscula com "!!!" anexado:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
É possível adicionar um teste "if" à direita de "for-loop" para restringir o resultado. O teste "if" é avaliado para cada elemento, incluindo apenas os elementos em que o teste é verdadeiro.
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
Exercício: list1.py
Para praticar o material desta seção, tente mais tarde os problemas em list1.py que usam classificação e tuplas (nos Exercícios básicos).