
In this codelab, you'll learn how to use some advanced features of BigQuery, including:
- User-Defined Functions in JavaScript
- Partitioned tables
- Direct queries against data living in Google Cloud Storage and Google Drive.
You'll take data from the US Federal Election Commission, clean it up, and load it into BigQuery. You'll also get a chance to ask some interesting questions of that dataset.
While this codelab doesn't assume any prior experience with BigQuery, some understanding of SQL will help you get more out of it.
What you'll learn
- How to use JavaScript User Defined Functions to perform operations that are difficult to do in SQL.
- How to use BigQuery to perform ETL (Extract, Transform, Load) operations on data that lives in other data stores, like Google Cloud Storage and Google Drive.
What you'll need
- A Google Cloud Project with billing enabled.
- A Google Cloud Storage Bucket
- Google Cloud SDK installed
How will you use this tutorial?
How would rate your experience level with BigQuery?
Self-paced environment setup
If you don't already have a Google Account (Gmail or Google Apps), you must create one. Sign-in to Google Cloud Platform console (console.cloud.google.com) and create a new project:



Remember the project ID, a unique name across all Google Cloud projects (the name above has already been taken and will not work for you, sorry!). It will be referred to later in this codelab as PROJECT_ID.
Next, you'll need to enable billing in the Cloud Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost you more than a few dollars, but it could be more if you decide to use more resources or if you leave them running (see "cleanup" section at the end of this document).
New users of Google Cloud Platform are eligible for a $300 free trial.
Google Cloud Shell
While Google Cloud and Big Query can be operated remotely from your laptop, in this codelab we will be using Google Cloud Shell, a command line environment running in the Cloud.
This Debian-based virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on the Google Cloud, greatly enhancing network performance and authentication. This means that all you will need for this codelab is a browser (yes, it works on a Chromebook).
To activate Google Cloud Shell, from the developer console simply click the button on the top right-hand side (it should only take a few moments to provision and connect to the environment):

Click the "Start Cloud Shell" button:


Once connected to the cloud shell, you should see that you are already authenticated and that the project is already set to your PROJECT_ID :
gcloud auth list
Command output
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Command output
[core] project = <PROJECT_ID>
Cloud Shell also sets some environment variables by default which may be useful as you run future commands.
echo $GOOGLE_CLOUD_PROJECT
Command output
<PROJECT_ID>
If for some reason the project is not set, simply issue the following command :
gcloud config set project <PROJECT_ID>
Looking for your PROJECT_ID? Check out what ID you used in the setup steps or look it up in the console dashboard:

IMPORTANT: Finally, set the default zone and project configuration:
gcloud config set compute/zone us-central1-f
You can choose a variety of different zones. Learn more in the Regions & Zones documentation.
In order to run the BigQuery queries in this codelab, you'll need your own dataset. Pick a name for it, such as campaign_funding. Run the following commands in your shell (CloudShell for instance):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
After your dataset has been created, you should be ready to go. Running this command should also help to verify that you've got the bq command line client setup correctly, authentication is working, and you have write access to the cloud project you're operating under. If you have more than one project, you will be prompted to select the one you're interested in from a list.

The US Federal Election Commission campaign finance dataset has been decompressed and copied to the GCS bucket gs://campaign-funding/.
Let's download one of the source files locally so that we can see what it looks like. Run the following commands from a command window:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
This should display the contents of the individual contributions file. There are three types of files we'll be looking at for this codelab: individual contributions (indiv*.txt), candidates (cn*.txt), and committees (cm*.txt). If you're interested, use the same mechanism to check out what is in those other files.
We're not going to load the raw data directly into BigQuery; instead, we're going to query it from Google Cloud Storage. To do so, we need to know the schema and some information about it.
The dataset is described on the federal election website here. The schemas for the tables we'll be looking at are:
In order to link to the tables, we need to create a table definition for them that includes the schemas. Run the following commands to generate the individual table definitions:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Open the indiv_dev.json file with your favorite text editor and take a look at the contents; it will contain json that describes how to interpret the FEC data file.
We will need to make two small edits to the csvOptions section. Add a fieldDelimiter value of "|" and a quote value of "" (the empty string). This is necessary because the data file is not actually comma-separated, it is pipe-separated:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
The indiv_dev.json file should now read :
"fieldDelimiter": "|",
"quote":"",
Since the creation of the table definitions for the committee and candidate tables are similar, and the schema contains a decent bit of boilerplate, let's just download those files.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
These files will look similar to the indiv_dev.json file. Note you can also download the indiv_def.json file, in case you are having trouble getting the right values.
