
আপনি যখন একটি সম্প্রদায় সংযোগকারী তৈরি করেন, তখন আপনি স্কিমাতে সংজ্ঞায়িত প্রতিটি ক্ষেত্রের জন্য একটি ডেটা টাইপ প্রয়োজন। ডেটা টাইপ ফিল্ডের আদিম প্রকার যেমন BOOLEAN , STRING , NUMBER , ইত্যাদি সংজ্ঞায়িত করে৷
ডেটা প্রকারের পাশাপাশি, লুকার স্টুডিও শব্দার্থিক প্রকারগুলিও ব্যবহার করে। শব্দার্থিক প্রকারগুলি ডেটা যে ধরনের তথ্য উপস্থাপন করে তা বর্ণনা করতে সাহায্য করে। উদাহরণস্বরূপ, একটি NUMBER ডেটা প্রকারের একটি ক্ষেত্র শব্দার্থগতভাবে একটি মুদ্রার পরিমাণ বা শতাংশের প্রতিনিধিত্ব করতে পারে এবং একটি STRING ডেটা প্রকার সহ একটি ক্ষেত্র শব্দার্থগতভাবে একটি শহরকে উপস্থাপন করতে পারে৷ কোন শব্দার্থিক প্রকারগুলি উপলব্ধ তা দেখতে, অনুগ্রহ করে শব্দার্থিক প্রকারের ডকুমেন্টেশন দেখুন৷
কমিউনিটি সংযোগকারী স্কিমা এবং লুকার স্টুডিও ক্ষেত্র
যখন আপনি আপনার সম্প্রদায় সংযোগকারীর জন্য স্কিমা সংজ্ঞায়িত করেন, তখন প্রতিটি ক্ষেত্রের জন্য বিভিন্ন বৈশিষ্ট্য রয়েছে যা নির্ধারণ করবে কিভাবে ক্ষেত্রটি লুকার স্টুডিওতে উপস্থাপন এবং ব্যবহার করা হয়। উদাহরণ স্বরূপ:
-
conceptTypeপ্রপার্টি ব্যবহার করে আপনার কানেক্টর স্কিমাতে কনসেপ্টটাইপ সংজ্ঞায়িত করা হয়েছে। এই বৈশিষ্ট্যটি নির্ধারণ করে যে ক্ষেত্রটিকে একটি মাত্রা বা মেট্রিক হিসাবে বিবেচনা করা হবে কিনা। মেট্রিক্স এবং মাত্রার মধ্যে পার্থক্য সম্পর্কে একটি ব্যাখ্যা মাত্রা এবং মেট্রিক্সে পাওয়া যাবে। - শব্দার্থিক প্রকারটি হয় সংযোগকারী স্কিমাতে সংজ্ঞায়িত করা যেতে পারে, অথবা আপনার সংযোগকারীতে সংজ্ঞায়িত ডেটা টাইপ বৈশিষ্ট্য এবং আপনার সংযোগকারী দ্বারা প্রত্যাবর্তিত ডেটা মানগুলির উপর ভিত্তি করে লুকার স্টুডিও দ্বারা স্বয়ংক্রিয়ভাবে সনাক্ত করা যেতে পারে। এটি কীভাবে কাজ করে তার বিশদ বিবরণের জন্য স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ দেখুন।
- একত্রিতকরণের ধরন নির্ধারণ করে যে মেট্রিক মান (মাত্রা উপেক্ষা করা হয়) পুনরায় একত্রিত করা যাবে কিনা।
semantics.isReaggregatableপ্রপার্টিtrueসেট করাSUMএগ্রিগেশনে ডিফল্ট হবে, অন্যথায় এটিAutoএ সেট করা হবে। আপনিdefaultAggregationTypeঅ্যাগ্রিগেশন টাইপ বৈশিষ্ট্য ব্যবহার করে পুনরায় সংযোজনযোগ্য ক্ষেত্রের জন্য ম্যানুয়ালি ডিফল্ট একত্রিতকরণের ধরণ সেট করতে পারেন।