Next, let's actually link a BigQuery table to these files. Run the following commands:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
This will create three bigquery tables: transactions, committees, and candidates. You can query these tables like they are normal BigQuery tables, but they're not actually stored in BigQuery, they're in Google Cloud Storage. If you update the underlying files, the updates will be immediately reflected in queries that you run.
Next, let's actually try running a couple of queries. Open the BigQuery Web UI.
Find your dataset in the left navigation pane (you might have to change the project dropdown in the top left corner), click the big red ‘COMPOSE QUERY' button, and enter the following query in the box:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
This will find the most recent 100 campaign donations by employees of Google. If you'd like, try playing around and finding campaign donations from residents of your zip code or find the largest donations in your city.
The query and the results will look something like this:
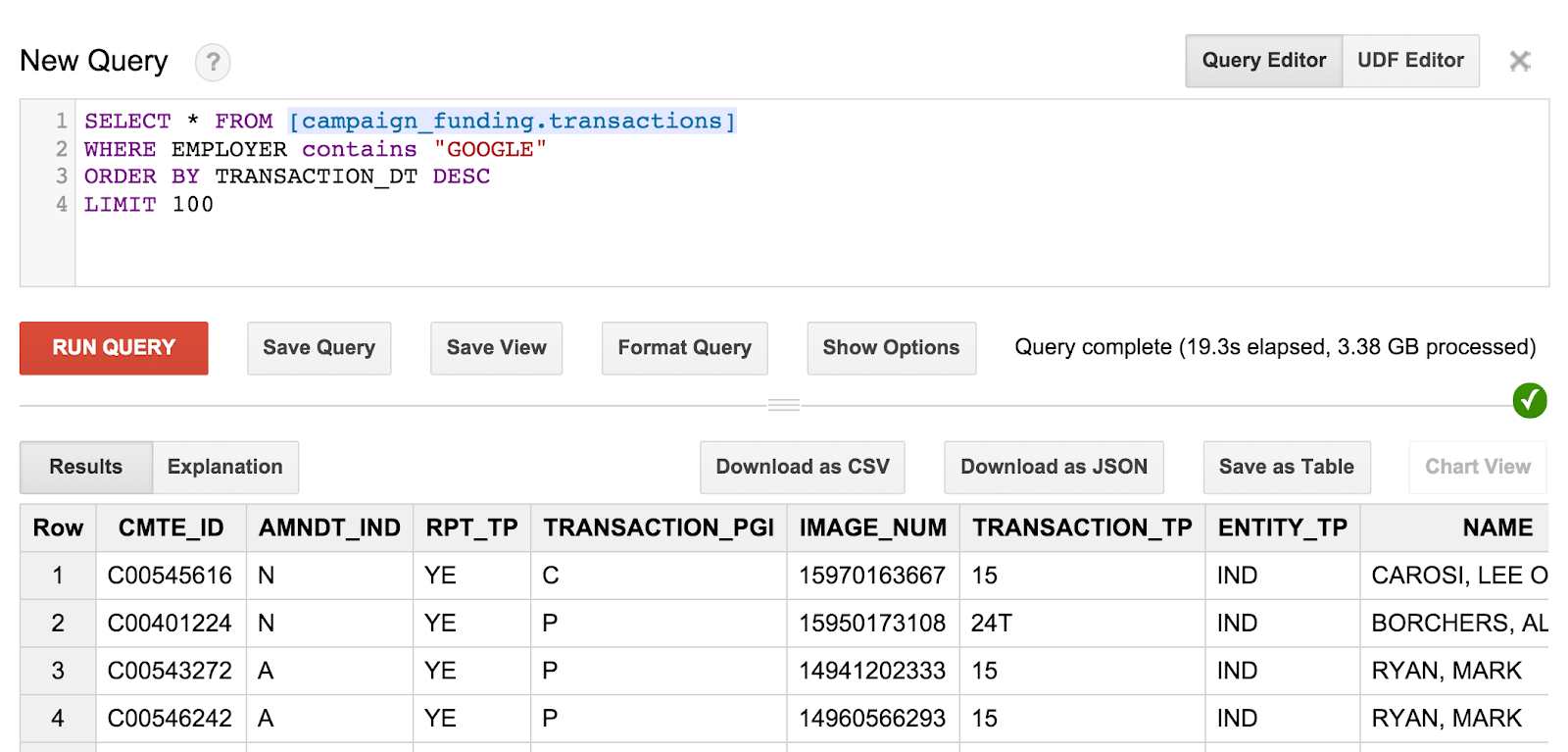
One thing you might notice, however, is that you can't really tell who the recipient was of these donations. We need to come up with some fancier queries to get that information.
Click on the transactions table in the left pane, and click on the schema tab. It should look like the screenshot below:
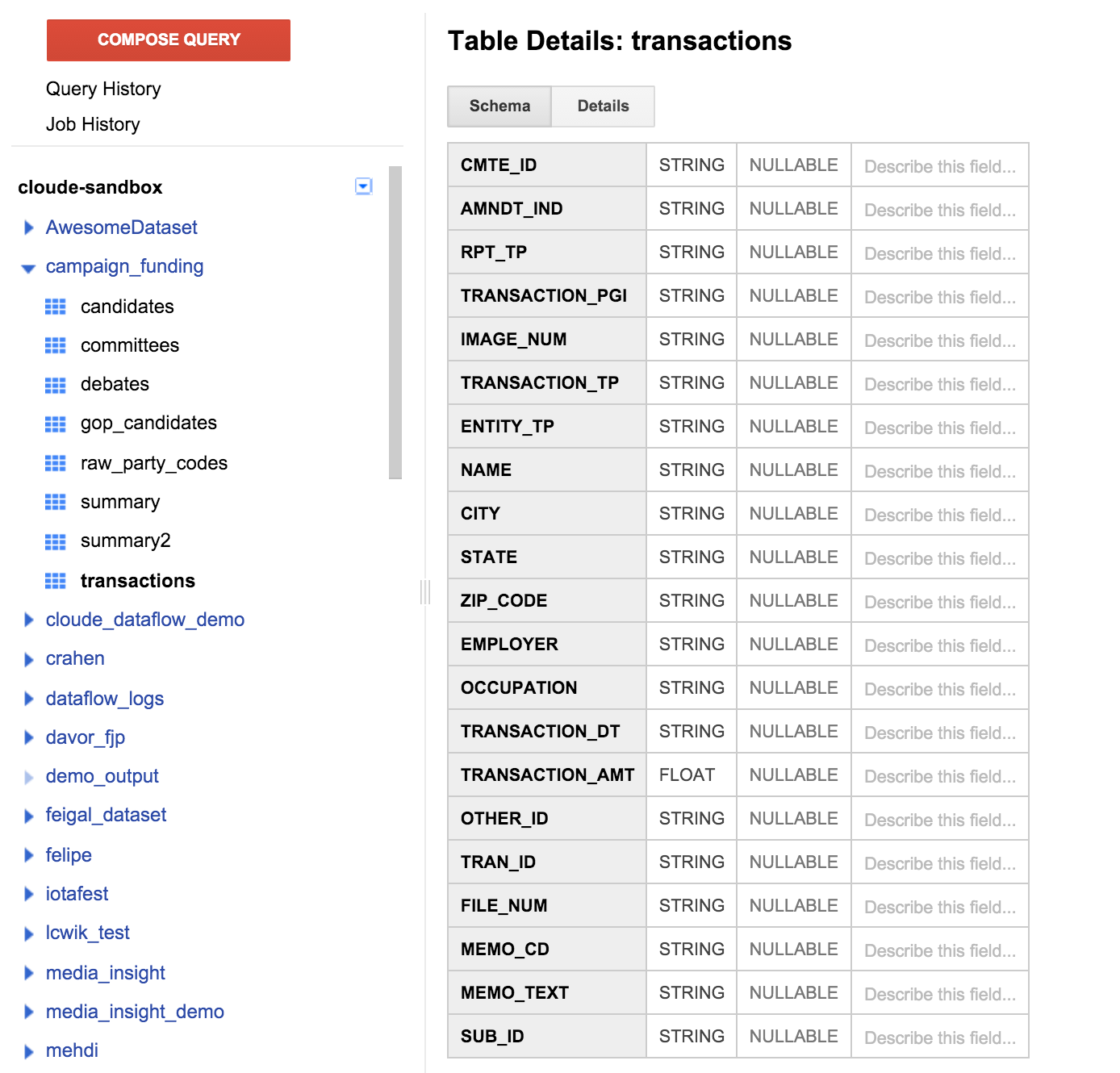
We can see a list of fields that match the table definition we specified previously. You may notice there is no recipient field, or any way to figure out what candidate the donation supported. However, there is a field called CMTE_ID. This will let us link the committee that was the recipient of the donation to the donation. This still isn't all that useful.
Next, click on the committees table to check out its schema. We've got a CMET_ID, which can join us to the transactions table. Another field is CAND_ID; this can be joined with a CAND_ID table in the candidates table. Finally, we have a link between transactions and candidates by going through the committees table.