আপনি যখন লুকার স্টুডিওতে একটি সংযোগকারী ব্যবহার করে কনফিগার করেন এবং সংযোগ করেন, তখন আপনি উপরের বৈশিষ্ট্যগুলি কীভাবে সংজ্ঞায়িত করেছেন তার উপর ভিত্তি করে ক্ষেত্র সম্পাদকটি সংযোগকারীর জন্য সম্পূর্ণ স্কিমা দেখায়৷ আপনি যদি শব্দার্থিক প্রকারগুলি অন্তর্ভুক্ত করে থাকেন, তাহলে সেগুলি দেখাবে যেমন আপনি তাদের সংজ্ঞায়িত করেছেন৷ আপনি যদি স্বয়ংক্রিয় শব্দার্থিক টাইপ সনাক্তকরণ ব্যবহার করেন, তাহলে ক্ষেত্রগুলি যেমন শনাক্ত করা হয়েছিল তেমন দেখাবে। 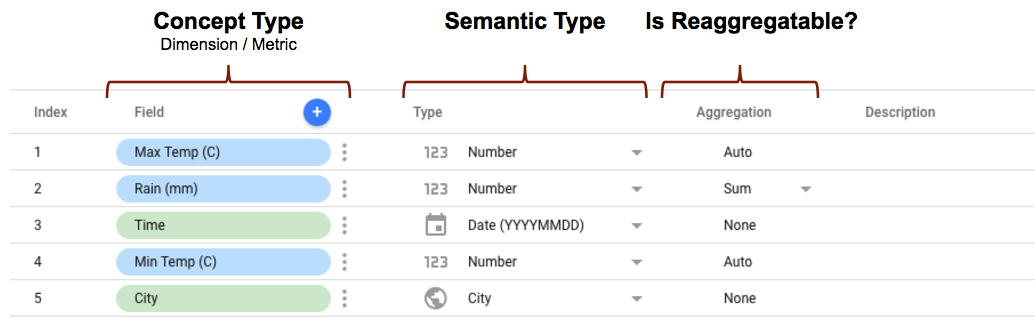
শব্দার্থিক তথ্য সেট করা
শব্দার্থিক তথ্য সেট করার দুটি উপায় আছে। আপনি হয় ক্ষেত্র শব্দার্থ ম্যানুয়ালি সেট করতে পারেন অথবা স্বয়ংক্রিয়ভাবে সনাক্ত করতে Looker Studio এর উপর নির্ভর করতে পারেন।
উদাহরণস্বরূপ, যদি আপনার কাছে এমন একটি নম্বর থাকে যা শব্দার্থগতভাবে ইউএস ডলারের প্রতিনিধিত্ব করে, তাহলে লুকার স্টুডিও এই শব্দার্থিক প্রকারটি স্বয়ংক্রিয়ভাবে সনাক্ত করতে সক্ষম হবে না। অতিরিক্তভাবে, স্বয়ংক্রিয় শব্দার্থিক সনাক্তকরণের জন্য আপনার স্কিমার প্রতিটি ক্ষেত্রের জন্য ডেটা আনয়ন কল করতে Looker Studio প্রয়োজন। আপনি যদি এর পরিবর্তে ম্যানুয়ালি স্কিমা নির্দিষ্ট করেন, তাহলে কোনো ডেটা আনয়ন কল করা হবে না। যে ক্ষেত্রে আপনি আপনার ডেটার জন্য শব্দার্থিক প্রকার (যেমন মুদ্রা, শতাংশ, তারিখ, ইত্যাদি) জানেন, তাহলে আমরা সঠিকতা এবং কার্যকারিতার কারণে এটিকে স্কিমাতে স্পষ্টভাবে সেট করার পরামর্শ দিই।
ম্যানুয়ালি শব্দার্থিক প্রকারগুলি সেট করা (প্রস্তাবিত)
আপনি যদি আপনার শব্দার্থিক প্রকারগুলি জানেন তবে আপনি প্রতিটি স্কিমা ক্ষেত্রের জন্য ম্যানুয়ালি semantics সংজ্ঞায়িত করতে পারেন। আপনার কাছে কী কী বৈশিষ্ট্য উপলব্ধ রয়েছে তার সম্পূর্ণ বিবরণ ক্ষেত্র রেফারেন্স পৃষ্ঠায় পাওয়া যাবে। আপনি যদি ম্যানুয়াল শব্দার্থিক প্রকারগুলি সংজ্ঞায়িত করতে পছন্দ করেন, তবে এটি সুপারিশ করা হয় যে আপনি প্রতিটি ক্ষেত্রের জন্য semanticType এবং semanticGroup সংজ্ঞায়িত করুন৷ ম্যানুয়ালি এই বৈশিষ্ট্যগুলি প্রদান করে, স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ প্রক্রিয়া চালানো হবে না। আপনি যদি ম্যানুয়ালি আপনার কিছু ফিল্ড সেট করেন, কিন্তু সবগুলো না করেন, তাহলে ফিল্ডের জন্য নির্দিষ্ট করা dataType উপর নির্ভর করে আপনি Text , Number বা Boolean ডিফল্ট নির্দিষ্ট করেন না।
নিম্নলিখিত একটি সাধারণ স্কিমার উদাহরণ যা ম্যানুয়ালি শব্দার্থিক প্রকারগুলি সেট করে। Income একটি মুদ্রা হিসাবে সেট করা হয়, এবং Filing Year একটি তারিখ হিসাবে সেট করা হয়।