Note that there isn't a preview tab for GCS-based tables. This is because in order to read the data, BigQuery needs to read from an external data source. Let's get a sample of the data by running a simple ‘SELECT *' query on the candidates table.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
The result should look something like this:
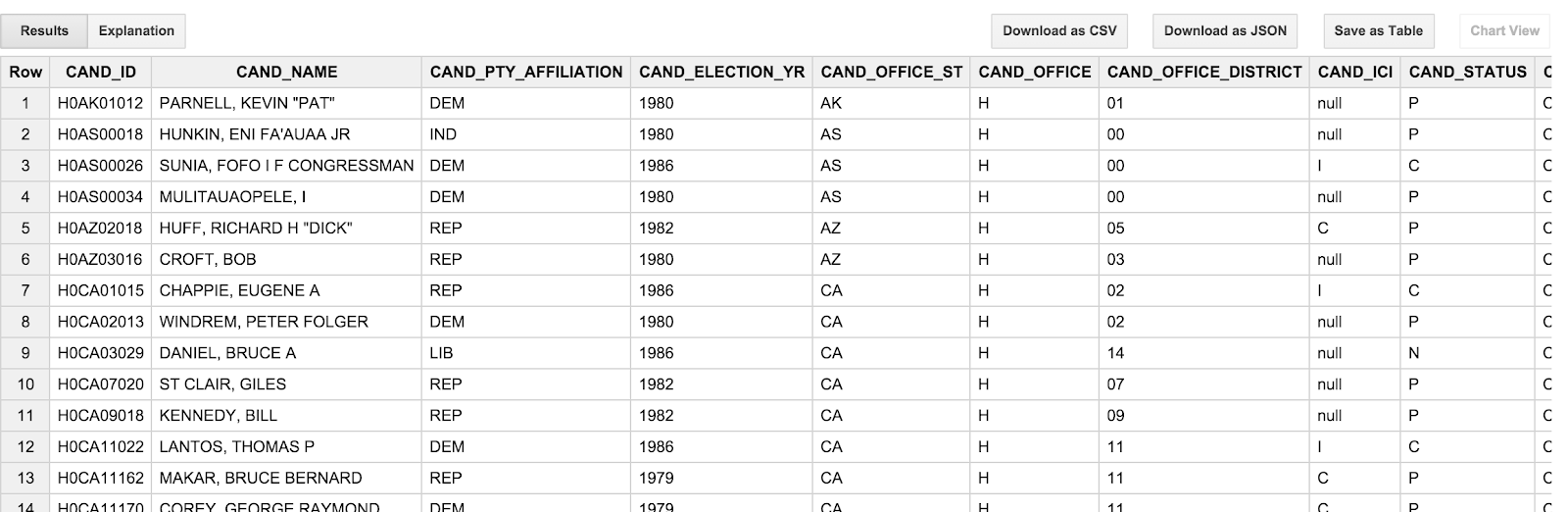
One thing you might notice, is that the candidate names are ALL CAPS and are presented in "lastname, firstname" order. This is a little bit annoying, since this isn't really how we tend to think of the candidates; we'd rather see "Barack Obama" than "OBAMA, BARACK". Moreover, the transaction dates (TRANSACTION_DT) in the transactions table are a bit awkward as well. They are string values in the format YYYYMMDD. We'll address these quirks in the next section.
Now that we have an understanding of how transactions relate to candidates, let's run a query to figure out who is giving money to whom. Cut and paste the following query into the compose box:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
This query joins the transactions table to the committees table and then to the candidates table. It only looks at transactions from people with the word "ENGINEER" in their occupation title. The query aggregates results by party affiliation; this lets us see the distribution of giving to various political parties amongst engineers.
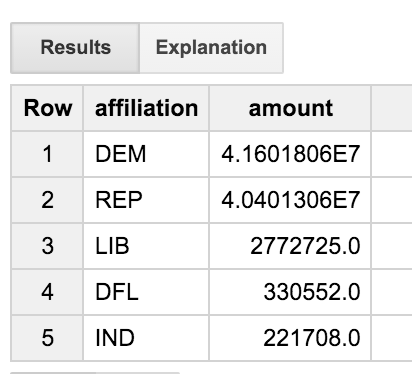
We can see that engineers are a pretty balanced bunch, giving more or less evenly to democrats and republicans. But what is the ‘DFL' party? Wouldn't it be nice to actually get full names, rather than just a three letter code?