ম্যানুয়াল শব্দার্থিক প্রকারের সমস্যা সমাধান করা
আপনি যদি অন্তর্নিহিত ডেটার জন্য আপনার শব্দার্থিক প্রকারগুলি ভুলভাবে সেট করেন তবে সেগুলি সঠিকভাবে কাজ করবে না। এটি পরীক্ষা করা কঠিন হতে পারে, তবে সমস্যাগুলি খুঁজে পেতে সহায়তা করার জন্য আপনি কিছু জিনিস করতে পারেন।
- সমস্ত ডেটার পরিবর্তে আপনার ডেটা থেকে 2 বা 3 সারি ফেরত দিন, তারপর ম্যানুয়ালি এটি পরিদর্শন করুন।
- লুকার স্টুডিওতে একটি টেবিল তৈরি করুন যা শুধুমাত্র সেই ক্ষেত্রটি ব্যবহার করে যা আপনি পরীক্ষা করার চেষ্টা করছেন।
-
GeoএবংDateক্ষেত্রগুলির প্রতি গভীর মনোযোগ দিন কারণ তাদের সবচেয়ে কঠোর বিন্যাস রয়েছে৷
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ
আপনি যদি আপনার স্কিমাতে কোনো শব্দার্থিক প্রকার সংজ্ঞায়িত না করে থাকেন, তাহলে লুকার স্টুডিও ডেটা টাইপ প্রপার্টি এবং আপনার সংযোগকারীর দ্বারা প্রত্যাবর্তিত ডেটা মানগুলির বিন্যাসের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে সেগুলি সনাক্ত করার চেষ্টা করবে।
স্বয়ংক্রিয় সনাক্তকরণ প্রক্রিয়ার ধাপগুলি নিম্নরূপ:
- আপনার সম্প্রদায় সংযোগকারীর
getSchemaফাংশন কার্যকর করে স্কিমার অনুরোধ করুন। - সংযোগকারী স্কিমাতে সংজ্ঞায়িত ক্ষেত্রগুলির ব্যাচগুলির মাধ্যমে পুনরাবৃত্তি করুন এবং ক্ষেত্রগুলিতে
getDataঅনুরোধগুলি ইস্যু করুন৷getDataঅনুরোধগুলিsampleExtractionপ্যারামিটারের সাথে নির্বাহ করা হয়trueবোঝা যায় যে ডেটা অনুরোধগুলি শব্দার্থিক সনাক্তকরণের উদ্দেশ্যে। - ফিল্ড ডেটা টাইপ এবং
getDataঅনুরোধ থেকে প্রত্যাবর্তিত মানের বিন্যাসের উপর ভিত্তি করে, ক্ষেত্রের শব্দার্থিক প্রকার সনাক্ত করুন।
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণ পরিচালনার জন্য বিকল্প
যখন লুকার স্টুডিও শব্দার্থিক সনাক্তকরণের উদ্দেশ্যে একটি সম্প্রদায় সংযোগকারীর getData ফাংশন সম্পাদন করে, তখন আগত অনুরোধে একটি sampleExtraction প্রপার্টি থাকবে যা true সেট করা হবে। আপনার সংযোগকারী দ্বারা প্রত্যাবর্তিত ডেটা শুধুমাত্র লুকার স্টুডিও দ্বারা ফিল্ডের শব্দার্থিক প্রকার সনাক্ত করতে ব্যবহার করা হয়। যেহেতু মানটি অন্য কোন উদ্দেশ্যে ব্যবহার করা হবে না, তাই এটির জন্য আপনার বাহ্যিক উৎস থেকে প্রকৃত তথ্যের প্রয়োজন নেই।
আপনার কোডে শব্দার্থিক প্রকার সনাক্তকরণ উন্নত করার বিভিন্ন উপায় রয়েছে:
প্রস্তাবিত: পূর্বনির্ধারিত মান পাস করুন
প্রতিটি ক্ষেত্রের জন্য একটি পূর্বনির্ধারিত মান ফেরত দিন যা ফিল্ডের জন্য শব্দার্থিক প্রকারকে সবচেয়ে ভালভাবে উপস্থাপন করে এবং লুকার স্টুডিও দ্বারা সঠিকভাবে সনাক্ত করা হবে বলে পরিচিত৷ উদাহরণস্বরূপ, যদি একটি ক্ষেত্রের জন্য শব্দার্থিক প্রকার দেশ হয় তাহলে একটি মান প্রদান করুন যেমন ইতালির জন্যIT। এই পদ্ধতির অন্য সুবিধা হল যে এটি অনেক দ্রুত কারণ এটি আপনাকে ডেটার জন্য তৃতীয় পক্ষের পরিষেবাতে HTTP অনুরোধ করতে হবে না।রেকর্ডের শুধুমাত্র n সংখ্যা রিটার্ন
আপনি যে তৃতীয় পক্ষের পরিষেবা থেকে ডেটা আনছেন তা যদি ডেটা অনুরোধ করার সময় সারি সীমা সমর্থন করে তবে সম্পূর্ণ ডেটা সেটের পরিবর্তে লুকার স্টুডিওতে সারিগুলির একটি ছোট উপসেট ফিরিয়ে দিন৷ এটি প্রতিটি শব্দার্থ শনাক্তকরণ অনুরোধের জন্য লুকার স্টুডিওতে পাস করার জন্য প্রয়োজনীয় ডেটার পরিমাণ সীমিত করবে।সমস্ত কলাম অনুরোধ করুন এবং প্রতিক্রিয়া ক্যাশে
যদি তৃতীয় পক্ষের পরিষেবার জন্য সমস্ত কলামের অনুরোধ করা সম্ভব হয় যেখান থেকে আপনি ডেটা আনছেন তাহলে লুকার স্টুডিও থেকে প্রাপ্ত প্রথম শব্দার্থ সনাক্তকরণ অনুরোধে সমস্ত কলাম আনুন এবং ফলাফলগুলি ক্যাশে করুন৷ পরবর্তী শব্দার্থ শনাক্তকরণ অনুরোধের জন্য তৃতীয় পক্ষের পরিষেবাতে অতিরিক্ত HTTP অনুরোধ করার পরিবর্তে ক্যাশে থেকে কলামের মান আনুন।ভিন্ন কিছু করবেন না
আপনি অনুরোধের জন্য কোনো নির্দিষ্ট আবাসন বাস্তবায়ন না করা বেছে নিতে পারেন যেখানেsampleExtractiontrueসেট করা আছে। এর ফলে শব্দার্থ শনাক্তকরণ প্রক্রিয়া ধীর হবে কারণ লুকার স্টুডিওকে শব্দার্থ শনাক্তকরণ প্রক্রিয়ার জন্য সমস্ত ডেটা আনতে হবে। এছাড়াও, এটি আপনার বাহ্যিক ডেটা উত্সের অনুরোধের হারকে প্রভাবিত করবে কারণ অনেক শব্দার্থ সনাক্তকরণ অনুরোধ সমান্তরালভাবে কার্যকর করা হবে।
স্বয়ংক্রিয় শব্দার্থিক প্রকার সনাক্তকরণের জন্য স্বীকৃত বিন্যাস
তারিখ সময়
-
YYYY/MM/DD-HH:MM:SS -
YYYY-MM-DD [HH:MM:SS[.uuuuuu]] -
YYYY/MM/DD [HH:MM:SS[.uuuuuu]] -
YYYYMMDD [HH:MM:SS[.uuuuuu]] -
Sat, 24 May 2008 20:09:47 GMT -
2008-05-24T20:09:47Z - সময়: সেকেন্ড, মাইক্রো, মিলি এবং ন্যানো এর জন্য যুগ।
জিও
- মহাদেশের নাম বা কোড
- উপমহাদেশের নাম বা কোড
- অঞ্চলের নাম বা কোড
- দেশের নাম বা কোড । এছাড়াও ISO_3166-1 দেখুন।
- শহরের নাম
- কমা অক্ষাংশ এবং দ্রাঘিমাংশের মান পৃথক করেছে
- মনোনীত মার্কেটিং এরিয়া (DMA) নাম এবং কোড