The party codes are defined on the FEC website. There is a table that matches the party code to the full name (it turns out that ‘DFL' is ‘Democratic-Farmer-Labor'). While we could manually perform the translations in our query, that seems like a lot of work, and difficult to keep in sync.
What if we could parse the HTML as part of the query? Right click anywhere on that page and look at "view page source". There is a lot of header / boilerplate information in the source, but find the <table> tag. Each mapping row is in an HTML <tr> element, the name and the code are both wrapped in <td> elements. Each row will look something like this:
The HTML looks something like this:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Note that BigQuery can't read the file directly from the web; this because bigquery is capable of hitting a source from thousands of workers simultaneously. If this were allowed to run against random web pages, it would essentially be a distributed denial of service attack (DDoS). The html file from the FEC web page is stored in the gs://campaign-funding bucket.
We'll need to make a table based on the campaign funding data. This will be similar to the other GCS-backed tables we created. The difference here is that we don't actually have a schema; we'll just use a single field per row and call it ‘data'. We'll pretend that it is a CSV file, with but instead of comma-delimiting, we'll use a bogus delimiter (`) and no quote character.
To create the party lookup table, run the following commands from the command line:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
We will now use javascript to parse the file. In the top right of the BigQuery Query Editor should be a button labeled "UDF Editor". Click on it to switch to editing a javascript UDF. The UDF editor will be populated with some commented out boilerplate.

Go ahead and delete the code it contains, and enter the following code:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
The javascript here is divided into two pieces; the first is a function that takes a row of input emits a parsed output. The other is a definition that registers that function as a User Defined Function (UDF) with the name tableParser, and indicates that it takes an input column called ‘data' and outputs two columns, code and name. The code column will be the three-letter code, the name column is the full name of the party.
Switch back to the "Query Editor tab", and enter the following query:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Running this query will parse the raw HTML file and output the field values in structured format. Pretty slick, eh? See if you can figure out what ‘DFL' stands for.
Now that we can translate party codes to names, let's try another query that uses this to find out something interesting. Run the following query:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
This query will show which candidates got the largest campaign donations, and will spell out their party affiliations.
These tables aren't very large, and they take 30 seconds or so to query. If you're going to be doing a lot of work with the tables, you'll probably want to import them into BigQuery. You can run an ETL query against the table to coerce the data to something easy to use, then save it as a permanent table. This means that you don't always have to remember how to translate party codes, and you can also filter out erroneous data while you're doing it.
Click the "Show options" button and then the ‘select table' button next to the "Destination Table" label. Pick your campaign_funding dataset, and enter the table ID as ‘summary'. Select the ‘allow large results' checkbox.
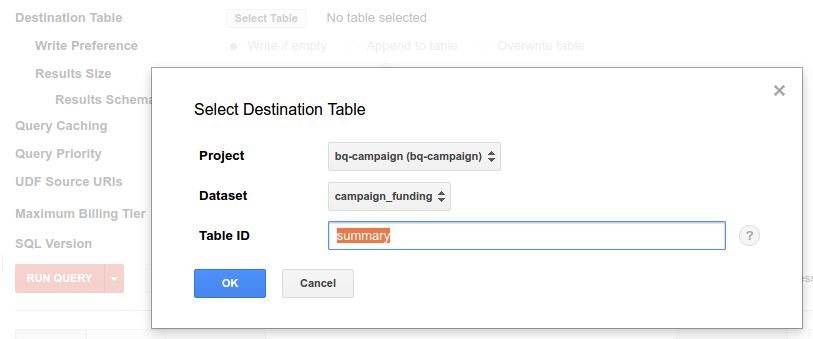
Now run the following query:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
This query is significantly longer, and has some additional cleanup options. For example, it ignores anything where the amount is greater than $1M. It also uses regular expressions to turn "LASTNAME, FIRSTNAME" into "FIRSTNAME LASTNAME". If you're feeling adventurous, try writing a UDF to do even better, and fix the capitalization (e.g. "Firstname Lastname").
Finally, try running a couple of queries against your campaign_funding.summary table to verify that the queries against that table are faster. Don't forget to remove the destination table query option, first, or you may end up overwriting your summary table!
You've now cleaned and imported data from the FEC website into BigQuery!
What we've covered
- Using GCS-backed tables in BigQuery.
- Using User-Defined Functions in BigQuery.
Next Steps
- Try some interesting queries to find out who is giving money to whom this election cycle.
Learn More
- Learn more about what you can do with user defined functions.
- Read about federated data sources (including GCS).
- Post questions and find answers on Stackoverflow under the google-bigquery tag.
Give us your feedback
- Feel free to use the link at the bottom left of this page to file issues or share feedback!